Tillägg: SQL Server 2012 visar en viss förbättrad prestanda på detta område men verkar inte ta itu med de specifika problemen som anges nedan. Detta borde tydligen fixas i nästa större version efter SQL Server 2012!
Din plan visar att de enskilda inläggen använder parametriserade procedurer (möjligen autoparametriserade) så analys-/kompileringstiden för dessa bör vara minimal.
Jag tänkte att jag skulle undersöka det här lite mer, så skapa en loop (skript) och försökte justera antalet VALUES satser och registrera kompileringstiden.
Jag dividerade sedan kompileringstiden med antalet rader för att få den genomsnittliga kompileringstiden per klausul. Resultaten är nedan
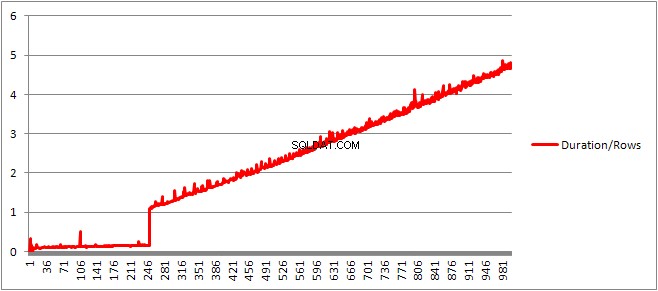
Upp till 250 VALUES satser som presenterar kompileringstiden / antalet satser har en svag uppåtgående trend men inget för dramatiskt.
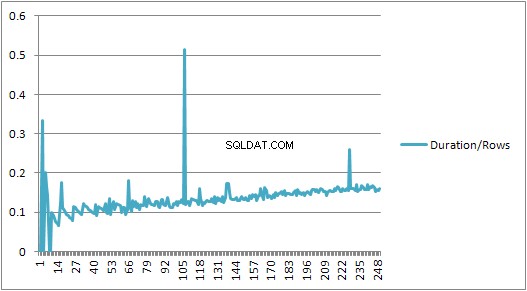
Men så sker en plötslig förändring.
Den delen av data visas nedan.
+------+----------------+-------------+---------------+---------------+
| Rows | CachedPlanSize | CompileTime | CompileMemory | Duration/Rows |
+------+----------------+-------------+---------------+---------------+
| 245 | 528 | 41 | 2400 | 0.167346939 |
| 246 | 528 | 40 | 2416 | 0.162601626 |
| 247 | 528 | 38 | 2416 | 0.153846154 |
| 248 | 528 | 39 | 2432 | 0.157258065 |
| 249 | 528 | 39 | 2432 | 0.156626506 |
| 250 | 528 | 40 | 2448 | 0.16 |
| 251 | 400 | 273 | 3488 | 1.087649402 |
| 252 | 400 | 274 | 3496 | 1.087301587 |
| 253 | 400 | 282 | 3520 | 1.114624506 |
| 254 | 408 | 279 | 3544 | 1.098425197 |
| 255 | 408 | 290 | 3552 | 1.137254902 |
+------+----------------+-------------+---------------+---------------+
Den cachade planstorleken som hade vuxit linjärt sjunker plötsligt men CompileTime ökar 7 gånger och CompileMemory skjuter upp. Detta är gränsen mellan att planen är en automatisk parametriserad (med 1 000 parametrar) till en icke-parametriserad. Därefter verkar det bli linjärt mindre effektivt (i termer av antal värdeklausuler som behandlas under en given tid).
Inte säker på varför detta skulle vara. Förmodligen när den sammanställer en plan för specifika bokstavliga värden måste den utföra någon aktivitet som inte skalas linjärt (som sortering).
Det verkar inte påverka storleken på den cachade frågeplanen när jag försökte en fråga som helt bestod av dubbletter av rader och inte heller påverkar ordningen på utdata från tabellen med konstanter (och som du infogar i en hög tid för att sortera skulle ändå vara meningslöst även om det gjorde det).
Om dessutom ett klustrat index läggs till i tabellen visar planen fortfarande ett explicit sorteringssteg så att det inte verkar sortera vid kompilering för att undvika sortering vid körning.

Jag försökte titta på detta i en debugger men de offentliga symbolerna för min version av SQL Server 2008 verkar inte vara tillgängliga så istället var jag tvungen att titta på motsvarande UNION ALL konstruktion i SQL Server 2005.
En typisk stackspårning är nedan
sqlservr.exe!FastDBCSToUnicode() + 0xac bytes
sqlservr.exe!nls_sqlhilo() + 0x35 bytes
sqlservr.exe!CXVariant::CmpCompareStr() + 0x2b bytes
sqlservr.exe!CXVariantPerformCompare<167,167>::Compare() + 0x18 bytes
sqlservr.exe!CXVariant::CmpCompare() + 0x11f67d bytes
sqlservr.exe!CConstraintItvl::PcnstrItvlUnion() + 0xe2 bytes
sqlservr.exe!CConstraintProp::PcnstrUnion() + 0x35e bytes
sqlservr.exe!CLogOp_BaseSetOp::PcnstrDerive() + 0x11a bytes
sqlservr.exe!CLogOpArg::PcnstrDeriveHandler() + 0x18f bytes
sqlservr.exe!CLogOpArg::DeriveGroupProperties() + 0xa9 bytes
sqlservr.exe!COpArg::DeriveNormalizedGroupProperties() + 0x40 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x18a bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!CQuery::PqoBuild() + 0x3cb bytes
sqlservr.exe!CStmtQuery::InitQuery() + 0x167 bytes
sqlservr.exe!CStmtDML::InitNormal() + 0xf0 bytes
sqlservr.exe!CStmtDML::Init() + 0x1b bytes
sqlservr.exe!CCompPlan::FCompileStep() + 0x176 bytes
sqlservr.exe!CSQLSource::FCompile() + 0x741 bytes
sqlservr.exe!CSQLSource::FCompWrapper() + 0x922be bytes
sqlservr.exe!CSQLSource::Transform() + 0x120431 bytes
sqlservr.exe!CSQLSource::Compile() + 0x2ff bytes
Så om man avviker från namnen i stackspåren verkar det spendera mycket tid på att jämföra strängar.
Den här KB-artikeln anger att DeriveNormalizedGroupProperties är associerat med vad som brukade kallas normaliseringsstadiet för frågebehandling
Det här steget kallas nu bindning eller algebrisering och det tar uttrycket parse tree-utdata från föregående parse-steg och matar ut ett algebriserat uttrycksträd (frågeprocessorträd) för att gå vidare till optimering (trivial planoptimering i detta fall) [ref].
Jag försökte ytterligare ett experiment (Script) som var att köra om det ursprungliga testet men titta på tre olika fall.
- Förnamn och efternamn Strängar med längd 10 tecken utan dubbletter.
- Förnamn och efternamn Strängar med längd 50 tecken utan dubbletter.
- Förnamn och efternamn Strängar med längd 10 tecken med alla dubbletter.
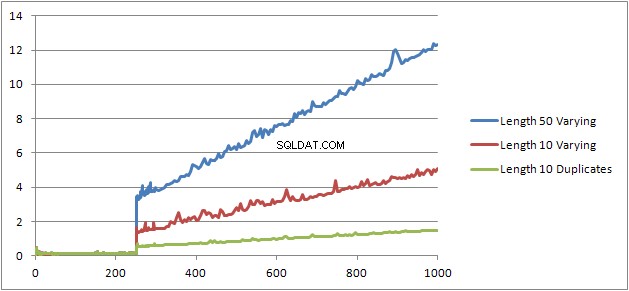
Det kan tydligt ses att ju längre strängarna desto sämre blir sakerna och att omvänt ju fler dubbletter desto bättre blir det. Som tidigare nämnts påverkar inte dubbletter den cachade planstorleken så jag antar att det måste finnas en process för dubblettidentifiering när man konstruerar själva det algebriserade uttrycksträdet.
Redigera
En plats där denna information utnyttjas visas av @Lieven här
SELECT *
FROM (VALUES ('Lieven1', 1),
('Lieven2', 2),
('Lieven3', 3))Test (name, ID)
ORDER BY name, 1/ (ID - ID)
Eftersom det vid kompilering kan fastställa att Name kolumnen har inga dubbletter den hoppar över beställning efter den sekundära 1/ (ID - ID) uttryck vid körning (sorteringen i planen har bara en ORDER BY kolumn) och inget divideringsfel med noll höjs. Om dubbletter läggs till i tabellen visar sorteringsoperatorn två ordningsföljder efter kolumner och det förväntade felet höjs.