SQL Server 2014 CTP1 har varit ute i några veckor nu, och du har förmodligen sett en hel del press om minnesoptimerade tabeller och uppdateringsbara kolumnbutiksindex. Även om dessa verkligen är värda att uppmärksammas, ville jag i det här inlägget utforska den nya förbättringen SELECT ... INTO parallellism. Förbättringen är en av de färdiga att bära förändringar som, utifrån utseendet, inte kommer att kräva betydande kodändringar för att börja dra nytta av den. Mina utforskningar utfördes med version Microsoft SQL Server 2014 (CTP1) – 11.0.9120.5 (X64), Enterprise Evaluation Edition.
Parallell SELECT … INTO
SQL Server 2014 introducerar parallellaktiverad SELECT ... INTO för databaser och för att testa den här funktionen använde jag databasen AdventureWorksDW2012 och en version av tabellen FactInternetSales som hade 61 847 552 rader (jag var ansvarig för att lägga till dessa rader; de följer inte med databasen som standard).
Eftersom den här funktionen, från och med CTP1, kräver databaskompatibilitetsnivå 110, för teständamål ställde jag databasen till kompatibilitetsnivå 100 och körde följande fråga för mitt första test:
SELECT [ProductKey],
[OrderDateKey],
[DueDateKey],
[ShipDateKey],
[CustomerKey],
[PromotionKey],
[CurrencyKey],
[SalesTerritoryKey],
[SalesOrderNumber],
[SalesOrderLineNumber],
[RevisionNumber],
[OrderQuantity],
[UnitPrice],
[ExtendedAmount],
[UnitPriceDiscountPct],
[DiscountAmount],
[ProductStandardCost],
[TotalProductCost],
[SalesAmount],
[TaxAmt],
[Freight],
[CarrierTrackingNumber],
[CustomerPONumber],
[OrderDate],
[DueDate],
[ShipDate]
INTO dbo.FactInternetSales_V2
FROM dbo.FactInternetSales; Frågekörningstiden var 3 minuter och 19 sekunder på min test-VM och den faktiska exekveringsplanen för frågekörning var följande:

SQL Server använde en serieplan, som jag förväntade mig. Lägg också märke till att min tabell hade ett icke-klustrat kolumnlagerindex på sig som skannades (jag skapade detta icke-klustrade kolumnlagerindex för användning med andra tester, men jag ska visa dig exekveringsplanen för klustrade kolumnbutiksindexförfrågningar senare också). Planen använde inte parallellism och Columnstore Index Scan använde radexekveringsläge istället för batchexekveringsläge.
Så härnäst ändrade jag databaskompatibilitetsnivån (och notera att det inte finns en SQL Server 2014-kompatibilitetsnivå i CTP1 ännu):
USE [master]; GO ALTER DATABASE [AdventureWorksDW2012] SET COMPATIBILITY_LEVEL = 110; GO
Jag tappade FactInternetSales_V2-tabellen och körde sedan om min ursprungliga SELECT ... INTO drift. Den här gången var frågans exekveringslängd 1 minut och 7 sekunder och den faktiska exekveringsplanen för frågan var som följer:
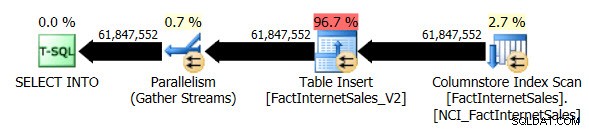
Vi har nu en parallell plan och den enda förändringen jag behövde göra var databaskompatibilitetsnivån för AdventureWorksDW2012. Min test-VM har fyra vCPU:er allokerade till den, och frågeexekveringsplanen fördelade rader över fyra trådar:

Den icke-klustrade Columnstore Index Scan, medan den använde parallellism, använde inte batchkörningsläge. Istället använde den radexekveringsläge.
Här är en tabell som visar testresultaten hittills:
| Skanningstyp | Kompatibilitetsnivå | Parallell SELECT ... INTO | Exekveringsläge | Längd |
|---|---|---|---|---|
| Icke-klusterad kolumnbutiksindexsökning | 100 | Nej | Rad | 3:19 |
| Icke-klusterad kolumnbutiksindexsökning | 110 | Ja | Rad | 1:07 |
Så som nästa test släppte jag det icke-klustrade kolumnlagerindexet och körde om SELECT ... INTO fråga med både databaskompatibilitetsnivå 100 och 110.
Kompatibilitetsnivå 100-testet tog 5 minuter och 44 sekunder att köra, och följande plan genererades:
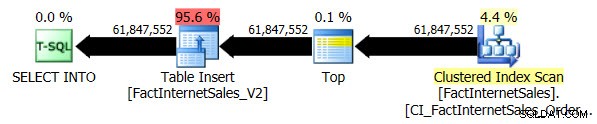
Den seriella Clustered Index Scan tog 2 minuter och 25 sekunder längre än den seriella icke-klustrade Columnstore Index Scan.
Med kompatibilitetsnivå 110 tog frågan 1 minut och 55 sekunder att köra, och följande plan genererades:

I likhet med det parallella icke-klustrade Columnstore Index Scan-testet fördelade den parallella Clustered Index Scan rader över fyra trådar:
Följande tabell sammanfattar dessa två ovannämnda test:
| Skanningstyp | Kompatibilitetsnivå | Parallell SELECT ... INTO | Exekveringsläge | Längd |
|---|---|---|---|---|
| Clustered Index Scan | 100 | Nej | Rad (N/A) | 5:44 |
| Clustered Index Scan | 110 | Ja | Rad (N/A) | 1:55 |
Så då undrade jag över prestandan för ett klustrat kolumnbutiksindex (nytt i SQL Server 2014), så jag släppte de befintliga indexen och skapade ett klustrat kolumnbutiksindex på FactInternetSales-tabellen. Jag var också tvungen att släppa de åtta olika begränsningarna för främmande nyckel som definierats i tabellen innan jag kunde skapa det klustrade kolumnarkivet.
Diskussionen blir något akademisk eftersom jag jämför SELECT ... INTO prestanda på databaskompatibilitetsnivåer som inte erbjöd klustrade columnstore-index i första hand – inte heller gjorde de tidigare testerna för icke-klustrade columnstore-index på databaskompatibilitetsnivå 100 – och ändå är det intressant att se och jämföra de övergripande prestandaegenskaperna.
CREATE CLUSTERED COLUMNSTORE INDEX [CCSI_FactInternetSales] ON [dbo].[FactInternetSales] WITH (DROP_EXISTING = OFF); GO
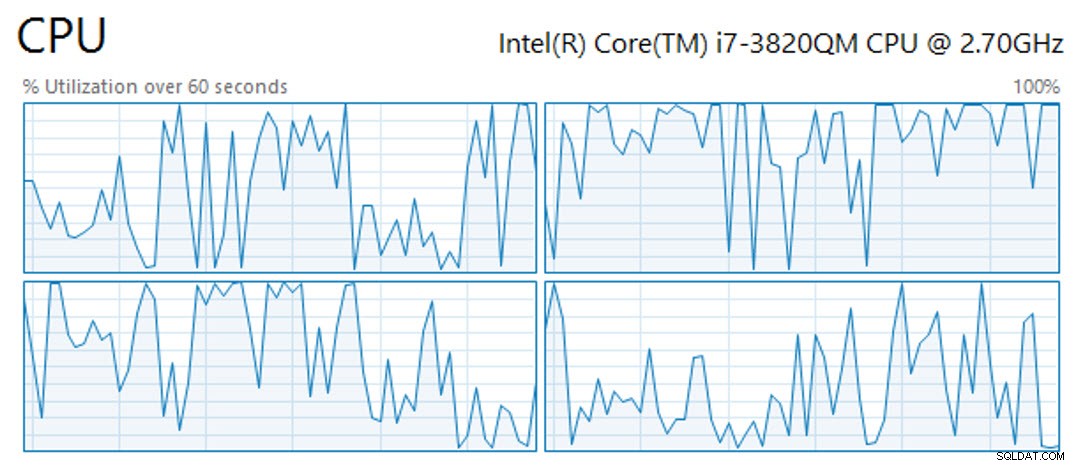
Dessutom tog operationen att skapa det klustrade kolumnbutiksindexet på en 61 847 552 miljoner radtabell 11 minuter och 25 sekunder med fyra tillgängliga vCPU:er (varav operationen utnyttjade dem alla), 4 GB RAM och virtuell gästlagring på OCZ Vertex SSD:er. Under den tiden var processorerna inte kopplade hela tiden, utan visade snarare toppar och dalar (ett urval av 60 sekunders CPU-aktivitet visas nedan):
Efter att det klustrade kolumnlagerindexet skapats körde jag om de två SELECT ... INTO tester. Kompatibilitetsnivå 100-testet tog 3 minuter och 22 sekunder att köra, och planen var seriell som förväntat (jag visar SQL Server Management Studio-versionen av planen sedan den klustrade Columnstore Index Scan, från och med SQL Server 2014 CTP1 , är ännu inte helt igenkänd av Plan Explorer):

Därefter ändrade jag databaskompatibilitetsnivån till 110 och körde testet igen, vilket den här gången tog 1 minut och 11 sekunder och hade följande faktiska exekveringsplan:

Planen fördelade rader över fyra trådar, och precis som det icke-klustrade kolumnlagerindexet var exekveringsläget för den klustrade Columnstore Index Scan rad och inte batch.
Följande tabell sammanfattar alla tester i detta inlägg (i varaktighetsordning, låg till hög):
| Skanningstyp | Kompatibilitetsnivå | Parallell SELECT ... INTO | Exekveringsläge | Längd |
|---|---|---|---|---|
| Icke-klusterad kolumnbutiksindexsökning | 110 | Ja | Rad | 1:07 |
| Clustered Columnstore Index Scan | 110 | Ja | Rad | 1:11 |
| Clustered Index Scan | 110 | Ja | Rad (N/A) | 1:55 |
| Icke-klusterad kolumnbutiksindexsökning | 100 | Nej | Rad | 3:19 |
| Clustered Columnstore Index Scan | 100 | Nej | Rad | 3:22 |
| Clustered Index Scan | 100 | Nej | Rad (N/A) | 5:44 |
Några observationer:
- Jag är inte säker på om skillnaden mellan en parallell
SELECT ... INTOoperation mot ett icke-klustrat kolumnlagerindex kontra klustrat kolumnlagerindex är statistiskt signifikant. Jag skulle behöva göra fler tester, men jag tror att jag skulle vänta med att utföra dem tills RTM. - Jag kan lugnt säga att den parallella
SELECT ... INTOöverträffade de seriella ekvivalenterna avsevärt över ett klustrat index, ett icke-klusterat kolumnlager och ett klustrat kolumnlagerindextest.
Det är värt att nämna att dessa resultat är för en CTP-version av produkten, och mina tester bör ses som något som kan förändras i beteende av RTM – så jag var mindre intresserad av fristående varaktigheter jämfört med hur dessa varaktigheter jämförts mellan seriell och parallell villkor.
Vissa prestandafunktioner kräver betydande omfaktorer – men för SELECT ... INTO förbättring, allt jag behövde göra var att öka databaskompatibilitetsnivån för att börja se fördelarna, vilket definitivt är något jag uppskattar.