SQL Server 2008 introducerade glesa kolumner som en metod för att minska lagringen för nollvärden och tillhandahålla mer utökningsbara scheman. Avvägningen är att det finns ytterligare overhead när du lagrar och hämtar icke-NULL-värden. Jag var intresserad av att förstå kostnaden för att lagra icke-NULL-värden, efter att ha pratat med en kund som använde denna datatyp i en mellanlagringsmiljö. De vill optimera skrivprestandan, och jag undrade om användningen av glesa kolumner hade någon effekt, eftersom deras metod krävde att man infogade en rad i tabellen och sedan uppdaterade den. Jag skapade ett konstruerat exempel för den här demon, förklarat nedan, för att avgöra om detta var en bra metod för dem att använda.
Intern granskning
Som en snabb recension, kom ihåg att när du skapar en kolumn för en tabell som tillåter NULL-värden, om det är en kolumn med fast längd (t.ex. en INT), kommer den alltid att förbruka hela kolumnbredden på sidan även när kolumnen är NULL. Om det är en kolumn med variabel längd (t.ex. VARCHAR), kommer den att förbruka minst två byte i kolumnoffset-arrayen när den är NULL, såvida inte kolumnerna är efter den senast ifyllda kolumnen (se Kimberlys blogginlägg Kolumnordningen spelar ingen roll...i allmänhet , men – DET BERÖR). En gles kolumn kräver inget utrymme på sidan för NULL-värden, oavsett om det är en kolumn med fast längd eller variabel längd, och oavsett vilka andra kolumner som är ifyllda i tabellen. Avvägningen är att när en gles kolumn är befolkad tar den fyra (4) fler byte lagring än en icke-gles kolumn. Till exempel:
| Kolumntyp | Lagringskrav |
|---|---|
| STORA kolumn, icke-gles, med nej värde | 8 byte |
| STORA kolumn, icke-gles, med ett värde | 8 byte |
| STOR kolumn, gles, med nej värde | 0 byte |
| STOR kolumn, gles, med ett värde | 12 byte |
Därför är det viktigt att bekräfta att lagringsfördelarna överväger den potentiella prestandaträffen vid hämtning – vilket kan vara försumbart baserat på balansen mellan läsning och skrivning mot data. De uppskattade utrymmesbesparingarna för olika datatyper dokumenteras i Books Online-länken ovan.
Testscenarier
Jag satte upp fyra olika scenarier för testning, som beskrivs nedan, och varje tabell hade en ID-kolumn (INT), en Name-kolumn (VARCHAR(100)) och en Type-kolumn (INT) och sedan 997 NULLABLE-kolumner.
| Test-ID | Tabellbeskrivning | DML Operations |
|---|---|---|
| 1 | 997 kolumner av INT-datatyp, NULLABLE, icke-gles | Infoga en rad i taget, fyll i ID, Namn, Typ och tio (10) slumpmässiga NULLABLE-kolumner |
| 2 | 997 kolumner av INT-datatyp, NULLABLE, sparse | Infoga en rad i taget, fyll i ID, Namn, Typ och tio (10) slumpmässiga NULLABLE-kolumner |
| 3 | 997 kolumner av INT-datatyp, NULLABLE, icke-gles | Infoga en rad i taget, fyll i ID, Namn, Endast typ, uppdatera sedan raden, lägg till värden för tio (10) slumpmässiga NULLABLE-kolumner |
| 4 | 997 kolumner av INT-datatyp, NULLABLE, sparse | Infoga en rad i taget, fyll i ID, Namn, Endast typ, uppdatera sedan raden, lägg till värden för tio (10) slumpmässiga NULLABLE-kolumner |
| 5 | 997 kolumner med VARCHAR-datatyp, NULLABLE, icke-gles | Infoga en rad i taget, fyll i ID, Namn, Typ och tio (10) slumpmässiga NULLABLE-kolumner |
| 6 | 997 kolumner med VARCHAR-datatyp, NULLABLE, sparse | Infoga en rad i taget, fyll i ID, Namn, Typ och tio (10) slumpmässiga NULLABLE-kolumner |
| 7 | 997 kolumner med VARCHAR-datatyp, NULLABLE, icke-gles | Infoga en rad i taget, fyll i ID, Namn, Endast typ, uppdatera sedan raden, lägg till värden för tio (10) slumpmässiga NULLABLE-kolumner |
| 8 | 997 kolumner med VARCHAR-datatyp, NULLABLE, sparse | Infoga en rad i taget, fyll i ID, Namn, Endast typ, uppdatera sedan raden, lägg till värden för tio (10) slumpmässiga NULLABLE-kolumner |
Varje test kördes två gånger med en datauppsättning på 10 miljoner rader. De bifogade skripten kan användas för att replikera testning, och stegen var följande för varje test:
- Skapa en ny databas med förstorade data och loggfiler
- Skapa lämplig tabell
- Väntestatistik för ögonblicksbilder och filstatistik
- Observera starttiden
- Kör DML (en infogning, eller en infogning och en uppdatering) för 10 miljoner rader
- Observera stopptiden
- Snapshot wait-statistik och filstatistik och skriv till en loggningstabell i en separat databas på separat lagring
- Ögonblicksbild dm_db_index_physical_stats
- Släpp databasen
Testning gjordes på en Dell PowerEdge R720 med 64 GB minne och 12 GB allokerat till SQL Server 2014 SP1 CU4-instansen. Fusion-IO SSD:er användes för datalagring för databasfilerna.
Resultat
Testresultaten presenteras nedan för varje testscenario.
Längd
I alla fall tog det mindre tid (i genomsnitt 11,6 minuter) att fylla i tabellen när glesa kolumner användes, även när raden först infogades och sedan uppdaterades. När raden först infogades och sedan uppdaterades tog testet nästan dubbelt så lång tid att köra jämfört med när raden infogades, eftersom dubbelt så många dataändringar utfördes.
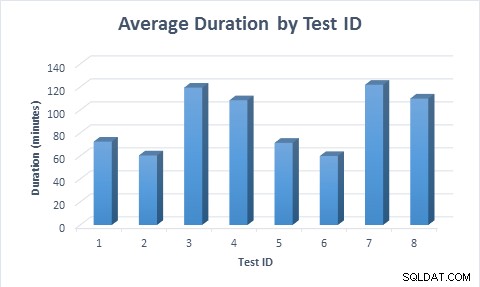 Genomsnittlig varaktighet för varje testscenario
Genomsnittlig varaktighet för varje testscenario
Väntestatistik
| Test-ID | Genomsnittlig procentandel | Genomsnittlig väntan (sekunder) |
|---|---|---|
| 1 | 16.47 | 0,0001 |
| 2 | 14.00 | 0,0001 |
| 3 | 16.65 | 0,0001 |
| 4 | 15.07 | 0,0001 |
| 5 | 12.80 | 0,0001 |
| 6 | 13.99 | 0,0001 |
| 7 | 14.85 | 0,0001 |
| 8 | 15.02 | 0,0001 |
Väntestatistiken var konsekvent för alla tester och inga slutsatser kan dras baserat på dessa data. Hårdvaran uppfyllde tillräckligt resurskraven i alla testfall.
Filstatistik
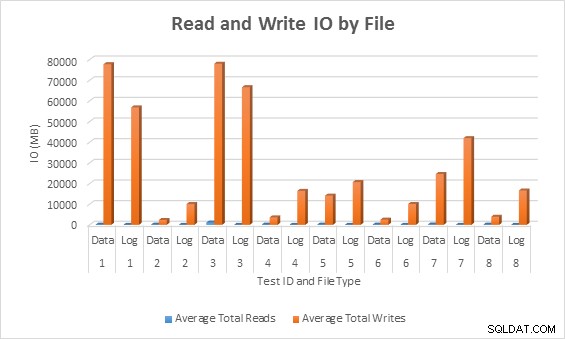 Genomsnittlig IO (läs och skriv) per databasfil
Genomsnittlig IO (läs och skriv) per databasfil
I samtliga fall genererade testerna med glesa kolumner mindre IO (särskilt skrivningar) jämfört med icke-glesa kolumner.
Indexa fysisk statistik
| Testfall | Antal rader | Totalt antal sidor (klustrade index) | Totalt utrymme (GB) | Genomsnittligt utrymme som används för bladsidor i CI (%) | Genomsnittlig poststorlek (byte) |
|---|---|---|---|---|---|
| 1 | 10 000 000 | 10 037 312 | 76 | 51,70 | 4 184,49 |
| 2 | 10 000 000 | 301 429 | 2 | 98.51 | 237,50 |
| 3 | 10 000 000 | 10 037 312 | 76 | 51,70 | 4 184,50 |
| 4 | 10 000 000 | 460 960 | 3 | 64.41 | 237,50 |
| 5 | 10 000 000 | 1 823 083 | 13 | 90.31 | 1 326,08 |
| 6 | 10 000 000 | 324 162 | 2 | 98.40 | 255.28 |
| 7 | 10 000 000 | 3 161 224 | 24 | 52.09 | 1 326,39 |
| 8 | 10 000 000 | 503 592 | 3 | 63.33 | 255.28 |
Det finns betydande skillnader i utrymmesanvändning mellan de icke-glesa och sparsamma tabellerna. Detta är mest anmärkningsvärt när man tittar på testfall 1 och 3, där en datatyp med fast längd användes (INT), jämfört med testfall 5 och 7, där en datatyp med variabel längd användes (VARCHAR(255)). Heltalskolumnerna förbrukar diskutrymme även när de är NULL. Kolumnerna med variabel längd förbrukar mindre diskutrymme, eftersom endast två byte används i offset-arrayen för NULL-kolumner, och inga byte för de NULL-kolumner som ligger efter den senast fyllda kolumnen i raden.
Dessutom orsakar processen att infoga en rad och sedan uppdatera den fragmentering för kolumntestet med variabel längd (fall 7), jämfört med att helt enkelt infoga raden (fall 5). Tabellstorleken nästan fördubblas när infogningen följs av uppdateringen, på grund av siddelningar som uppstår vid uppdatering av raderna, vilket lämnar sidorna halvfulla (mot 90 % fulla).
Sammanfattning
Sammanfattningsvis ser vi en betydande minskning av diskutrymme och IO när glesa kolumner används, och de presterar något bättre än icke-glesa kolumner i våra enkla datamodifieringstester (observera att hämtningsprestanda också bör övervägas; kanske föremål för en annan inlägg).
Glesa kolumner har ett mycket specifikt användningsscenario och det är viktigt att undersöka mängden diskutrymme som sparas, baserat på datatypen för kolumnen och antalet kolumner som vanligtvis kommer att fyllas i tabellen. I vårt exempel hade vi 997 glesa kolumner, och vi fyllde bara i 10 av dem. Som mest, i fallet där datatypen som användes var heltal, skulle en rad på bladnivån för det klustrade indexet förbruka 188 byte (4 byte för ID, 100 byte max för Namn, 4 byte för typen och sedan 80 byte för 10 kolumner). När 997 kolumner var icke-glesa, tilldelades 4 byte för varje kolumn, även när NULL, så varje rad var minst 4 000 byte på bladnivå. I vårt scenario är glesa kolumner absolut acceptabla. Men om vi fyllde 500 eller fler glesa kolumner med värden för en INT-kolumn, så går utrymmesbesparingarna förlorade och modifieringsprestandan kanske inte längre är bättre.
Beroende på datatypen för dina kolumner och det förväntade antalet kolumner som ska fyllas i av totalen, kanske du vill utföra liknande tester för att säkerställa att, när du använder glesa kolumner, infogningsprestanda och lagring är jämförbara eller bättre än när du använder icke -glesa kolumner. För fall då inte alla kolumner är ifyllda är glesa kolumner definitivt värda att överväga.