Introduktion
För några år sedan fick vi i uppdrag att ha ett affärskrav på kortdata i ett specifikt format i syfte att göra något som kallas "avstämning". Tanken var att presentera data i en tabell till en applikation som skulle konsumera och bearbeta data som skulle ha en lagringstid på sex månader. Vi var tvungna att skapa en ny databas för detta affärsbehov och sedan skapa kärntabellen som en partitionerad tabell. Processen som beskrivs här är den process vi använder för att säkerställa att data äldre än sex månader flyttas från tabellen på ett rent sätt.
Lite om partitionering
Tabellpartitionering är en databasteknik som låter dig lagra data som tillhör en logisk enhet (tabellen) som en uppsättning partitioner som kommer att sitta på separat fysisk struktur – datafiler – genom ett abstraktionslager som kallas filgrupper i SQL Server. Processen att skapa denna partitionerade tabell involverar två nyckelobjekt:
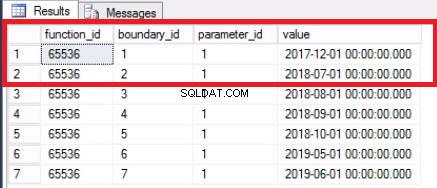
En partitionsfunktion :En partitionsfunktion definierar hur raderna i en partitionerad tabell mappas baserat på värdena i en angiven kolumn (partitionskolumnen). En partitionerad tabell kan vara baserad på antingen en lista eller ett intervall. För vårt användningsfall (med endast sex månaders data) använde vi en räckviddspartition . En partitionsfunktion kan definieras som antingen RANGE RIGHT eller RANGE LEFT. Vi använde RANGE RIGHT som visas i koden i Lista 1 vilket betyder att gränsvärdet kommer att tillhöra höger sida av gränsvärdesintervallet när värdena sorteras i stigande ordning från vänster till höger.
-- Lista 1:Skapa en partitionsfunktion ANVÄND [post_office_history]GOCREATE PARTITION FUNCTIONPostTranPartFunc (datetime)SOM OMRÅDE HÖGERFÖR VÄRDEN ('20190201','20190301','2019014019','012'01','01'01','01'09','052'01','01'01','01'01','01'09','01'09','01'09','01'09','01'01','01'09','01'09','01' '20190801','20190901','20191001','20191101','20191201')GO Ett partitionsschema :Ett partitionsschema är baserat på partitionsfunktionen och bestämmer på vilka fysiska strukturer rader som tillhör varje partition kommer att placeras. Detta uppnås genom att mappa sådana rader till filgrupper. Lista 2 visar koden för att skapa ett partitionsschema. Innan partitionsschemat skapas måste filgrupperna som det kommer att hänvisa till existera.
-- Lista 2:Skapa partitionsschema ---- Steg 1:Skapa filgrupper --ANVÄND [master]GOALTER DATABAS [post_office_history] LÄGG TILL FILGROUP [JAN]ÄNDRA DATABAS [post_office_history] LÄGG TILL FILGRUPP [FEB]ÄNDRA DATABAS [post_office_history] ] LÄGG TILL FILGROUP [MAR]ÄNDRA DATABAS [post_office_history] LÄGG TILL FILGROUP [APR]ÄNDRA DATABAS [post_office_history] LÄGG TILL FILGROUP [MAJ]ÄNDRA DATABAS [post_office_history] ADD FILEGROUP [JUN]ALTER DATABASE [post_office_GROUP] ] LÄGG TILL FILGROUP [AUG]ÄNDRA DATABAS [post_kontorshistoria] LÄGG TILL FILGROUP [SEP]ÄNDRA DATABAS [post_office_history] LÄGG TILL FILGROUP [OKT]ÄNDRA DATABAS [post_office_history] LÄGG TILL FILGROUP [NOV]ÄNDRAR DATABAS [NOV]ALTER_OFFICE_FILE [NOV]POST_OFFICE_FILE [STEG_OFFICE_FILE] 2:Lägg till datafiler till varje filgrupp --ANVÄND [master]GOALTER DATABASE [post_office_history] LÄGG TILL FIL (NAME =N'post_office_history_part_01', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_01.ndf', SIZE FILE =52K, TH, SIZE=1048576KB) TILL FILGROUP [JAN]ÄNDRAR DATABAS [post_office_history] LÄGG TILL FIL (NAME =N'post_office_history_part_02', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_02.ndf') 5FI 201 GROUP =5 FI 200, 5 FI 2 02. FEB]ÄNDRA DATABAS [post_office_history] LÄGG TILL FIL (NAMN =N'post_office_history_part_03', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_03.ndf', SIZE =2097152KB, FILEGROWATAB8TH =1K04ATAB8TH FILEGROW 2097152KB, FILEGROWATAB8TH HILEGROW4ATAB8TH) ] LÄGG TILL FIL (NAMN =N'post_office_history_part_04', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_04.ndf', STORLEK =2097152KB, FILEGROWTH =1048576KB) [ATABARASELEhistory_GROUP]DATABRAASELEhistory_GROUP]DATABRAASELEhistory_GROUP N'post_office_history_part_05', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_05.ndf', SIZE =2097152KB, FILEGROWTH =1048576KB) TO FILEGROUP [MAY_FILE_NAME]postoffice_part_05 [MAY_FILE_NAME]postoffice_0[MAY_NAME]postoffice_0 =N'G:\MSSQL\DATA\post_office_history_part_06. ndf', STORLEK =2097152KB, FILEGROWTH =1048576KB) TILL FILGROUP [JUN]ÄNDRA DATABAS [post_office_history] LÄGG TILL FIL (NAMN =N'post_office_history_part_07', FILEMSNAAMN\FILEGRUPPEN\DATA_07_1_07_07_07', FILEMShistory =N_L_2, 12_07', FILEMShistoria =1_2, 7, 7, 5 , FILEGROWTH =1048576KB) TILL FILGRUPPER [JUL]ÄNDRAR DATABAS [post_office_history] LÄGG TILL FIL (NAME =N'post_office_history_part_08', FILENAME =N'G:\MSSQL\DATA\post_office_history_part_5, 9B_08.ZEndfGRO_10, 7B, 7K, 9, 7K, 7K, 7K, 8, 8. FILGROUP [AUG]ÄNDRA DATABAS [post_office_history] LÄGG TILL FIL (NAMN =N'post_office_history_part_09', FILENAME =N'G:\MSSQL\DATA\post_office_history_part_09.ndf', SIZE =2097152KATERIEL TILL 2097152KAST] =2097152KAST. [post_office_history] LÄGG TILL FIL (NAME =N'post_office_history_part_10', FILENAME =N'G:\MSSQL\DATA\post_office_history_part_10.ndf', SIZE =2097152KB, FILEGROWTH =10B485]post_office_history_tot_office NAME =N'post_office_history_part_09', FILENAME =N'G:\MS SQL\DATA\post_office_history_part_11.ndf', STORLEK =2097152KB, FILEGROWTH =1048576KB) TILL FILGROUP [NOV]ÄNDRAR DATABAS [post_office_history] LÄGG TILL FIL (NAME =N'post_part_office_history\N_part_office_0TA\N_post_FILE_0A_1, NAAMN =N'post_part_office_0ATA\N_post_FILE_0TA\\ ndf', STORLEK =2097152KB, FILEGROWTH =1048576KB) TILL FILGRUPPE [DEC]GO-- Steg 3:Skapa partitionsschema --PRINT 'skapar partitionsschema ...'GOUSE [post_office_history]GOCREATE PARTITIONSSCHEMA TILL PARTITION ArtSchME ASPJncart ,FEB,MAR,APR,MAJ,JUN,JUL,AUG,SEP,OKT,NOV,DEC)GO
Lägg märke till att för N partitioner kommer det alltid att finnas N-1 gränser. Försiktighet måste iakttas när du definierar den första filgruppen i partitionsschemat. Den första gränsen som listas i partitionsfunktionen kommer att ligga mellan den första och andra filgruppen, så detta gränsvärde (20190201) kommer att sitta i den andra partitionen (FEB). Dessutom är det faktiskt möjligt att placera alla partitioner i en enda filgrupp men vi har valt separata filgrupper i det här fallet.
Smutsa ner händerna
Så låt oss dyka in i uppgiften att byta ut partitioner!
Det första vi behöver göra är att bestämma exakt hur vår data är fördelad mellan partitionerna så att vi kan veta vilken partition vi skulle vilja byta ut. Vanligtvis kommer vi att byta ut den äldsta partitionen.
-- Lista 3:Kontrollera datadistribution i partitioner --ANVÄND POST_OFFICE_HISTORYGOSELECT $PARTITION.POSTTRANPARTFUNC(DATETIME_TRAN_LOCAL) SOM [PARTITIONSNUMMER] , MIN(DATETIME_TRAN_LOCAL) SOM [MIN DATUM], MAX(DATETIME_TRAN_LOCAL) SOM, [MAXLOCALDATE] COUNT(*) SOM [RADER I PARTITION]FRÅN DBO.POST_TRAN_TAB -- PARTITIONED TABLEGROUP BY $PARTITION.POSTTRANPARTFUNC(DATETIME_TRAN_LOCAL)ORDER BY [PARTITION NUMBER]GO
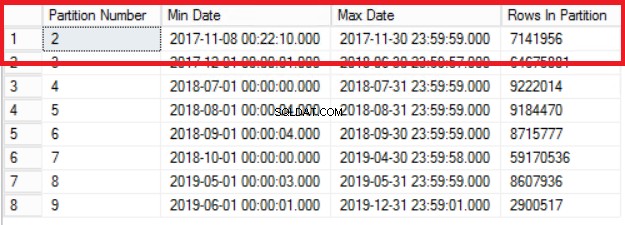
Fig. 1 Output of Listing 3
Fig. 1 visar oss utdata från frågan i Listing 3. Den äldsta partitionen är Partition 2 som innehåller rader från år 2017. Vi verifierar detta med frågan i Listing 4. Lista 4 visar också vilken filgrupp som innehåller data i Partition 2.
-- Lista 4:Kontrollera filgrupp associerad med partition --ANVÄND POST_OFFICE_HISTORYGOSELECT PS.NAME SOM PSNAME, DDS.DESTINATION_ID SOM PARTITIONNUMBER, FG.NAME SOM FILGROUPNAMEFROM (((SYS.TABLER SOM T INNER JOIN SYS.INDEXES SOM JAG (T.OBJECT_ID =I.OBJECT_ID)) INNER JOIN SYS.PARTITION_SCHEMES AS PS ON (I.DATA_SPACE_ID =PS.DATA_SPACE_ID)) INNER JOIN SYS.DESTINATION_DATA_SPACES SOM DDS ON (PS.DATA_SPACE_PARTIID) DYS. FILGRUPPER SOM FG PÅ DDS.DATA_SPACE_ID =FG.DATA_SPACE_IDWHERE (T.NAME ='POST_TRAN_TAB') OCH (I.INDEX_ID IN (0,1)) OCH DDS.DESTINATION_ID =$PARTITION.POSTTRANPARTFUNC(Fig. 1 Output of Listing 3
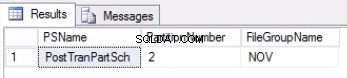
Fig. 2 Output of Listing 4
Lista 4 visar oss att filgruppen associerad med partition 2 är NOV . För att byta ut partition 2 behöver vi en historiktabell som är en kopia av livetabellen men sitter på samma filgrupp som den partition vi tänker byta ut. Eftersom vi redan har den här tabellen behöver vi bara återskapa den på önskad filgrupp. Du måste också återskapa det klustrade indexet. Observera att detta klustrade index har samma definition som det klustrade indexet i tabellen post_tran_tab och sitter även i samma filgrupp som post_tran_tab_hist bord.
-- Lista 5:Återskapa historiktabellen -- Återskapa historiktabellen --USE [post_office_history]GOSET ANSI_NULLS ONGOSET QUOTED_IDENTIFIER ONGOSET ANSI_PADDING ONGODROP TABLE [dbo].[post_tran_tabbo_hist] [post_tran_tabbo_hist] post_tran_tab_hist]( [tran_nr] [bigint] NOT NULL, [tran_type] [char](2) NULL, [tran_reversed] [char](2) NULL, [batch_nr] [int] NULL, [meddelandetyp] [char](4) ) NULL, [source_node_name] [varchar](12) NULL, [system_trace_audit_nr] [char](6) NULL, [settle_currency_code] [char](3) NULL, [sink_node_name] [varchar](30) NULL, [sink_nod_code]_curl [char](3) NULL, [to_account_id] [varchar](30) NULL, [pan] [varchar](19) NOT NULL, [pan_encrypted] [char](18) NULL, [pan_reference] [char](70) ) NULL, [datetime_tran_local] [datetime] NOT NULL, [tran_amount_req] [float] NOT NULL, [tran_amount_rsp] [float] NOT NULL, [tran_cash_req] [float] NOT NULL, [tran_cash_rsp ] [tran_cash_rsp ] [float_]mt ] [char](10) NULL, [merchant_type] [char](4) NULL, [pos_entry_mode] [char] (3) NULL, [pos_condition_code] [char](2) NULL, [acquiring_inst_id_code] [varchar](11) NULL, [retrieval_reference_nr] [char](12) NULL, [auth_id_rsp] [char](6) NULL, [ rsp_code_rsp] [char](2) NULL, [service_restriction_code] [char](3) NULL, [terminal_id] [char](8) NULL, [terminal_owner] [varchar](25) NULL, [card_acceptor_id_code] [char]( 15) NULL, [card_acceptor_name_loc] [char](40) NULL, [from_account_id] [varchar](28) NULL, [auth_reason] [char](1) NULL, [auth_type] [char](1) NULL, [message_reason_code ] [char](4) NULL, [datetime_req] [datetime] NULL, [datetime_rsp] [datetime] NULL, [from_account_type] [char](2) NULL, [to_account_type] [char](2) NULL, [insert_date] [datetime] NOT NULL, [tran_postilion_originated] [int] NOT NULL, [card_product] [varchar](20) NULL, [card_seq_nr] [char](3) NULL, [expiry_date] [char](4) NULL, [srcnode_cash_approved ] [float] NOT NULL, [tran_completed] [char](2) NULL) ON [NOV] GOSET ANSI_PADDING OFFGO-- Återskapa det klustrade indexet --USE [post_office_history]GO SKAPA CLUSTERED INDEX [IX_Datetime_Local] PÅ [dbo].[post_tran_tab_hist] ( [datetime_tran_local] ASC, [tran_nr] ASC ) MED (PAD_INDEX =OFF, STATISTICS_DRORECOMPUTE =OFFLINE =OFFLINE, IOFFLINE =OFFLINE, SORT_IN_EXIST , ALLOW_ROW_LOCKS =PÅ, ALLOW_PAGE_LOCKS =PÅ) PÅ [NOV]GOAtt byta ut den sista partitionen är nu ett enradskommando. Att ta en räkning av båda tabellerna före och efter exekvering av detta enradskommando ger en försäkran om att vi har all data som önskas.
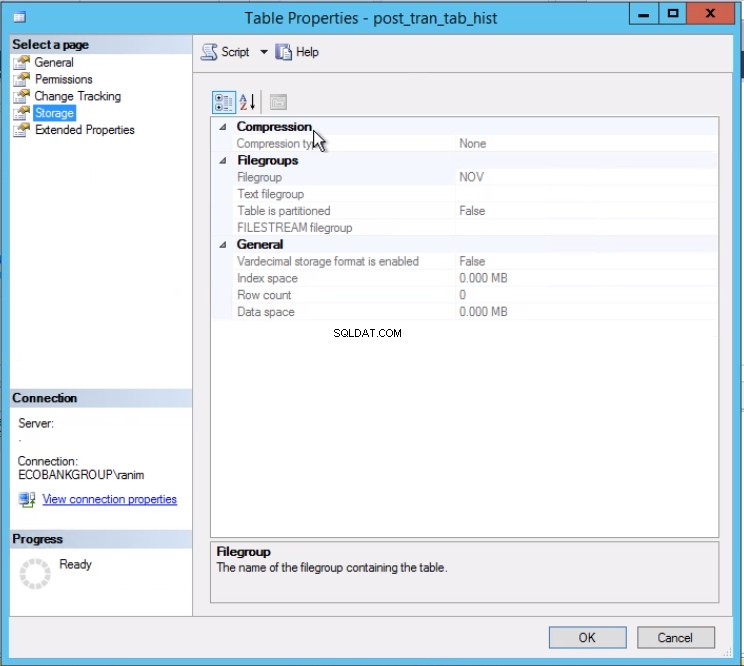
Fig. 3 Tabell post_tran_tab_hist sitter på NOV-filgruppen
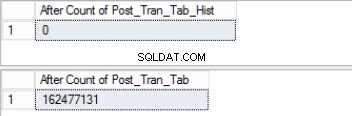
-- Lista 6:Byt ut den senaste partitionen. VÄLJ ANTAL(*) FRÅN 'POST_TRAN_TAB'; VÄLJ ANTAL(*) FRÅN 'POST_TRAN_TAB_HIST'; ANVÄND [POST_OFFICE_HISTORY]MÅLTABELL POST_TRAN_TAB BYT ANTAL PARTITION_TROM_SELECT TILL POST_TRAN_TAB POST_TRAN_TAB';VÄLJ ANTAL(*) FRÅN 'POST_TRAN_TAB_HIST';Eftersom vi har bytt ut den sista partitionen behöver vi inte längre gränsen. Vi slår samman de två intervallen som tidigare delats av den gränsen med kommandot i Lista 7. Vi trunkerar historiktabellen ytterligare som visas i Lista 8. Vi gör detta eftersom det här är hela poängen:att ta bort gamla data som vi inte längre behöver.
-- Lista 7:Sammanfoga partitionsintervall-- Merge RangeUSE [POST_OFFICE_HISTORY]GOALTER PARTITIONSFUNKTION POSTTRANPARTFUNC() MERGE RANGE ('20171101');-- Bekräfta att intervallet är sammanfogatUSE [POST_OFFICE_HISTORY]Spre>FANGERISGOSELECT_PARTISTORY]GOSELECT_PARTIGOROM.>
Fig. 4 Gräns sammanfogad
-- Lista 8:Trunkera historiktabellenUSE [post_office_history]GOTRUNCATE TABLE post_tran_tab_hist;GO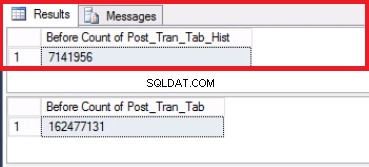
Fig. 5 Antal rader för båda tabellerna före trunkering
Observera att antalet rader i historiktabellen är exakt detsamma som antalet rader tidigare i partition 2 som visas i fig. 1. Du kan också gå den extra milen genom att återställa det tomma utrymmet i filgruppen som tillhör den sista dela. Detta kommer att vara användbart om eftersom du behöver detta utrymme för den nya data som kommer att sitta på den tidigare partitionen. Det här steget kanske inte är nödvändigt om du känner att du har gott om utrymme i din miljö.
-- Lista 9:Återställ utrymme på operativsystemet-- Fastställ att filen har tömtsUSE [post_office_history]GOSELECT DF.FILE_ID, DF.NAME, DF.PHYSICAL_NAME, DS.NAME, DS.TYPE, DF.STATE_DESC FROM SYS .DATABASE_FILES DFJOIN SYS.DATA_SPACES DS PÅ DF.DATA_SPACE_ID =DS.DATA_SPACE_ID;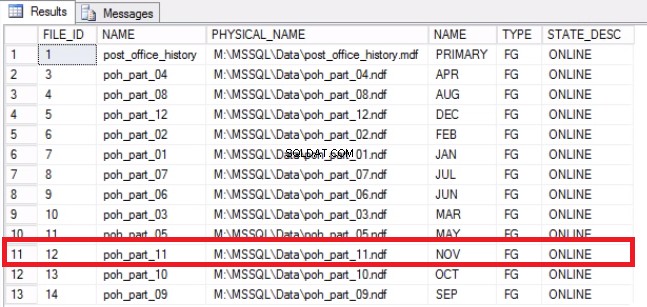
Fig. 7 Fil till filgruppsmappningar
-- Krympa filen till 2GBUSE [post_office_history]GODBCC SHRINKFILE (N'post_office_history_part_11', 2048)GO-- Från OS bekräfta ledigt utrymme på diskar. VÄLJ DISTINCT DB_NAME (S.DATABASE_ID) AS DATA.DATA_BASE_NAME,SID. VOLUME_MOUNT_POINT--, S.VOLUME_ID, S.LOGICAL_VOLUME_NAME, S.FILE_SYSTEM_TYPE, S.TOTAL_BYTES/1024/1024/1024 SOM [TOTAL_SIZE (GB)], S.AVAILABLE_BYTES/104/24/FREE/1024/1024 GB, S.AVAILABLE_BYTES/104/24/124 GB VÄNSTER ((ROUND (((S.AVAILABLE_BYTES*1.0)/S.TOTAL_BYTES), 4)*100),4) SOM PERCENT_FREEFROM SYS.MASTER_FILES AS FCROSS APPLY SYS.DM_OS_VOLUME_STATS (F.DATABASE_ID, F.DATABASE_ID) (S.DATABASE_ID) ='POST_OFFICE_HISTORY';
Fig. 8 Ledigt utrymme på operativsystemet
Slutsats
I den här artikeln har vi gjort en genomgång av processen för att byta ut partitioner från en partitionerad tabell. Detta är ett mycket effektivt sätt att hantera datatillväxt inbyggt i SQL Server. Mer avancerad teknik som Stretch Database finns i nuvarande versioner av SQL Server.
Referenser
Isakov, V. (2018). Exam Ref 70-764 Administrera en SQL-databasinfrastruktur. Pearson Education
Partitionerade tabeller och index i SQL Server