I min tidigare artikel har jag kortfattat tagit upp databasstatistik, dess betydelse och varför statistik bör uppdateras. Dessutom har jag demonstrerat en steg-för-steg-process för att skapa en SQL Server-underhållsplan för att uppdatera statistik. I den här artikeln kommer följande problem att förklaras:1. Hur man uppdaterar statistik med T-SQL Command. 2. Hur man identifierar de ofta uppdaterade tabellerna med T-SQL och även hur man uppdaterar statistiken för tabeller med ofta infogade/uppdaterade/raderade data.
Uppdatera statistik med T-SQL
Du kan uppdatera statistik med T-SQL-skriptet. Om du vill uppdatera statistik med T-SQL eller SQL Server Management Studio behöver du ALTER databas behörighet på databasen. Se T-SQL-kodexemplet för att uppdatera statistiken för en specifik tabell:
UPDATE STATISTICS <schema_name>.<table_name>.
Låt oss överväga exemplet med att uppdatera statistiken för OrderLines tabellen för WideWorldImporters databas. Följande skript kommer att göra det.
UPDATE STATISTICS [Sales].[OrderLines]
Om du vill uppdatera statistiken för ett specifikt index kan du använda följande skript:
UPDATE STATISTICS <schema_name>.<table_name> <index_name>
Om du vill uppdatera statistiken för IX_Sales_OrderLines_Perf_20160301_02 index för OrderLines tabell kan du köra följande skript:
UPDATE STATISTICS [Sales].[OrderLines] [IX_Sales_OrderLines_Perf_20160301_02]
Du kan också uppdatera statistiken för hela databasen. Om du har en mycket liten databas med få tabeller och liten mängd data kan du uppdatera statistiken för alla tabeller i en databas. Se följande skript:
USE wideworldimporters go EXEC Sp_updatestats
Uppdatera statistik för tabeller med ofta infogade / uppdaterade / raderade data
På stora databaser blir det komplicerat att schemalägga statistikjobbet, särskilt när du bara har några timmar på dig att utföra indexunderhåll, uppdatera statistik och utföra andra underhållsuppgifter. Med en stor databas menar jag en databas som innehåller tusentals tabeller och varje tabell innehåller tusentals rader. Till exempel har vi en databas som heter X. Den har hundratals tabeller och varje tabell har miljontals rader. Och bara ett fåtal tabeller uppdateras ofta. Andra tabeller ändras sällan och har mycket få transaktioner utförda på dem. Som jag nämnde tidigare, för att hålla databasens prestanda upp till märket, måste tabellstatistiken vara uppdaterad. Så vi skapar en SQL-underhållsplan för att uppdatera statistiken för alla tabeller i X-databasen. När SQL-servern uppdaterar statistiken för en tabell använder den en betydande mängd resurser vilket kan leda till prestandaproblem. Så det tar lång tid att uppdatera statistiken för hundratals stora tabeller och medan statistiken uppdateras minskar databasens prestanda avsevärt. Under sådana omständigheter är det alltid tillrådligt att uppdatera statistiken endast för de tabeller som uppdateras ofta. Du kan hålla reda på förändringar i datavolym eller antal rader över tiden genom att använda följande dynamiska hanteringsvyer:1. sys.partitions ger information om det totala antalet rader i en tabell. 2. sys.dm_db_partition_stats ger information om radantal och sidantal per partition. 3. sys.dm_db_index_physical_stats ger information om antalet rader och sidor, plus information om indexfragmentering med mera. Detaljerna om datavolymen är viktiga, men de gör inte bilden av databasaktivitet komplett. Till exempel kan en mellanställningstabell som har nästan samma antal poster tas bort från tabellen eller infogas i en tabell varje dag. På grund av det skulle en ögonblicksbild av antalet rader tyda på att tabellen är statisk. Det kan vara möjligt att de poster som läggs till och raderas har väldigt olika värden som förändrar datafördelningen kraftigt. I det här fallet gör automatisk uppdatering av statistik i SQL Server statistik meningslös. Därför är det mycket användbart att spåra antalet ändringar av en tabell. Detta kan göras på följande sätt:1. rowmodctr kolumn i sys.sysindexes 2. modified_count kolumn i sys.system_internals_partition_columns 3. modification_counter kolumn i sys.dm_db_stats_properties Således, som jag förklarade tidigare, om du har begränsad tid för databasunderhåll, är det alltid lämpligt att uppdatera statistiken endast för tabellerna med en högre frekvens av dataändring (infoga / uppdatera / ta bort). För att göra det effektivt har jag skapat ett skript som uppdaterar statistiken för de "aktiva" tabellerna. Skriptet utför följande uppgifter:• Deklarerar de nödvändiga parametrarna • Skapar en tillfällig tabell med namnet #tempstatistics för att lagra tabellnamn, schemanamn och databasnamn • Skapar en annan tabell med namnet #tempdatabase för att lagra databasnamnet. Kör först följande skript för att skapa två tabeller:
DECLARE @databasename VARCHAR(500) DECLARE @i INT=0 DECLARE @DBCOunt INT DECLARE @SQLCOmmand NVARCHAR(max) DECLARE @StatsUpdateCOmmand NVARCHAR(max) CREATE TABLE #tempstatistics ( databasename VARCHAR(max), tablename VARCHAR(max), schemaname VARCHAR(max) ) CREATE TABLE #tempdatabases ( databasename VARCHAR(max) ) INSERT INTO #tempdatabases (databasename) SELECT NAME FROM sys.databases WHERE database_id > 4 ORDER BY NAME
Skriv sedan en while-loop för att skapa en dynamisk SQL-fråga som itererar genom alla databaser och infogar en lista med tabeller som har en modifieringsräknare som är större än 200 i #tempstatistics tabell. För att få information om dataändringar använder jag sys.dm_db_stats_properties . Studera följande kodexempel:
SET @DBCOunt=(SELECT Count(*) FROM #tempdatabases) WHILE ( @i < @DBCOunt ) BEGIN DECLARE @DBName VARCHAR(max) SET @DBName=(SELECT TOP 1 databasename FROM #tempdatabases) SET @SQLCOmmand= ' use [' + @DBName + ']; select distinct ''' + @DBName+ ''', a.TableName,a.SchemaName from (SELECT obj.name as TableName, b.name as SchemaName,obj.object_id, stat.name, stat.stats_id, last_updated, modification_counter FROM [' + @DBName+ '].sys.objects AS obj inner join ['+ @DBName + '].sys.schemas b on obj.schema_id=b.schema_id INNER JOIN [' + @DBName+ '].sys.stats AS stat ON stat.object_id = obj.object_id CROSS APPLY [' + @DBName+'].sys.dm_db_stats_properties(stat.object_id, stat.stats_id) AS sp WHERE modification_counter > 200 and obj.name not like ''sys%''and b.name not like ''sys%'')a' INSERT INTO #tempstatistics (databasename, tablename, schemaname) EXEC Sp_executesql @SQLCOmmand
Skapa nu den andra slingan inom den första slingan. Det kommer att generera en dynamisk SQL-fråga som uppdaterar statistiken med full scan. Se kodexemplet nedan:
DECLARE @j INT=0 DECLARE @StatCount INT SET @StatCount =(SELECT Count(*) FROM #tempstatistics) WHILE @J < @StatCount BEGIN DECLARE @DatabaseName_Stats VARCHAR(max) DECLARE @Table_Stats VARCHAR(max) DECLARE @Schema_Stats VARCHAR(max) DECLARE @StatUpdateCommand NVARCHAR(max) SET @DatabaseName_Stats=(SELECT TOP 1 databasename FROM #tempstatistics) SET @Table_Stats=(SELECT TOP 1 tablename FROM #tempstatistics) SET @Schema_Stats=(SELECT TOP 1 schemaname FROM #tempstatistics) SET @StatUpdateCommand='Update Statistics [' + @DatabaseName_Stats + '].[' + @Schema_Stats + '].[' + @Table_Stats + '] with fullscan' EXEC Sp_executesql @StatUpdateCommand SET @example@sqldat.com + 1 DELETE FROM #tempstatistics WHERE databasename = @DatabaseName_Stats AND tablename = @Table_Stats AND schemaname = @Schema_Stats END SET @example@sqldat.com + 1 DELETE FROM #tempdatabases WHERE databasename = @DBName END
När skriptkörningen är klar kommer alla tillfälliga tabeller att tas bort.
SELECT * FROM #tempstatistics DROP TABLE #tempdatabases DROP TABLE #tempstatistics
Hela skriptet kommer att se ut enligt följande:
--set count on CREATE PROCEDURE Statistics_maintenance AS BEGIN DECLARE @databasename VARCHAR(500) DECLARE @i INT=0 DECLARE @DBCOunt INT DECLARE @SQLCOmmand NVARCHAR(max) DECLARE @StatsUpdateCOmmand NVARCHAR(max) CREATE TABLE #tempstatistics ( databasename VARCHAR(max), tablename VARCHAR(max), schemaname VARCHAR(max) ) CREATE TABLE #tempdatabases ( databasename VARCHAR(max) ) INSERT INTO #tempdatabases (databasename) SELECT NAME FROM sys.databases WHERE database_id > 4 ORDER BY NAME SET @DBCOunt=(SELECT Count(*) FROM #tempdatabases) WHILE ( @i < @DBCOunt ) BEGIN DECLARE @DBName VARCHAR(max) SET @DBName=(SELECT TOP 1 databasename FROM #tempdatabases) SET @SQLCOmmand= ' use [' + @DBName + ']; select distinct ''' + @DBName+ ''', a.TableName,a.SchemaName from (SELECT obj.name as TableName, b.name as SchemaName,obj.object_id, stat.name, stat.stats_id, last_updated, modification_counter FROM [' + @DBName+ '].sys.objects AS obj inner join ['+ @DBName + '].sys.schemas b on obj.schema_id=b.schema_id INNER JOIN [' + @DBName+ '].sys.stats AS stat ON stat.object_id = obj.object_id CROSS APPLY [' + @DBName+'].sys.dm_db_stats_properties(stat.object_id, stat.stats_id) AS sp WHERE modification_counter > 200 and obj.name not like ''sys%''and b.name not like ''sys%'')a' INSERT INTO #tempstatistics (databasename, tablename, schemaname) EXEC Sp_executesql @SQLCOmmand DECLARE @j INT=0 DECLARE @StatCount INT SET @StatCount =(SELECT Count(*) FROM #tempstatistics) WHILE @J < @StatCount BEGIN DECLARE @DatabaseName_Stats VARCHAR(max) DECLARE @Table_Stats VARCHAR(max) DECLARE @Schema_Stats VARCHAR(max) DECLARE @StatUpdateCommand NVARCHAR(max) SET @DatabaseName_Stats=(SELECT TOP 1 databasename FROM #tempstatistics) SET @Table_Stats=(SELECT TOP 1 tablename FROM #tempstatistics) SET @Schema_Stats=(SELECT TOP 1 schemaname FROM #tempstatistics) SET @StatUpdateCommand='Update Statistics [' + @DatabaseName_Stats + '].[' + @Schema_Stats + '].[' + @Table_Stats + '] with fullscan' EXEC Sp_executesql @StatUpdateCommand SET @example@sqldat.com + 1 DELETE FROM #tempstatistics WHERE databasename = @DatabaseName_Stats AND tablename = @Table_Stats AND schemaname = @Schema_Stats END SET @example@sqldat.com + 1 DELETE FROM #tempdatabases WHERE databasename = @DBName END SELECT * FROM #tempstatistics DROP TABLE #tempdatabases DROP TABLE #tempstatistics END
Du kan också automatisera det här skriptet genom att skapa ett SQL Server Agent-jobb som kör det vid en schemalagd tidpunkt. En steg-för-steg-instruktion för att automatisera detta jobb ges nedan.
Skapa ett SQL-jobb
Låt oss först skapa ett SQL Job för att automatisera processen. För att göra det, öppna SSMS, anslut till önskad server och expandera SQL Server Agent, högerklicka på Jobb och välj Nytt jobb . 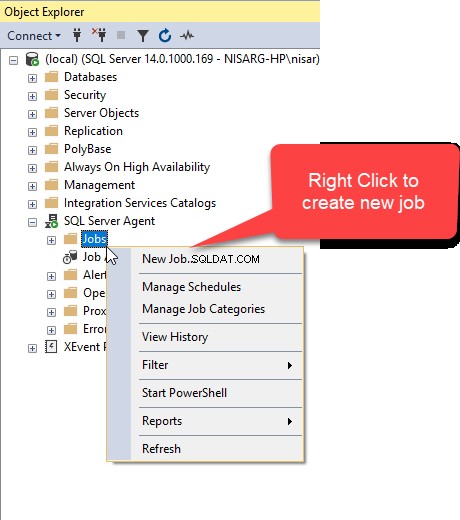 I Nya jobbet i dialogrutan, skriv önskat namn i Namn fält.
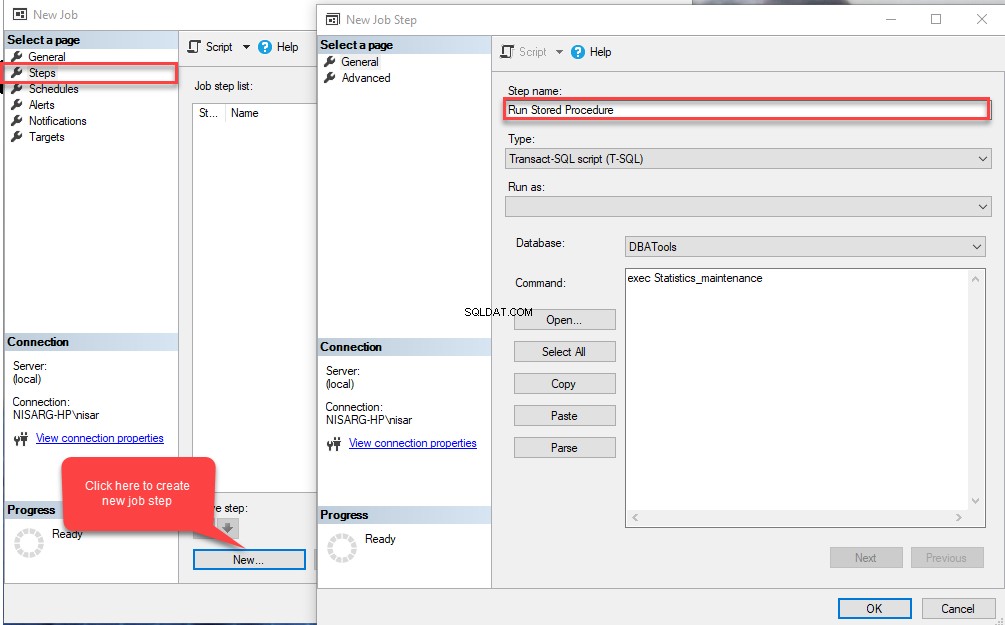
I Nya jobbet i dialogrutan, skriv önskat namn i Namn fält. 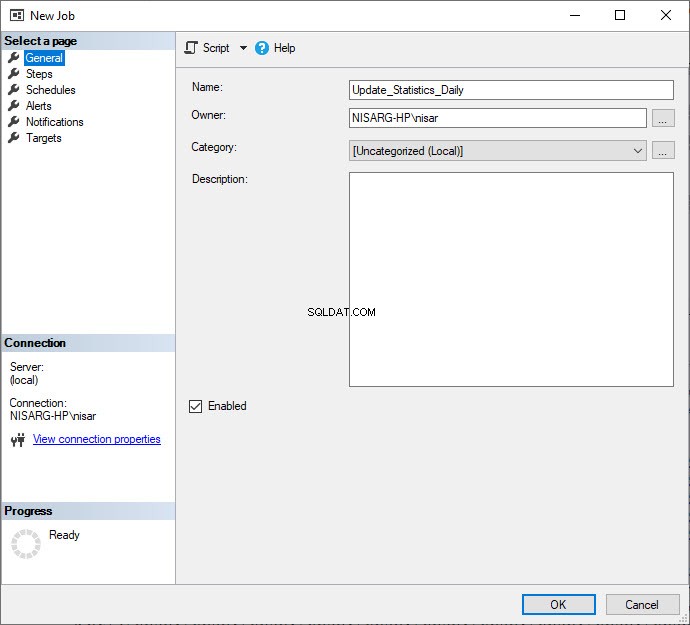 Klicka nu på Steg menyalternativet på den vänstra panelen i Nytt jobb dialogrutan och klicka sedan på Ny i stegen fönster. I steget Nytt jobb dialogrutan som öppnas, ange önskat namn i Stegnamn fält. Välj sedan Transact-SQL-skript (T-SQL) i Typ rullgardinsmenyn. Välj sedan DBATools i databasen rullgardinsmenyn och skriv följande fråga i kommandotextrutan:
Klicka nu på Steg menyalternativet på den vänstra panelen i Nytt jobb dialogrutan och klicka sedan på Ny i stegen fönster. I steget Nytt jobb dialogrutan som öppnas, ange önskat namn i Stegnamn fält. Välj sedan Transact-SQL-skript (T-SQL) i Typ rullgardinsmenyn. Välj sedan DBATools i databasen rullgardinsmenyn och skriv följande fråga i kommandotextrutan:
EXEC Statistics_maintenance
 För att konfigurera schemat för jobbet klickar du på Schedules menyalternativet i Nytt jobb dialog ruta. Nytt jobbschema dialogrutan öppnas. I Namn fältet, ange önskat schemanamn. I vårt exempel vill vi att det här jobbet ska utföras varje kväll klockan 01.00, därför i Uppstår rullgardinsmenyn i Frekvens väljer du Dagligen . I avsnittet Förekommer en gång på i fältet Daglig frekvens sektion, ange 01:00:00.
För att konfigurera schemat för jobbet klickar du på Schedules menyalternativet i Nytt jobb dialog ruta. Nytt jobbschema dialogrutan öppnas. I Namn fältet, ange önskat schemanamn. I vårt exempel vill vi att det här jobbet ska utföras varje kväll klockan 01.00, därför i Uppstår rullgardinsmenyn i Frekvens väljer du Dagligen . I avsnittet Förekommer en gång på i fältet Daglig frekvens sektion, ange 01:00:00. 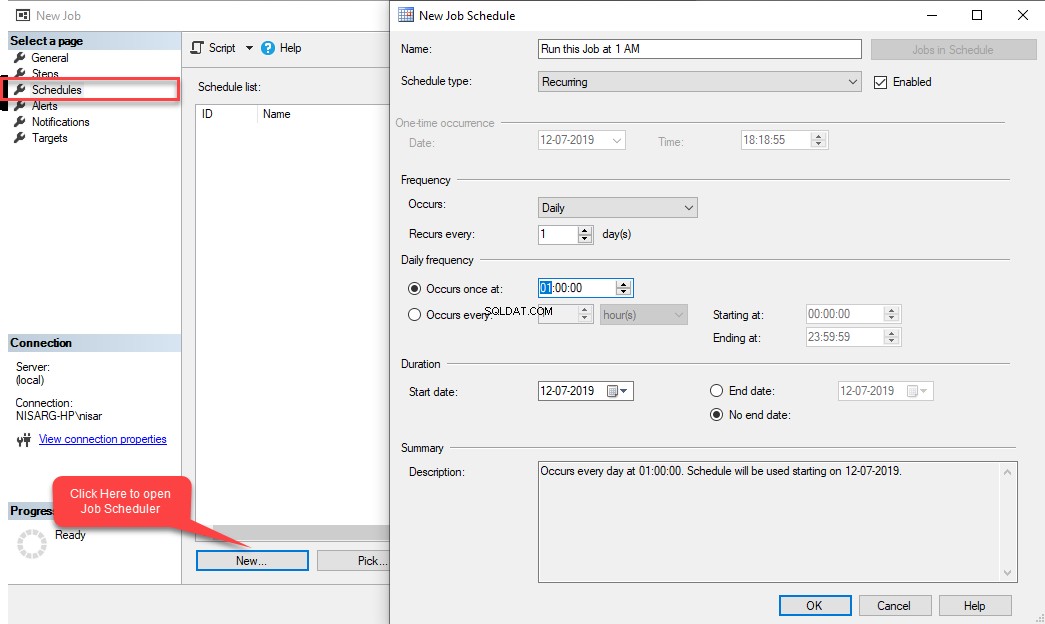 Klicka på OK för att stänga Nytt jobbschema fönstret och klicka sedan på OK igen i Nytt jobb dialogrutan för att stänga den. Låt oss nu testa det här jobbet. Under SQL Server Agent högerklickar du på Update_Statistics_Daily .
Klicka på OK för att stänga Nytt jobbschema fönstret och klicka sedan på OK igen i Nytt jobb dialogrutan för att stänga den. Låt oss nu testa det här jobbet. Under SQL Server Agent högerklickar du på Update_Statistics_Daily . 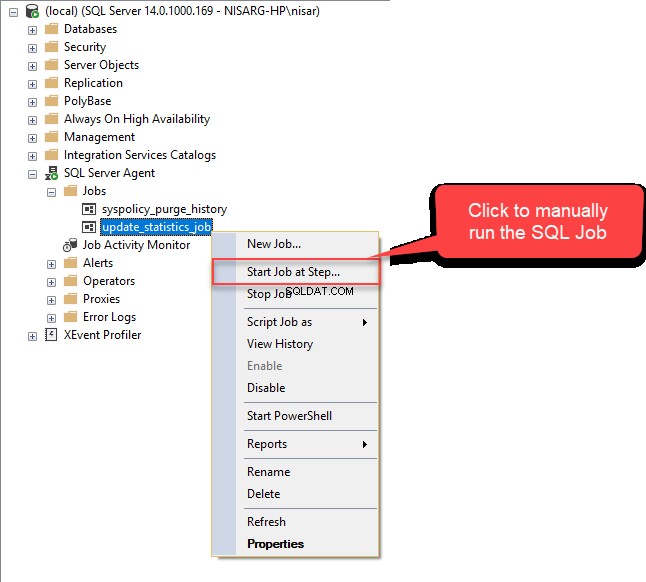 Om jobbet har utförts framgångsrikt kommer du att se följande fönster.
Om jobbet har utförts framgångsrikt kommer du att se följande fönster. 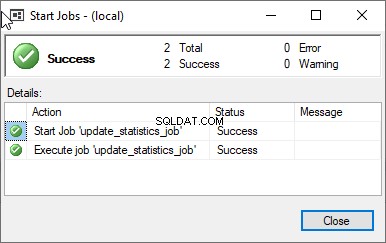
Sammanfattning
I den här artikeln har följande frågor behandlats:1. Hur man uppdaterar statistiken för tabeller med T-SQL-skript. 2. Hur man får information om förändringar i datavolym och frekvens av dataändringar. 3. Hur man skapar skriptet som uppdaterar statistik på aktiva tabeller. 4. Hur man skapar ett SQL Server Agent Job för att exekvera skriptet vid den schemalagda tiden.