Introduktion
En tabell är en logisk struktur. När du skapar en tabell skulle du vanligtvis inte bry dig om vilka enheter den sitter på vid lagringslagret. Men om du är databasadministratör kan denna kunskap bli viktig om du behöver flytta vissa databasdelar till alternativ lagring eller volym. Sedan kanske du vill att bestämda tabeller ska finnas på en viss volym eller uppsättning diskar.
Filgrupper i SQL Server erbjuder det abstraktionsskiktet som tillåter oss att kontrollera den fysiska platsen för våra logiska strukturer – tabeller, index etc.
Filgrupper
En filgrupp är en logisk struktur för att gruppera datafiler i SQL Server. Om vi skapar en filgrupp och associerar den med en uppsättning datafiler, kommer alla logiska objekt som skapas i den filgruppen att finnas fysiskt på den uppsättningen fysiska filer.
Det primära syftet med sådan fysisk filgruppering är datatilldelning och dataplacering. Till exempel vill vi att våra transaktionsdata ska lagras på en uppsättning snabba diskar. Samtidigt behöver vi historiska data lagrade på en annan uppsättning billigare diskar. I ett sådant scenario skulle vi skapa Tran tabellen på TXN-filgruppen och TranHist tabell på en annan HIST-filgrupp. Längre fram i den här artikeln ska vi se hur detta översätts till att ha data på olika diskar.
Skapa filgrupper
Syntaxen för att skapa filgrupper visas i Lista 1 . Obs :Databaskontexten är master databas. När vi utfärdar satserna ändrar vi DB2-databasen genom att lägga till nya filgrupper till den. I huvudsak är dessa filgrupper bara logiska konstruktioner vid denna tidpunkt. De innehåller inga data.
-- Listing 1: Creating File Groups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [TXN]
GO
Lägga till filer i filgrupper
Nästa steg är att lägga till en fil till var och en av filgrupperna. Vi kan lägga till mer än en fil, men vi håller det enkelt för demonstrationsändamål. Lägg märke till att varje fil är helt och hållet på en annan enhet, och syntaxen tillåter oss att specificera den avsedda filgruppen.
-- Listing 2: Adding Files to Filegroups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_HIST_01', FILENAME = N'E:\MSSQL\Data\DB2_HIST_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_TXN_01', FILENAME = N'C:\MSSQL\Data\DB2_TXN_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [TXN]
GO
Skapa tabeller till filgrupper
Här säkerställer vi att tabeller finns på önskade diskar. Syntaxen för att skapa tabeller låter oss ange vilken filgrupp vi vill ha.
-- Listing 3: Creating a table on Filegroups TXN and HIST
USE [DB2]
GO
CREATE TABLE [dbo].[tran](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [TXN]
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [TXN]
GO
CREATE TABLE [dbo].[tranhist](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [HIST]
GO
Om vi tar ett steg tillbaka noterar vi att vi nu har uppnått följande:
- Skapade två filgrupper.
- Fastställde datafilerna (och diskarna) som är associerade med varje filgrupp.
- Har bestämt vilka tabeller som är associerade med varje filgrupp.
I huvudsak är filgruppen abstraktionslagret .
Kontrollera vilka filgrupper våra tabeller sitter på
För att kontrollera vilken filgrupp varje tabell tillhör, kör vi koden i Listing 4. Vi använder två huvudsystemkatalogvyer:sys.indexes och sys.data_spaces . sys.data_spaces katalogvyn innehåller information om filgrupper och partitioner, och de huvudsakliga logiska strukturerna där tabeller och index lagras.
Obs! Vi använde inte sys.tables . SQL Server associerar index i en tabell med datautrymmen snarare än tabeller, som vi intuitivt tror.
-- Listing 4: Check the filegroup of an index or table
USE DB2
GO
select object_name(i.object_id) [Table Name]
, i.name [Index Name]
, i.type_desc [Index Type]
, d.name [FileGroup]
from sys.indexes i inner join sys.data_spaces d
on i.data_space_id=d.data_space_id
where d.name<>'PRIMARY'
Utdata från frågan i Listing 4 visar två tabeller som vi just har skapat. Lägg märke till att tranhisten tabellen har inget index. Ändå dyker den upp i resultatuppsättningen, identifierad som en hög .
En hög är en tabell som inte har något klustrat index som bestämmer orderdata som fysiskt lagras i en tabell. Det kan bara finnas ett klustrat index i en tabell.
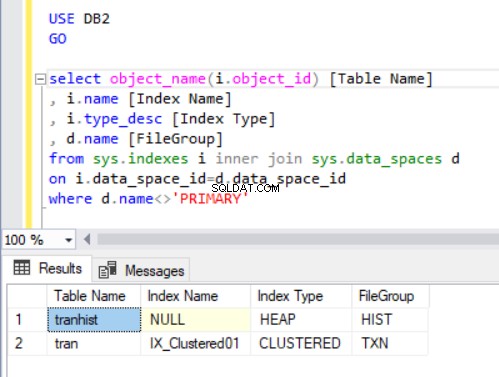
Följa Trans-tabellen
Nu måste vi lägga till några poster i trans tabell med följande kod:
-- Listing 5: Populate the Tran Table
USE DB2
GO
SELECT * FROM [tran];
INSERT INTO [tran] VALUES (1, GETDATE(),12.00);
INSERT INTO [tran] VALUES (2, GETDATE(),13.00);
INSERT INTO [tran] VALUES (3, GETDATE(),15.40);
INSERT INTO [tran] VALUES (4, GETDATE(),16.20);
INSERT INTO [tran] VALUES (5, GETDATE(),11.10);
SELECT * FROM [tran];
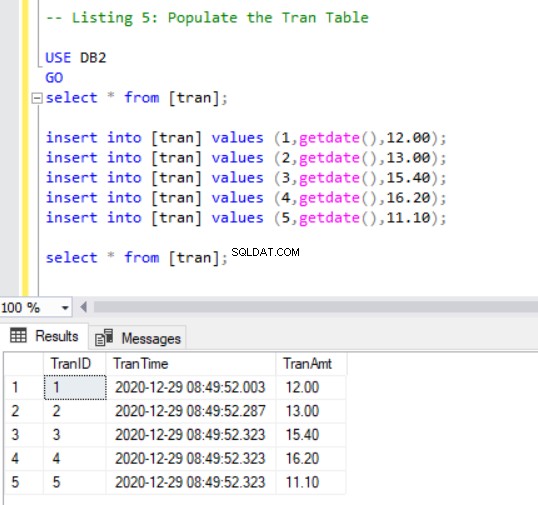
Flytta en tabell till en annan filgrupp
För att flytta trans tabell till en annan filgrupp behöver vi bara bygga om det klustrade indexet och ange den nya filgruppen medan du gör ombyggnaden. Lista 5 visar detta tillvägagångssätt.
Vi utför två steg:släpp först indexet och återskapa det sedan. Däremellan kontrollerar vi att uppgifterna och platsen för de två tabeller vi skapade tidigare förblir intakta.
-- Listing 6: Check what filegroup an index or table belongs to
USE [DB2]
GO
DROP INDEX [IX_Clustered01] ON [dbo].[tran] WITH ( ONLINE = OFF )
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [HIST]
GO
Genom att ta bort det klustrade indexet från tran tabell, har vi konverterat den till en hög :
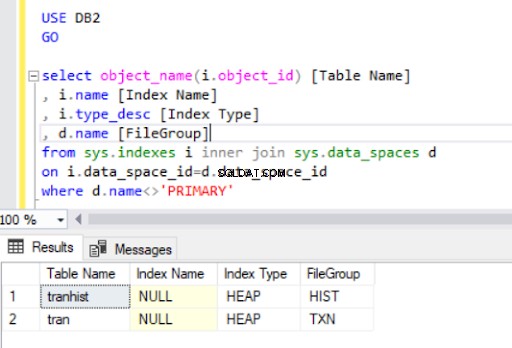
När vi återskapar det klustrade indexet indikeras det också i Listing 4-utgången.
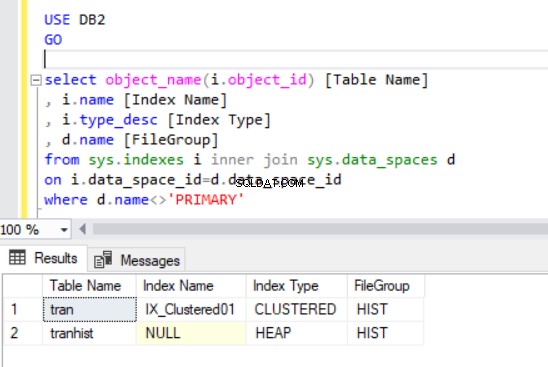
Nu har vi trans tabell i HIST-filgruppen.
Slutsats
Den här artikeln visade förhållandet mellan tabeller, index, filer och filgrupper när det gäller vår SQL Server-datalagring. Vi har också förklarat att flytta en tabell från en filgrupp till en annan genom att återskapa det klustrade indexet.
Denna färdighet kommer att vara användbar när du behöver migrera data till ny lagring (snabbare diskar eller långsammare diskar för arkivering). I mer avancerade scenarier kan du använda filgrupper för att hantera datalivscykeln genom att implementera tabellpartitioner.
Referenser
- Databasfiler och filgrupper
- Byta ut tabellpartitioner – en genomgång