SQL Server Transactional Replication är en av de vanligaste replikeringsteknikerna som används för att kopiera eller distribuera data över flera destinationer.
I de tidigare artiklarna diskuterade vi SQL Server-replikering, hur det fungerar internt och hur man konfigurerar replikering via Replication Wizard eller T-SQL-metoden. Nu fokuserar vi på SQL-replikeringsproblem och att felsöka dem korrekt.
SQL-replikeringsproblem
Majoriteten av kunderna som använder SQL Server Transactional Replication fokuserar huvudsakligen på att uppnå nästan realtidsdata som är tillgänglig i instanser av Subscriber-databasen. Därför bör den DBA som hanterar replikeringen vara medveten om olika möjliga SQL-replikeringsrelaterade problem som kan uppstå. Dessutom måste DBA kunna lösa dessa problem inom en kort tid.
Vi kan kategorisera alla SQL-replikeringsproblem i nedanstående kategorier (baserat på min erfarenhet):
Konfigurationsproblem
- Maximal textreplikeringsstorlek
- SQL Server Agent Service är inte inställd på att starta automatiskt läge
- Oövervakade replikeringsinstanser hamnar i ett oinitierat prenumerationsläge
- Kända problem inom SQL Server
Behörighetsproblem
- Problem med SQL Server Agent jobbbehörighet
- Snapshot Agent jobbuppgifter kan inte komma åt Snapshot Folder sökväg
- Log Reader Agent jobbuppgifter kan inte ansluta till utgivare/distributionsdatabas
- Distributionsagentens jobbuppgifter kan inte ansluta till distributions-/prenumerantdatabasen
Anslutningsproblem
- Utgivarservern hittades inte eller var inte tillgänglig
- Distributionsservern hittades inte eller var inte tillgänglig
- Prenumerantserver hittades inte eller var inte tillgänglig
Problem med dataintegritet
- Fel vid överträdelse av primär nyckel eller unik nyckel
- Rad Not Found-fel
- Fel med främmande nyckel eller andra begränsningsöverträdelser
Prestandaproblem
- Långa aktiva transaktioner i utgivarens databas
- MassINFOGA/UPPDATERA/RADERA operationer på artiklar
- Enorma dataförändringar inom en enda transaktion
- Blockeringar i distributionsdatabasen
Korruptionsrelaterade frågor
- Korruption av utgivarens databas
- Utgivarens transaktionsloggfil korruption
- Korruption av distributionsdatabasen
- Korruption av prenumerantdatabas
DEMO Miljöförberedelse
Innan vi går in i detaljer om SQL-replikeringsproblemen måste vi förbereda vår miljö för demon. Som diskuterats i mina tidigare artiklar, kommer eventuella dataändringar som sker i prenumerantdatabasen i Transactional Replication inte att vara synliga direkt för Publisher-databasen. Därför kommer vi att göra vissa ändringar direkt i prenumerantdatabasen för inlärningsändamål.
Var extremt försiktig och modifiera ingenting i produktionsdatabaserna. Det kommer att påverka dataintegriteten för abonnentdatabaserna. Jag tar säkerhetskopieringsskripten för varje ändring som görs och kommer att använda dessa skript för att åtgärda SQL-replikeringsproblemen.
Ändring 1 – Infoga poster i Person.ContactType-tabellen
Innan du infogar poster i Person.ContacType tabell, låt oss ta en titt på den tabellstrukturen, några standardbegränsningar och utökade egenskaper redigerade i skriptet nedan:
CREATE TABLE [Person].[ContactType](
[ContactTypeID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[Name] [dbo].[Name] NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_ContactType_ContactTypeID] PRIMARY KEY CLUSTERED
(
[ContactTypeID] ASC
) ON [PRIMARY]
) ON [PRIMARY]
GO
Jag har valt den här tabellen eftersom den har färre kolumner. Det är bekvämare för teständamål. Låt oss nu kolla vad vi har om dess struktur:
- ContactTypeId definieras som en IDENTITETSKOLONN – den kommer att autogenerera de primära nyckelvärdena och INTE FÖR REPLIKATION.
- INTE FÖR REPLIKATION är en speciell egenskap som kan användas på olika objekttyper som tabeller, begränsningar som begränsningar för främmande nyckel, kontrollbegränsningar, utlösare och identitetskolumner på antingen utgivare eller prenumerant medan endast någon av replikeringsmetoderna används. Det låter DBA planera eller implementera replikering för att säkerställa att vissa funktioner beter sig annorlunda i Publisher/Subscriber när du använder replikering.
- I vårt fall instruerar vi SQL Server att använda IDENTITY-värdena som genereras endast i Publisher-databasen. Egenskapen IDENTITY ska inte användas på Person.ContactType tabell i prenumerantdatabasen. På samma sätt kan vi modifiera begränsningarna eller utlösarna för att få dem att bete sig annorlunda medan replikering konfigureras med det här alternativet.
- 2 andra NOT NULL-kolumner är tillgängliga i tabellen.
- Tabellen har en primärnyckel definierad på ContactTypeId . Bara för att komma ihåg, den primära nyckeln är ett obligatoriskt krav för replikering. Utan den på en tabell skulle vi inte kunna replikera en tabellartikel.
Låt oss nu INFOGA en exempelpost till Person .ContactType tabellen i AdventureWorks_REPL databas:
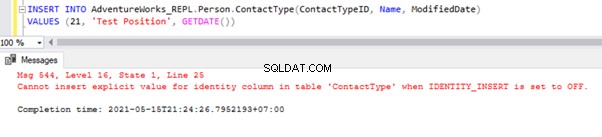
Direkt INSERT på bordet kommer att misslyckas i abonnentdatabasen eftersom identitetsegenskapen är inaktiverad endast för replikering genom alternativet INTE FÖR REPLIKATION. När vi utför INSERT-operationen manuellt måste vi fortfarande använda alternativet SET IDENTITY_INSERT så här:
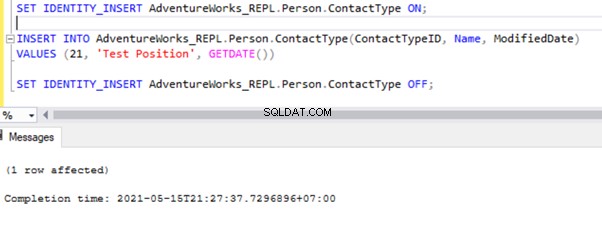
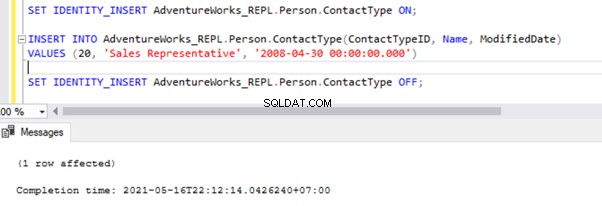
SET IDENTITY_INSERT AdventureWorks_REPL.Person.ContactType ON;
INSERT INTO AdventureWorks_REPL.Person.ContactType(ContactTypeID, Name, ModifiedDate)
VALUES (21, 'Test Position', GETDATE())
SET IDENTITY_INSERT AdventureWorks_REPL.Person.ContactType OFF;
Efter att ha lagt till alternativet SET IDENTITY_INSERT kan vi INFOGA posten framgångsrikt i Person.ContactType bord.
Om du kör SELECT i tabellen visas den nyligen infogade posten:
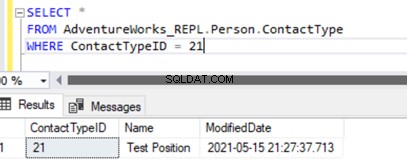
Vi har endast lagt till en ny post i prenumerantdatabasen som inte är tillgänglig i Publisher-databasen på Person.ContactType bord.
Att köra en SELECT på samma tabell i Publisher-databasen visar inga poster. Alla ändringar som görs på prenumerantdatabasen replikeras inte till utgivardatabasen.
Ändra 2 – Ta bort 2 poster från Person.ContactType-tabellen
Vi håller oss till vår välbekanta Person.ContactType tabell. Innan vi tar bort poster från prenumerantdatabasen måste vi verifiera om dessa poster finns hos både utgivare och prenumerant. Se nedan:
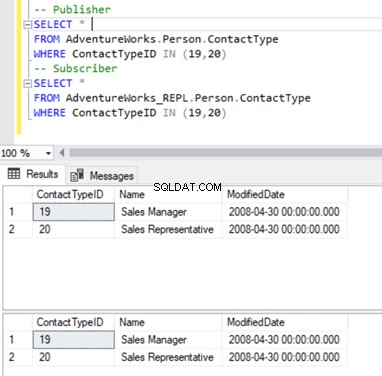
Nu kan vi ta bort dessa 2 ContactTypeId med följande uttalande:
DELETE FROM AdventureWorks_REPL.Person.ContactType
WHERE ContactTypeID IN (19,20)
Skriptet ovan låter oss ta bort 2 poster från Person.ContactType tabell i prenumerantdatabasen:
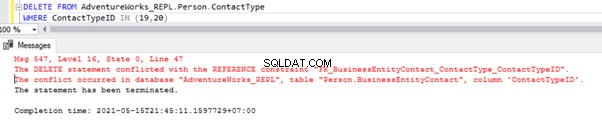
Vi har den främmande nyckelreferensen som förhindrar radering av dessa två poster från Person.ContactType tabell. Vi kan hantera detta scenario genom att tillfälligt inaktivera begränsningen för främmande nyckel på den underordnade tabellen. Skriptet är nedan:
ALTER TABLE [Person].[BusinessEntityContact] NOCHECK CONSTRAINT [FK_BusinessEntityContact_ContactType_ContactTypeID];
När främmande nycklar är inaktiverade kan vi radera poster framgångsrikt från Person.ContactType tabell:
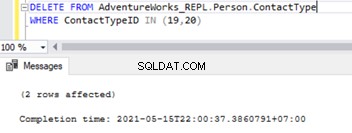
Detta har också ändrat referensbegränsningen för den främmande nyckeln över de två tabellerna. Vi kan försöka simulera SQL-replikeringsproblem baserat på detta scenario.
I vårt nuvarande scenario vet vi att Person.ContactType Tabellen hade inte synkroniserad data mellan utgivaren och prenumeranten.
Tro mig, i få produktionsmiljöer gör utvecklare eller DBA:er vissa datafixar på abonnentdatabasen. precis som alla ändringar vi utförde tidigare orsakade dataintegritetsproblemen i Publisher- och Prenumerantdatabaserna i samma tabell. Som DBA behöver jag en enklare mekanism för att verifiera den här typen av avvikelser. Annars skulle det göra DBA:s liv patetiskt.
Här kommer lösningen från Microsoft som gör att vi kan verifiera dataavvikelser mellan tabeller i Publisher och Prenumerant. Ja, du gissade rätt. Det är TableDiff-verktyget som vi diskuterade i tidigare artiklar.
TableDiff Utility
TableDiff-verktyget används främst i replikeringsmiljöer. Vi kan också använda det för andra fall där vi behöver jämföra 2 SQL Server-tabeller för icke-konvergens. Vi kan jämföra dem och identifiera skillnaderna mellan dessa två tabeller. Sedan hjälper verktyget till att synkronisera Destinationen tabell till Källan tabell genom att generera nödvändiga INSERT/UPDATE/DELETE-skript.
TableDiff är ett fristående program tablediff.exe installerat som standard på C:\Program Files\Microsoft SQL Server\130\COM när vi har installerat replikeringskomponenterna. Observera att standardsökvägen kan variera beroende på SQL Server-installationsparametrarna. Siffran 130 i sökvägen indikerar SQL Server-versionen (SQL Server 2016). Därför kommer det att variera för varje version av SQL Server-installationen.
Du kan komma åt TableDiff-verktyget via kommandotolken eller endast från batchfiler. Verktyget har inte en fancy Wizard eller GUI att använda. Den detaljerade syntaxen för TableDiff-verktyget finns i MSDN-artikeln. Vår nuvarande artikel fokuserar endast på några nödvändiga alternativ.
För att jämföra 2 tabeller med hjälp av verktyget TableDiff måste vi tillhandahålla obligatoriska uppgifter för käll- och destinationstabellerna, såsom källservernamn, källdatabasnamn, källschemanamn, källtabellnamn, destinationsservernamn, destinationsdatabasnamn, destination Schemanamn och destinationstabellnamn.
Låt oss testa TableDiff med Person.ContactType tabell med skillnader mellan utgivaren och prenumeranten.
Öppna kommandotolken och navigera till sökvägen för TableDiff-verktyget (om den sökvägen inte läggs till i miljövariablerna).
För att se listan över alla tillgängliga parametrar, skriv kommandot "tablediff-?" för att lista alla tillgängliga alternativ och parametrar. Resultaten är nedan:
Låt oss kontrollera personen.ContactType tabell över våra Publisher- och Prenumerantdatabaser genom att köra kommandot nedan:
tablediff -sourceserver RRJ -sourcedatabase AdventureWorks -sourceschema Person -sourcetable ContactType -destinationserver RRJ -destinationdatabase AdventureWorks_REPL -destinationschema Person -destinationtable ContactTypeObservera att jag inte har angett källanvändaren , källkod , destinationuser och destinationslösenord eftersom min Windows-inloggning har tillgång till tabellerna. Om du vill använda SQL-uppgifter istället för Windows-autentisering, är ovanstående parametrar obligatoriska för att komma åt tabellerna för jämförelse . Annars kommer du att få felmeddelanden.
Resultaten av korrekt kommandoexekvering:
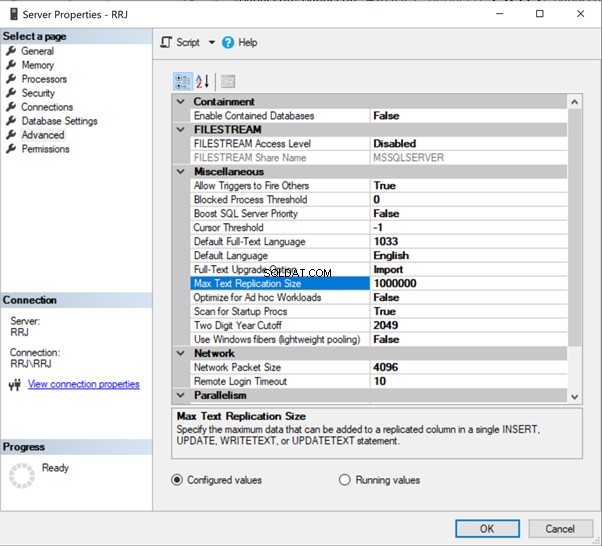
Det visar att vi har 3 avvikelser. En är en ny post i destinationsdatabasen, och två poster är inte tillgängliga i destinationsdatabasen.
Nu ska vi ta en snabb titt på Övrigt tillgängliga alternativ för TableDiff-verktyget.
- -et – loggar resultatsammanfattningen till måltabellen
- -dt – tar bort resultatdestinationstabellen om den redan finns
- -f – genererar ett T-SQL DML-skript med INSERT/UPDATE/DELETE-satser för att få destinationstabellen att konvergens med källtabellen.
- -o – utdatafilnamn om alternativet -f används för att generera konvergensfilen.
Vi skapar en konvergensfil med -f och -o alternativ till vårt tidigare kommando:
tablediff -sourceserver RRJ -sourcedatabase AdventureWorks -sourceschema Person -sourcetable ContactType -destinationserver RRJ -destinationdatabase AdventureWorks_REPL -destinationschema Person -destinationtable ContactType -f -o C:\PersonContactType.sqlKonvergensfilen skapades framgångsrikt:
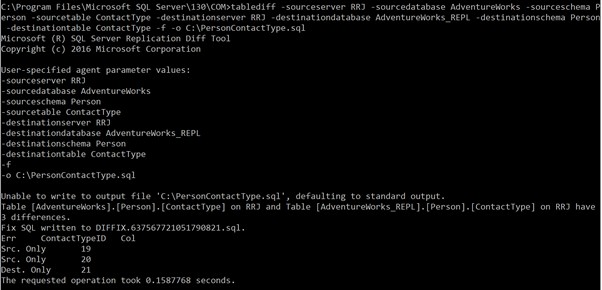
Som du kan se är skapandet av en ny fil i rotmappen på C:-enheten inte tillåtet av säkerhetsskäl. Därför visar den ett felmeddelande och skapar utdatafilen DIFFIX.*.sql-fil i verktygsmappen TableDiff. När vi öppnar den filen kan vi se nedanstående detaljer:

INSERT-skripten skapades för de två raderade posterna, och DELETE-skripten skapades för posterna som nyligen infogats i prenumerantdatabasen. Verktyget bryr sig också om att använda IDENTITY_INSERT-alternativen som krävs för Destinationen tabell. Därför kommer detta verktyg att vara till stor nytta när en DBA behöver synkronisera två tabeller.
I vårt fall kommer jag inte att köra skripten, eftersom vi behöver dessa avvikelser för att simulera våra SQL-replikeringsproblem.
Fördelar med TableDiff Utility
- TableDiff är ett kostnadsfritt verktyg som kommer som en del av installationen av SQL Server Replication-komponenter för att användas för tabelljämförelse eller konvergens.
- Skripten för att skapa konvergens kan skapas utan manuell inblandning.
Begränsningar för TableDiff Utility
- TableDiff-verktyget kan endast köras från kommandotolken eller batchfilen.
- Från kommandotolken kan du endast utföra en tabelljämförelse åt gången, såvida du inte har flera kommandoprompter öppna parallellt för att jämföra flera tabeller.
- Källtabellen som du behöver jämföra med hjälp av verktyget TableDiff kräver antingen en primärnyckel eller en identitetskolumn definierad, eller ROWGUID-kolumnen tillgänglig för att utföra jämförelsen rad för rad. Om -strikt används, kräver destinationstabellen också en primärnyckel eller en identitetskolumn, eller kolumnen ROWGUID tillgänglig.
- Om käll- eller måltabellen innehåller sql_variant datatyp kolumnen kan du inte använda TableDiff-verktyget för att jämföra det.
- Prestandaproblem kan uppmärksammas när du kör TableDiff-verktyget på tabeller som innehåller enorma poster, eftersom det kommer att utföra en rad-för-rad-jämförelse på dessa tabeller.
- Konvergensskript som skapats av TableDiff-verktyget inkluderar inte kolumner för BLOB-teckendatatyp, till exempel varchar(max) , nvarchar(max) , varbinary(max) , text , ntext , eller bild kolumner och xml eller tidsstämpel kolumner. Därför behöver du alternativa metoder för att hantera tabellerna med dessa datatypkolumner.
Men även med dessa begränsningar kan TableDiff-verktyget användas över alla SQL Server-tabeller för snabb dataverifiering eller konvergenskontroll. Du kan dock köpa ett bra verktyg från tredje part också.
Låt oss nu överväga de olika SQL-replikeringsproblemen i detalj.
Konfigurationsproblem
Av min erfarenhet har jag kategoriserat ofta missade alternativ för replikeringskonfiguration som kan leda till kritiska SQL-replikeringsproblem som Konfiguration frågor. Några av dem finns nedan.
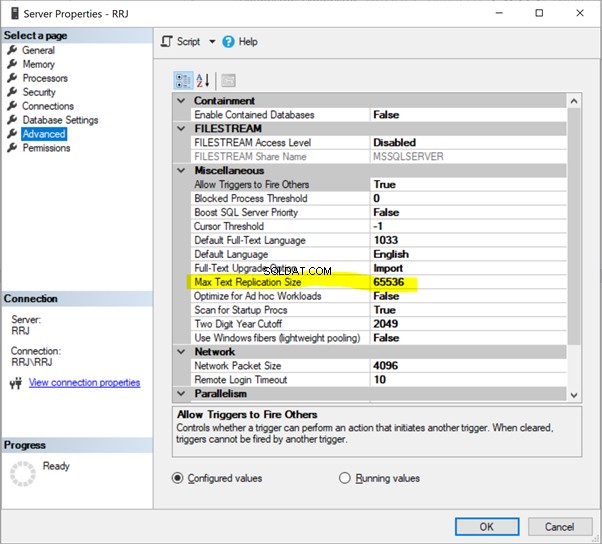
Max textreplikeringsstorlek
Max textrepl.storlek hänvisar till Maximal textreplikeringsstorlek i byte . Det gäller alla datatyper som char(max), nvarchar(max), varbinary(max), text, ntext, varbinary, xml, och bild .
SQL Server har ett standardalternativ för att begränsa den maximala kolumnlängden för strängdatatyp (i byte) som ska replikeras som 65536 byte.
Vi måste utvärdera Max Text Repl Size noggrant när replikering konfigureras för en databas. För det måste vi kontrollera alla ovanstående datatypkolumner och identifiera maximalt möjliga byte som kommer att överföras via replikering.
Att ändra värdet till -1 indikerar att det inte finns några gränser. Vi rekommenderar dock att du utvärderar den maximala stränglängden och konfigurerar det värdet.
Vi kan konfigurera Max Text Repl Size med SSMS eller T-SQL.
I SSMS högerklickar du på servernamnet> Egenskaper > Avancerat :
Klicka bara på 65536 att ändra den. För tester har jag ändrat 65536 till 1000000 och klickat på OK :
För att konfigurera alternativet Max Text Repl Size via T-SQL, öppna ett nytt frågefönster och kör skriptet nedan mot huvuddatabasen:
EXEC sys.sp_configure N'max text repl size (B)', N'-1'
GO
RECONFIGURE WITH OVERRIDE
GO
Denna fråga gör att Replikering inte begränsar storleken på ovanstående datatypkolumner.
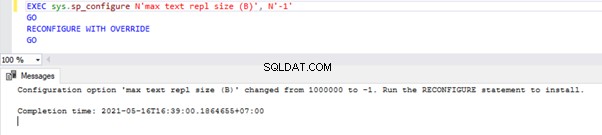
För att verifiera kan vi utföra ett SELECT på sys.configurations DMV och kontrollera value_in_use kolumn enligt nedan:

SQL Server Agent Service inte inställd på att starta automatiskt läge
Replikering förlitar sig på replikeringsagenter som körs som SQL Server Agent-jobb. Därför kommer alla problem med vissa SQL Server Agent-tjänster att ha en direkt inverkan på replikeringsfunktionaliteten.
Vi måste se till att startläget för SQL Server och SQL Server Agent Services är inställt på Automatisk. Om den är inställd på Manuell bör vi konfigurera några varningar. De skulle meddela DBA eller serveradministratörer att starta SQL Server Agent Service när servern startar om antingen planerade eller oplanerade.
Om det inte görs kanske replikeringen inte körs på länge, vilket också påverkar andra SQL Server Agent-jobb.
Oövervakade replikeringsinstanser hamnar i ett oinitierat prenumerationsläge
I likhet med att övervaka SQL Server Agent Service, spelar konfigurering av Database Mail Service i alla SQL Server-instanser en viktig roll för att varna DBA eller den person som konfigurerats i tid. För eventuella jobbfel eller problem kan SQL Server Agent-jobb som Log Reader Agent eller Distribution Agent konfigureras för att skicka varningar till DBA eller respektive teammedlem via e-post. Ett misslyckande med att köra replikeringsagentjobbet kan leda till följande scenarier:
Icke-exekvering av Log Reader Agent Job . Transaktionsloggfilen i Publisher-databasen kommer att återanvändas först efter kommandot markerat för replikering läses av Log Reader Agent och skickas framgångsrikt till distributionsdatabasen. Annars, log_reuse_wait_desc kolumn sys.databases kommer att visa värdet som replikering, vilket indikerar att databasloggen inte kan återanvändas förrän den har överfört ändringar till distributionsdatabasen. Därför kommer underlåtenhet att köra Log Reader-agenten att fortsätta att öka storleken på transaktionsloggfilen i Publisher-databasen, och vi kommer att stöta på prestandaproblem under den fullständiga säkerhetskopieringen, eller diskutrymmesproblem i Publisher-databasens instans.
Icke-utförande av distributionsagentjobb. Distributionsagentjobbet läser data från distributionsdatabasen och skickar dem till abonnentdatabasen. Sedan markerar den dessa poster för radering i distributionsdatabasen. Om distributionsagentjobbet inte körs kommer det att öka storleken på distributionsdatabasen och orsaka prestandaproblem till den övergripande replikeringsprestandan. Som standard är distributionsdatabasen konfigurerad för att hålla poster till maximalt 0-72 timmar, vilket visas i egenskapen Transaktionsretention nedan. Om replikeringen misslyckas i mer än 72 timmar kommer motsvarande prenumeration att markeras som oinitierad, vilket tvingar oss att antingen konfigurera om prenumerationen eller skapa en ny ögonblicksbild för att replikeringen ska fungera igen.
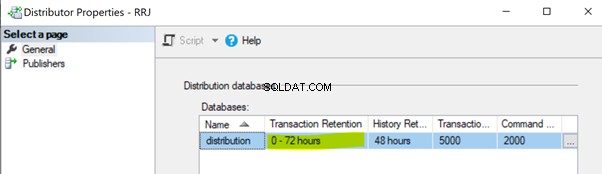
Icke-utförande av distributionsrensning:distributionsjobb . Distributionsrensningsjobbet är ansvarigt för att ta bort alla replikerade poster från distributionsdatabasen för att hålla distributionsdatabasens storlek under kontroll. Underlåtenhet att utföra detta jobb leder till en ökad storlek på distributionsdatabasen, vilket leder till problem med replikeringsprestanda.
För att säkerställa att vi inte hamnar i några av dessa oövervakade problem, bör Databas Mail konfigureras för att rapportera alla jobbmisslyckanden eller omförsök till respektive teammedlemmar för omedelbar åtgärd.
Kända problem inom SQL Server
Vissa SQL Server-versioner hade kända replikeringsproblem i RTM-versionen eller tidigare versioner. Dessa problem åtgärdades i de efterföljande Service Packs eller CU-paketen. Därför rekommenderas det att tillämpa de senaste Service Packs eller CU-paketen när de är tillgängliga för alla SQL Server efter att ha testat dem i QA-miljön. Även om detta är en allmän rekommendation för servrar som kör SQL Server, är den även tillämplig för replikering.
Tillståndsproblem
I en miljö med SQL Server Transactional Replication konfigurerad kan vi observera behörighetsproblemen ofta. Vi kan möta dem under tiden för replikeringskonfigurationen eller underhållsaktiviteter på utgivaren, distributören eller prenumerantdatabasen. Det resulterar i förlorade referenser eller behörigheter. Låt oss nu observera några vanliga behörighetsproblem relaterade till replikering.
SQL Server Agent jobbbehörighetsproblem
Alla replikeringsagenter använder SQL Server Agent-jobb. Varje SQL Server Agent-jobb som är relaterat till ögonblicksbilden eller Log Reader Agent eller Distribution körs under vissa Windows- eller SQL-inloggningsuppgifter enligt nedan:
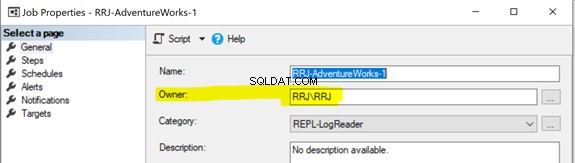
För att starta ett SQL Server Agent-jobb måste du ha antingen SQLAgentOperatorRole för att starta alla jobb eller antingen SQLAgentUserRole eller SQLAgentReaderRole att starta jobb som du äger. Om några jobb inte kunde starta ordentligt, kontrollera om jobbägaren har de nödvändiga rättigheterna för att utföra jobbet.
Snapshot Agent Job Credential kan inte komma åt Snapshot Mapp Sökväg
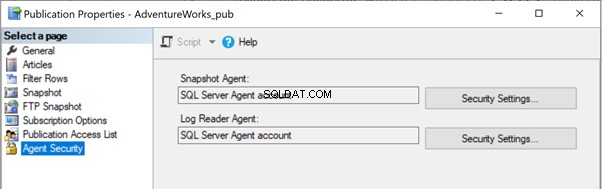
I våra tidigare artiklar märkte vi att körningen av Snapshot-agenten skulle skapa ögonblicksbilden av artiklarna i antingen lokal eller delad mappsökväg för att spridas till abonnentdatabasen via distributionsagenten. Sökvägen för ögonblicksbilden kan identifieras under Publikationsegenskaper > Ögonblicksbild :
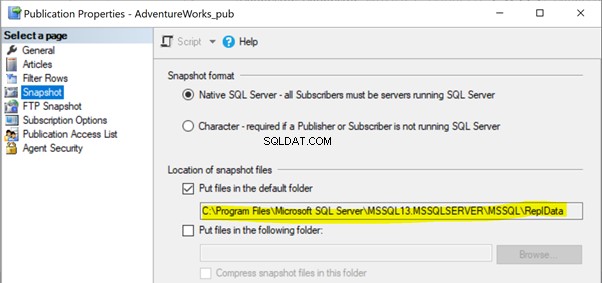
Om Snapshot-agenten inte har åtkomst till denna Snapshot-filplats kan vi få felmeddelandet:
Åtkomst till sökvägen 'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\repldata\unc\XXXX\ÅÅÅÅMMDDHHMISS\' nekas.
För att lösa problemet är det bättre att ge fullständig åtkomst till mappsökvägen C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\repldata\unc\ för kontot som Snapshot Agent kör under. I vår konfiguration använder vi SQL Server Agent-kontot, och SQL Server Agent-tjänsten körs under RRJ\RRJ-kontot.
Jobbuppgifterna för Log Reader Agent kan inte ansluta till utgivar-/distributionsdatabasen
Log Reader Agent ansluter till Publisher-databasen för att köra sp_replcmds procedur för att söka efter transaktioner som är markerade för replikering från transaktionsloggarna i Publisher-databasen.
Om databasägaren av Publisher-databasen inte är korrekt inställd kan vi få följande felmeddelanden:
Processen kunde inte köra 'sp_replcmds' på 'RRJ.
Eller
Kan inte köras som databasprincipal eftersom principal "dbo" inte existerar, den här typen av principal kan inte efterliknas eller så har du inte behörighet.
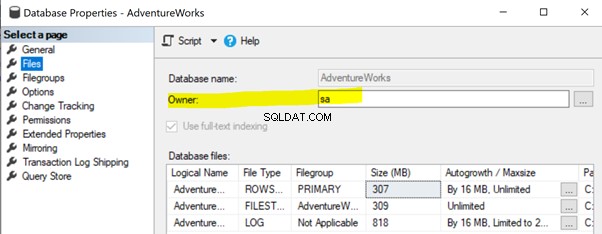
För att lösa det här problemet, se till att databasägarens egenskap för Publisher-databasen är inställd på sa eller ett annat giltigt konto (se nedan).
Högerklicka på Utgivaren databas (AdventureWorks )> Egenskaper > Filer . Se till att Ägaren fältet är satt till sa eller någon giltig inloggning och inte tom .
Om några behörighetsproblem uppstår när vi ansluter till utgivaren eller distributionsdatabasen, kontrollera autentiseringsuppgifterna som används för Log Reader Agent och ge dem behörighet att komma åt dessa databaser.
Jobbuppgifterna för distributionsagenten kan inte ansluta till distributions-/prenumerantdatabasen
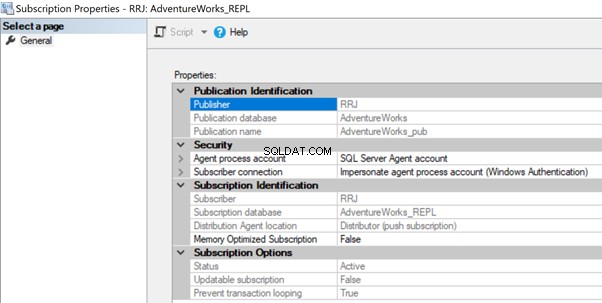
Distributionsagenten kan ha behörighetsproblem om kontot inte får åtkomst till distributionsdatabasen eller ansluta till abonnentdatabasen. I det här fallet kan vi få följande fel:
Det gick inte att starta exekvering av steg 2 (orsak:Fel vid autentisering av proxy RRJ\RRJ, systemfel:Användarnamnet eller lösenordet är felaktigt.)
Processen kunde inte ansluta till prenumerant "RRJ.
Inloggning misslyckades för användaren 'RRJ\RRJ'.
För att lösa det, kontrollera kontot som används i prenumerationsegenskaperna och se till att det har nödvändiga behörigheter för att ansluta till distributions- eller prenumerantdatabasen.
Anslutningsproblem
Vi konfigurerar vanligtvis transaktionsreplikeringen över servrar inom samma nätverk eller över geografiskt distribuerade platser. Om distributionsdatabasen finns på en dedikerad server förutom utgivaren eller abonnenten, blir den känslig för nätverkspaketförluster – anslutningsproblem.
I händelse av sådana problem kan replikeringsagenter (loggläsare eller distributionsagent) rapportera följande fel:
Utgivarservern hittades inte eller var inte tillgänglig
Distributionsservern hittades inte eller var inte tillgänglig
Prenumerantserver hittades inte eller var inte tillgänglig
För att felsöka dessa problem kan vi försöka ansluta till utgivaren, distributören eller prenumerantdatabasen i SSMS för att kontrollera om vi kan ansluta till dessa SQL Server-instanser utan problem eller inte.
Om anslutningsproblem inträffar ofta kan vi försöka pinga servern kontinuerligt för att identifiera eventuella paketförluster. Vi måste också arbeta med de nödvändiga teammedlemmarna för att lösa dessa problem och få igång servern för att replikering ska kunna återuppta överföringen av data.
Problem med dataintegritet
Eftersom transaktionsreplikering är en enkelriktad mekanism, kommer eventuella dataändringar som sker på prenumeranten (manuellt eller från applikationen) inte att återspeglas på utgivaren. Det kan leda till dataavvikelser mellan utgivaren och prenumeranten.
Låt oss granska de problem som är relaterade till dataintegritet och se hur du löser dem. Observera att vi har infogat en post i Person.ContactType tabell och raderade 2 poster från Person.ContactType tabell i prenumerantdatabasen. Vi kommer att använda dessa tre poster för att hitta fel.
Fel vid primärnyckel eller Unique Key Violation
Jag ska testa INSERT-posten på Person.ContactType tabell. Låt oss infoga den posten i Publisher-databasen och se vad som händer:
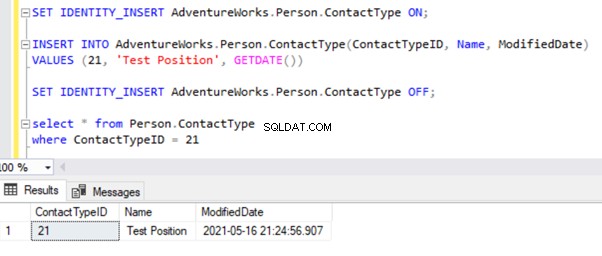
Starta replikeringsmonitorn för att se hur det går. Vi får felet:
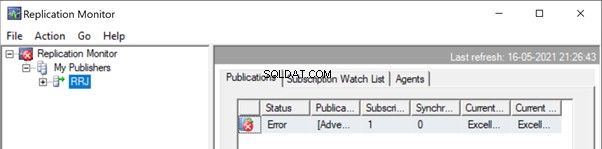
Expanderar Utgivare och Publicering , får vi följande information:
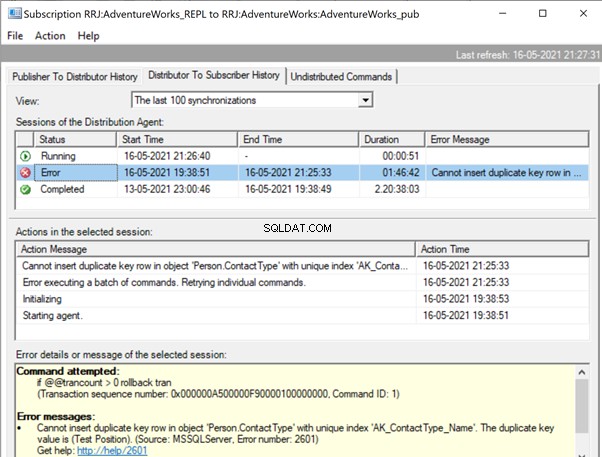
Om vi har konfigurerat replikeringsvarningarna och tilldelat respektive personer att ta emot deras e-postavisering, kommer vi att få lämpliga e-postmeddelanden med felmeddelandet:Kan inte infoga en dubblettnyckelrad i objektet 'Person.ContactType' med unikt index 'AK_ContactType_Name' ' . Dupliceringsnyckelvärdet är (Testposition). (Källa:MSSQLServer, Felnummer:2601)
För att lösa problemet med unika nyckelöverträdelser eller primära nyckelproblem har vi flera alternativ:
- Analysera varför detta fel har inträffat, hur posten var tillgänglig i prenumerantdatabasen och vem som infogade den av vilka skäl. Identifiera om det var nödvändigt eller inte.
- Lägg till överhoppare parametern till distributionsagentprofilen för att hoppa över Felnummer 2601 eller Felnummer 2627 i händelse av överträdelse av primärnyckeln.
I vårt fall har vi medvetet infogat data för att ta emot detta fel. För att hantera det här problemet, radera den manuellt infogade posten för att fortsätta replikera ändringar som tagits emot från utgivaren.
DELETE from Person.ContactType
where ContactTypeID = 21
För att studera andra alternativ och för att jämföra skillnaderna mellan dessa två tillvägagångssätt, hoppar jag över det första alternativet (som är effektivt och rekommenderat) och fortsätter till det andra alternativet genom att lägga till -skiperrors parameter till distributionsagentjobbet.
Vi kan implementera det genom att redigera Distributionsagentjobbet > Steg > klicka på 2 jobbsteg med namnet Kör agent > klicka på Redigera för att se det tillgängliga kommandot:
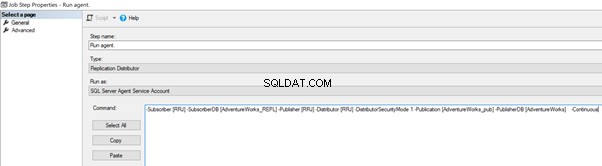
Lägg nu till -SkipErrors 2601 nyckelord till slut (2601 är felnumret – vi kan hoppa över alla felnummer som tas emot som en del av replikering) och klicka på OK .
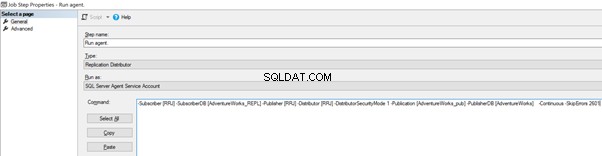
To make sure that the Distribution job is aware of this configuration change, we need to restart the Distribution agent job. For that, stop it and start again from Step 1 as shown below:
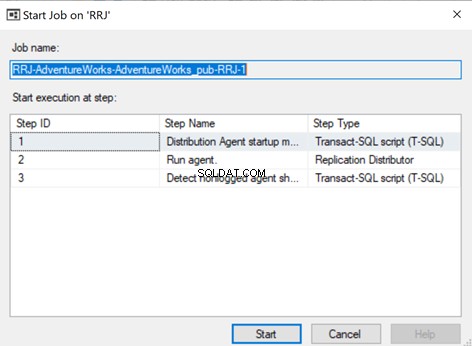
The Replication Monitor displays that one of the error records is skipped from the Replication, that started working fine.
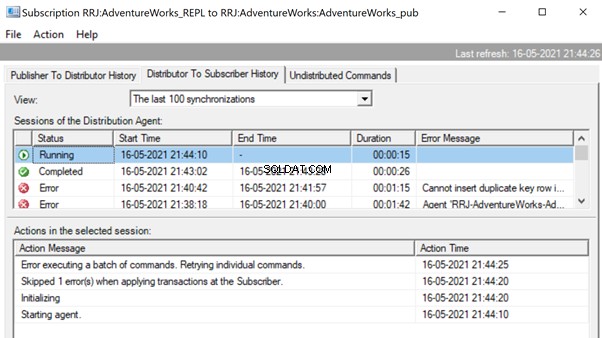
Since the Replication issue is resolved successfully, we’d recommend removing the -SkipErrors parameter from the Distribution Agent job. Then, restart the job to get the changes reflected.
Thus, we’ve fixed the replication issue, but let’s compare the data across the same Person.ContactType in the Publisher and Subscriber databases. The results show the data variance, or the data integrity issue :
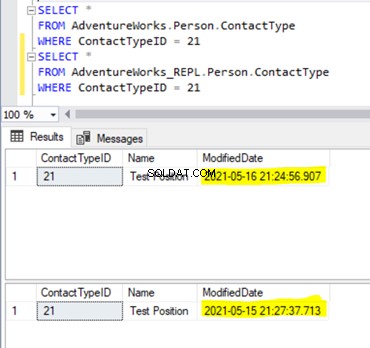
ModifiedDate is different across the Publisher and Subscriber databases. It happens because the data in the Subscriber database was inserted earlier (when we were preparing the test data), and the data in the Publisher database has just been inserted.
If we deleted the record from the Subscriber database, the record from the Publisher would have been inserted to match the data across the Publisher and the Subscriber databases.
Most of the newbie DBAs simply add the -SkipErrors option to get the replication working immediately without detailed investigations of the issue. Hence, it is recommended not to use the -SkipErrors option as a primary solution without proper examination of the problem. The Person.ContactType table had only 3 columns. Assume that the table has over 20 columns. Then, we have just screwed up the Data integrity of this table with that -SkipErrors kommando.
We used this approach just to illustrate the usage of that option. The best way is to examine and clarify the reason for variance and then perform the appropriate DELETE statements on the Subscriber database to maintain the Data Integrity across the Publisher and Subscriber databases.
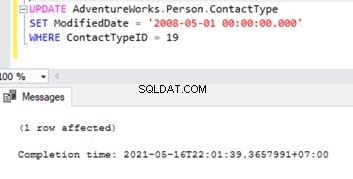
Row Not Found Errors
Let’s try to perform an UPDATE on one of the records that were deleted from the Subscriber database:
Let’s check the Replication Monitor to see the performance. We have the following error:
The row was not found at the Subscriber when applying the replicated UPDATE command for Table ‘[Person].[ContactType]’ with Primary Key(s):[ContactTypeID] =19 (Source:MSSQLServer, Error number:20598).
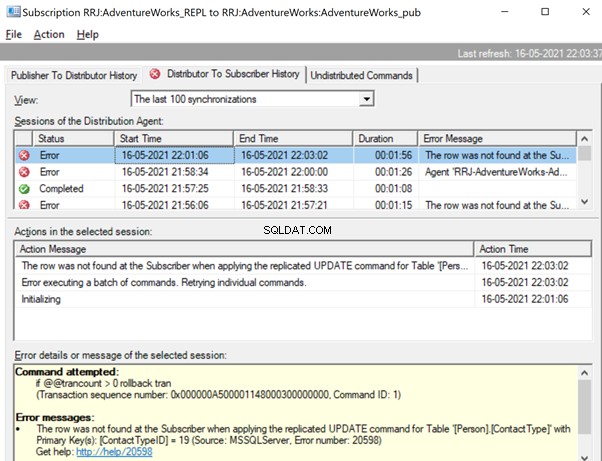
There are two ways to resolve this error. First, we can use -SkipErrors for Error Number 20598 . Or, we can INSERT the record with ContactTypeID =19 (shown in the error message) to get the data changes reflected.
If we skip this error, we’ll lose the record with ContactTypeId =19 from the Subscriber database permanently. It can cause data inconsistency issues. Hence, we aren’t going to use the -SkipErrors alternativ. Instead, we’ll apply the INSERT approach.
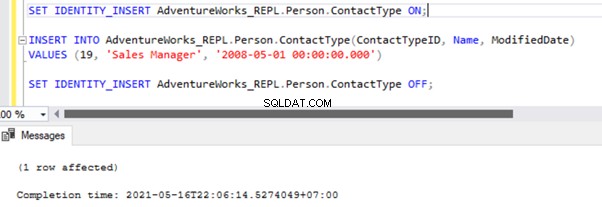
The Replication resumes correctly by sending the UPDATE to the Subscriber database.
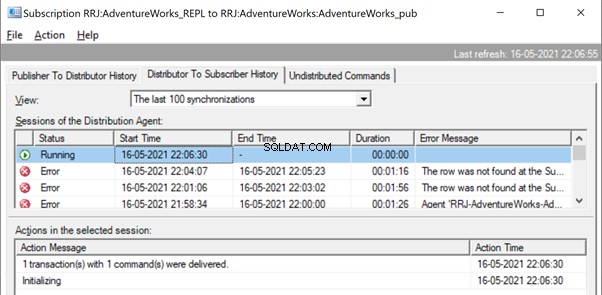
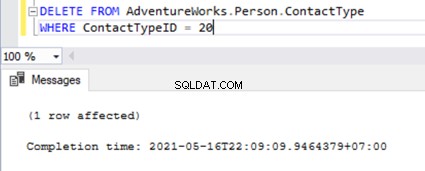
It is the same when we try to delete the ContactTypeId =20 from the Publisher database and see the error popping up in the Replication Monitor.
The Replication Monitor shows us a message similar to the one we already noticed:
The row was not found at the Subscriber when applying the replicated DELETE command for Table ‘[Person].[ContactType]’ with Primary Key(s):[ContactTypeID] =20 (Source:MSSQLServer, Error number:20598)
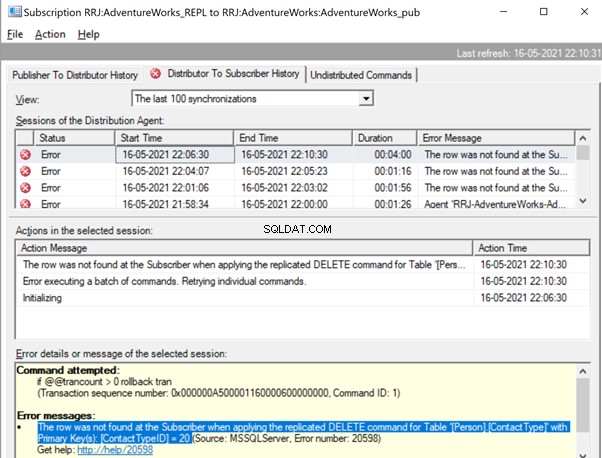
Similar to the previous error, we need to identify the missing record and insert it back to the Subscriber database for the DELETE statement to get replicated properly. For DELETE scenario, using -SkipErrors doesn’t have any issues but can’t be considered as a safe option, as both missing UPDATE or missing DELETE record are captured with the same error number 20598 and adding -SkipErrors 20598 will skip applying all records from the Subscriber database.
We can also get more details about the problematic command by using the sp_browsereplcmds stored procedure which we have discussed earlier as well. Let’s try to use sp_browsereplcmds stored procedure for the previous error we have received out as shown below.

exec sp_browsereplcmds @xact_seqno_start = '0x000000A500001160000600000000'
, @xact_seqno_end = '0x000000A500001160000600000000'
, @publisher_database_id = 1
, @command_id = 1
@xact_seqno_start and @xact_seqno_end will be the same value. We can fetch that value from the Transaction Sequence number in the Replication Monitor along with Command ID.
@publisher_database_id can be fetched from the id column of the distribution..MSPublisher_databases DMV.
select * from MSpublisher_databases Foreign Key or Other Constraint Violation Errors
The error messages related to Foreign keys or any other data issues are slightly different. Microsoft has made these error messages detailed and self-explanatory for anyone to understand what the issue is about.
To identify the exact command that was executed on the Publisher and resolve it efficiently, we can use the sp_browsereplcmds procedure explained above and identify the root cause of the issue.
Once the commands are identified as INSERT/UPDATE/DELETE which caused the errors, we can take corresponding actions to resolve the problems correctly which is more efficient compared to simply adding -SkipErrors approach. Once corrective measures are taken, Replication will start resuming fine immediately.
Word of Caution Using -SkipErrors Option
Those who are comfortable using -SkipErrors option to resolve error quickly should remember that -SkipErrors option is added at the Distribution agent level and applies to all Published articles in that Publication. Command -SkipErrors will result in skipping any number of commands related to that particular error across all published articles any number of times resulting in discrepancies we have seen in demo resulting in data discrepancies across Publisher and Subscriber without knowing how many tables are having discrepancies and would require efforts to compare the tables and fix it out.
Slutsats
Thanks for going through another robust article. I hope it was helpful for you to understand the SQL Server Transactional Replication issues and methods of troubleshooting them. In our next article, we’ll continue the discussion about the SQL Transaction Replication issues, examine other types, such as Corruption-related issues, and learn the best methods of handling them.