Moodle, ett lärandehanteringssystem med öppen källkod, blev mer och mer populärt under förra året eftersom pandemin tvingade fram hårda nedstängningar och majoriteten av utbildningsaktiviteterna har flyttats från skolor, högskolor och universitet till onlineplattformar. Med den sattes press på IT-teamen för att säkerställa att dessa onlineplattformar kommer att kunna ta emot mycket högre belastning än de brukade uppleva. Frågor har väckts – hur kan en Moodle-plattform skalas för att klara den ökade belastningen? Å ena sidan är att skala själva applikationen inte en svår bedrift att utföra, men databasen är å andra sidan ett annat djur. Databaser, som alla statliga tjänster, är notoriskt svåra att skala ut. I det här blogginlägget vill vi diskutera några utmaningar du kommer att ställas inför när du skalar en Moodle-databas.
Scaling Moodle-databas - The Challenge
Den huvudsakliga källan till problem är arvet - Moodle, precis som många databaser, kommer från en enda databasbakgrund och som sådan kommer den med några förväntningar som är relaterade till en sådan miljö. Det typiska är att du kan utföra en transaktion efter den andra och den andra transaktionen kommer alltid att se resultatet av den första. Detta är inte nödvändigtvis fallet i de flesta av de distribuerade databasmiljöerna. Asynkron replikering ger inga löften. Alla transaktioner kan gå förlorade i processen. Det räcker att mastern kraschar innan transaktionsdata överförs till slavar. Semisynkron replikering ger ett löfte om datasäkerhet men det lovar inget annat. Slavar kan fortfarande släpa efter och även om data lagras på beständig lagring som en relälogg och så småningom kommer den att appliceras på datasetet, betyder det fortfarande inte att den redan har tillämpats. Du kan fråga dina slavar och ser inte data du just har skrivit till mastern.
Även kluster som Galera levereras som standard inte med den verkligt synkrona replikeringen - gapet minskas avsevärt jämfört med replikeringssystemen men det finns fortfarande kvar och omedelbar SELECT som körs efter en tidigare skrivning kanske inte ser data som du just lagrade i databasen eftersom din SELECT dirigerades till en annan Galera-nod än din tidigare skrivning.
Det finns flera lösningar du kan använda för att skala Moodle MySQL-databas. Till att börja med, om du använder replikeringsinställningar kan du använda funktionen "säkra läsningar" från Moodle. Vi tog upp det i en av våra tidigare bloggar. Detta kommer att leda till situationen där Moodle kommer att bestämma vilka skrivningar som ska distribueras över slavarna och vilka som kommer att träffa mästaren.
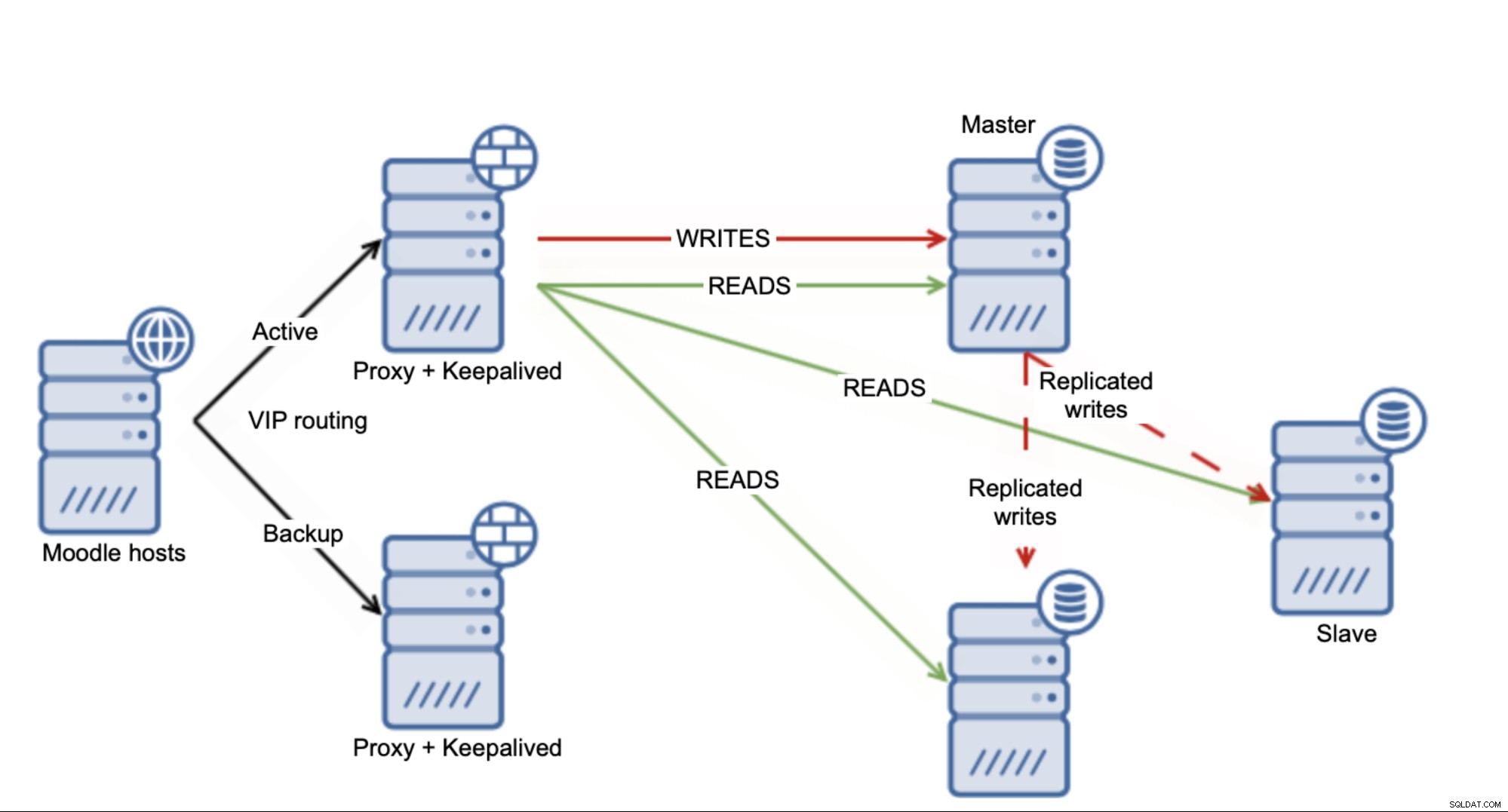
Å ena sidan är det bra - du är säker att använda flera kopplade slavar till mastern, så att du åtminstone i viss mån kan ladda ner mastern. Å andra sidan är det långt ifrån idealiskt, eftersom det bara är en delmängd av SELECT som du kommer att kunna skicka till slavarna. Naturligtvis beror allt på det exakta fallet men du kan förvänta dig att befälhavaren förblir en flaskhals när det gäller lasten.
Alternativt tillvägagångssätt kan vara att använda Galera-klustret och fördela belastningen jämnt över alla noder.
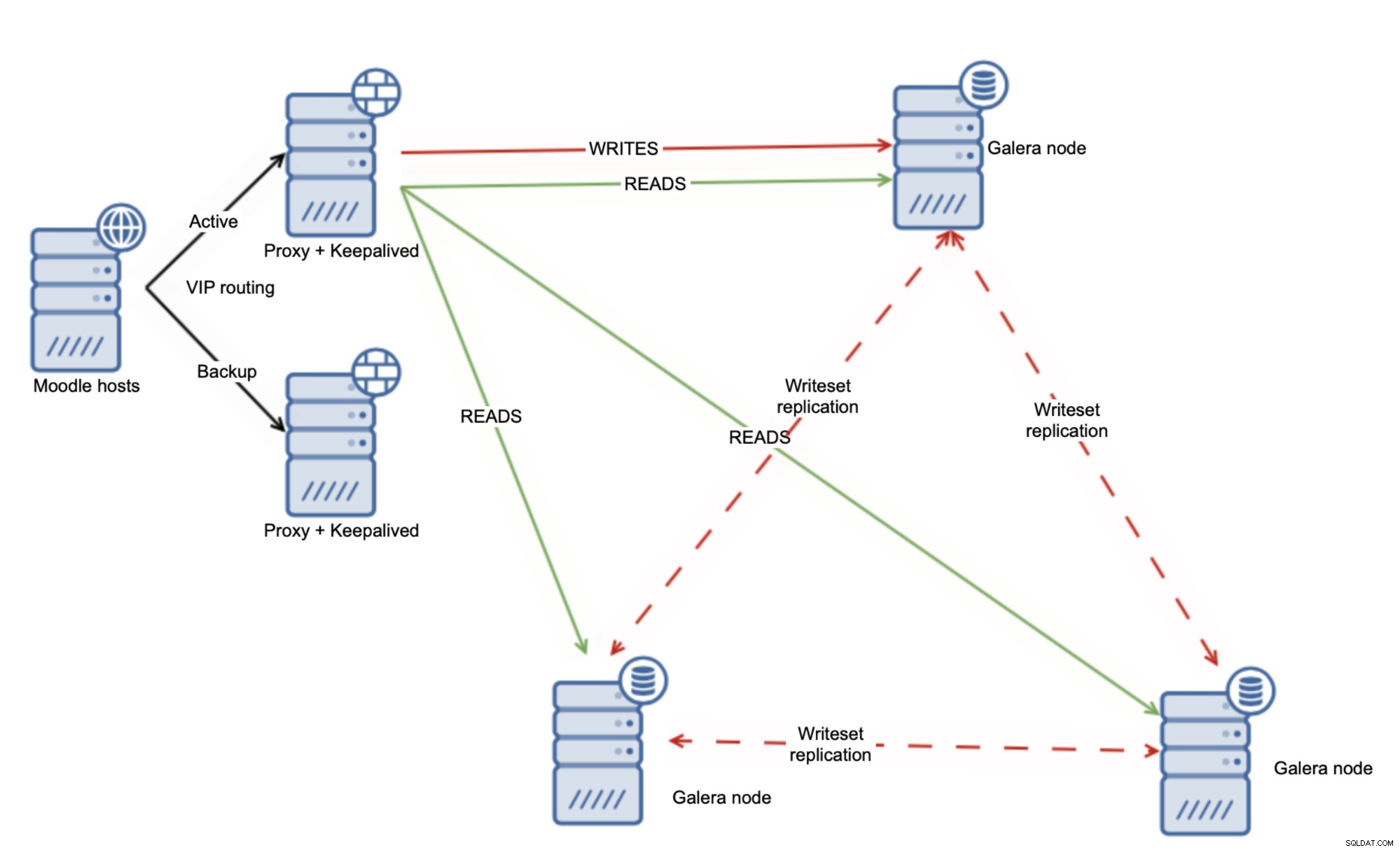
I och för sig räcker inte detta för att hantera all läsning efter -skrivproblem men som tur är kan du använda variabeln wsrep-sync-wait som kan användas för att säkerställa att kausalitetskontrollerna är på plats och att klustret beter sig som ett riktigt synkront kluster. Genom att använda den här inställningen kan du läsa säkert från alla dina Galera-noder.
Naturligtvis kommer att upprätthålla kausalitetskontroller påverka Galeras prestanda men det är fortfarande vettigt eftersom du kan dra nytta av att läsa från flera Galera-noder samtidigt. Från den punkten är det ganska enkelt att skala avläsningar med Galera Cluster - du lägger bara till fler Galera-noder till klustret. Load Balancer bör konfigureras om för att plocka upp dem och användas som ett extra mål för läsningarna så att du kan skala ut till till och med 10+ läsarnoder.
Du måste komma ihåg att att lägga till ytterligare noder, replikering eller Galera, det spelar ingen roll, lägger till viss komplexitet till operationerna i klustret. Du måste se till att dina noder övervakas ordentligt, att du har säkerhetskopior som fungerar, att replikeringen fungerar korrekt och att själva klustret är i korrekt tillstånd. För replikeringsmiljöer måste failover hanteras på ett eller annat sätt och för både Galera och replikering kanske du vill kunna bygga om noderna i klustret om du upptäcker någon form av datainkonsekvens i klustret. Lyckligtvis kan ClusterControl avsevärt hjälpa dig att hantera dessa utmaningar.
Hur ClusterControl hjälper till att hantera Moodle MySQL-databasklustret
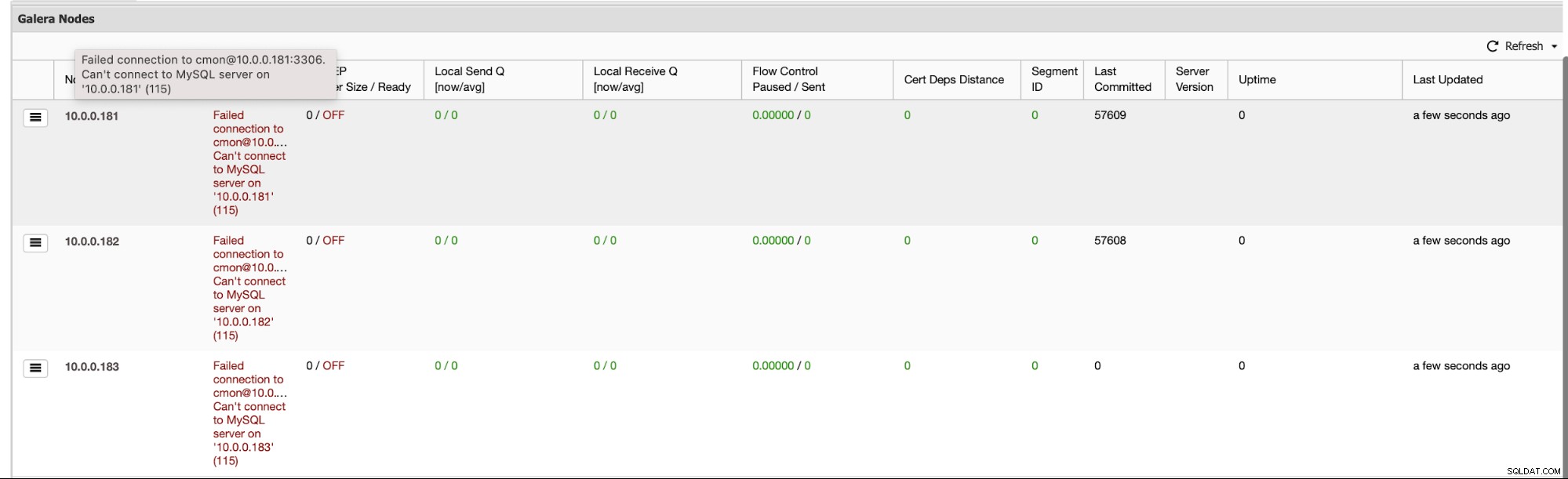
För det första, om hela klustret kollapsar, kommer ClusterControl att utföra en automatisk klusteråterställning - så länge som alla noder kommer att vara tillgängliga kommer ClusterControl att starta klusteråterställningsprocessen:

Efter ett tag bör hela klustret vara online igen.
ClusterControl levereras med en uppsättning hanteringsalternativ:
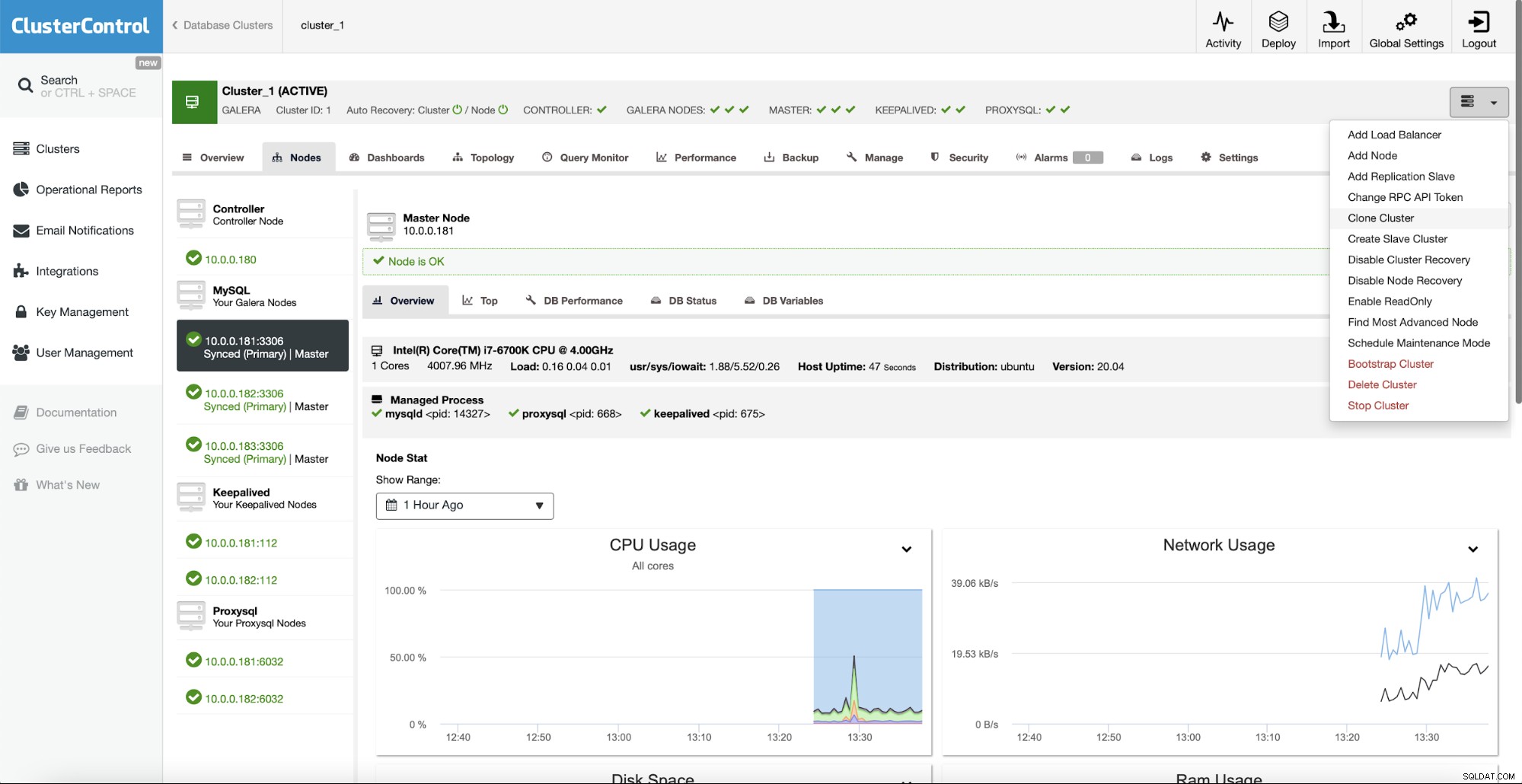
Du kan skala ut klustret genom att lägga till noder eller replikeringsslavar. Du kan till och med skapa ett helt slavkluster som kommer att replikera från huvudklustret.
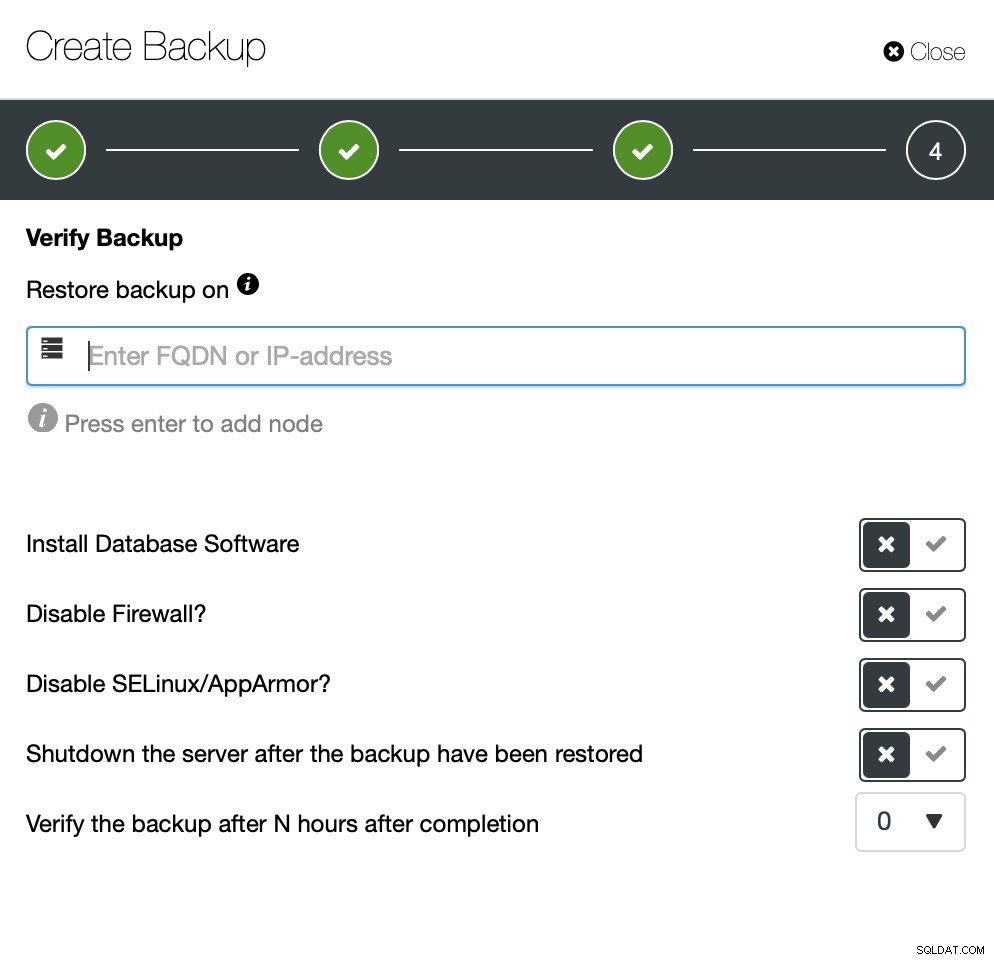
Det är möjligt att enkelt ställa in ett säkerhetskopieringsschema som kommer att köras av ClusterControl. Du kan till och med ställa in automatisk säkerhetskopiering.
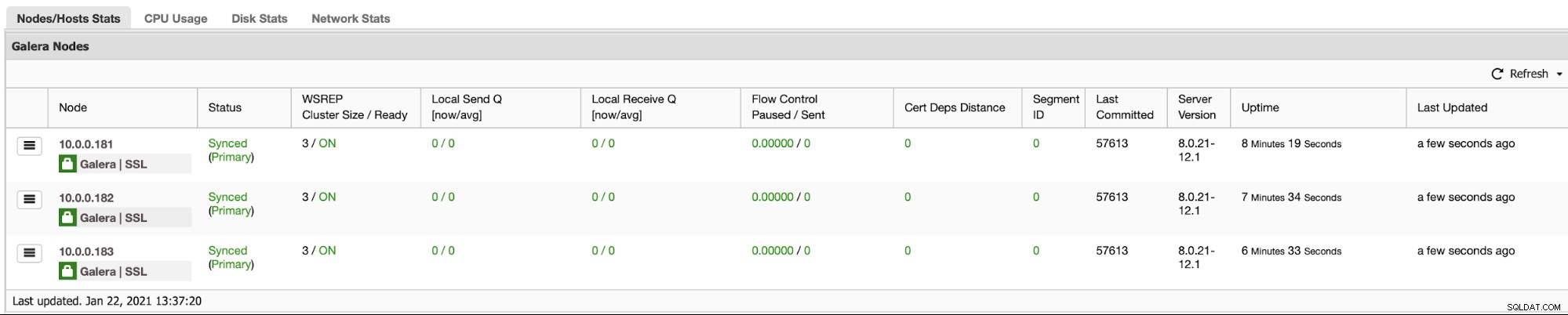
Du vill förmodligen kunna övervaka ditt databaskluster. ClusterControl låter dig göra just det:
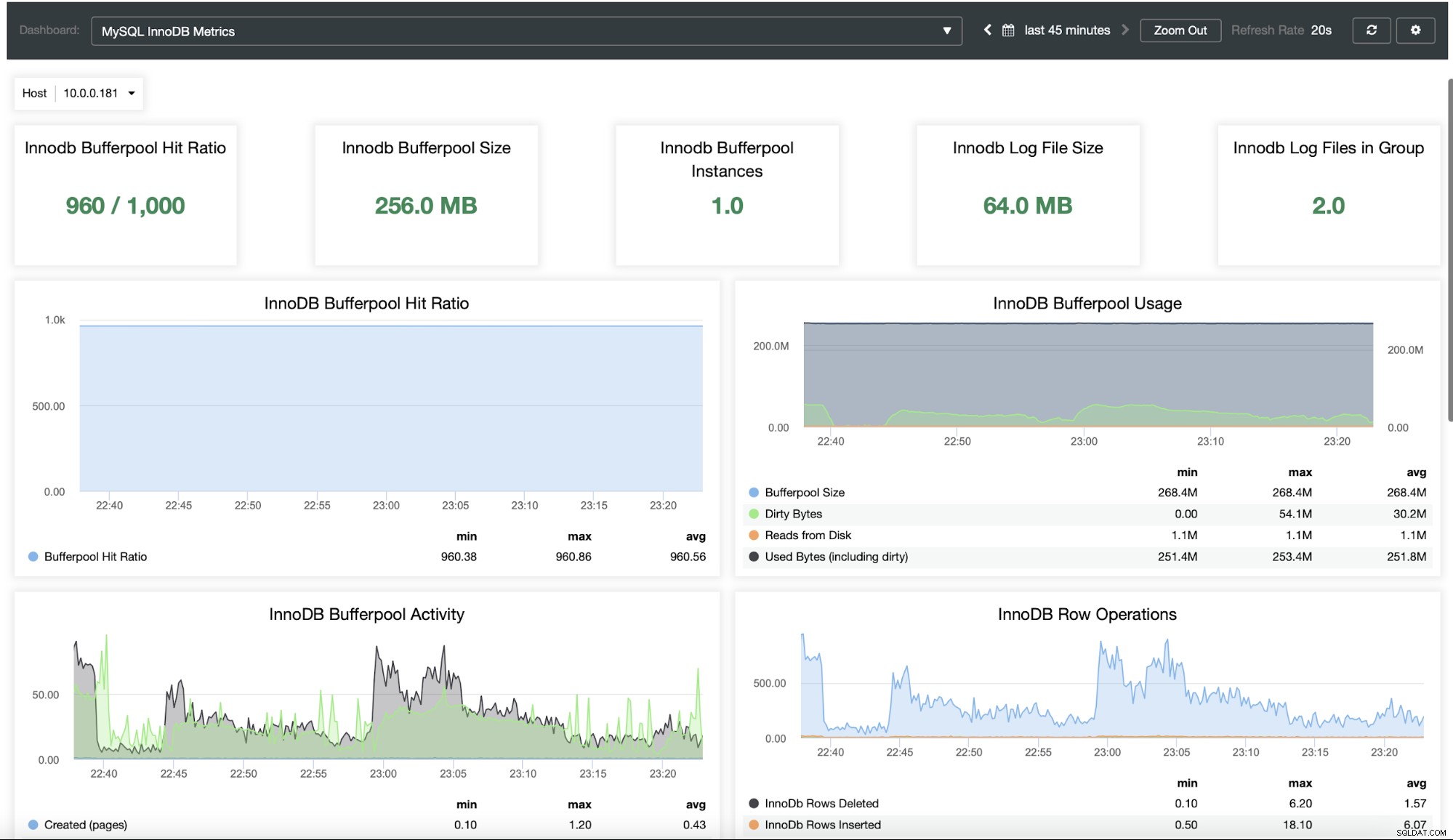
Som du kan se är ClusterControl en fantastisk plattform som kan användas för att minska komplexiteten i att skala och hantera Moodle MySQL-databasen. Vi skulle gärna vilja höra om din erfarenhet av att skala ut Moodle och dess databas i synnerhet.