Du använder arvet (även känt i entitetsrelationsmodellering som "underklass" eller "kategori"). I allmänhet finns det tre sätt att representera det i databasen:
- "Alla klasser i en tabell": Ha bara en tabell som "täcker" föräldern och alla underordnade klasser (d.v.s. med alla överordnade och underordnade kolumner), med en CHECK-begränsning för att säkerställa att rätt delmängd av fält inte är NULL (dvs. två olika barn "blandar inte").
- "Betongklass per tabell": Ha olika bord för varje barn, men inget föräldrabord. Detta kräver att föräldrarnas relationer (i ditt fall Inventory <- Storage) upprepas hos alla barn.
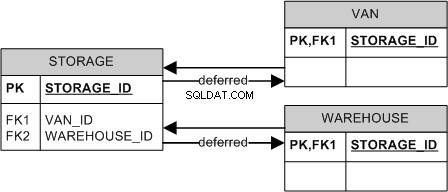
- "Klass per bord": Att ha ett föräldrabord och ett separat bord för varje barn, vilket är vad du försöker göra. Detta är renast, men kan kosta en del prestanda (främst när du ändrar data, inte så mycket när du frågar eftersom du kan gå med direkt från barnet och hoppa över föräldern).
Jag föredrar vanligtvis den 3:e metoden, men upprätthåller både närvaro och exklusiviteten av ett barn på applikationsnivå. Att tillämpa båda på databasnivå är lite besvärligt, men kan göras om DBMS stöder uppskjutna begränsningar. Till exempel:
CHECK (
(
(VAN_ID IS NOT NULL AND VAN_ID = STORAGE_ID)
AND WAREHOUSE_ID IS NULL
)
OR (
VAN_ID IS NULL
AND (WAREHOUSE_ID IS NOT NULL AND WAREHOUSE_ID = STORAGE_ID)
)
)
Detta kommer att upprätthålla både exklusiviteten (på grund av CHECK). ) och närvaron (på grund av kombinationen av CHECK och FK1 /FK2 ) av barnet.
Tyvärr stöder inte MS SQL Server uppskjutna begränsningar, men du kanske kan "gömma" hela operationen bakom lagrade procedurer och förbjuda klienter att modifiera tabellerna direkt.
Bara exklusiviteten kan upprätthållas utan uppskjutna begränsningar:
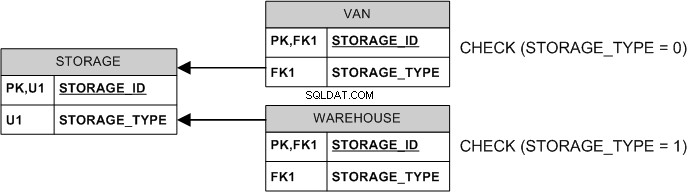
STORAGE_TYPE är en typdiskriminator, vanligtvis ett heltal för att spara utrymme (i exemplet ovan är 0 och 1 "kända" för din applikation och tolkas därefter).
VAN.STORAGE_TYPE och WAREHOUSE.STORAGE_TYPE kan beräknas (aka. "beräknade") kolumner för att spara lagring och undvika behovet av CHECK s.
--- REDIGERA ---
Beräknade kolumner skulle fungera under SQL Server så här:
CREATE TABLE STORAGE (
STORAGE_ID int PRIMARY KEY,
STORAGE_TYPE tinyint NOT NULL,
UNIQUE (STORAGE_ID, STORAGE_TYPE)
);
CREATE TABLE VAN (
STORAGE_ID int PRIMARY KEY,
STORAGE_TYPE AS CAST(0 as tinyint) PERSISTED,
FOREIGN KEY (STORAGE_ID, STORAGE_TYPE) REFERENCES STORAGE(STORAGE_ID, STORAGE_TYPE)
);
CREATE TABLE WAREHOUSE (
STORAGE_ID int PRIMARY KEY,
STORAGE_TYPE AS CAST(1 as tinyint) PERSISTED,
FOREIGN KEY (STORAGE_ID, STORAGE_TYPE) REFERENCES STORAGE(STORAGE_ID, STORAGE_TYPE)
);
-- We can make a new van.
INSERT INTO STORAGE VALUES (100, 0);
INSERT INTO VAN VALUES (100);
-- But we cannot make it a warehouse too.
INSERT INTO WAREHOUSE VALUES (100);
-- Msg 547, Level 16, State 0, Line 24
-- The INSERT statement conflicted with the FOREIGN KEY constraint "FK__WAREHOUSE__695C9DA1". The conflict occurred in database "master", table "dbo.STORAGE".
Tyvärr kräver SQL Server för en beräknad kolumn som används i en främmande nyckeln för att PERSISTERAS. Andra databaser kanske inte har denna begränsning (t.ex. Oracles virtuella kolumner), vilket kan spara lite lagringsutrymme.