I den här artikeln kommer vi att prata om SQL Server Checkpoints.
För att förbättra prestandan tillämpar SQL Server ändringar på databassidor i minnet. Ofta kallas detta minne buffertcache eller buffertpool. SQL Server spolar inte dessa sidor till disken efter varje ändring. Istället utför databasmotorn kontrollpunkter på varje databas då och då. KONTROLLPUNKT operation skriver de smutsiga sidorna (aktuella modifierade sidor i minnet) och skriver även detaljer om transaktionsloggen.
SQL Server stöder fyra typer av kontrollpunkter:
1. Automatisk — Den här typen av kontrollpunkter förekommer bakom kulisserna och beror på serverns konfigurationer med återställningsintervall. Värdet mäts i minuter och standardvärdet är 1 minut (kan inte ställas lägre). Kontrollpunkten kommer att slutföras inom den tid som minimerar påverkan på prestanda.
EXEC sp_configure 'recovery interval', 'seconds'
Under SIMPLE-återställningsmodellen utlöses också en automatisk kontrollpunkt när transaktionsloggen är 70 % full.
2. Indirekt — Den här typen av kontrollpunkter förekommer också bakom kulisserna enligt de användarspecificerade databasåterställningstidsinställningarna. Från och med SQL Server 2016 CTP2 är standardvärdet för denna typ av kontrollpunkt 1 minut. Det betyder att en databas kommer att använda indirekta kontrollpunkter. För äldre SQL Server-versioner är standardvärdet 0. Detta betyder att en databas kommer att använda automatiska kontrollpunkter, vars frekvens beror på återställningsintervallinställningen för SQL Server-instansen. Microsoft rekommenderar 1 minut för de flesta system.
ALTER DATABASE … SET TARGET_RECOVERY_TIME =
target_recovery_time { SECONDS | MINUTES }
När du ställer in detta, överväg det underliggande I/O-undersystemets kapacitet. Kan vara vettigt att ställa in detta lägre för snabbare I/O-undersystem (t.ex. SSD-enheter). Var försiktig, den här inställningen kvarstår genom säkerhetskopiering och återställning, så återställning till långsammare hårdvara kan orsaka prestandaproblem på grund av för mycket I/O-belastning.
3. Manual — Uppstår när kommandot T-SQL CHECKPOINT körs.
CHECKPOINT [ checkpoint_duration ]
checkpoint_duration är ett heltal som används för att definiera hur lång tid en kontrollpunkt ska slutföras. Denna parameter styr också hur många resurser som tilldelas kontrollpunktsoperationen. Om parametern inte anges kommer kontrollpunkten att slutföras inom den tid som minimerar påverkan på prestandan.
4. Internt — Vissa SQL Server-operationer utfärdar den här typen av kontrollpunkter för att säkerställa att diskavbildningar matchar det aktuella transaktionsloggtillståndet. Det här är kontrollpunkter som utförs när en viss operation äger rum:
- En datafil läggs till eller tas bort
- En databasavstängning inträffar (av någon anledning)
- En säkerhetskopia eller en ögonblicksbild av databasen skapas
- Ett DBCC-kommando körs som skapar en dold databasögonblicksbild (eller t.ex. DBCC_CHECKDB, DBCC_CHECKTABLE).
Varför är kontrollpunkter användbara?
Kontrollpunkter minskar tiden för att återställa kraschar. Detta händer eftersom datafilsidor inte skrivs till disken samtidigt som loggposterna. Det finns datafilsidor i minnet som är mer uppdaterade än datafilsidor på disken.
Checkpoints reducerar I/O till disk och förbättrar prestanda. Anledningen till att datafilsidor inte skrivs till disken vid den tidpunkt då transaktionen genomförs är för att minska antalet I/O-operationer. Föreställ dig flera tusentals UPPDATERA transaktioner till en enda datasida. Det är mer effektivt att skriva en datasida till disken bara en gång, under en kontrollpunkt, snarare än efter varje ändring.
Rena och smutsiga sidor
Buffertpoolen har ett antal datasidor i minnet. Det finns två typer av datasidor:ren och smutsig . En ren sida är en sida som inte har ändrats sedan den senast lästes från disk eller skrevs till disk. En smutsig sida är en sida som har ändrats och ändringarna har inte skrivits till disken. Kontrollpunkter hänvisar till "smutsiga sidor".
Informationen om sidan kan ses med sys.dm_os_buffer_descriptors . Låt oss se vad den här funktionen returnerar:
SELECT * FROM sys.dm_os_buffer_descriptors dobd; GO
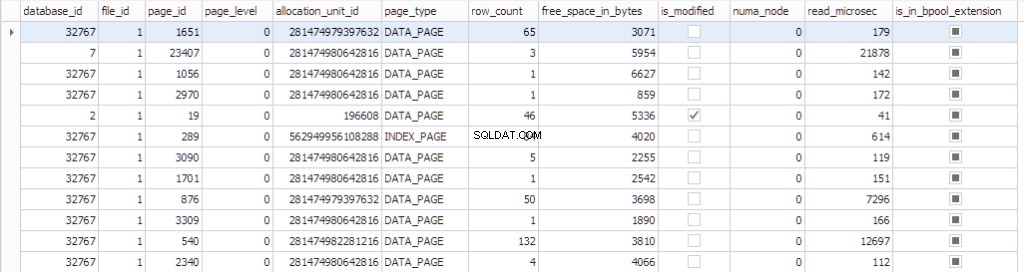
Varje sida har en kontrollstruktur kopplad till sig som spårar sidstatus:
- En databas som har datdabase_id 32767 är en skrivskyddad resursdatabas som innehåller alla systemobjekt.
- fil_id , page_id , allocation_unit_id den sidan tillhör.
- Vilken typ av sida är det:antingen datasida eller indexsida.
- Antalet rader på sidan.
- Det lediga utrymmet på sidan
- Om sidan är smutsig eller inte
- Numa_noden som den specifika sidan tillhör
- Lite information om algoritmen Senast använde
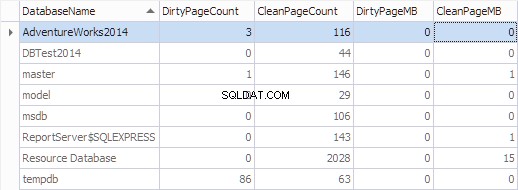
Låt oss sammanställa denna information efter databas med hjälp av följande kod:
SELECT
*,
[DirtyPageCount] * 8 / 1024 AS [DirtyPageMB],
[CleanPageCount] * 8 / 1024 AS [CleanPageMB]
FROM (SELECT
(CASE
WHEN ([database_id] = 32767) THEN N'Resource Database'
ELSE DB_NAME([database_id])
END) AS [DatabaseName],
SUM(CASE
WHEN ([is_modified] = 1) THEN 1
ELSE 0
END) AS [DirtyPageCount],
SUM(CASE
WHEN ([is_modified] = 1) THEN 0
ELSE 1
END) AS [CleanPageCount]
FROM sys.dm_os_buffer_descriptors
GROUP BY [database_id]) AS [buffers]
ORDER BY [DatabaseName]
GO
Kontrollpunktsmekanism
När kontrollpunkten inträffar skriver den alla smutsiga sidor till disken. Sidor markerade som smutsiga så snart de har några ändringar. Det spelar ingen roll om transaktionen som gjorde ändringen är genomförd eller oengagerad vid tidpunkten för kontrollpunkten. Efter att sidorna har skrivits till disken rensas den "smutsiga" biten. När kontrollpunkten inträffar sker följande åtgärder:
- En ny loggpost indikerar början på en kontrollpunkt
- Ytterligare loggposter visas med en kontrollpunktsinformation (som tillståndet för transaktionsloggen vid den tidpunkt då kontrollpunkten startas)
- Alla smutsiga sidor skrivs till disken
- Markera LSN för kontrollpunkten på databasens startsida (i dbi_checkptLSN), detta är avgörande för kraschåterställning
- Om SIMPLE återställningsmodell används, försök att rensa loggen
- En sista loggpost indikerar att kontrollpunkten är klar
Det är möjligt för kontrollpunkter för flera databaser att ske parallellt. SQL Server 2000 var begränsad till en kontrollpunkt åt gången. När bufferthanteraren skriver en sida söker den efter angränsande smutsiga sidor som kan inkluderas i en enda samla-skriv-operation. Buffertpoolen kommer också att försöka se till att den inte överbelasta I/O-undersystemet. Den håller reda på hur lång tid det tar för I/O att slutföra. Om skrivlatensen överstiger 20 ms under kontrollpunkten, stryper den sig själv. Under avstängningen ökar strypningströskeln till 100 ms. Du kan hitta en mer detaljerad förklaring här. Du kan använda odokumenterat "-kXX" startalternativ för att ställa in kontrollpunktens I/O-hastighet på XX MB/s.
När datafilsidan skrivs till disken av en kontrollpunkt, garanterar skrivningsloggning att alla loggposter som påverkar den sidan måste skrivas till transaktionsloggen på disken först. Alla loggposter till och med den sista som påverkade sidan skrivs ut, oavsett vilken transaktion de ingår i. Loggposter skrivs ut på tre sätt:
- När en transaktion genomförs eller avbryts
- När datafilsidan skrivs till disken
- När ett loggblock når den maximala storleken på 60 kB och tvångsavslutas
Kontrollpunktsloggpost
Kontrollpunkter skriver flera loggposter i transaktionsloggen:
- LOP_BEGIN_CKPT — anger att kontrollpunkten startade
- LOP_XACT_CKPT med NULL-kontext (endast om det finns obegångna transaktioner vid den tidpunkt då kontrollpunkten startade) — innehåller en räkning av antalet icke-åtagande transaktioner. Den listar också LSN:erna för LOP_BEGIN_XACT-loggposterna för de ej genomförda transaktionerna.
- LOP_BEGIN_CKPT med kontexten LOP_BOOT_PAGE_CKPT (endast SQL Server 2012) — anger att startsidan har uppdaterats.
- LOP_END_CKPT — betecknar slutet på kontrollpunkten.
Kontrollpunktsövervakning
Det kan vara användbart att korrelera kontrollpunkter som inträffar med toppar i I/O så att ändringar kan göras i den specifika databasen (för I/O-undersystemet) för att lindra I/O-spiken om den överbelastas I/O-undersystemet. Till exempel att göra mer frekventa, manuella kontrollpunkter eller konfigurera ett lägre återställningsintervall på SQL Server 2012 med indirekta kontrollpunkter. Detta kommer att producera en mer konstant I/O-belastning utan höga toppar som överbelastar I/O-delsystemet. Men grundorsaken kan vara att mer I/O utförs på grund av en förändring någonstans, så acceptera inte bara en plötslig ökning av kontrollpunktsaktivitet utan att undersöka varför det inträffade.
Bufferthanteraren/Checkpoint-sidor/sek-räknaren är inte databasspecifik så att identifiera vilken databas som är involverad kräver spårningsflaggor eller utökade händelser.
Spårningsflagga 3502 skriver meddelanden till felloggen om vilken databaskontrollpunkt som sker för.
Spårningsflagga 3504 skriver mer detaljerad information om hur många sidor som skrevs ut och den genomsnittliga skrivfördröjningen.
Dessa spårflaggor är säkra att använda i produktionen för en begränsad kalkhalt. Allt de gör är att skriva ut meddelanden i felloggen.
Om du vill använda utökade händelser finns det två händelser du kan använda:checkpoint_begin och checkpoint_end.
Sammanfattning
I den här artikeln har vi pratat om kontrollpunkter i SQL Server — huvudmekanismen för att skriva datafilsidor till disk efter att de har ändrats.