För alla större RDBMS-produkter, Primärnyckel i SQL-begränsningar har en viktig roll. De identifierar posterna som finns i en tabell unikt. Därför bör vi välja Primary Keys-server noggrant under tabelldesignen för att förbättra prestandan.
I den här artikeln kommer vi att lära oss vad en primärnyckelbegränsning är. Vi kommer också att se hur du skapar, ändrar eller släpper begränsningar för primärnycklar.
SQL-serverbegränsningar
I SQL Server, Begränsningar är regler som reglerar inmatning av uppgifterna i de nödvändiga kolumnerna. Restriktioner tvingar fram exaktheten hos data och hur dessa data matchar affärskrav. Dessutom gör de data tillförlitliga för slutanvändare. Det är därför det är viktigt att identifiera korrekta begränsningar under designfasen av databasen eller tabellschemat.
SQL Server stöder följande Begränsningstyper för att upprätthålla dataintegritet:
Primära nyckelbegränsningar skapas på en enda kolumn eller kombination av kolumner för att framtvinga posternas unika karaktär och identifiera posterna snabbare. De inblandade kolumnerna ska inte innehålla NULL-värden. Därför bör egenskapen NOT NULL definieras i kolumnerna.
Begränsningar för främmande nyckel skapas på en enskild kolumn eller en kombination av kolumner för att skapa en relation mellan två tabeller och genomdriva data som finns i en tabell till en annan. I idealfallet hänvisar tabellkolumner där vi måste genomdriva data med Foreign Key-begränsningar till Source-tabellen med en primärnyckel i SQL eller Unique Key-begränsning. Med andra ord kan endast de poster som är tillgängliga i källtabellens primära eller unika nyckelbegränsningar infogas eller uppdateras till destinationstabellen.
Unika nyckelbegränsningar skapas på en enda kolumn eller kombination av kolumner för att framtvinga unikhet över kolumndata. De liknar Primärnyckelns begränsningar med en enda ändring. Skillnaden mellan Primary Key och Unique Key Constraints är att de senare kan skapas på Nullable kolumner och tillåt en NULL-värdespost i dess kolumn.
Kontrollera begränsningar skapas på en enda kolumn eller kombination av kolumner genom att begränsa de accepterade datavärdena för de involverade kolumnerna via ett logiskt uttryck. Det är skillnad mellan främmande nyckel och kontrollbegränsningar. Den främmande nyckeln upprätthåller dataintegritet genom att kontrollera data från en annan tabells primära eller unika nyckel. Men kontrollbegränsningen gör detta genom att använda ett logiskt uttryck.
Låt oss nu gå igenom de primära nyckelbegränsningarna.
Primärnyckelbegränsning
Primary Key Constraint tvingar fram unikhet på en enda kolumn eller kombination av kolumner utan några NULL-värden inuti de involverade kolumnerna.
För att framtvinga unikhet skapar SQL Server ett unikt klustrade index på kolumnerna där primärnycklar skapades. Om det finns några befintliga klustrade index, skapar SQL Server ett unikt icke-klustrat index på tabellen för den primära nyckeln.
Låt oss se hur vi skapar, ändrar, släpper, inaktiverar eller aktiverar primärnycklar på en tabell med hjälp av T-SQL-skript.
Skapa en primärnyckel
Vi kan skapa primärnycklar på en tabell antingen under tabellskapandet eller efter det. Syntaxen varierar något för dessa scenarier.
Skapande av den primära nyckeln under tabellskapandet
Syntaxen är nedan:
CREATE TABLE SCHEMA_NAME.TABLE_NAME
(
COLUMN1 datatype [ NULL | NOT NULL ] PRIMARY KEY,
COLUMN2 datatype [ NULL | NOT NULL ],
...
);
Låt oss skapa en tabell med namnet Anställda i HumanResources schema för teständamål med skriptet nedan:
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL PRIMARY KEY,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
Vi har framgångsrikt skapat HumanResources.Employees tabellen på AdventureWorks databas:
Vi kan se att det klustrade indexet skapades i tabellen som matchar det primära nyckelnamnet som markerats ovan.
Låt oss släppa tabellen med skriptet nedan och försök igen med den nya syntaxen.
DROP TABLE HumanResources.EmployeesAtt skapa den primära nyckeln i SQL i en tabell med det användardefinierade primärnyckelnamnet PK_Anställda , använd nedanstående syntax:
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY (Employee_Id)
);
Vi har skapat HumanResources.Employees tabell med Primärnyckelnamnet PK_Anställda :
Skapande av den primära nyckeln efter att tabellen skapats
Ibland glömmer utvecklare eller DBA:er de primära nycklarna och skapar tabeller utan dem. Men det är möjligt att skapa en primärnyckel på befintliga tabeller.
Låt oss släppa HumanResources.Employees tabell och återskapa den med skriptet nedan:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
När du kör det här skriptet framgångsrikt kan vi se HumanResources.Employees tabell skapad utan några primära nycklar eller index:

För att skapa en primärnyckel som heter PK_Anställda i den här tabellen, använd nedanstående syntax:
ALTER TABLE <schema_name>.<table_name>
ADD CONSTRAINT <constraint_name> PRIMARY KEY ( <column_name> );
Utförande av detta skript skapar den primära nyckeln på vårt bord:
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
Skapa primärnyckel på flera kolumner
I våra exempel skapade vi primärnycklar på enstaka kolumner. Om vi vill skapa primärnycklar på flera kolumner behöver vi en annan syntax.
För att lägga till flera kolumner som en del av den primära nyckeln behöver vi helt enkelt lägga till kommaseparerade värden för kolumnnamnen som ska vara en del av den primära nyckeln.
Primärnyckel under tabellskapandet
CREATE TABLE HumanResources.Employees
( First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY (First_Name, Last_Name)
);
GO
Primärnyckel efter att tabellen skapats
CREATE TABLE HumanResources.Employees
( First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (First_Name, Last_Name);
GO
Släpp den primära nyckeln
För att släppa den primära nyckeln använder vi syntaxen nedan. Det spelar ingen roll om den primära nyckeln var på en eller flera kolumner.
ALTER TABLE <schema_name>.<table_name>
DROP CONSTRAINT <constraint_name> ;
Att släppa den primära nyckelbegränsningen på HumanResources.Employees tabell, använd skriptet nedan:
ALTER TABLE HumanResources.Employees
DROP CONSTRAINT PK_Employees;
Om du släpper den primära nyckeln tas både de primära nycklarna och klustrade eller icke-klustrade index som skapats tillsammans med skapandet av den primära nyckeln bort:
Ändra den primära nyckeln
I SQL Server finns det inga direkta kommandon för att ändra primärnycklar. Vi måste släppa en befintlig primärnyckel och återskapa den med nödvändiga ändringar. Därför är stegen för att ändra den primära nyckeln:
- Släpp en befintlig primär nyckel.
- Skapa nya primära nycklar med nödvändiga ändringar.
Inaktivera/aktivera primärnyckel
När du utför bulkbelastning på en tabell med många poster, inaktivera den primära nyckeln och aktivera den igen för bättre prestanda. Stegen är nedan:
Inaktivera den befintliga primärnyckeln med syntaxen nedan:
ALTER INDEX <index_name> ON <schema_name>.<table_name> DISABLE;För att inaktivera den primära nyckeln på HumanResources.Employees tabell, skriptet är:
ALTER INDEX PK_Employees ON HumanResources.Employees
DISABLE;
Aktivera befintliga primärnycklar som är i inaktiverat tillstånd. Vi måste bygga om indexet med syntaxen nedan:
ALTER INDEX <index_name> ON <schema_name>.<table_name> REBUILD;För att aktivera den primära nyckeln på HumanResources.Employees tabell, använd följande skript:
ALTER INDEX PK_Employees ON HumanResources.Employees
REBUILD;
Myterna om den primära nyckeln
Många människor blir förvirrade över myterna nedan relaterade till primärnycklar i SQL Server.
- Tabell med primärnyckel är inte en heaptabell
- Primära nycklar har det klustrade indexet och data sorterade i fysisk ordning
Låt oss förtydliga dem.
Tabell med primärnyckel är inte en heaptabell
Innan vi dyker djupare, låt oss revidera definitionen av primärnyckeln och högtabellen.
Den primära nyckeln skapar ett klustrade index på en tabell om det inte finns några andra klustrade index tillgängliga där. En tabell utan ett klusterindex blir en heaptabell.
Baserat på dessa definitioner kan vi förstå att den primära nyckeln skapar ett klustrade index endast om det inte finns några andra klustrade index på tabellen. Om det finns några befintliga klustrade index kommer skapandet av den primära nyckeln att skapa ett icke-klustrat index på tabellen som matchar den primära nyckeln.
Låt oss verifiera detta genom att ta bort HumanResources.Employees Tabell och återskapa den:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (Employee_Id)
);
GO
Vi kan specificera alternativet INTE CLUSTERED index för den primära nyckeln (se ovan). En tabell skapades med ett unikt, icke-klustrat index för de primära nyckel-PK_anställda .
Därför är den här tabellen en heaptabell även om den har en primärnyckel.
Låt oss se om SQL Server kan skapa ett icke-klustrat index för den primära nyckeln om vi inte anger nyckelordet Icke-klustrade under skapandet av den primära nyckeln. Använd skriptet nedan:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
-- Create Clustered Index on Employee_Id column before creating Primary Key
CREATE CLUSTERED INDEX IX_Employee_ID ON HumanResources.Employees(First_Name, Last_Name);
GO
-- Create Primary Key on Employee_Id column
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
GO
Här har vi skapat ett klustrat index separat innan den primära nyckeln skapades. Och en tabell kan bara ha ett klustrat index. Därför har SQL Server skapat den primära nyckeln som ett unikt, icke-klustrat index. Just nu är tabellen inte en heaptabell eftersom den har ett klustrat index.
Om jag ändrade mig och släppte det klustrade indexet på First_Name och Efternamn kolumner med skriptet nedan:
DROP INDEX IX_Employee_ID ON HumanResources.Employees;
GO
Vi har tagit bort det klustrade indexet framgångsrikt. HumanResources.Employees table är en heap-tabell även om vi har en primärnyckel tillgänglig i tabellen:
Detta rensar myten att en tabell med en primärnyckel kan vara en heaptabell om det inte finns några klustrade index tillgängliga på tabellen.
Primärnyckel kommer att ha ett klusterindex och data sorterade i fysisk ordning
Som vi lärde oss från föregående exempel, kan en primärnyckel i SQL ha ett icke-klustrat index. I så fall skulle posterna inte sorteras i fysisk ordning.
Låt oss verifiera tabellen med det klustrade indexet på en primärnyckel. Vi ska kontrollera om den sorterar posterna i fysisk ordning.
Återskapa HumanResources.Employees tabell med minimala kolumner och IDENTITY-egenskapen borttagen för Employee_ID kolumn:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL
);
GO
Nu när vi har skapat tabellen utan den primära nyckeln eller ett klustrat index, kan vi INFOGA 3 poster i en osorterad ordning för Employee_Id kolumn:
INSERT INTO HumanResources.Employees ( Employee_Id, First_Name, Last_Name)
VALUES
(3, 'Antony', 'Mark'),
(1, 'James', 'Cameroon'),
(2, 'Jackie', 'Chan')

Låt oss välja bland HumanResources.Employees tabell:
SELECT *
FROM HumanResources.Employees
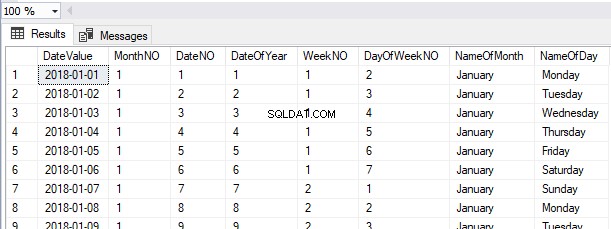
Vi kan se posterna hämtade i samma ordning som posterna som infogats från Heap-tabellen för närvarande.
Låt oss skapa en primärnyckel på denna Heap-tabell och se om den har någon inverkan på SELECT-satsen:
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
GO
SELECT *
FROM HumanResources.Employees

Efter skapandet av den primära nyckeln kan vi se att SELECT-satsen hämtade poster i stigande ordning av Employee_Id (kolumnen Primär nyckel). Det beror på det klustrade indexet på Employee_Id .
Om en primärnyckel skapas med alternativet icke-klustrade, kommer tabelldata inte att sorteras baserat på kolumnen Primärnyckel.
Om längden på en enskild post i en tabell överstiger 4030 byte, kan endast en post passa en sida. Det klustrade indexet säkerställer att sidorna är i fysisk ordning.
En sida är en grundläggande lagringsenhet i SQL Server-datafiler med en storlek på 8 KB (8192 byte). Endast 8060 byte av den enheten är användbara för datalagring. Det återstående beloppet är för sidrubriker och andra interna delar.
Tips för att välja primära nyckelkolumner
- Kolumner för heltalsdatatyp är bäst lämpade för primära nyckelkolumner eftersom de upptar mindre lagringsstorlekar och kan hjälpa till att hämta data snabbare.
- Eftersom primära nyckelkolumner har ett klustrat index som standard, använd alternativet IDENTITY på heltalsdatatypkolumner för att få nya värden genererade i inkrementell ordning.
- Istället för att skapa en primärnyckel på flera kolumner skapar du en ny heltalskolumn med egenskapen IDENTITY definierad. Skapa också ett unikt index på flera kolumner som ursprungligen identifierades för bättre prestanda.
- Försök att undvika kolumner med strängdatatyp som varchar, nvarchar, etc. Vi kan inte garantera sekventiell ökning av data för dessa datatyper. Det kan påverka INSERT-prestandan på dessa kolumner.
- Välj kolumner där värden inte uppdateras som primärnycklar. Om t.ex. Primärnyckelns värde kan ändras från 5 till 1000, måste B-trädet som är associerat med det klustrade indexet uppdateras vilket resulterar i en liten prestandaförsämring.
- Om kolumner för strängdatatyp måste väljas som primärnyckelkolumner, se till att längden på varchar- eller nvarchar-datatypkolumner förblir liten för bättre prestanda.
Slutsats
Vi har gått igenom grunderna för begränsningar tillgängliga i SQL Server. Vi undersökte primärnyckelns begränsningar i detalj och lärde oss hur man skapar, släpper, modifierar, inaktiverar och återskapar primärnycklar. Dessutom har vi klargjort några populära myter kring primärnycklar med exempel.
Håll utkik efter nästa artikel!