För att svara på din fråga varför SQL Server gör detta, så är svaret att frågan inte kompileras i en logisk ordning, varje påstående kompileras på sina egna meriter, så när frågeplanen för din select-sats genereras, kommer optimeraren vet inte att @val1 och @Val2 kommer att bli 'val1' respektive 'val2'.
När SQL Server inte känner till värdet måste den göra en bästa gissning om hur många gånger den variabeln kommer att visas i tabellen, vilket ibland kan leda till suboptimala planer. Min huvudsakliga poäng är att samma fråga med olika värden kan generera olika planer. Föreställ dig detta enkla exempel:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 991 1
FROM sys.all_objects a
UNION ALL
SELECT TOP 9 ROW_NUMBER() OVER(ORDER BY a.object_id) + 1
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Allt jag har gjort här är att skapa en enkel tabell och lägga till 1000 rader med värdena 1-10 för kolumnen val 1 visas dock 991 gånger och de andra 9 bara en gång. Utgångspunkten är denna fråga:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 1;
Skulle vara effektivare att bara skanna hela tabellen än att använda indexet för en sökning och sedan göra 991 bokmärkessökningar för att få värdet för Filler , dock med endast en rad följande fråga:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 2;
kommer att vara effektivare att göra en indexsökning och en enda bokmärkessökning för att få värdet för Filler (och att köra dessa två frågor kommer att ratificera detta)
Jag är ganska säker på att gränsen för en sökning och bokmärkessökning faktiskt varierar beroende på situationen, men den är ganska låg. Med hjälp av exempeltabellen, med lite försök och fel, upptäckte jag att jag behövde Val kolumn för att ha 38 rader med värdet 2 innan optimeraren gick för en fullständig tabellsökning över en indexsökning och bokmärkessökning:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
DECLARE @I INT = 38;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP (991 - @i) 1
FROM sys.all_objects a
UNION ALL
SELECT TOP (@i) 2
FROM sys.all_objects a
UNION ALL
SELECT TOP 8 ROW_NUMBER() OVER(ORDER BY a.object_id) + 2
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
SELECT COUNT(Filler), COUNT(*)
FROM #T
WHERE Val = 2;
Så för det här exemplet är gränsen 3,7 % av matchande rader.
Eftersom frågan inte vet hur många rader som matchar när du använder en variabel måste den gissa, och det enklaste sättet är att ta reda på det totala antalet rader och dividera detta med det totala antalet distinkta värden i kolumnen, så i det här exemplet det uppskattade antalet rader för WHERE val = @Val är 1000 / 10 =100. Den faktiska algoritmen är mer komplex än så här, men för t.ex. Så när vi tittar på genomförandeplanen för:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
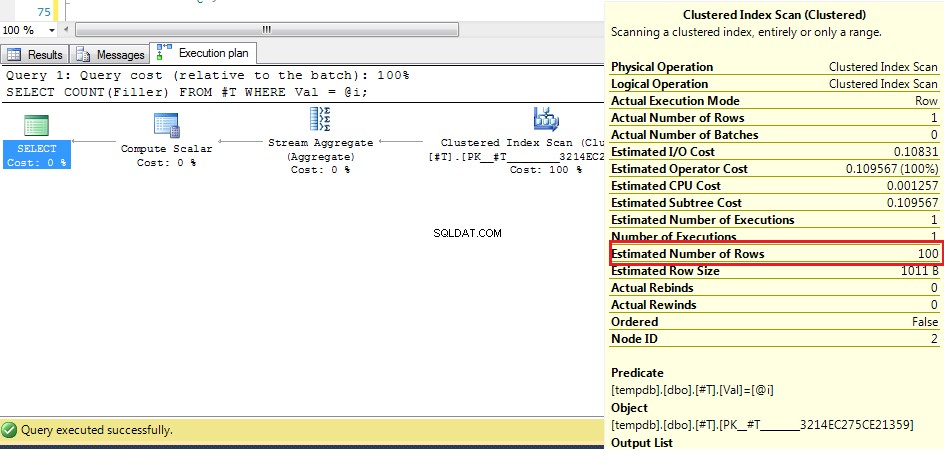
Vi kan se här (med originaldata) att det uppskattade antalet rader är 100, men de faktiska raderna är 1. Från de föregående stegen vet vi att med fler än 38 rader kommer optimeraren att välja en klustrad indexskanning över ett index sök, så eftersom den bästa gissningen för antalet rader är högre än detta, är planen för en okänd variabel en klustrad indexskanning.
Bara för att ytterligare bevisa teorin, om vi skapar tabellen med 1000 rader med nummer 1-27 jämnt fördelade (så det beräknade radantalet kommer att vara ungefär 1000 / 27 =37,037)
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 27 ROW_NUMBER() OVER(ORDER BY a.object_id)
FROM sys.all_objects a;
INSERT #T (val)
SELECT TOP 973 t1.Val
FROM #T AS t1
CROSS JOIN #T AS t2
CROSS JOIN #T AS t3
ORDER BY t2.Val, t3.Val;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Kör sedan frågan igen, vi får en plan med en indexsökning:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
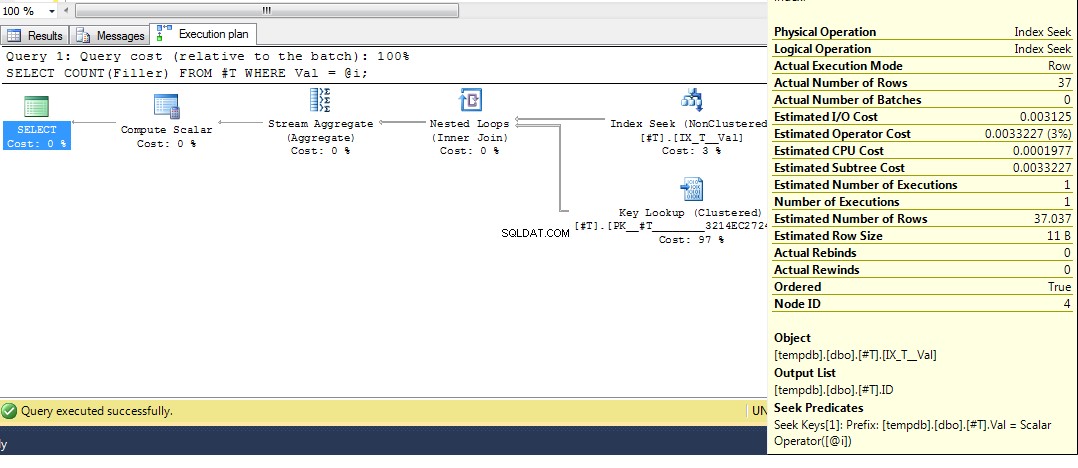
Så förhoppningsvis täcker det ganska uttömmande varför du får den planen. Nu antar jag att nästa fråga är hur man tvingar fram en annan plan, och svaret är att använda frågetipset OPTION (RECOMPILE) , för att tvinga frågan att kompilera vid körning när värdet på parametern är känt. Återgå till originaldata, där den bästa planen för Val = 2 är en uppslagning, men att använda en variabel ger en plan med en indexskanning, vi kan köra:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
GO
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i
OPTION (RECOMPILE);
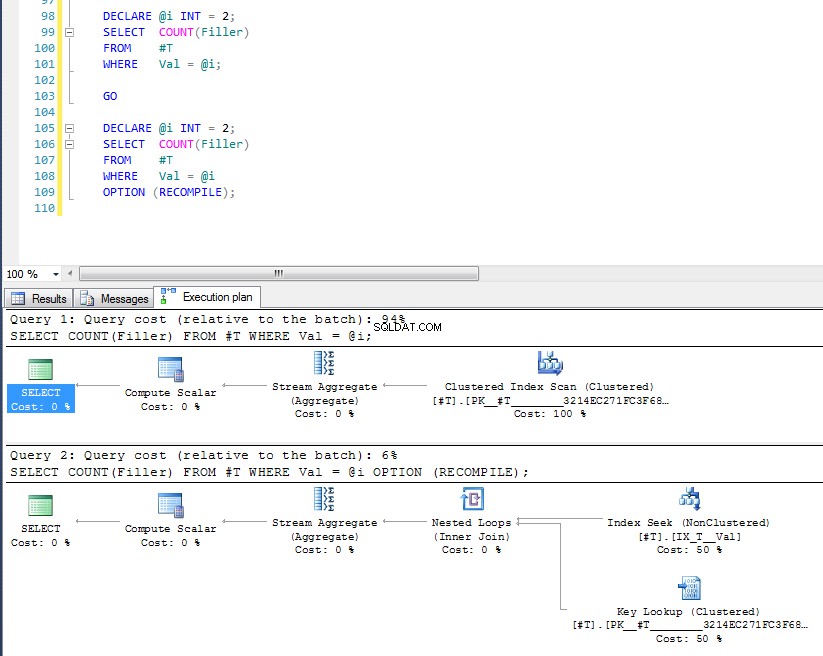
Vi kan se att den senare använder indexsök och nyckeluppslag eftersom den har kontrollerat variabelns värde vid körningstidpunkten och den mest lämpliga planen för det specifika värdet väljs. Problemet med OPTION (RECOMPILE) är det betyder att du inte kan dra fördel av cachade frågeplaner, så det tillkommer en extra kostnad för att kompilera frågan varje gång.