I den här artikeln kommer vi att diskutera typiska fel som nybörjarutvecklare kan möta när de designar T-SQL-kod. Dessutom kommer vi att ta en titt på de bästa metoderna och några användbara tips som kan hjälpa dig när du arbetar med SQL Server, samt lösningar för att förbättra prestandan.
Innehåll:
1. Datatyper
2. *
3. Alias
4. Kolumnordning
5. NOT IN vs NULL
6. Datumformat
7. Datumfilter
8. Beräkning
9. Konvertera implicit
10. GILLA &Undertryckt index
11. Unicode vs ANSI
12. SAMMANSTÄLL
13. BINÄR SAMMANSTÄLLNING
14. Kodstil
15. [var]char
16. Datalängd
17. ISNULL vs COALESCE
18. Matte
19. UNION vs UNION ALLA
20. Läs igen
21. Underfråga
22. FALL NÄR
23. Skalär funktion
24. VISNINGAR
25. CURSORs
26. STRING_CONCAT
27. SQL-injektion
Datatyper
Huvudproblemet vi möter när vi arbetar med SQL Server är ett felaktigt val av datatyper.
Anta att vi har två identiska tabeller:
DECLARE @Employees1 TABELL ( EmployeeID BIGINT PRIMARY KEY , IsMale VARCHAR(3) , Födelsedatum VARCHAR(20))INSERT INTO @Employees1VALUES (123, 'JA', '2012-09-01')DEKLARERA Anställda2 TABELL INT PRIMARY KEY , IsMale BIT , Födelsedatum) INTO @Employees2VALUES (123, 1, '2012-09-01')
Låt oss köra en fråga för att kontrollera vad skillnaden är:
DECLARE @BirthDate DATE ='2012-09-01'SELECT * FROM @Employees1 WHERE BirthDate =@BirthDateSELECT * FROM @Employees2 WHERE BirthDate =@BirthDate
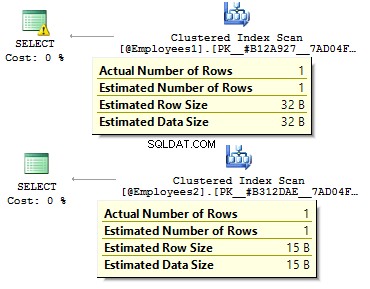
I det första fallet är datatyperna mer redundanta än de kan vara. Varför ska vi lagra ett bitvärde som JA/NEJ rad? Varför ska vi lagra ett datum som en rad? Varför ska vi använda BIGINT för anställda i tabellen, snarare än INT ?
Det leder till följande nackdelar:
- Tabell kan ta mycket utrymme på disken;
- Vi måste läsa fler sidor och lägga in mer data i BufferPool för att hantera data.
- Dålig prestanda.
*
Jag har ställts inför situationen när utvecklare hämtar all data från en tabell och sedan på klientsidan använder DataReader för att endast välja obligatoriska fält. Jag rekommenderar inte att du använder detta tillvägagångssätt:
ANVÄND AdventureWorks2014GOSET STATISTICS TIME, IO ONSELECT *FRÅN Person.PersonSELECT BusinessEntityID , FirstName , MiddleName , AfterNameFROM Person.PersonSET STATISTICS TIME, IO OFF
Det kommer att finnas en betydande skillnad i exekveringstiden för frågan. Dessutom kan det täckande indexet minska ett antal logiska läsningar.
Tabell 'Person'. Skanningsantal 1, logisk läsning 3819, fysisk läsning 3, ... SQL Server Execution Times:CPU-tid =31 ms, förfluten tid =1235 ms. Tabell 'Person'. Skanningsantal 1, logisk läsning 109, fysisk läsning 1, ... SQL Server Execution Times:CPU-tid =0 ms, förfluten tid =227 ms.
Alias
Låt oss skapa en tabell:
ANVÄND AdventureWorks2014GOIF OBJECT_ID('Sales.UserCurrency') IS NOT NULL DROP TABLE Sales.UserCurrencyGOCREATE TABLE Sales.UserCurrency ( CurrencyCode NCHAR(3) PRIMARY KEY)UPPLYSNINGAR INTO Försäljning.UserCurrency'
Anta att vi har en fråga som returnerar antalet identiska rader i båda tabellerna:
VÄLJ COUNT_BIG(*)FROM Sales.CurrencyWHERE CurrencyCode IN ( SELECT CurrencyCode FROM Sales.UserCurrency )
Allt kommer att fungera som förväntat tills någon byter namn på en kolumn i Sales.UserCurrency tabell:
EXEC sys.sp_rename 'Sales.UserCurrency.CurrencyCode', 'Code', 'COLUMN'
Därefter kommer vi att köra en fråga och se att vi får alla rader i Sales.Currency tabell, istället för 1 rad. När man bygger en exekveringsplan, på bindningsstadiet, kontrollerar SQL Server kolumnerna för Sales.UserCurrency, den kommer inte att hitta CurrencyCode där och bestämmer att denna kolumn tillhör Säljvalutan tabell. Efter det släpper en optimerare CurrencyCode =CurrencyCode skick.
Därför rekommenderar jag att du använder alias:
VÄLJ COUNT_BIG(*)FROM Sales.Currency cWHERE c.CurrencyCode IN (VÄLJ u.CurrencyCode FROM Sales.UserCurrency u )
Kolumnordning
Antag att vi har en tabell:
OM OBJECT_ID('dbo.DatePeriod') INTE ÄR NULL DROP TABLE dbo.DatePeriodGOCREATE TABLE dbo.DatePeriod ( StartDate DATE , EndDate DATE)
Vi lägger alltid in data där baserat på informationen om kolumnordningen.
INSERT INTO dbo.DatePeriodSELECT '2015-01-01', '2015-01-31'
Anta att någon ändrar ordningen på kolumner:
SKAPA TABELL dbo.DatePeriod ( EndDate DATE , StartDate DATE)
Data kommer att infogas i en annan ordning. I det här fallet är det en bra idé att explicit specificera kolumner i INSERT-satsen:
INSERT INTO dbo.DatePeriod (StartDate, EndDate)SELECT '2015-01-01', '2015-01-31'
Här är ett annat exempel:
VÄLJ TOP(1) *FRÅN dbo.DatePeriodORDER BY 2 DESC
På vilken kolumn ska vi beställa data? Det beror på kolumnordningen i en tabell. Om man ändrar ordningen får vi fel resultat.
NOT IN vs NULL
Låt oss prata om NOT IN uttalande.
Till exempel måste du skriva ett par frågor:returnera poster från den första tabellen, som inte finns i den andra tabellen och visa versen. Vanligtvis använder juniorutvecklare IN och INTE I :
DEKLÄRA @t1 TABELL (t1 INT, UNIK KLUSTERAD(t1))INSERT I @t1 VÄRDEN (1), (2)DEKLÄRA @t2 TABELL (t2 INT, UNIK KLUSTERAD(t2))INSERT I @t2 VÄRDEN (1) )VÄLJ *FRÅN @t1WHERE t1 INTE IN (VÄLJ t2 FRÅN @t2)VÄLJ *FRÅN @t1WHERE t1 IN (VÄLJ t2 FRÅN @t2)
Den första frågan returnerade 2, den andra – 1. Vidare kommer vi att lägga till ytterligare ett värde i den andra tabellen – NULL :
INSERT I @t2-VÄRDEN (1), (NULL)
När du kör frågan med NOT IN , vi kommer inte att få några resultat. Varför fungerar IN och INTE i inte? Anledningen är att SQL Server använder TRUE , FALSKT , och OKÄNDA logik när man jämför data.
När en fråga körs tolkar SQL Server IN-villkoret på följande sätt:
a IN (1, NULL) ==a=1 ELLER a=NULL
INTE I :
a NOT IN (1, NULL) ==a<>1 OCH en<>NULL
När man jämför ett värde med NULL, SQL Server returnerar UNKNOWN. Antingen1=NULL eller NULL=NULL – båda resulterar iOKÄNT. Såvitt vi har OCH i uttrycket returnerar båda sidor OKÄNT.
Jag vill påpeka att detta fall inte är ovanligt. Till exempel markerar du en kolumn som NOT NULL. Efter ett tag beslutar en annan utvecklare att tillåta NULLs för den kolumnen. Detta kan leda till situationen när en klientrapport slutar fungera när ett NULL-värde har infogats i tabellen.
I det här fallet skulle jag rekommendera att utesluta NULL-värden:
VÄLJ *FRÅN @t1WHERE t1 NOT IN (VÄLJ t2 FRÅN @t2 DÄR t2 INTE ÄR NULL)
Dessutom är det möjligt att använda UTOM :
VÄLJ * FRÅN @t1EXCEPTSELECT * FRÅN @t2
Alternativt kan du använda FINNS INTE :
VÄLJ *FRÅN @t1WHERE INTE FINNS(VÄLJ 1 FRÅN @t2 DÄR t1 =t2)
Vilket alternativ är mer att föredra? Det senare alternativet med FINNS INTE verkar vara den mest produktiva eftersom den genererar den mer optimala predikat pushdown operatör för att komma åt data från den andra tabellen.
Egentligen kan NULL-värdena returnera ett oväntat resultat.
Tänk på det i detta specifika exempel:
ANVÄND AdventureWorks2014GOSELECT COUNT_BIG(*)FROM Production.ProductSELECT COUNT_BIG(*)FROM Production.ProductWHERE Färg ='Grå'VÄLJ COUNT_BIG(*)FRÅN Production.ProductWHERE Färg <> 'Grå'
Som du kan se har du inte fått det förväntade resultatet av anledningen att NULL-värden har separata jämförelseoperatorer:
VÄLJ COUNT_BIG(*)FROM Production.ProductWHERE Color IS NULLSELECT COUNT_BIG(*)FROM Production.ProductWHERE Color IS NOT NULL
Här är ett annat exempel med CHECK begränsningar:
OM OBJECT_ID('tempdb.dbo.#temp') INTE ÄR NULL DROP TABELL #tempGOCREATE TABLE #temp ( Färg VARCHAR(15) --NULL , CONSTRAINT CK CHECK (Color IN ('Svart', 'Vit') ))
Vi skapar en tabell med tillåtelse att endast infoga vita och svarta färger:
INSERT INTO #temp VALUES ('Svart')(1 rad(er) påverkas)
Allt fungerar som förväntat.
INSERT INTO #temp VALUES ('Röd') INSERT-satsen kom i konflikt med CHECK-begränsningen...satsen har avslutats.
Nu lägger vi till NULL:
INSERT INTO #temp VALUES (NULL)(1 rad(er) påverkas)
Varför har CHECK-begränsningen passerat NULL-värdet? Tja, anledningen är att det finns tillräckligt med NOT FALSE villkor för att göra en uppteckning. Lösningen är att uttryckligen definiera en kolumn som NOT NULL eller använd NULL i begränsningen.
Datumformat
Mycket ofta kan du ha problem med datatyper.
Du behöver till exempel få det aktuella datumet. För att göra detta kan du använda GETDATE-funktionen:
VÄLJ GETDATE()
Sedan är det bara att kopiera det returnerade resultatet i en obligatorisk fråga och radera tiden:
VÄLJ *FRÅN sys.objectsWHERE create_date <'2016-11-14'
Stämmer det?
Datumet anges av en strängkonstant:
STÄLL IN SPRÅK EnglishSET DATEFORMAT DMYDECLARE @d1 DATETIME ='05/12/2016' , @d2 DATETIME ='2016/12/05' , @d3 DATETIME ='2016-12-05' , @d4 DATETIME ='05 -dec-2016'SELECT @d1, @d2, @d3, @d4
Alla värden har en envärdig tolkning:
----------- ----------- ------------------ ----------2016-12 -05 2016-05-12 2016-05-12 2016-12-05
Det kommer inte att orsaka några problem förrän frågan med denna affärslogik körs på en annan server där inställningarna kan skilja sig:
STÄLL IN DATUMFORMAT MDYDECLARE @d1 DATETIME ='05/12/2016' , @d2 DATETIME ='2016/12/05' , @d3 DATETIME ='2016-12-05' , @d4 DATETIME ='05-dec -2016'SELECT @d1, @d2, @d3, @d4
Dessa alternativ kan dock leda till en felaktig tolkning av datumet:
----------- ----------- ------------------ ----------2016-05 -12 2016-12-05 2016-12-05 2016-12-05
Dessutom kan den här koden leda till både en synlig och latent bugg.
Betrakta följande exempel. Vi måste infoga data i en testtabell. På en testserver fungerar allt perfekt:
DEKLARERA @t-TABELL (en DATUM-TID)INSERT I @t-VÄRDEN ('05/13/2016')
Ändå, på klientsidan kommer denna fråga att ha problem eftersom våra serverinställningar skiljer sig:
DEKLARERA @t TABELL (en DATUM TID)STÄLL DATUMFORMAT DMYINSERT I @t VÄRDEN ('05/13/2016') Msg 242, Level 16, State 3, Rad 28. Konverteringen av en varchar-datatyp till en datetime-datatyp resulterade i ett värde utanför intervallet.
Så vilket format ska vi använda för att deklarera datumkonstanter? För att svara på den här frågan, kör den här frågan:
STÄLL IN DATUMFORMAT YMDSET LANGUAGE EnglishDECLARE @d1 DATETIME ='2016/01/12' , @d2 DATETIME ='2016-01-12' , @d3 DATETIME ='12-jan-2016' , @d4 DATETIME ='20160112 'SELECT @d1, @d2, @d3, @d4GOSET LANGUAGE DeutschDECLARE @d1 DATETIME ='2016/01/12' , @d2 DATETIME ='2016-01-12' , @d3 DATETIME ='12-jan-2016' , @d4 DATETIME ='20160112'SELECT @d1, @d2, @d3, @d4
Tolkningen av konstanter kan variera beroende på det installerade språket:
------------ ----------- ------------------ ----------2016-01 -12 2016-01-12 2016-01-12 2016-01-12 ------------------ ------------------ ---------- ----------2016-12-01 2016-12-01 2016-01-12 2016-01-12
Därför är det bättre att använda de två sista alternativen. Jag skulle också vilja tillägga att det inte är en bra idé att uttryckligen ange datumet:
SET LANGUAGE FrenchDECLARE @d DATETIME ='12-jan-2016'Msg 241, Level 16, State 1, Line 29Échec de la conversion de la date et/ou de l'heure à partir d'une chaîne de caractères.
Därför, om du vill att konstanter med datumen ska tolkas korrekt, måste du ange dem i följande format ÅÅÅÅMMDD.
Dessutom skulle jag vilja uppmärksamma dig på beteendet hos vissa datatyper:
SET LANGUAGE EnglishSET DATEFORMAT YMDDECLARE @d1 DATE ='2016-01-12' , @d2 DATETIME ='2016-01-12'SELECT @d1, @d2GOSET LANGUAGE DeutschSET DATEFORMAT DMYDECLARE @d1 DATE ='2016-0 12' , @d2 DATETIME ='2016-01-12'SELECT @d1, @d2
Till skillnad från DATETIME, DATE typ tolkas korrekt med olika inställningar på en server:
---------- ----------2016-01-12 2016-01-12---------------- ------- ---2016-01-12 2016-12-01
Datumfilter
För att gå vidare kommer vi att överväga hur man filtrerar data effektivt. Låt oss utgå från dem DATUM TID/DATUM:
ANVÄND AdventureWorks2014GOUPDATE TOP(1) dbo.DatabaseLogSET PostTime ='20140716 12:12:12'
Nu ska vi försöka ta reda på hur många rader frågan returnerar för en angiven dag:
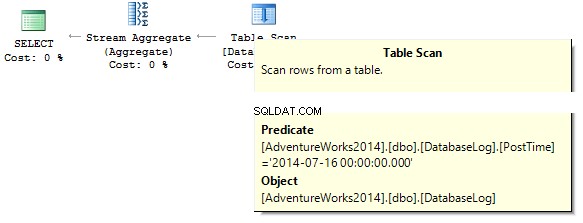
VÄLJ COUNT_BIG(*)FRÅN dbo.DatabaseLogWHERE PostTime ='20140716'
Frågan returnerar 0. När man bygger en exekveringsplan försöker SQL-servern att casta en strängkonstant till datatypen för kolumnen som vi behöver filtrera bort:
Skapa ett index:
SKAPA INKLUSTERAT INDEX IX_PostTime PÅ dbo.DatabaseLog (PostTime)
Det finns korrekta och felaktiga alternativ för att mata ut data. Du måste till exempel ta bort tidskolumnen:
VÄLJ COUNT_BIG(*)FRÅN dbo.DatabaseLogWHERE CONVERT(CHAR(8), PostTime, 112) ='20140716'VÄLJ COUNT_BIG(*)FRÅN dbo.DatabaseLogWHERE CAST(PostTime AS DATE) ='20140716'
Eller så måste vi ange ett intervall:
VÄLJ COUNT_BIG(*)FRÅN dbo.DatabaseLogWHERE PostTime MELLAN '20140716' OCH '20140716 23:59:59.997'VÄLJ COUNT_BIG(*)FRÅN dbo.DatabaseLogWHERE PostTime>='161'4AND <7172'4AND <7172'4AND>
Med hänsyn till optimering kan jag säga att dessa två frågor är de mest korrekta. Poängen är att all omvandling och beräkningar av indexkolumner som filtreras bort kan minska prestandan drastiskt och öka tiden för logiska avläsningar:
Tabell "Databaslogg". Scan count 1, logiskt läser 7, ... Tabell 'DatabasLog'. Skanna antal 1, logiskt läser 2, ...
PostTime fältet hade inte inkluderats i indexet tidigare och vi kunde inte se någon effektivitet i att använda detta korrekta tillvägagångssätt vid filtrering. En annan sak är när vi behöver mata ut data för en månad:
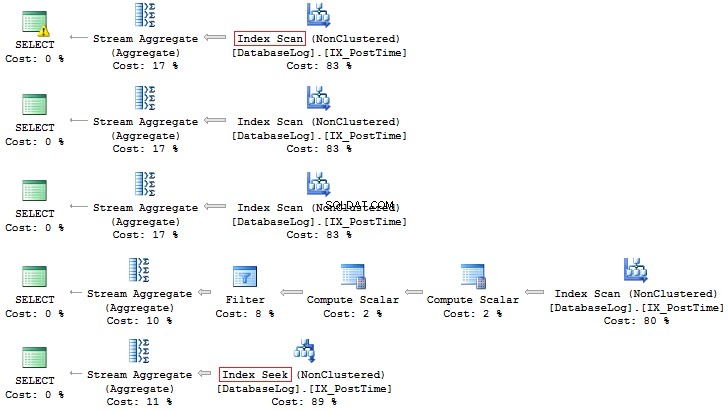
VÄLJ COUNT_BIG(*)FRÅN dbo.DatabaseLogWHERE CONVERT(CHAR(8), PostTime, 112) LIKE '201407%'VÄLJ COUNT_BIG(*)FRÅN dbo.DatabaseLogWHERE DATEPART(YEAR, PostTime) =2014PART(MÅNAD, DATUM) PostTime) =7VÄLJ COUNT_BIG(*)FRÅN dbo.DatabaseLogWHERE YEAR(PostTime) =2014 AND MONTH(PostTime) =7SELECT COUNT_BIG(*)FRÅN dbo.DatabaseLogWHERE EOMONTH(PostTime) ='2014073BIG. PostTime>='20140701' OCH PostTime <'20140801'
Återigen, det senare alternativet är mer att föredra:
Dessutom kan du alltid skapa ett index baserat på ett beräknat fält:
IF COL_LENGTH('dbo.DatabaseLog', 'MonthLastDay') IS NOT NULL ALTER TABLE dbo.DatabaseLog DROP COLUMN MonthLastDayGOALTER TABLE dbo.DatabaseLog ADD MonthLastDay AS MONTH_LastDay AS ONEMONTH_TIMEDEXMONTH.BASDADAGLOEOMONTH (PostINDDEXDAY) (PostINDDEXDAY) (MostInDEXDay).
I jämförelse med föregående fråga kan skillnaden i logiska avläsningar vara betydande (om stora tabeller är i fråga):
SET STATISTICS IO ONSELECT COUNT_BIG(*)FRÅN dbo.DatabaseLogWHERE PostTime>='20140701' AND PostTime <'20140801'VÄLJ COUNT_BIG(*)FRÅN dbo.DatabaseLogWHERE MonthLastDay4SETIOgSTIOgSTIOgSTD1SETIOgSTdAvSlAstDag'1SETIOgStIoG'STIOg'STIOG Scan count 1, logiskt läser 7, ... Tabell 'DatabasLog'. Scan count 1, logiskt läser 3, ...
Beräkning
Som det redan har diskuterats minskar alla beräkningar på indexkolumner prestandan och ökar logiktiden:
ANVÄND AdventureWorks2014GOSET STATISTICS IO ONSELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID * 2 =10000SELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID =2500 * 2SELECT=BusinessEntityIDFROMHPerson.PersonWHERE BusinessEntityWHERPERSON.Per00Tsonable Scan count 1, logiskt läser 67, ... Tabell 'Person'. Scan count 0, logiskt läser 3, ...
Om vi tittar på exekveringsplanerna, så kör SQL Server i den första IndexScan :
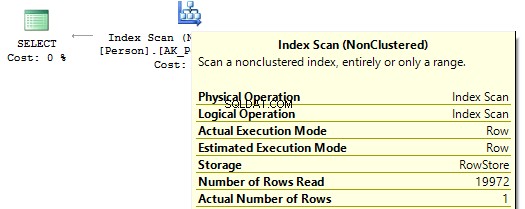
Sedan, när det inte finns några beräkningar på indexkolumnerna, ser vi IndexSeek :

Konvertera implicit
Låt oss ta en titt på dessa två frågor som filtrerar efter samma värde:
ANVÄND AdventureWorks2014GOSELECT BusinessEntityID, NationalIDNumberFROM HumanResources.EmployeeWHERE NationalIDNumber =30845SELECT BusinessEntityID, NationalIDNumberFROM HumanResources.EmployeeWHERE NationalIDNumber ='30845'
Utförandeplanerna ger följande information:
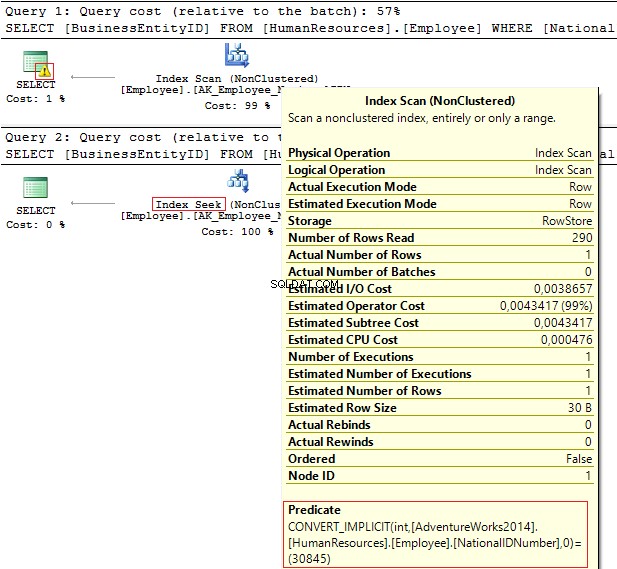
- Varning och IndexScan på den första planen
- IndexSeek – på den andra.
Tabell "Anställd". Scan count 1, logiskt läser 4, ... Tabell 'Anställd'. Scan count 0, logiskt läser 2, ...
NationalIDNumber kolumnen har NVARCHAR(15) data typ. Konstanten vi använder för att filtrera bort data är satt som INT vilket leder oss till en implicit datatypkonvertering. Det kan i sin tur minska prestandan. Du kan övervaka det när någon ändrar datatypen i kolumnen, men frågorna ändras inte.
Det är viktigt att förstå att en implicit datatypkonvertering kan leda till fel vid körning. Till exempel, innan fältet Postnummer var numeriskt visade det sig att ett postnummer kunde innehålla bokstäver. Därmed uppdaterades datatypen. Fortfarande, om vi infogar ett alfabetiskt postnummer, kommer den gamla frågan inte längre att fungera:
SELECT AddressIDFROM Person.[Address]WHERE PostalCode =92700SELECT AddressIDFROM Person.[Address]WHERE PostalCode ='92700'Msg 245, Level 16, State 1, Rad 16Konverteringen misslyckades vid konvertering av nvarchar-värdet 'K4B 1S2' int.
Ett annat exempel är när du behöver använda EntityFramework på projektet, som som standard tolkar alla radfält som Unicode:
SELECT CustomerID, AccountNumberFROM Sales.CustomerWHERE AccountNumber =N'AW00000009'SELECT CustomerID, AccountNumberFROM Sales.CustomerWHERE AccountNumber ='AW00000009'
Därför genereras felaktiga frågor:

För att lösa det här problemet, se till att datatyperna matchar.
GILLA och undertryckt index
Att ha ett täckande index betyder faktiskt inte att du kommer att använda det effektivt.
Låt oss kontrollera det på detta specifika exempel. Antag att vi måste mata ut alla rader som börjar med...
ANVÄND AdventureWorks2014GOSET STATISTICS IO ONSELECT AddressLine1FROM Person.[Address]WHERE SUBSTRING(AddressLine1, 1, 3) ='100'VÄLJ AddressLine1FROM Person.[Address]WHERE LEFT(AddressLine1, 3'SELECT) ='10.Line Adress]WHERE CAST(AddressLine1 AS CHAR(3)) ='100'VÄLJ AddressLine1FROM Person.[Address]WHERE AddressLine1 LIKE '100%'
Vi kommer att få följande logiska avläsningar och exekveringsplaner:
Tabell "Adress". Scan count 1, logiskt läser 216, ... Tabell 'Adress'. Scan count 1, logiskt läser 216, ... Tabell 'Adress'. Scan count 1, logiskt läser 216, ... Tabell 'Adress'. Scan count 1, logiskt läser 4, ...
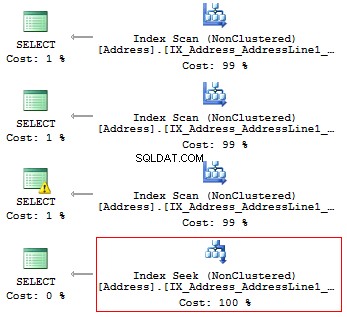
Om det finns ett index bör det alltså inte innehålla några beräkningar eller konvertering av typer, funktioner etc.
Men vad gör du om du behöver hitta förekomsten av en delsträng i en sträng?
VÄLJ AddressLine1FROM Person.[Address]WHERE AddressLine1 LIKE '%100%'v
Vi återkommer till denna fråga senare.
Unicode vs ANSI
Det är viktigt att komma ihåg att det finns UNICODE och ANSI strängar. UNICODE-typen inkluderar NVARCHAR/NCHAR (2 byte till en symbol). För att lagra ANSI strängar, är det möjligt att använda VARCHAR/CHAR (1 byte till 1 symbol). Det finns också TEXT/NTEXT , men jag rekommenderar inte att du använder dem eftersom de kan minska prestandan.
Om du anger en Unicode-konstant i en fråga är det nödvändigt att föregå den med N-symbolen. För att kontrollera det, kör följande fråga:
VÄLJ '文本 ANSI' , N'文本 UNICODE'------- ------------?? ANSI 文本 UNICODE
Om N inte föregår konstanten kommer SQL Server att försöka hitta en lämplig symbol i ANSI-kodningen. Om den inte hittar kommer den att visa ett frågetecken.
SAMLA
Mycket ofta, när en intervjuare intervjuas till positionen Middle/Senior DB-utvecklare, ställer en intervjuare ofta följande fråga:Kommer denna fråga att returnera data?
DECLARE @a NCHAR(1) ='Ё' , @b NCHAR(1) ='Ф'VÄLJ @a, @bWHERE @a =@b
Det beror på. För det första kommer N-symbolen inte före en strängkonstant, så den kommer att tolkas som ANSI. För det andra beror mycket på det aktuella COLLATE-värdet, som är en uppsättning regler, när man väljer och jämför strängdata.
ANVÄND [master]GOIF DB_ID('test') IS NOT NULL BÖRJA ÄNDRA DATABAS-test SET SINGLE_USER MED ROLLBACK OMEDELBART DROP DATABASE-testENDGOCREATE DATABASE-test SAMMANSTÄLL Latin1_General_100_CI_ASGOUSE ) ='Ф'VÄLJ @a, @bWHERE @a =@b Denna COLLATE-sats returnerar frågetecken eftersom deras symboler är lika:
---- ----? ?
Om vi ändrar COLLATE-satsen för en annan sats:
ALTER DATABASE test COLLATE Cyrillic_General_100_CI_AS
I det här fallet returnerar frågan ingenting, eftersom kyrilliska tecken kommer att tolkas korrekt.
Därför, om en strängkonstant tar upp UNICODE, är det nödvändigt att sätta N före en strängkonstant. Ändå skulle jag inte rekommendera att ställa in den överallt av de skäl som vi har diskuterat ovan.
En annan fråga som ska ställas under intervjun avser jämförelse av rader.
Tänk på följande exempel:
DECLARE @a VARCHAR(10) ='TEXT' , @b VARCHAR(10) ='text'SELECT IIF(@a =@b, 'TRUE', 'FALSE')
Är dessa rader lika? För att kontrollera detta måste vi uttryckligen ange COLLATE:
DECLARE @a VARCHAR(10) ='TEXT' , @b VARCHAR(10) ='text'SELECT IIF(@a COLLATE Latin1_General_CS_AS =@b COLLATE Latin1_General_CS_AS, 'TRUE', 'FALSE')
Eftersom det finns skiftlägeskänsliga (CS) och skiftlägesokänsliga (CI) COLLATEs när man jämför och väljer rader, kan vi inte säga säkert om de är lika. Dessutom finns det olika COLLATEs både på en testserver och en klientsida.
Det finns ett fall när COLLATEs av en målbas och tempdb stämmer inte.
Skapa en databas med COLLATE:
ANVÄND [master]GOIF DB_ID('test') IS NOT NULL BÖRJA ÄNDRA DATABAS-test SET SINGLE_USER MED ROLLBACK OMEDELBART DROP DATABASE-testENDGOCREATE DATABASE-test SAMLA Albanian_100_CS_ASGOUSE testGOCREATE CHERTTO1t (VÄRDE IN TABLE 1t) (VÄRDE) ')GOIF OBJECT_ID('tempdb.dbo.#t1') IS NOT NULL DROP TABLE #t1IF OBJECT_ID('tempdb.dbo.#t2') IS NOT NULL DROP TABLE #t2IF OBJECT_ID('tempdb.dbo.#t3') ÄR INTE NULL DROP TABELL #t3GOCREATE TABELL #t1 (c CHAR(1))INSERT INTO #t1-VÄRDEN ('a')SKAPA TABELL #t2 (c CHAR(1) SAMMANSTÄLL databas_default)INSERT INTO #t2-VÄRDEN ('a') SELECT c =CAST('a' SOM CHAR(1))INTO #t3DECLARE @t TABLE (c VARCHAR(100))INSERT INTO @t VALUES ('a')SELECT 'tempdb', DATABASEPROPERTYEX('tempdb', 'kollation ')UNION ALLSELECT 'test', DATABASEPROPERTYEX(DB_NAME(), 'kollation')UNION ALLSELECT 't', SQL_VARIANT_PROPERTY(c, 'kollation') FRÅN tUNION ALLSELECT '#t1', SQL_VARIANT_PROPERTY(c, 'kollation') FRÅN # t1UNION ALLSELECT '#t2', SQL_VARIANT_PROPERTY(c, 'kollation') FROM # t2UNION ALLSELECT '#t3', SQL_VARIANT_PROPERTY(c, 'kollation') FRÅN #t3UNION ALLSELECT '@t', SQL_VARIANT_PROPERTY(c, 'kollation') FRÅN @t När du skapar en tabell ärver den COLLATE från en databas. Den enda skillnaden för den första temporära tabellen, för vilken vi bestämmer en struktur explicit utan COLLATE, är att den ärver COLLATE från tempdb databas.
------ --------------------------tempdb Cyrillic_General_CI_AStest Albanian_100_CS_ASt Albanian_100_CS_AS#t1 Cyrillic_General_CI_AS#t2 Albanian_100_CS_AS#t3 Albanian_100_CS_AS@t Albanian_100_CS_AS
Jag kommer att beskriva fallet när COLLATEs inte matchar i det specifika exemplet med #t1.
Data filtreras till exempel inte bort korrekt, eftersom COLLATE kanske inte tar hänsyn till ett fall:
VÄLJ *FROM #t1WHERE c ='A'
Alternativt kan vi ha en konflikt för att koppla tabeller med olika COLLATEs:
VÄLJ *FRÅN #t1JOIN t ON [#t1].c =t.c
Allt verkar fungera perfekt på en testserver, medan vi på en klientserver får ett felmeddelande:
Msg 468, Level 16, State 9, Line 93Kan inte lösa kollationskonflikten mellan "Albanian_100_CS_AS" och "Cyrillic_General_CI_AS" i lika med operationen.
För att komma runt det måste vi ställa in hackor överallt:
VÄLJ *FRÅN #t1JOIN t ON [#t1].c =t.c COLLATE database_default
BINÄR SAMMANSTÄLLNING
Nu kommer vi att ta reda på hur du använder COLLATE till din fördel.
Tänk på exemplet med förekomsten av en delsträng i en sträng:
VÄLJ AddressLine1FROM Person.[Address]WHERE AddressLine1 LIKE '%100%'
Det är möjligt att optimera den här frågan och minska dess körningstid.
Först måste vi skapa en stor tabell:
ANVÄND [master]GOIF DB_ID('test') IS NOT NULL BÖRJA ÄNDRA DATABAS-test SET SINGLE_USER MED ROLLBACK OMEDELBART DROP DATABASE-testENDGOCREATE DATABASE-test SAMMANSTÄLL Latin1_General_100_CS_ASGOALTER DATABASE-test =MBYFIZEGO-test =MBYFIZEGO'(MODUSNAMN =MBYFIZEGO') DATABAS test MODIFIERA FIL (NAMN =N'test_log', STORLEK =64MB)GOUSE testGOCREATE TABELL t ( ansi VARCHAR(100) NOT NULL , unicod NVARCHAR(100) NOT NULL)GO;WITH E1(N) AS ( SELECT * FROM ( VÄRDEN (1),(1),(1),(1),(1), (1),(1),(1),(1),(1) ) t(N) ), E2(N ) AS (VÄLJ 1 FRÅN E1 a, E1 b), E4(N) AS (VÄLJ 1 FRÅN E2 a, E2 b), E8(N) AS (VÄLJ 1 FRÅN E4 a, E4 b)INSERT INTO tSELECT v, vFROM ( SELECT TOP(50000) v =REPLACE(CAST(NEWID() AS VARCHAR(36)) + CAST(NEWID() AS VARCHAR(36)), '-', '') FROM E8) t Skapa beräknade kolumner med binära COLLATEs och index:
ALTER TABLE t ADD ansi_bin AS UPPER(ansi) COLLATE Latin1_General_100_Bin2ALTER TABLE t ADD unicod_bin AS UPPER(unicod) COLLATE Latin1_General_100_BIN2CREATE ICKELUSTERED INDEX nEXLUSTERED INDEX (EXLUSTERED INDEX) INGENICOdCON (EXLUSTERED INDEX) ansicod ansi_bin) SKAPA ECKLUSTERAT INDEX unicod_bin ON t (unicod_bin)
Utför filtreringsprocessen:
STÄLL IN STATISTIK TID, IO ONSELECT COUNT_BIG(*)FROM TWHERE ansi LIKE '%AB%'SELECT COUNT_BIG(*)FROM TWHERE unicod LIKE '%AB%'SELECT COUNT_BIG(*)FROM TWHERE ansi_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2SELECT COUNT_BIG(*)FROM tWHERE unicod_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2SET STATISTICS TIME, IO OFF
Som du kan se returnerar denna fråga följande resultat:
SQL Server Execution Times:CPU-tid =350 ms, förfluten tid =354 ms.SQL Server Execution Times:CPU-tid =335 ms, förfluten tid =355 ms.SQL Server Execution Times:CPU-tid =16 ms, förfluten tid =18 ms.SQL-serverexekveringstider:CPU-tid =17 ms, förfluten tid =18 ms.
Poängen är att filter baserat på den binära jämförelsen tar mindre tid. Således, om du behöver filtrera förekomsten av strängar ofta och snabbt, är det möjligt att lagra data med COLLATE som slutar med BIN. Det bör dock noteras att alla binära COLLATEs är skiftlägeskänsliga.
Kodstil
En kodningsstil är strikt individuell. Ändå bör den här koden helt enkelt underhållas av andra utvecklare och matcha vissa regler.
Skapa en separat databas och en tabell inuti:
ANVÄND [master]GOIF DB_ID('test') IS NOT NULL BÖRJA ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK OMEDELBART DROP DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_General_CI_ASGOUSE testGOCREATE KYNTABAS ANVÄNDNING (pre-anställd)
Skriv sedan frågan:
välj anställd-id från anställd
Ändra nu COLLATE till valfri skiftlägeskänslig:
ALTER DATABASE test COLLATE Latin1_General_CS_AI
Försök sedan att köra frågan igen:
Msg 208, Level 16, State 1, Rad 19Ogiltigt objektnamn 'employee'.
En optimerare använder regler för den aktuella COLLATE i bindningssteget när den söker efter tabeller, kolumner och andra objekt, och den jämför varje objekt i syntaxträdet med ett verkligt objekt i en systemkatalog.
Om du vill generera frågor manuellt måste du alltid använda rätt skiftläge i objektnamn.
När det gäller variabler ärvs COLLATEs från huvuddatabasen. Därför måste du använda rätt fall för att arbeta med dem också:
SELECT DATABASEPROPERTYEX('master', 'kollation')DECLARE @EmpID INT =1SELECT @empid
I det här fallet kommer du inte att få ett felmeddelande:
-----------------------Cyrillic_General_CI_AS-----1
Ändå kan ett fallfel visas på en annan server:
--------------------------Latin1_General_CS_ASMsg 137, nivå 15, tillstånd 2, rad 4 Måste deklarera skalärvariabeln "@empid".
[var]char
Som ni vet finns det fixade (CHAR , NCHAR ) och variabel (VARCHAR , NVARCHAR ) datatyper:
DECLARE @a CHAR(20) ='text' , @b VARCHAR(20) ='text'VÄLJ LEN(@a) , LEN(@b) , DATALENGTH(@a) , DATALENGTH(@b) , '"' + @a + '"' , '"' + @b + '"'VÄLJ [a =b] =IIF(@a =@b, 'TRUE', 'FALSE'), [b =a] =IIF(@b =@a, 'TRUE', 'FALSE'), [a LIKE b] =IIF(@a LIKE @b, 'TRUE', 'FALSE') , [b LIKE a] =IIF(@ b GILLA @a, 'TRUE', 'FALSE')
Om en rad har en fast längd, säg 20 symboler, men du bara har skrivit 4 symboler, kommer SQL Server att lägga till 16 tomrum till höger som standard:
--- --- ---- ---- ---------------------------- ----------- ----------4 4 20 4 "text" "text"
In addition, it is important to understand that when comparing rows with =, blanks on the right are not taken into account:
a =b b =a a LIKE b b LIKE a----- ----- -------- --------TRUE TRUE TRUE FALSE
As for the LIKE operator, blanks will be always inserted.
SELECT 1WHERE 'a ' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a ' -- !!!SELECT 1WHERE 'a' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a%'
Data length
It is always necessary to specify type length.
Consider the following example:
DECLARE @a DECIMAL , @b VARCHAR(10) ='0.1' , @c SQL_VARIANTSELECT @a =@b , @c =@aSELECT @a , @c , SQL_VARIANT_PROPERTY(@c,'BaseType') , SQL_VARIANT_PROPERTY(@c,'Precision') , SQL_VARIANT_PROPERTY(@c,'Scale')
As you can see, the type length was not specified explicitly. Thus, the query returned an integer instead of a decimal value:
---- ---- ---------- ----- -----0 0 decimal 18 0
As for rows, if you do not specify a row length explicitly, then its length will contain only 1 symbol:
----- ------------------------------------------ ---- ---- ---- ----40 123456789_123456789_123456789_123456789_ 1 1 30 30
In addition, if you do not need to specify a length for CAST/CONVERT, then only 30 symbols will be used.
ISNULL vs COALESCE
There are two functions:ISNULL and COALESCE. On the one hand, everything seems to be simple. If the first operator is NULL, then it will return the second or the next operator, if we talk about COALESCE. On the other hand, there is a difference – what will these functions return?
DECLARE @a CHAR(1) =NULLSELECT ISNULL(@a, 'NULL'), COALESCE(@a, 'NULL')DECLARE @i INT =NULLSELECT ISNULL(@i, 7.1), COALESCE(@i, 7.1)
The answer is not obvious, as the ISNULL function converts to the smallest type of two operands, whereas COALESCE converts to the largest type.
---- ----N NULL---- ----7 7.1
As for performance, ISNULL will process a query faster, COALESCE is split into the CASE WHEN operator.
Math
Math seems to be a trivial thing in SQL Server.
SELECT 1 / 3SELECT 1.0 / 3
However, it is not. Everything depends on the fact what data is used in a query. If it is an integer, then it returns the integer result.
-----------0-----------0.333333
Also, let’s consider this particular example:
SELECT COUNT(*) , COUNT(1) , COUNT(val) , COUNT(DISTINCT val) , SUM(val) , SUM(DISTINCT val)FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)SELECT AVG(val) , SUM(val) / COUNT(val) , AVG(val * 1.) , AVG(CAST(val AS FLOAT))FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)
This query COUNT(*)/COUNT(1) will return the total amount of rows. COUNT on the column will return the amount of non-NULL rows. If we add DISTINCT, then it will return the amount of non-NULL unique values.
The AVG operation is divided into SUM and COUNT. Thus, when calculating an average value, NULL is not applicable.
UNION vs UNION ALL
When the data is not overridden, then it is better to use UNION ALL to improve performance. In order to avoid replication, you may use UNION.
Still, if there is no replication, it is preferable to use UNION ALL:
SELECT [object_id]FROM sys.system_objectsUNIONSELECT [object_id]FROM sys.objectsSELECT [object_id]FROM sys.system_objectsUNION ALLSELECT [object_id]FROM sys.objects
Also, I would like to point out the difference of these operators:the UNION operator is executed in a parallel way, the UNION ALL operator – in a sequential way.
Assume, we need to retrieve 1 row on the following conditions:
DECLARE @AddressLine NVARCHAR(60)SET @AddressLine ='4775 Kentucky Dr.'SELECT TOP(1) AddressIDFROM Person.[Address]WHERE AddressLine1 =@AddressLine OR AddressLine2 =@AddressLine
As we have OR in the statement, we will receive IndexScan:
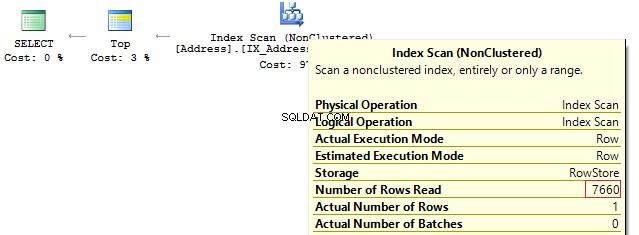
Table 'Address'. Scan count 1, logical reads 90, ...
Now, we will re-write the query using UNION ALL:
SELECT TOP(1) AddressIDFROM ( SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine1 =@AddressLine UNION ALL SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine2 =@AddressLine) t
When the first subquery had been executed, it returned 1 row. Thus, we have received the required result, and SQL Server stopped looking for, using the second subquery:
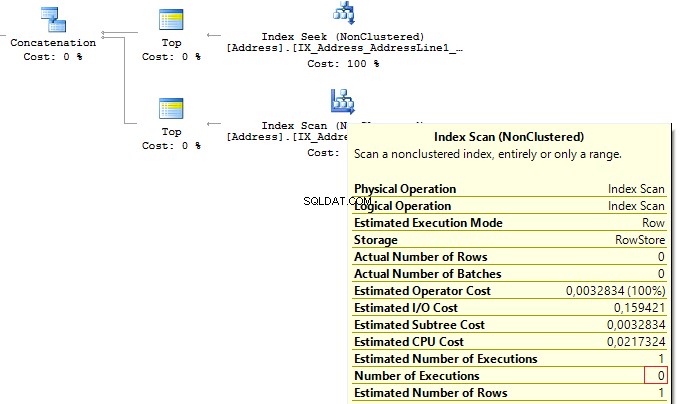
Table 'Worktable'. Scan count 0, logical reads 0, ...Table 'Address'. Scan count 1, logical reads 3, ...
Re-read
Very often, I faced the situation when the data can be retrieved with one JOIN. In addition, a lot of subqueries are created in this query:
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT e.BusinessEntityID , ( SELECT p.LastName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID ) , ( SELECT p.FirstName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID )FROM HumanResources.Employee eSELECT e.BusinessEntityID , p.LastName , p.FirstNameFROM HumanResources.Employee eJOIN Person.Person p ON e.BusinessEntityID =p.BusinessEntityID
The fewer there are unnecessary table lookups, the fewer logical readings we have:
Table 'Person'. Scan count 0, logical reads 1776, ...Table 'Employee'. Scan count 1, logical reads 2, ...Table 'Person'. Scan count 0, logical reads 888, ...Table 'Employee'. Scan count 1, logical reads 2, ...
SubQuery
The previous example works only if there is a one-to-one connection between tables.
Assume tables Person.Person and Sales.SalesPersonQuotaHistory were directly connected. Thus, one employee had only one record for a share size.
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT p.BusinessEntityID , ( SELECT s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID )FROM Person.Person p
However, as settings on the client server may differ, this query may lead to the following error:
Msg 512, Level 16, State 1, Line 6Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <=,>,>=or when the subquery is used as an expression.
It is possible to solve such issues by adding TOP(1) and ORDER BY. Using the TOP operation makes an optimizer force using IndexSeek. The same refers to using OUTER/CROSS APPLY with TOP:
SELECT p.BusinessEntityID , ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC )FROM Person.Person pSELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pOUTER APPLY ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC) t
When executing these queries, we will get the same issue – multiple IndexSeek operators:
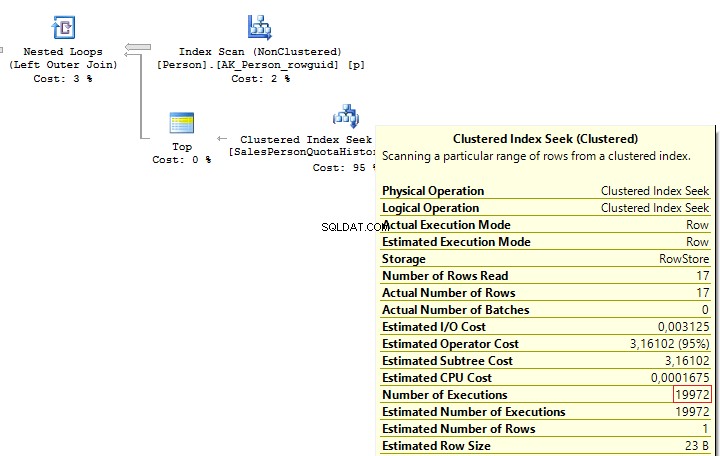
Table 'SalesPersonQuotaHistory'. Scan count 19972, logical reads 39944, ...Table 'Person'. Scan count 1, logical reads 67, ...
Re-write this query with a window function:
SELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pLEFT JOIN ( SELECT s.BusinessEntityID , s.SalesQuota , RowNum =ROW_NUMBER() OVER (PARTITION BY s.BusinessEntityID ORDER BY s.QuotaDate DESC) FROM Sales.SalesPersonQuotaHistory s) t ON p.BusinessEntityID =t.BusinessEntityID AND t.RowNum =1
We get the following result:
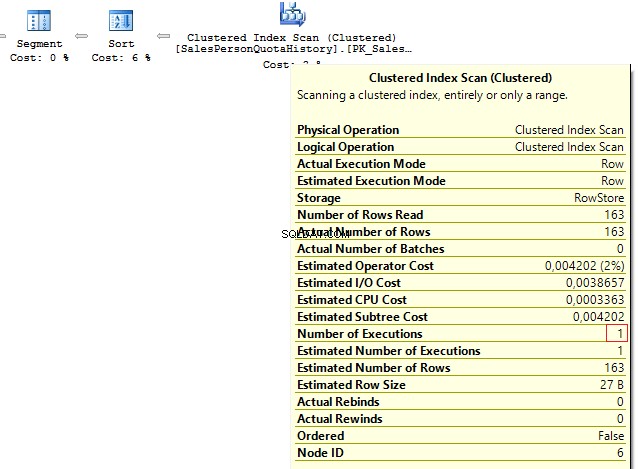
Table 'Person'. Scan count 1, logical reads 67, ...Table 'SalesPersonQuotaHistory'. Scan count 1, logical reads 4, ...
CASE WHEN
Since this operator is used very often, I would like to specify its features. Regardless, how we wrote the CASE WHEN operator:
USE AdventureWorks2014GOSELECT BusinessEntityID , Gender , Gender =CASE Gender WHEN 'M' THEN 'Male' WHEN 'F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.Employee
SQL Server will decompose the statement to the following:
SELECT BusinessEntityID , Gender , Gender =CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.Employee
Thus, this will lead to the main issue:each condition will be executed in a sequential order until one of them returns TRUE or ELSE.
Consider this issue on a particular example. To do this, we will create a scalar-valued function which will return the right part of a postal code:
IF OBJECT_ID('dbo.GetMailUrl') IS NOT NULL DROP FUNCTION dbo.GetMailUrlGOCREATE FUNCTION dbo.GetMailUrl( @Email NVARCHAR(50))RETURNS NVARCHAR(50)AS BEGIN RETURN SUBSTRING(@Email, CHARINDEX('@', @Email) + 1, LEN(@Email))END
Then, configure SQL Profiler to build SQL events:StmtStarting / SP:StmtCompleted (if you want to do this with XEvents :sp_statement_starting / sp_statement_completed ).
Execute the query:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) --WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddress
The function will be executed for 10 times. Now, delete a comment from the condition:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddress
In this case, the function will be executed for 20 times. The thing is that it is not necessary for a statement to be a must function in CASE. It may be a complicated calculation. As it is possible to decompose CASE, it may lead to multiple calculations of the same operators.
You may avoid it by using subqueries:
SELECT EmailAddressID , EmailAddress , CASE MailUrl WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM ( SELECT TOP(10) EmailAddressID , EmailAddress , MailUrl =dbo.GetMailUrl(EmailAddress) FROM Person.EmailAddress) t
In this case, the function will be executed 10 times.
In addition, we need to avoid replication in the CASE operator:
SELECT DISTINCT CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='M' THEN '...' WHEN Gender ='M' THEN '......' WHEN Gender ='F' THEN 'Female' WHEN Gender ='F' THEN '...' ELSE 'Unknown' ENDFROM HumanResources.Employee
Though statements in CASE are executed in a sequential order, in some cases, SQL Server may execute this operator with aggregate functions:
DECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE 1/0 ENDGODECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE MIN(1/0) END
Scalar func
It is not recommended to use scalar functions in T-SQL queries.
Consider the following example:
USE AdventureWorks2014GOUPDATE TOP(1) Person.[Address]SET AddressLine2 =AddressLine1GOIF OBJECT_ID('dbo.isEqual') IS NOT NULL DROP FUNCTION dbo.isEqualGOCREATE FUNCTION dbo.isEqual( @val1 NVARCHAR(100), @val2 NVARCHAR(100))RETURNS BITAS BEGIN RETURN CASE WHEN (@val1 IS NULL AND @val2 IS NULL) OR @val1 =@val2 THEN 1 ELSE 0 ENDEND
The queries return the identical data:
SET STATISTICS TIME ONSELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE dbo.IsEqual(AddressLine1, AddressLine2) =1SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE (AddressLine1 IS NULL AND AddressLine2 IS NULL) OR AddressLine1 =AddressLine2SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE AddressLine1 =ISNULL(AddressLine2, '')SET STATISTICS TIME OFF
However, as each call of the scalar function is a resource-intensive process, we can monitor this difference:
SQL Server Execution Times:CPU time =63 ms, elapsed time =57 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.
In addition, when using a scalar function, it is not possible for SQL Server to build parallel execution plans, which may lead to poor performance in a huge volume of data.
Sometimes scalar functions may have a positive effect. For example, when we have SCHEMABINDING in the statement:
IF OBJECT_ID('dbo.GetPI') IS NOT NULL DROP FUNCTION dbo.GetPIGOCREATE FUNCTION dbo.GetPI ()RETURNS FLOATWITH SCHEMABINDINGAS BEGIN RETURN PI()ENDGOSELECT dbo.GetPI()FROM Sales.Currency
In this case, the function will be considered as deterministic and executed 1 time.
VIEWs
Here I would like to talk about features of views.
Create a test table and view on its base:
IF OBJECT_ID('dbo.tbl', 'U') IS NOT NULL DROP TABLE dbo.tblGOCREATE TABLE dbo.tbl (a INT, b INT)GOINSERT INTO dbo.tbl VALUES (0, 1)GOIF OBJECT_ID('dbo.vw_tbl', 'V') IS NOT NULL DROP VIEW dbo.vw_tblGOCREATE VIEW dbo.vw_tblAS SELECT * FROM dbo.tblGOSELECT * FROM dbo.vw_tbl
As you can see, we get the correct result:
a b----------- -----------0 1
Now, add a new column in the table and retrieve data from the view:
ALTER TABLE dbo.tbl ADD c INT NOT NULL DEFAULT 2GOSELECT * FROM dbo.vw_tbl
We receive the same result:
a b----------- -----------0 1
Thus, we need either to explicitly set columns or recompile a script object to get the correct result:
EXEC sys.sp_refreshview @viewname =N'dbo.vw_tbl'GOSELECT * FROM dbo.vw_tbl
Result:
a b c----------- ----------- -----------0 1 2
When you directly refer to the table, this issue will not take place.
Now, I would like to discuss a situation when all the data is combined in one query as well as wrapped in one view. I will do it on this particular example:
ALTER VIEW HumanResources.vEmployeeAS SELECT e.BusinessEntityID , p.Title , p.FirstName , p.MiddleName , p.LastName , p.Suffix , e.JobTitle , pp.PhoneNumber , pnt.[Name] AS PhoneNumberType , ea.EmailAddress , p.EmailPromotion , a.AddressLine1 , a.AddressLine2 , a.City , sp.[Name] AS StateProvinceName , a.PostalCode , cr.[Name] AS CountryRegionName , p.AdditionalContactInfo FROM HumanResources.Employee e JOIN Person.Person p ON p.BusinessEntityID =e.BusinessEntityID JOIN Person.BusinessEntityAddress bea ON bea.BusinessEntityID =e.BusinessEntityID JOIN Person.[Address] a ON a.AddressID =bea.AddressID JOIN Person.StateProvince sp ON sp.StateProvinceID =a.StateProvinceID JOIN Person.CountryRegion cr ON cr.CountryRegionCode =sp.CountryRegionCode LEFT JOIN Person.PersonPhone pp ON pp.BusinessEntityID =p.BusinessEntityID LEFT JOIN Person.PhoneNumberType pnt ON pp.PhoneNumberTypeID =pnt.PhoneNumberTypeID LEFT JOIN Person.EmailAddress ea ON p.BusinessEntityID =ea.BusinessEntityID
What should you do if you need to get only a part of information? For example, you need to get Fist Name and Last Name of employees:
SELECT BusinessEntityID , FirstName , LastNameFROM HumanResources.vEmployeeSELECT p.BusinessEntityID , p.FirstName , p.LastNameFROM Person.Person pWHERE p.BusinessEntityID IN ( SELECT e.BusinessEntityID FROM HumanResources.Employee e )
Look at the execution plan in the case of using a view:
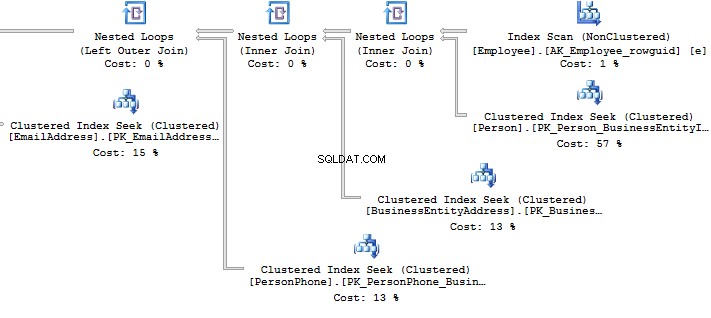
Table 'EmailAddress'. Scan count 290, logical reads 640, ...Table 'PersonPhone'. Scan count 290, logical reads 636, ...Table 'BusinessEntityAddress'. Scan count 290, logical reads 636, ...Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...
Now, we will compare it with the query we have written manually:
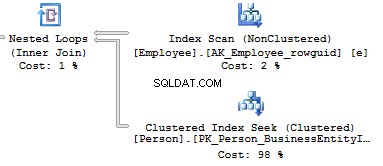
Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...
When creating an execution plan, an optimizer in SQL Server drops unused connections.
However, sometimes when there is no valid foreign key between tables, it is not possible to check whether a connection will impact the sample result. It may also be applied to the situation when tables are connecteCURSORs
I recommend that you do not use cursors for iteration data modification.
You can see the following code with a cursor:
DECLARE @BusinessEntityID INTDECLARE cur CURSOR FOR SELECT BusinessEntityID FROM HumanResources.EmployeeOPEN curFETCH NEXT FROM cur INTO @BusinessEntityIDWHILE @@FETCH_STATUS =0 BEGIN UPDATE HumanResources.Employee SET VacationHours =0 WHERE BusinessEntityID =@BusinessEntityID FETCH NEXT FROM cur INTO @BusinessEntityIDENDCLOSE curDEALLOCATE cur
Though, it is possible to re-write the code by dropping the cursor:
UPDATE HumanResources.EmployeeSET VacationHours =0WHERE VacationHours <> 0
In this case, it will improve performance and decrease the time to execute a query.
STRING_CONCAT
To concatenate rows, the STRING_CONCAT could be used. However, as there is no such a function in the SQL Server, we will do this by assigning a value to the variable.
To do this, create a test table:
IF OBJECT_ID('tempdb.dbo.#t') IS NOT NULL DROP TABLE #tGOCREATE TABLE #t (i CHAR(1))INSERT INTO #tVALUES ('1'), ('2'), ('3')
Then, assign values to the variable:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tSELECT @txt--------123
Everything seems to be working fine. However, MS hints that this way is not documented and you may get this result:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tORDER BY LEN(i)SELECT @txt--------3
Alternatively, it is a good idea to use XML as a workaround:
SELECT [text()] =iFROM #tFOR XML PATH('')--------123
It should be noted that it is necessary to concatenate rows per each data, rather than into a single set of data:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'------------------------ ------------------------------------ScrapReason ScrapReasonID, Name, ModifiedDateShift ShiftID, Name, StartTime, EndTime
In addition, it is recommended that you should avoid using the XML method for parsing as it is a high-runner process:
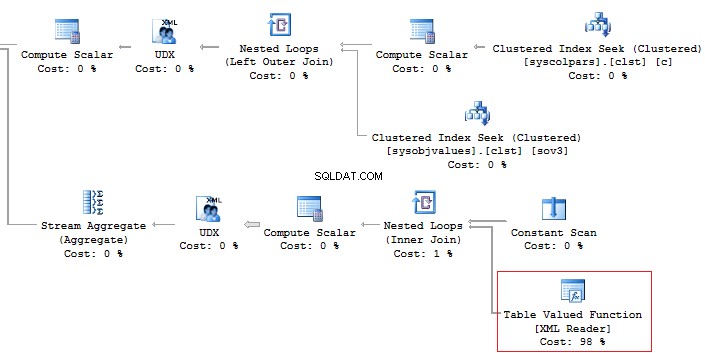
Alternatively, it is possible to do this less time-consuming:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
But, it does not change the main point.
Now, execute the query without using the value method:
SELECT t.name , STUFF(( SELECT ', ' + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
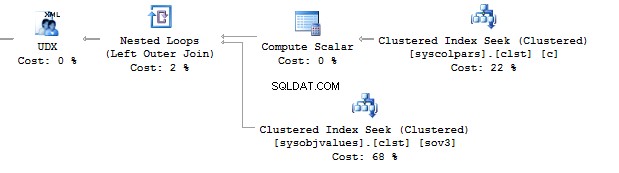
This option would work perfect. However, it may fail. If you want to check it, execute the following query:
SELECT t.name , STUFF(( SELECT ', ' + CHAR(13) + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
If there are special symbols in rows, such as tabulation, line break, etc., then we will get incorrect results.
Thus, if there are no special symbols, you can create a query without the value method, otherwise, use value(‘(./text())[1]’… .
SQL Injection
Assume we have a code:
DECLARE @param VARCHAR(MAX)SET @param =1DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =' + @paramPRINT @SQLEXEC (@SQL)
Create the query:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1
If we add any additional value to the property,
SET @param ='1; select ''hack'''
Then our query will be changed to the following construction:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1; select 'hack'
This is called SQL injection when it is possible to execute a query with any additional information.
If the query is formed with String.Format (or manually) in the code, then you may get SQL injection:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( string.Format("SELECT TOP(5) name FROM sys.objects WHERE schema_id ={0}", value), conn); using (SqlDataReader reader =command.ExecuteReader()) { while (reader.Read()) {} }}
When you use sp_executesql and properties as shown in this code:
DECLARE @param VARCHAR(MAX)SET @param ='1; select ''hack'''DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id'PRINT @SQLEXEC sys.sp_executesql @SQL , N'@schema_id INT' , @schema_id =@param
It is not possible to add some information to the property.
In the code, you may see the following interpretation of the code:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( "SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id", conn); command.Parameters.Add(new SqlParameter("schema_id", value)); ...} Sammanfattning
Working with databases is not as simple as it may seem. There are a lot of points you should keep in mind when writing T-SQL queries.
Of course, it is not the whole list of pitfalls when working with SQL Server. Still, I hope that this article will be useful for newbies.