"Upprepa inte dig själv"-principen föreslår att du bör minska upprepningen. I veckan stötte jag på ett fall där DRY borde kastas ut genom fönstret. Det finns andra fall också (till exempel skalära funktioner), men det här var ett intressant fall som involverade Bitwise-logik.
Låt oss föreställa oss följande tabell:
CREATE TABLE dbo.CarOrders
(
OrderID INT PRIMARY KEY,
WheelFlag TINYINT,
OrderDate DATE
--, ... other columns ...
);
CREATE INDEX IX_WheelFlag ON dbo.CarOrders(WheelFlag); "WheelFlag"-bitarna representerar följande alternativ:
0 = stock wheels 1 = 17" wheels 2 = 18" wheels 4 = upgraded tires
Så möjliga kombinationer är:
0 = no upgrade 1 = upgrade to 17" wheels only 2 = upgrade to 18" wheels only 4 = upgrade tires only 5 = 1 + 4 = upgrade to 17" wheels and better tires 6 = 2 + 4 = upgrade to 18" wheels and better tires
Låt oss lägga argument åt sidan, åtminstone för nu, om huruvida detta ska packas i en enda TINYINT i första hand, eller lagras som separata kolumner, eller använda en EAV-modell... att fixa designen är en separat fråga. Det här handlar om att jobba med det du har.
För att göra exemplen användbara, låt oss fylla den här tabellen med ett gäng slumpmässiga data. (Och vi antar, för enkelhetens skull, att den här tabellen endast innehåller beställningar som ännu inte har skickats.) Detta kommer att infoga 50 000 rader med ungefär lika fördelning mellan de sex alternativkombinationerna:
;WITH n AS
(
SELECT n,Flag FROM (VALUES(1,0),(2,1),(3,2),(4,4),(5,5),(6,6)) AS n(n,Flag)
)
INSERT dbo.CarOrders
(
OrderID,
WheelFlag,
OrderDate
)
SELECT x.rn, n.Flag, DATEADD(DAY, x.rn/100, '20100101')
FROM n
INNER JOIN
(
SELECT TOP (50000)
n = (ABS(s1.[object_id]) % 6) + 1,
rn = ROW_NUMBER() OVER (ORDER BY s2.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
) AS x
ON n.n = x.n; Om vi tittar på fördelningen kan vi se denna fördelning. Observera att dina resultat kan skilja sig något från mina beroende på objekten i ditt system:
SELECT WheelFlag, [Count] = COUNT(*) FROM dbo.CarOrders GROUP BY WheelFlag;
Resultat:
WheelFlag Count --------- ----- 0 7654 1 8061 2 8757 4 8682 5 8305 6 8541
Låt oss nu säga att det är tisdag och vi har precis fått en leverans av 18" hjul, som tidigare var slut i lager. Det betyder att vi kan tillgodose alla beställningar som kräver 18" hjul – både de som har uppgraderat däck (6), och de som inte gjorde det (2). Så vi *kunde* skriva en fråga som följande:
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag IN (2,6); I verkligheten kan man förstås inte riktigt göra så; vad händer om fler alternativ läggs till senare, som hjullås, livstidsgaranti på hjul eller flera däckalternativ? Du vill inte behöva skriva en serie IN()-värden för varje möjlig kombination. Istället kan vi skriva en BITWISE AND-operation för att hitta alla rader där den andra biten är satt, till exempel:
DECLARE @Flag TINYINT = 2;
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag & @Flag = @Flag; Detta ger mig samma resultat som IN()-frågan, men om jag jämför dem med SQL Sentry Plan Explorer är prestandan helt annorlunda:

Det är lätt att förstå varför. Den första använder en indexsökning för att isolera raderna som uppfyller frågan, med ett filter i kolumnen WheelFlag:
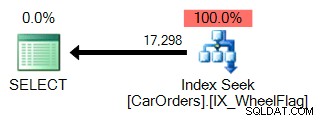

Den andra använder en skanning, i kombination med en implicit omvandling, och fruktansvärt felaktig statistik. Allt på grund av BITWISE AND-operatören:
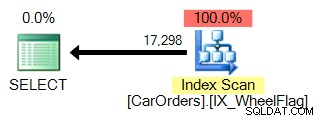


Så vad betyder detta? Kärnan i det säger oss att BITWISE AND-operationen inte är sargbar .
Men allt hopp är inte ute.
Om vi bortser från DRY-principen för ett ögonblick kan vi skriva en lite effektivare fråga genom att vara lite redundant för att dra nytta av indexet på WheelFlag-kolumnen. Om vi antar att vi är ute efter något WheelFlag-alternativ över 0 (ingen uppgradering alls), kan vi skriva om frågan på detta sätt och tala om för SQL Server att WheelFlag-värdet måste vara minst samma värde som flaggan (vilket eliminerar 0 och 1 ), och sedan lägga till den kompletterande informationen att den också måste innehålla den flaggan (och därmed eliminera 5).
SELECT OrderID FROM dbo.CarOrders WHERE WheelFlag >= @Flag AND WheelFlag & @Flag = @Flag;
>=-delen av denna klausul täcks uppenbarligen av BITWISE-delen, så det är här vi bryter mot DRY. Men eftersom den här satsen som vi har lagt till är sargbar, ger en omplacering av BITWISE AND-operationen till ett sekundärt sökvillkor fortfarande samma resultat, och den övergripande frågan ger bättre prestanda. Vi ser ett liknande indexsök till den hårdkodade versionen av frågan ovan, och även om uppskattningarna är ännu längre bort (något som kan behandlas som ett separat problem), är läsningarna fortfarande lägre än med BITWISE AND-operationen enbart:

Vi kan också se att ett filter används mot indexet, vilket vi inte såg när vi bara använde BITWISE AND-operationen:

Slutsats
Var inte rädd för att upprepa dig själv. Det finns tillfällen då denna information kan hjälpa optimeraren; även om det kanske inte är helt intuitivt att *lägga till* kriterier för att förbättra prestanda, är det viktigt att förstå när ytterligare klausuler hjälper till att förminska data för slutresultatet snarare än att göra det "lätt" för optimeraren att hitta de exakta raderna på egen hand.