Det finns så mycket man kan säga om historia och betydelse. Historien om ett land, om civilisationen, om var och en av oss. Jag älskar citat och gillar den här från Teddy Roosevelt (cool kille):
Ju mer du vet om det förflutna, desto bättre förberedd är du för framtiden.Varför är jag poetisk (eller försöker) om historien i en blogg om SQL Server? För historik i SQL Server är också viktig. När ett prestandaproblem finns i SQL Server är det idealiskt att felsöka problemet live, men i vissa fall kan historisk information ge en rykande pistol, eller åtminstone en utgångspunkt. En stor källa till historisk information i SQL Server är ERRORLOG. Jag nämnde i mitt ursprungliga inlägg, Performance Issues:The First Encounter, att ERRORLOGGEN brukade vara en eftertanke för mig. Inte mer. Under klientrevisioner fångar vi alltid ERRORLOGS, och även om vi underrättas för alla varningar med hög allvarlighet (som skrivs till loggen), är det inte ovanligt att hitta annan intressant information i loggen. Vi förbereder oss för framtiden genom att använda den historiska informationen i loggarna; informationen kan hjälpa oss att lösa ett problem, eller potentiellt problem, innan det blir katastrofalt.
Visar ERRORLOG
Först och främst kommer vi att granska några alternativ för att visa ERROLOG. Om jag är ansluten till en instans navigerar jag vanligtvis till den via SSMS (Management | SQL Server Logs, högerklicka på en logg och välj View SQL Server Log). Från det här fönstret kan jag bara bläddra igenom loggen eller använda alternativen Filter eller Sök för att begränsa resultatuppsättningen. Jag kan också visa flera filer genom att markera dem i den vänstra rutan.
Om jag tittar på data som fångats i en av våra hälsorevisioner öppnar jag bara loggfilerna i en textredigerare och granskar dem (jag har möjlighet att gå in i visningsprogrammet och ladda dem också). Loggfilerna finns i loggmappen (standardplats:C:\Program Files\Microsoft SQL Server\MSSQL12.SQL2014\MSSQL\Log) om jag någonsin velat titta på dem på servern. Många av er kanske föredrar att visa och/eller söka i loggen med den odokumenterade proceduren sp_readerrorlog eller den utökade lagrade proceduren xp_readerrorlog.
Och slutligen, om du gillar PowerShell, är det också ett alternativ för att läsa loggen på det sättet (se det här inlägget:Använd PowerShell för att analysera SQL Server 2012-felloggar). Metoden är upp till dig – använd det du vet och det som fungerar för dig – det är innehållet som verkligen betyder något. Och kom ihåg att det finns tillfällen då du helt enkelt behöver läsa igenom loggen för att förstå händelseordningen, och det finns andra tillfällen då du kan söka för att hitta ett specifikt fel eller en viss information.
Vad finns i FELLOGGEN?
Så vilken information kan vi hitta i ERRORLOG, förutom fel? Jag har listat många av de saker jag har funnit mest användbara nedan. Observera att detta inte är en uttömmande lista (och jag är säker på att många av er kommer att ha förslag på vad som kan läggas till – skriv gärna en kommentar så kan jag uppdatera det här!), men återigen, det här är vad jag är letar efter först när jag proaktivt tittar på en instans.
- Om servern är fysisk eller virtuell (leta efter posten System Manufacturer)
- Spårningsflaggor aktiverade vid start
- Om du rullar hela vägen till höger i posten för registrets startparametrar ser du om några spårningsflaggor är aktiverade:
 Spårningsflaggor aktiverade vid start
Spårningsflaggor aktiverade vid start
- Om du rullar hela vägen till höger i posten för registrets startparametrar ser du om några spårningsflaggor är aktiverade:
- Spårningsflaggor aktiverade eller inaktiverade efter att instansen har startat
- Om användare (eller ett program) aktiverar eller inaktiverar en spårningsflagga med DBCC TRACEON eller DBCC TRACEOFF, visas en post i loggen
- Antal kärnor och sockets som upptäckts av SQL Server
- Jag vill alltid verifiera att SQL Server ser all tillgänglig hårdvara – och om inte är det en röd flagga att undersöka vidare. För ett bra exempel, se Jonathans inlägg, Performance Problems with SQL Server 0212 Enterprise Edition Under CAL Licensing, och Glenns inlägg, Balancing Your Available SQL Server Core Licenses Evenly Across NUMA Nodes, som också innehåller några praktiska TSQL för att fråga loggen.
- Observera att texten för denna post varierar mellan SQL Server-versioner.
- Mängd minne som upptäckts av SQL Server
- Återigen vill jag verifiera att SQL Server ser allt minne som är tillgängligt för den.
- Bekräftelse på att låsta sidor i minnet (LPIM) är aktiverat
- Medan det här alternativet är aktiverat via Windows säkerhetspolicy kan du bekräfta att det är aktiverat genom att leta efter meddelandet "Använder låsta sidor i minneshanteraren" i loggen.
- Observera att om du har Trace Flag 834 i bruk kommer meddelandet inte att säga låsta sidor, utan att stora sidor används för buffertpoolen.
- Version av CLR som används
- Lyckad eller misslyckad registrering av Service Principal Name (SPN)
- Hur lång tid tar det för en databas att komma online
- Loggen registrerar när databasen startar och när den är online – jag kontrollerar om det tar lång tid att komma upp någon databas.
- Status för Service Broker och Databas Mirroring endpoints – viktigt om du använder någon av funktionerna
- Bekräftelse på att Instant File Initialization (IFI) är aktiverad*
- Som standard loggas inte denna information, men om du aktiverar Trace Flag 3004 (och 3605 för att tvinga utdata till loggen), när du skapar eller odlar en datafil, kommer du att se meddelanden i loggen för att indikera om IFI används eller inte.
- Status för SQL-spår
- När du startar eller stoppar en SQL-spårning loggas den, och jag ser efter om det finns några spår utöver standardspårningen (antingen tillfälligt eller långsiktigt). Om du kör ett övervakningsverktyg från tredje part, som SQL Sentrys Performance Advisor, kanske du ser en aktiv spårning som alltid körs, men som bara registrerar specifika händelser, eller så kanske du ser en spårningsstart, körs under en kort tid, sedan sluta. Jag är inte bekymrad över ett eller två extra spår, såvida de inte fångar många händelser, men jag är definitivt uppmärksam när flera spår körs.
- Senast CHECKDB slutfördes
- Det här meddelandet missförstås ofta av människor – när instansen startar läser den startsidan för varje databas och noterar när CHECKDB senast kördes framgångsrikt. De flesta läser inte hela meddelandet:
 Datum då DBCC CHECKDB senast slutfördes framgångsrikt
Datum då DBCC CHECKDB senast slutfördes framgångsrikt Datumet för att CHECKDB slutförs är den 11 november 2012, men ERRORLOG-datumet är den 7 juli 2015. Det är viktigt att förstå att SQL Server inte kör CHECKDB mot databaser vid uppstart, det kontrollerar dbcclastknowngood-värdet på startsidan (för att se när det uppdateras, kolla in mitt inlägg, What Checks Update dbcclastknowngood. Dessutom, om DBCC CHECKDB aldrig har körts mot en databas, kommer ingen post kommer att dyka upp för databasen här.
- Det här meddelandet missförstås ofta av människor – när instansen startar läser den startsidan för varje databas och noterar när CHECKDB senast kördes framgångsrikt. De flesta läser inte hela meddelandet:
- KONTROLLDB-slutförande
- När CHECKDB körs mot en databas, registreras utdata i loggen.
- Ändringar av instansinställningar
- Om du ändrar inställningar på instansnivå (t.ex. max serverminne, kostnadströskel för parallellitet) med sp_configure eller via användargränssnittet (observera att det inte loggar vem ändrade det).
- Ändringar av databasinställningar
- Har någon aktiverat AUTO_SHRINK? Ändra alternativet ÅTERSTÄLLNING till SIMPLE och sedan tillbaka till FULL? Du hittar den här.
- Ändringar av databasstatus
- Om någon tar en databas OFFLINE (eller gör den ONLINE) loggas denna.
- Information om dödläge*
- Om du behöver fånga information om dödläge, vill du inte köra ett spår, och du kör SQL Server 2005 till 2008R2, använd spårningsflagga 1222 för att skriva dödlägesinformation till loggen i XML-format. För de av er som använder SQL Server 2000 och lägre, kan du spåra flagga 1204 (denna spårningsflagga är också tillgänglig i SQL Server 2005+, men den matar ut minimal information). Om du kör SQL Server 2012 eller högre behövs inte detta, eftersom system_health-händelssessionen fångar den här informationen (och den finns där 2008 och 20082 också, men du måste hämta den från ring_buffer kontra event_file-målet).
- FlushCache-meddelanden
- Om cachen töms av SQL Server eftersom kontrollpunktsprocessen överskrider återställningsintervallet för databasen, kommer du att se en uppsättning FlushCache-meddelanden i loggen (se det här inlägget av Bob Dorr för mer information). Blanda inte ihop dessa meddelanden med de som dyker upp när du kör DBCC FREEPROCCACHE eller DBCC FREESYSTEMCACHE:
 Meddelande efter att ha kört DBCC FREEPROCCACHE eller DBCC FREESYSTEMCACHE
Meddelande efter att ha kört DBCC FREEPROCCACHE eller DBCC FREESYSTEMCACHE
- Om cachen töms av SQL Server eftersom kontrollpunktsprocessen överskrider återställningsintervallet för databasen, kommer du att se en uppsättning FlushCache-meddelanden i loggen (se det här inlägget av Bob Dorr för mer information). Blanda inte ihop dessa meddelanden med de som dyker upp när du kör DBCC FREEPROCCACHE eller DBCC FREESYSTEMCACHE:
- AppDomain-avlastningsmeddelanden
- Loggen noterar också när AppDomains skapas, och du ser bara antingen om du använder CLR. Om jag ser AppDomain-avlastningsmeddelanden på grund av minnestryck är det något att undersöka närmare.
Det finns annan information i loggen som är användbar, såsom autentiseringsläge som används, om den dedikerade administratörsanslutningen (DAC) är aktiverad eller inte, etc. men jag kan också få det från sys.configurations och jag kontrollerar de med instansens baslinjer Jag diskuterade tidigare (Proactive SQL Server Health Checks, Part 3:Instance and Database Settings).
Vad står inte i ERROLOGGEN, som du kanske förväntar dig?
Det här är en kort lista för nu, eftersom jag gissar att några av er kanske har hittat andra saker som ni trodde skulle finnas i loggen men inte var...
- Lägga till eller ta bort databasfiler eller filgrupper
- Starta eller stoppa utökade evenemangssessioner
- Men om du distribuerar en DDL-utlösare eller händelsemeddelande på servernivå kan du logga denna information. Se Jonathans inlägg, Logga förlängda händelseförändringar i ERRORLOG, för mer information.
- Att köra DBCC DROPCLEANBUFFERS visas i ERRORLOGGEN
Hantera loggen
Kom ihåg att som standard behåller SQL Server endast de senaste sex (6) loggfilerna (utöver den aktuella filen), och loggfilen rullar över varje gång SQL Server startar om. Som ett resultat kan du ibland ha extremt stora loggfiler som tar ett tag att öppna och som är jobbigt att gräva igenom. Å andra sidan, om du stöter på ett fall där instansen startas om ett par gånger, kan du förlora viktig information. Det rekommenderas att öka antalet sparade filer till ett högre värde (t.ex. 30) och skapa ett agentjobb för att rulla över filen en gång i veckan med sp_cycle_errorlog.
Förutom att hantera filerna kan du påverka vilken information som skrivs till loggen. En av de vanligaste posterna som skapar röran i ERRORLOG är den framgångsrika backup-posten:
 Säkerhetskopieringen har slutförts
Säkerhetskopieringen har slutförts
Om du har en instans med många databaser och säkerhetskopior av transaktionsloggar tas med någon regelbundenhet (t.ex. var 15:e minut), kommer du att se loggen snabbt fyllas med meddelanden, vilket gör det svårare att hitta ett verkligt problem. Lyckligtvis kan du använda spårningsflagga 3226 för att inaktivera framgångsrika säkerhetskopieringsmeddelanden (fel kommer fortfarande att dyka upp i loggen och alla poster kommer fortfarande att finnas i msdb).
En annan uppsättning meddelanden som rör loggen är framgångsrika inloggningsmeddelanden. Detta är ett alternativ som du konfigurerar för instansen på fliken Säkerhet:
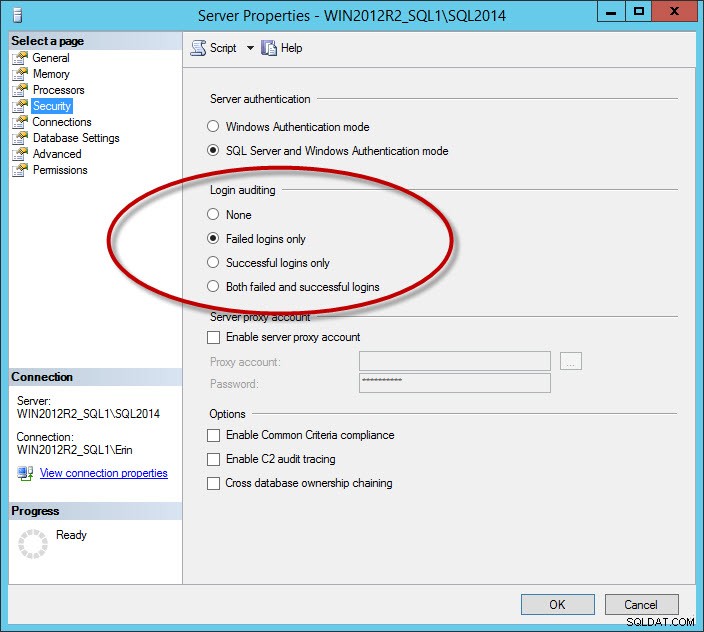 Säkerhetsalternativ för att logga framgångsrika och/eller misslyckade inloggningar
Säkerhetsalternativ för att logga framgångsrika och/eller misslyckade inloggningar
Om du loggar framgångsrika inloggningar, eller misslyckade och lyckade inloggningar, kan du ha mycket stora loggfiler, även om du rullar över filerna dagligen (det beror på hur många användare som ansluter). Jag rekommenderar att endast registrera misslyckade inloggningar. För företag som har ett krav på att logga in framgångsrika inloggningar, överväg att använda granskningsfunktionen, tillagd i SQL Server 2008. Sidanteckning:Om du ändrar inställningen för inloggningsgranskning kommer den inte att träda i kraft förrän du startar om instansen.
Underskatta inte FELLOGGEN
Som du kan se finns det en del bra information i ERRORLOG som du kan använda inte bara när du felsöker prestanda eller undersöker fel, utan också när du proaktivt övervakar en instans. Du kan hitta information i loggen som inte finns någon annanstans; se till att du kontrollerar det regelbundet och inte lämnar det som en eftertanke.
Se de andra delarna i den här serien:
- Del 1:Diskutrymme
- Del 2:Underhåll
- Del 3:Inställningar för instans och databas