Håller du fortfarande på förälder/barn-designen, eller vill du prova något nytt, som SQL Server hierarchyID? Tja, det är verkligen nytt eftersom hierarchyID har varit en del av SQL Server sedan 2008. Självklart är nyheten i sig inte ett övertygande argument. Men observera att Microsoft lade till den här funktionen för att representera en-till-många-relationer med flera nivåer på ett bättre sätt.
Du kanske undrar vilken skillnad det gör och vilka fördelar du får av att använda hierarchyID istället för de vanliga förälder/barn-relationerna. Om du aldrig har utforskat det här alternativet kan det vara överraskande för dig.
Sanningen är att jag inte utforskade det här alternativet sedan det släpptes. Men när jag äntligen gjorde det tyckte jag att det var en stor innovation. Det är en snyggare kod, men den har mycket mer i sig. I den här artikeln ska vi ta reda på om alla dessa utmärkta möjligheter.
Men innan vi dyker in i särdragen med att använda SQL Server hierarchyID, låt oss klargöra dess innebörd och omfattning.
Vad är SQL Server HierarchyID?
SQL Server hierarchyID är en inbyggd datatyp designad för att representera träd, som är den vanligaste typen av hierarkisk data. Varje objekt i ett träd kallas en nod. I ett tabellformat är det en rad med en kolumn med hierarkiID-datatyp.
Vanligtvis visar vi hierarkier med hjälp av en tabelldesign. En ID-kolumn representerar en nod och en annan kolumn står för föräldern. Med SQL Server HierarchyID behöver vi bara en kolumn med en datatyp av hierarchyID.
När du frågar en tabell med en hierarki-ID-kolumn ser du hexadecimala värden. Det är en av de visuella bilderna av en nod. Ett annat sätt är en sträng:
'/' står för rotnoden;
'/1/', '/2/', '/3/' eller '/n/' står för barnen – direkta ättlingar 1 till n;
'/1/1/' eller '/1/2/' är "barn till barn – "barnbarn." Strängen som '/1/2/' betyder att det första barnet från roten har två barn, som i sin tur är två barnbarn till roten.
Här är ett exempel på hur det ser ut:
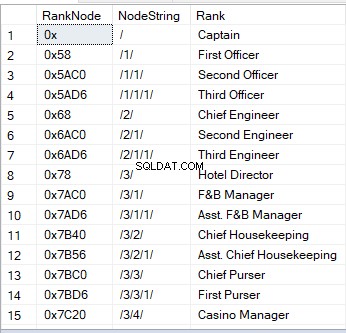
Till skillnad från andra datatyper kan hierarchyID-kolumner dra fördel av inbyggda metoder. Till exempel, om du har en hierarkiID-kolumn som heter RankNode , kan du ha följande syntax:
RankNode.
SQL Server HierarchyID Metoder
En av de tillgängliga metoderna är IsDescendantOf . Den returnerar 1 om den aktuella noden är en avkomling av ett hierarki-ID-värde.
Du kan skriva kod med den här metoden som liknar den nedan:
SELECT
r.RankNode
,r.Rank
FROM dbo.Ranks r
WHERE r.RankNode.IsDescendantOf(0x58) = 1Andra metoder som används med hierarchyID är följande:
- GetRoot – den statiska metoden som returnerar trädets rot.
- GetDescendant – returnerar en underordnad nod till en förälder.
- GetAncestor – returnerar ett hierarki-ID som representerar den n:te förfadern till en given nod.
- GetLevel – returnerar ett heltal som representerar nodens djup.
- ToString – returnerar strängen med den logiska representationen av en nod. ToString anropas implicit när omvandlingen från hierarki-ID till strängtypen sker.
- GetReparentedValue – flyttar en nod från den gamla föräldern till den nya föräldern.
- Parse – fungerar som motsatsen till ToString . Den konverterar strängvyn för ett hierarki-ID värde till hexadecimalt.
SQL Server HierarchyID Indexing Strategier
För att säkerställa att frågor för tabeller som använder hierarchyID körs så snabbt som möjligt måste du indexera kolumnen. Det finns två indexeringsstrategier:
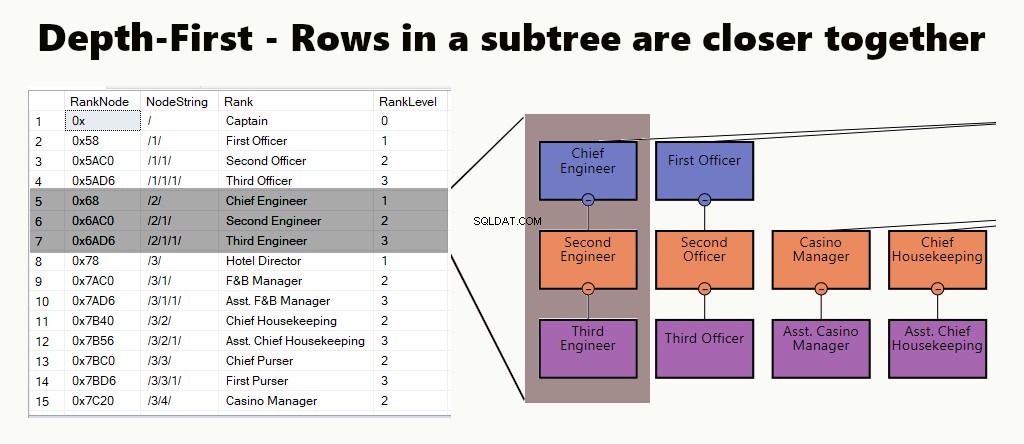
DJUP-FÖRSTA
I ett djup-först-index är underträdsraderna närmare varandra. Det passar frågor som att hitta en avdelning, dess underenheter och anställda. Ett annat exempel är en chef och dess anställda lagrade närmare varandra.
I en tabell kan du implementera ett djup-först-index genom att skapa ett klustrat index för noderna. Vidare utför vi ett av våra exempel, precis som det.
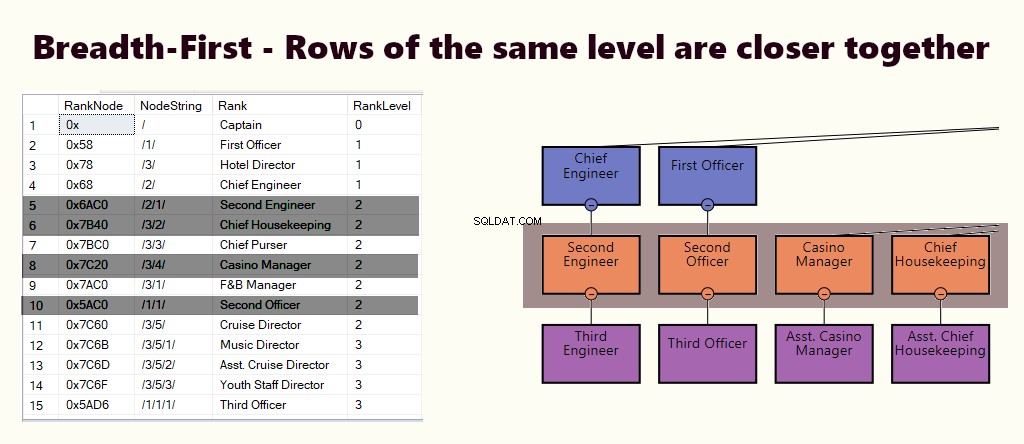
BREAD-FIRST
I ett bredd-först-index ligger samma nivås rader närmare varandra. Det passar frågor som att hitta alla chefens direktrapporterande medarbetare. Om de flesta av frågorna liknar detta, skapa ett klustrat index baserat på (1) nivå och (2) nod.
Det beror på dina krav om du behöver ett djup-först-index, ett bredd-först eller båda. Du måste balansera mellan vikten av frågetypen och DML-satserna du kör på tabellen.
SQL Server HierarchyID Begränsningar
Tyvärr kan användningen av hierarchyID inte lösa alla problem:
- SQL Server kan inte gissa vad som är barnet till en förälder. Du måste definiera trädet i tabellen.
- Om du inte använder en unik begränsning kommer det genererade hierarki-ID-värdet inte att vara unikt. Att hantera detta problem är utvecklarens ansvar.
- Relationer mellan en förälder och underordnade noder upprätthålls inte som en främmande nyckelrelation. Därför, innan du tar bort en nod, fråga efter eventuella ättlingar som finns.
Visualisera hierarkier
Innan vi fortsätter, fundera över en fråga till. Om du tittar på resultatuppsättningen med nodsträngar, tycker du att hierarkin visualiserar svårt för dina ögon?
För mig är det ett stort ja eftersom jag inte blir yngre.
Av denna anledning kommer vi att använda Power BI och Hierarchy Chart från Akvelon tillsammans med våra databastabeller. De hjälper till att visa hierarkin i ett organisationsschema. Jag hoppas att det kommer att göra jobbet lättare.
Låt oss nu börja.
Användningar av SQL Server HierarchyID
Du kan använda HierarchyID med följande affärsscenarier:
- Organisationsstruktur
- Mappar, undermappar och filer
- Uppgifter och deluppgifter i ett projekt
- Sidor och undersidor till en webbplats
- Geografisk data med länder, regioner och städer
Även om ditt affärsscenario liknar ovanstående, och du sällan frågar över hierarkisektionerna, behöver du inte hierarki-ID.
Till exempel behandlar din organisation lönelistor för anställda. Behöver du komma åt underträdet för att behandla någons lönelista? Inte alls. Men om du bearbetar provisioner från personer i ett marknadsföringssystem på flera nivåer kan det vara annorlunda.
I det här inlägget använder vi delen av organisationsstrukturen och kommandokedjan på ett kryssningsfartyg. Strukturen anpassades från organisationsschemat härifrån. Ta en titt på det i figur 4 nedan:

Nu kan du visualisera hierarkin i fråga. Vi använder nedanstående tabeller i det här inlägget:
- Fartyg – är bordet som står för kryssningsfartygens lista.
- Ranger – är tabellen över besättningsgrader. Där upprättar vi hierarkier med hjälp av hierarki-ID.
- Besättning – är listan över besättningen på varje fartyg och deras led.
Tabellstrukturen för varje fall är följande:
CREATE TABLE [dbo].[Vessel](
[VesselId] [int] IDENTITY(1,1) NOT NULL,
[VesselName] [varchar](20) NOT NULL,
CONSTRAINT [PK_Vessel] PRIMARY KEY CLUSTERED
(
[VesselId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Ranks](
[RankId] [int] IDENTITY(1,1) NOT NULL,
[Rank] [varchar](50) NOT NULL,
[RankNode] [hierarchyid] NOT NULL,
[RankLevel] [smallint] NOT NULL,
[ParentRankId] [int] -- this is redundant but we will use this to compare
-- with parent/child
) ON [PRIMARY]
GO
CREATE UNIQUE NONCLUSTERED INDEX [IX_RankId] ON [dbo].[Ranks]
(
[RankId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE UNIQUE CLUSTERED INDEX [IX_RankNode] ON [dbo].[Ranks]
(
[RankNode] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Crew](
[CrewId] [int] IDENTITY(1,1) NOT NULL,
[CrewName] [varchar](50) NOT NULL,
[DateHired] [date] NOT NULL,
[RankId] [int] NOT NULL,
[VesselId] [int] NOT NULL,
CONSTRAINT [PK_Crew] PRIMARY KEY CLUSTERED
(
[CrewId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Ranks] FOREIGN KEY([RankId])
REFERENCES [dbo].[Ranks] ([RankId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Ranks]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Vessel] FOREIGN KEY([VesselId])
REFERENCES [dbo].[Vessel] ([VesselId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Vessel]
GOInfoga tabelldata med SQL Server HierarchyID
Den första uppgiften med att använda hierarki-ID grundligt är att lägga till poster i tabellen med etthierarki-ID kolumn. Det finns två sätt att göra det.
Använda strängar
Det snabbaste sättet att infoga data med hierarki-ID är att använda strängar. För att se detta i praktiken, låt oss lägga till några poster i rankningarna bord.
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Captain', '/',0)
,('First Officer','/1/',1)
,('Chief Engineer','/2/',1)
,('Hotel Director','/3/',1)
,('Second Officer','/1/1/',2)
,('Second Engineer','/2/1/',2)
,('F&B Manager','/3/1/',2)
,('Chief Housekeeping','/3/2/',2)
,('Chief Purser','/3/3/',2)
,('Casino Manager','/3/4/',2)
,('Cruise Director','/3/5/',2)
,('Third Officer','/1/1/1/',3)
,('Third Engineer','/2/1/1/',3)
,('Asst. F&B Manager','/3/1/1/',3)
,('Asst. Chief Housekeeping','/3/2/1/',3)
,('First Purser','/3/3/1/',3)
,('Asst. Casino Manager','/3/4/1/',3)
,('Music Director','/3/5/1/',3)
,('Asst. Cruise Director','/3/5/2/',3)
,('Youth Staff Director','/3/5/3/',3)Ovanstående kod lägger till 20 poster till rangtabellen.
Som du kan se har trädstrukturen definierats i INSERT uttalande ovan. Det är lätt att urskilja när vi använder strängar. Dessutom konverterar SQL Server den till motsvarande hexadecimala värden.
Med Max(), GetAncestor() och GetDescendant()
Att använda strängar passar uppgiften att fylla i initialdata. I det långa loppet behöver du koden för att hantera infogning utan att tillhandahålla strängar.
För att göra denna uppgift, skaffa den sista noden som används av en förälder eller förfader. Vi åstadkommer det genom att använda funktionerna MAX() och GetAncestor() . Se exempelkoden nedan:
-- add a bartender rank reporting to the Asst. F&B Manager
DECLARE @MaxNode HIERARCHYID
DECLARE @ImmediateSuperior HIERARCHYID = 0x7AD6
SELECT @MaxNode = MAX(RankNode) FROM dbo.Ranks r
WHERE r.RankNode.GetAncestor(1) = @ImmediateSuperior
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Bartender', @ImmediateSuperior.GetDescendant(@MaxNode,NULL),
@ImmediateSuperior.GetDescendant(@MaxNode, NULL).GetLevel())Nedan är punkterna hämtade från ovanstående kod:
- Först behöver du en variabel för den sista noden och den närmaste överordnade.
- Den sista noden kan erhållas med MAX() mot RankNode för den angivna föräldern eller närmaste chef. I vårt fall är det Assistant F&B Manager med ett nodvärde på 0x7AD6.
- Använd sedan @ImmediateSuperior.GetDescendant(@MaxNode, NULL) för att säkerställa att inga dubbletter av barn visas. . Värdet i @MaxNode är det sista barnet. Om det inte är NULL , GetDescendant() returnerar nästa möjliga nodvärde.
- Sista, GetLevel() returnerar nivån för den nya skapade noden.
Fråga data
Efter att ha lagt till poster i vår tabell är det dags att fråga efter det. Det finns två sätt att söka efter data:
Frågan för Direct Descendants
När vi letar efter de anställda som direkt rapporterar till chefen behöver vi veta två saker:
- Nodvärdet för chefen eller föräldern
- Nivån på medarbetaren under chefen
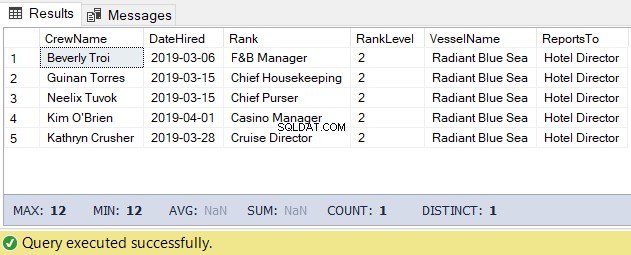
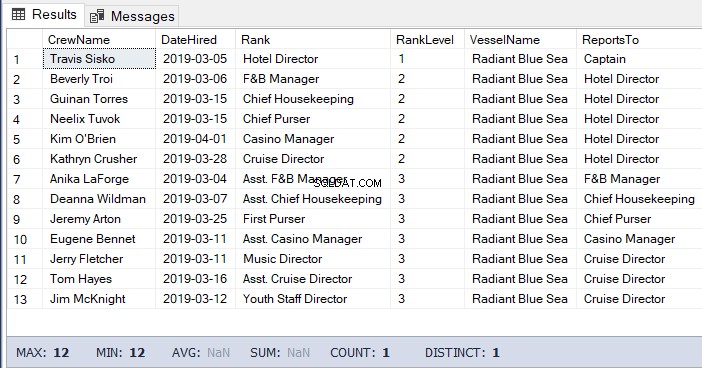
För denna uppgift kan vi använda koden nedan. Resultatet är listan över besättningen under hotelldirektören.
-- Get the list of crew directly reporting to the Hotel Director
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
DECLARE @Level SMALLINT = @Node.GetLevel()
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1
AND b.RankLevel = @Level + 1 -- add 1 for the level of the crew under the
-- Hotel DirectorResultatet av ovanstående kod är som följer i figur 5:
Fråga efter underträd
Ibland måste du också lista barnen och barnens barn ner till botten. För att göra detta måste du ha förälderns hierarki-ID.
Frågan kommer att likna den tidigare koden men utan att behöva få nivån. Se kodexemplet:
-- Get the list of the crew under the Hotel Director down to the lowest level
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1Resultatet av ovanstående kod:
Flytta noder med SQL Server HierarchyID
En annan standardoperation med hierarkisk data är att flytta ett barn eller ett helt underträd till en annan förälder. Men innan vi fortsätter, notera ett potentiellt problem:
Potentiellt problem
- För det första involverar rörliga noder I/O. Hur ofta du flyttar noder kan vara avgörande om du använder hierarchyID eller den vanliga föräldern/barnet.
- För det andra uppdateras en rad genom att flytta en nod i en överordnad/underordnad design. Samtidigt, när du flyttar en nod med hierarki-ID, uppdateras en eller flera rader. Antalet rader som påverkas beror på hierarkinivåns djup. Det kan förvandlas till ett betydande prestandaproblem.
Lösning
Du kan hantera detta problem med din databasdesign.
Låt oss överväga designen vi använde här.
Istället för att definiera hierarkin på Crew tabellen definierade vi den i rankningarna tabell. Detta tillvägagångssätt skiljer sig från anställd tabellen i AdventureWorks exempeldatabas, och den erbjuder följande fördelar:
- Besättningsmedlemmarna rör sig oftare än leden i ett fartyg. Denna design kommer att minska nodernas rörelser i hierarkin. Som ett resultat minimerar det problemet som definierats ovan.
- Definiera mer än en hierarki i besättningen Tabellen är mer komplicerad, eftersom två fartyg behöver två kaptener. Resultatet är två rotnoder.
- Om du behöver visa alla grader med motsvarande besättningsmedlem kan du använda en LEFT JOIN. Om ingen är ombord för den rangen visar den en tom plats för positionen.
Låt oss nu gå vidare till syftet med detta avsnitt. Lägg till barnnoder under fel föräldrar.
För att visualisera vad vi ska göra, föreställ dig en hierarki som den nedan. Notera de gula noderna.

Flytta en nod utan barn
Att flytta en underordnad nod kräver följande:
- Definiera hierarki-ID för den underordnade noden som ska flyttas.
- Definiera den gamla förälderns hierarki-ID.
- Definiera den nya förälderns hierarki-ID.
- Använd UPPDATERA med GetReparentedValue() för att flytta noden fysiskt.
Börja med att flytta en nod utan barn. I exemplet nedan flyttar vi kryssningspersonalen från under kryssningsdirektören till under assistenten. Kryssningsdirektör.
-- Moving a node with no child node
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 24 -- the cruise staff
SELECT @OldParent = @NodeToMove.GetAncestor(1)
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 19 -- the assistant cruise director
UPDATE dbo.Ranks
SET RankNode = @NodeToMove.GetReparentedValue(@OldParent,@NewParent)
WHERE RankNode = @NodeToMoveNär noden väl har uppdaterats kommer ett nytt hexadecimalt värde att användas för noden. Uppdaterar min Power BI-anslutning till SQL Server – det kommer att ändra hierarkidiagrammet enligt nedan:
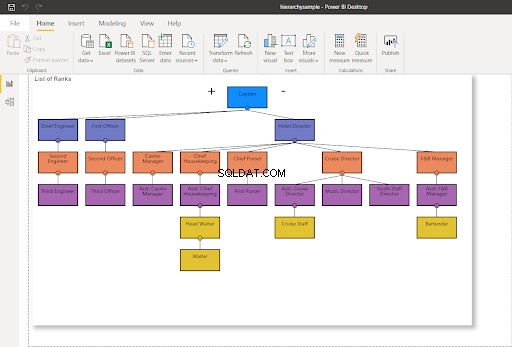
I figur 8 rapporterar kryssningspersonalen inte längre till kryssningschefen – den ändras till att rapportera till assisterande kryssningschef. Jämför det med figur 7 ovan.
Låt oss nu gå vidare till nästa steg och flytta huvudservitören till assisterande F&B Manager.
Flytta en nod med barn
Det finns en utmaning i den här delen.
Saken är den att den tidigare koden inte fungerar med en nod med ens ett barn. Vi kommer ihåg att flytta en nod kräver att en eller flera underordnade noder uppdateras.
Dessutom slutar det inte där. Om den nya föräldern har ett befintligt barn kan vi stöta på dubbla nodvärden.
I det här exemplet måste vi möta det problemet:Asst. F&B Manager har en Bartender-barnnod.
Redo? Här är koden:
-- Move a node with at least one child
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 22 -- the head waiter
SELECT @OldParent = @NodeToMove.GetAncestor(1) -- head waiter's old parent
--> asst chief housekeeping
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 14 -- the assistant f&b manager
DECLARE children_cursor CURSOR FOR
SELECT RankNode FROM dbo.Ranks r
WHERE RankNode.GetAncestor(1) = @OldParent;
DECLARE @ChildId hierarchyid;
OPEN children_cursor
FETCH NEXT FROM children_cursor INTO @ChildId;
WHILE @@FETCH_STATUS = 0
BEGIN
START:
DECLARE @NewId hierarchyid;
SELECT @NewId = @NewParent.GetDescendant(MAX(RankNode), NULL)
FROM dbo.Ranks r WHERE RankNode.GetAncestor(1) = @NewParent; -- ensure
--to get a new id in case there's a
--sibling
UPDATE dbo.Ranks
SET RankNode = RankNode.GetReparentedValue(@ChildId, @NewId)
WHERE RankNode.IsDescendantOf(@ChildId) = 1;
IF @@error <> 0 GOTO START -- On error, retry
FETCH NEXT FROM children_cursor INTO @ChildId;
END
CLOSE children_cursor;
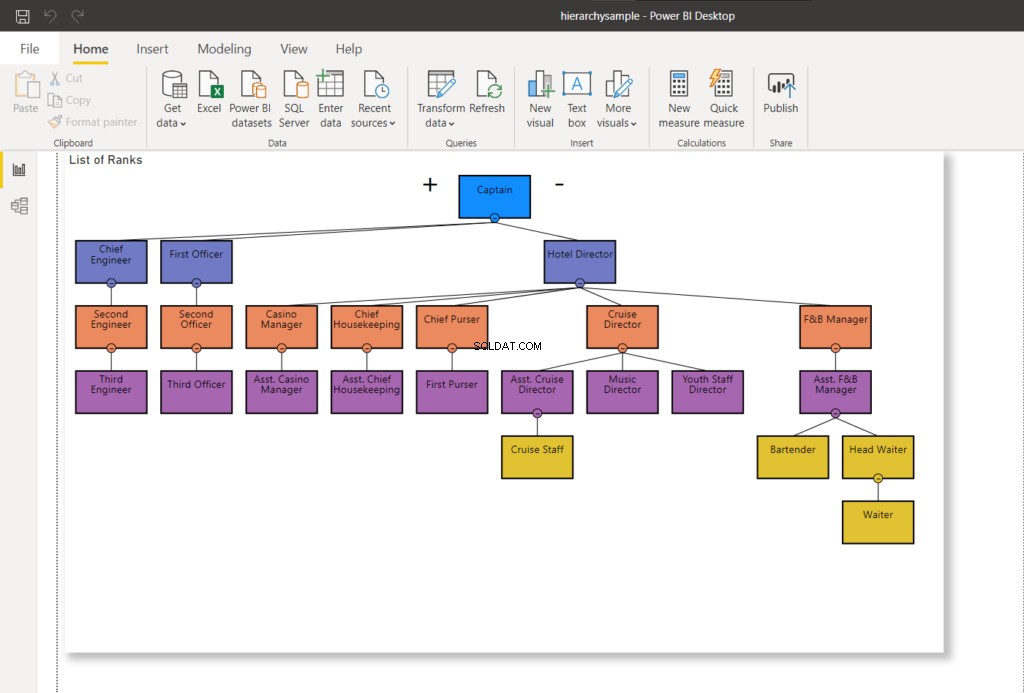
DEALLOCATE children_cursor;I ovanstående kodexempel börjar iterationen som behovet av att överföra noden ner till barnet på den sista nivån.
När du har kört det, rankas tabellen kommer att uppdateras. Och igen, om du vill se ändringarna visuellt, uppdatera Power BI-rapporten. Du kommer att se ändringar som liknar den nedan:
Fördelar med att använda SQL Server HierarchyID kontra förälder/barn
För att övertyga någon att använda en funktion måste vi känna till fördelarna.
I det här avsnittet kommer vi alltså att jämföra påståenden med samma tabeller som de från början. En kommer att använda hierarchyID, och den andra kommer att använda förälder/barn-metoden. Resultatuppsättningen kommer att vara densamma för båda tillvägagångssätten. Vi förväntar oss att den för den här övningen är den från Figur 6 ovan.
Nu när kraven är exakta, låt oss undersöka fördelarna noggrant.
Enklare att koda
Se koden nedan:
-- List down all the crew under the Hotel Director using hierarchyID
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.RANK AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON d.RankNode = b.RankNode.GetAncestor(1)
WHERE a.VesselId = 1
AND b.RankNode.IsDescendantOf(0x78)=1Detta exempel behöver bara ett hierarki-ID-värde. Du kan ändra värdet efter behag utan att ändra frågan.
Jämför nu uttalandet för förälder/barn-metoden som ger samma resultatuppsättning:
-- List down all the crew under the Hotel Director using parent/child
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.Rank AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON b.RankParentId = d.RankId
WHERE a.VesselId = 1
AND (b.RankID = 4) OR (b.RankParentID = 4 OR b.RankParentId >= 7)Vad tror du? Kodexemplen är nästan desamma förutom en punkt.
VAR satsen i den andra frågan kommer inte att vara flexibel att anpassa om ett annat underträd krävs.
Gör den andra frågan generisk nog så blir koden längre. Hoppsan!
Snabbare exekvering
Enligt Microsoft är "underträdsfrågor betydligt snabbare med hierarki-ID" jämfört med förälder/barn. Låt oss se om det är sant.
Vi använder samma frågor som tidigare. Ett viktigt mått att använda för prestanda är de logiska läsningarna från SET STATISTICS IO . Den talar om hur många 8KB sidor SQL Server kommer att behöva för att få den resultatuppsättning vi vill ha. Ju högre värde, desto större antal sidor som SQL Server kommer åt och läser, och desto långsammare körs frågan. Kör SET STATISTICS IO ON och kör om de två frågorna ovan. Det lägre värdet på de logiska läsningarna kommer att vinna.
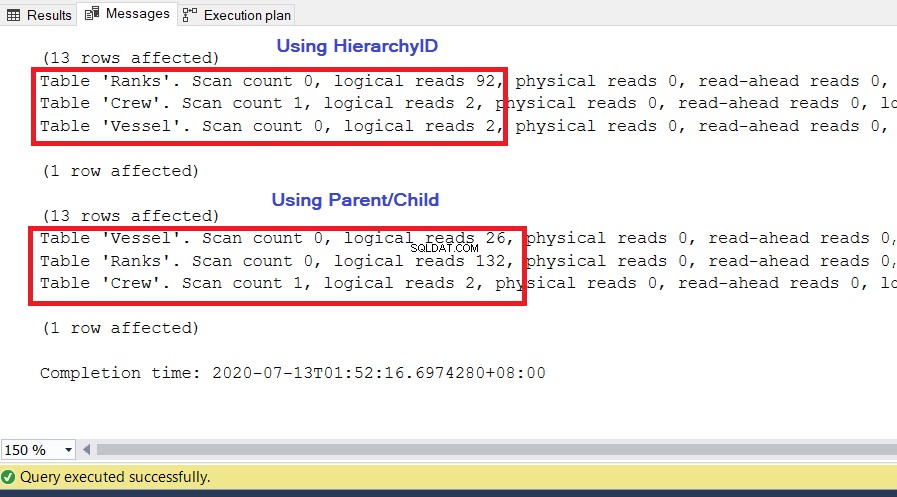
ANALYS
Som du kan se i figur 10 har I/O-statistiken för frågan med hierarki-ID lägre logiska läsningar än deras överordnade/underordnade motsvarigheter. Notera följande punkter i detta resultat:
- Fartyget tabellen är den mest anmärkningsvärda av de tre tabellerna. Att använda hierarchyID kräver endast 2 * 8KB =16KB sidor som ska läsas av SQL Server från cachen (minnet). Samtidigt kräver förälder/barn 26 * 8KB =208KB sidor – betydligt högre än att använda hierarki-ID.
- Rank tabell, som inkluderar vår definition av hierarkier, kräver 92 * 8KB =736KB. Å andra sidan kräver förälder/barn 132 * 8KB =1056KB.
- Besättningen tabellen behöver 2 * 8KB =16KB, vilket är samma för båda metoderna.
Kilobyte sidor kan vara ett litet värde för tillfället, men vi har bara ett fåtal poster. Det ger oss dock en uppfattning om hur belastande vår fråga kommer att vara på vilken server som helst. För att förbättra prestandan kan du göra en eller flera av följande åtgärder:
- Lägg till lämpliga index
- Omstrukturera frågan
- Uppdatera statistik
Om du gjorde ovanstående, och de logiska läsningarna minskade utan att lägga till fler poster, skulle prestandan öka. Så länge du gör de logiska läsningarna lägre än för den som använder hierarchyID, kommer det att vara goda nyheter.
Men varför hänvisa till logiska läsningar istället för förfluten tid?
Kontrollerar förfluten tid för båda frågorna med STÄLL IN STATISTIK TID PÅ avslöjar ett litet antal millisekunders skillnader för vår lilla uppsättning data. Dessutom kan din utvecklingsserver ha en annan hårdvarukonfiguration, SQL Server-inställningar och arbetsbelastning. En förfluten tid på mindre än en millisekund kan lura dig om din fråga fungerar så snabbt som du förväntar dig eller inte.
Gräver vidare
STÄLL PÅ STATISTIK IO avslöjar inte vad som händer "bakom kulisserna". I det här avsnittet tar vi reda på varför SQL Server kommer med dessa siffror genom att titta på exekveringsplanen.
Låt oss börja med exekveringsplanen för den första frågan.
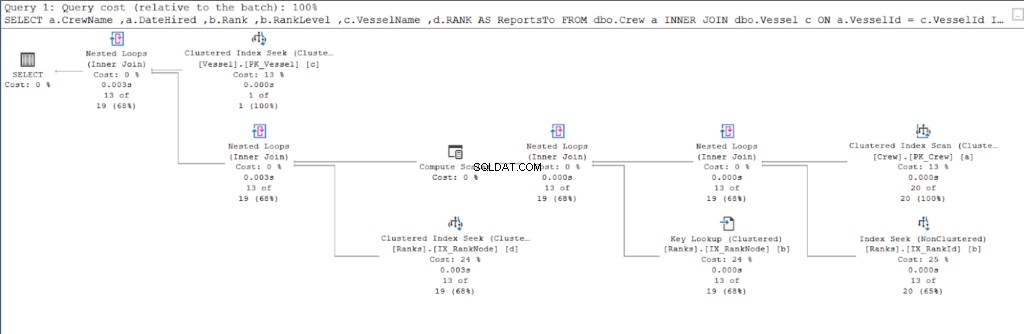
Titta nu på exekveringsplanen för den andra frågan.
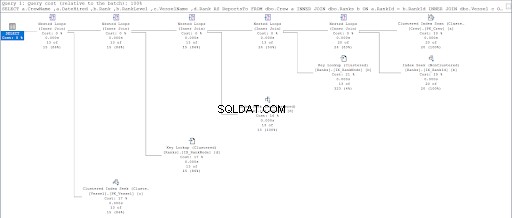
Genom att jämföra figurerna 11 och 12 ser vi att SQL Server behöver ytterligare ansträngning för att producera resultatuppsättningen om du använder förälder/barn-metoden. VAR klausulen är ansvarig för denna komplikation.
Felet kan dock också bero på bordets utformning. Vi använde samma tabell för båda metoderna:rankningarna tabell. Så jag försökte duplicera rankningarna tabell men använder olika klustrade index som är lämpliga för varje procedur.
Som resultat hade användningen av hierarchyID fortfarande mindre logiska läsningar jämfört med förälder/underordnad motsvarighet. Slutligen bevisade vi att Microsoft gjorde rätt i att hävda det.
Slutsats
Här är det centrala aha-momentet för hierarki-ID:
- HierarchyID är en inbyggd datatyp designad för en mer optimerad representation av träd, som är den vanligaste typen av hierarkisk data.
- Varje objekt i trädet är en nod och hierarki-ID-värden kan vara i hexadecimalt eller strängformat.
- HierarchyID är tillämpligt för data om organisationsstrukturer, projektuppgifter, geografiska data och liknande.
- Det finns metoder för att gå igenom och manipulera hierarkiska data, som GetAncestor (), GetDescendant (). GetLevel (), GetReparentedValue () och mer.
- Det konventionella sättet att fråga efter hierarkisk data är att hämta de direkta ättlingarna till en nod eller få underträden under en nod.
- Användningen av hierarchyID för att fråga underträd är inte bara enklare att koda. Den presterar också bättre än förälder/barn.
Förälder/barn-design är inte alls dåligt, och det här inlägget är inte för att förminska det. Att utöka alternativen och introducera nya idéer är dock alltid en stor fördel för en utvecklare.
Du kan själv prova de exempel vi gav här. Ta emot effekterna och se hur du kan använda det för ditt nästa projekt som involverar hierarkier.
Om du gillar inlägget och dess idéer kan du sprida budskapet genom att klicka på delningsknapparna för de sociala medier du föredrar.