Enligt Wikipedia är bulkinfogningen en process eller metod som tillhandahålls av ett databashanteringssystem för att ladda flera rader med data i en databastabell. Om vi justerar denna förklaring till BULK INSERT-satsen, tillåter bulkinsert import av externa datafiler till SQL Server.
Antag att vår organisation har en CSV-fil med 1 500 000 rader och vi vill importera den till en viss tabell i SQL Server för att använda BULK INSERT-satsen i SQL Server. Vi kan hitta flera metoder för att hantera denna uppgift. Det kan vara att använda BCP (b ulk c opy p rogram), SQL Server Import och Export Wizard eller SQL Server Integration Service-paket. Men BULK INSERT-satsen är mycket snabbare och potent. En annan fördel är att den erbjuder flera parametrar som hjälper till att bestämma inställningarna för bulkinsertprocessen.
Låt oss börja med ett grundläggande prov. Sedan ska vi gå igenom mer sofistikerade scenarier.
Förberedelser
Först och främst behöver vi ett exempel på en CSV-fil. Vi laddar ner en exempel-CSV-fil från E for Excel-webbplatsen (en samling av CSV-filer med ett annat radnummer). Här kommer vi att använda 1 500 000 försäljningsposter.
Ladda ner en zip-fil, packa upp den för att få en CSV-fil och placera den på din lokala enhet.
Importera CSV-fil till SQL Server-tabell
Vi importerar vår CSV-fil till destinationstabellen i enklaste form. Jag placerade min exempel-CSV-fil på C:-enheten. Nu skapar vi en tabell för att importera CSV-fildata till den:
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
Följande BULK INSERT-sats importerar CSV-filen till försäljningstabellen:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Du har antagligen noterat de specifika parametrarna i ovanstående bulkinsert-sats. Låt oss förtydliga dem:
- FIRSTROW anger startpunkten för infogningssatsen. I exemplet nedan vill vi hoppa över kolumnrubriker, så vi ställer in den här parametern till 2.

- FIELDTERMINATOR definierar tecknet som skiljer fält från varandra. SQL Server upptäcker varje fält på detta sätt.
- ROWTERMINATOR skiljer sig inte mycket från FIELDTERMINATOR. Den definierar separationskaraktären för rader.
I exempel-CSV-filen är FIELDTERMINATOR mycket tydlig, och det är ett kommatecken (,). För att upptäcka denna parameter, öppna CSV-filen i Notepad++ och navigera till Visa -> Visa symbol -> Visa alla charter. CRLF-tecknen finns i slutet av varje fält.
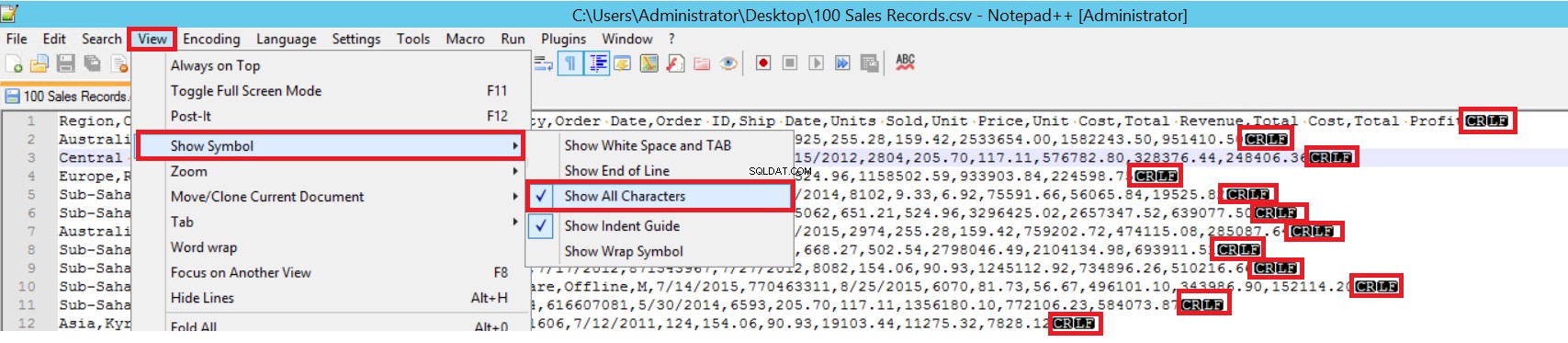
CR =Carriage Return och LF =Linjematning. De används för att markera en radbrytning i en textfil. Indikatorn är "\n" i bulkinsert-satsen.
Ett annat sätt att importera en CSV-fil till en tabell med bulkinfogning är att använda parametern FORMAT. Observera att den här parametern endast är tillgänglig i SQL Server 2017 och senare versioner.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
Det var det enklaste scenariot där måltabellen och CSV-filen har lika många kolumner. Men fallet när måltabellen har fler kolumner, då är CSV-filen typisk. Låt oss överväga det.
Vi lägger till en primärnyckel i tabellen Försäljning för att bryta mappningarna av jämlikhetskolumnen. Vi skapar försäljningstabellen med en primärnyckel och importerar CSV-filen genom kommandot bulk insert.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Men det ger ett fel:
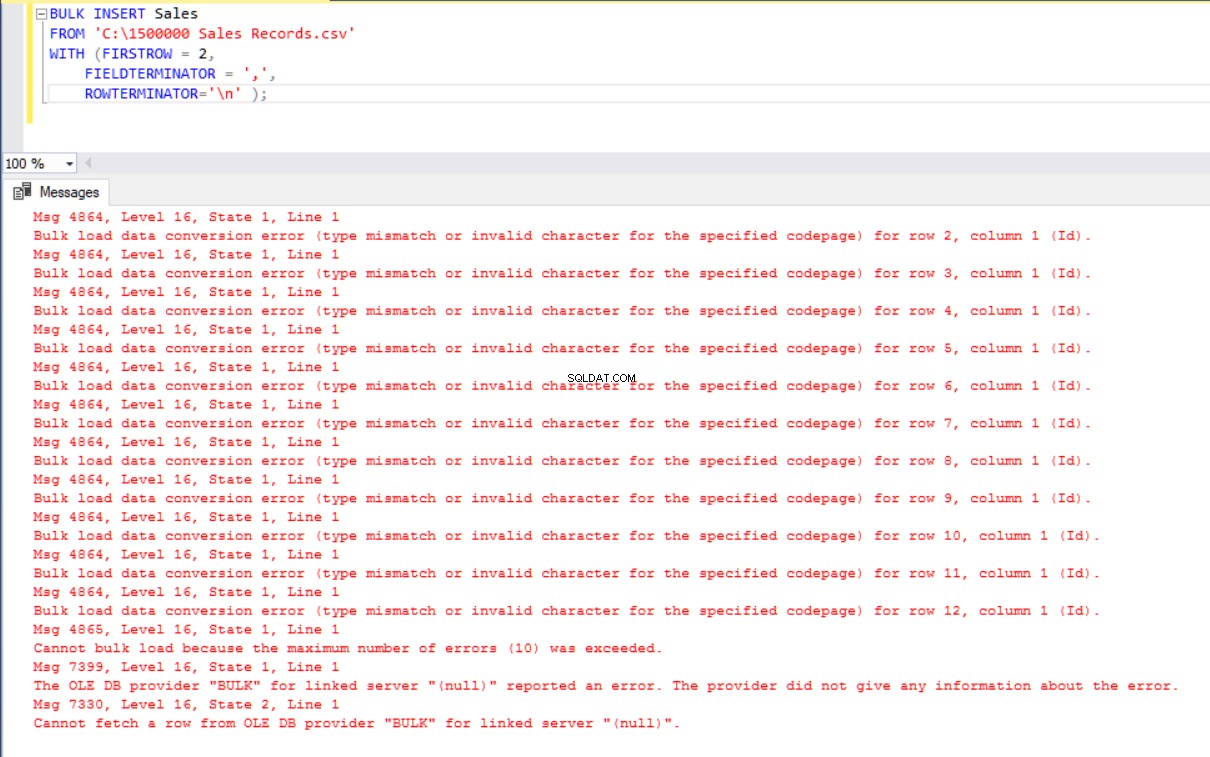
För att övervinna felet skapar vi en vy av försäljningstabellen med mappningskolumner till CSV-filen. Sedan importerar vi CSV-data över denna vy till tabellen Försäljning:
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Separera och ladda en stor CSV-fil i en liten batchstorlek
SQL Server skaffar ett lås till destinationstabellen under massinsättningsoperationen. Som standard, om du inte ställer in parametern BATCHSIZE, öppnar SQL Server en transaktion och infogar hela CSV-data i den. Med den här parametern delar SQL Server upp CSV-data enligt parametervärdet.
Låt oss dela upp hela CSV-data i flera uppsättningar med 300 000 rader vardera.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 ); Uppgifterna kommer att importeras fem gånger i delar.
- Om din bulkinsert-sats inte inkluderar BATCHSIZE-parametern, kommer ett fel att uppstå och SQL-servern återställer hela bulk-insättningsprocessen.
- Med denna parameter inställd på bulk insert-sats, återställer SQL Server endast den del där felet uppstod.
Det finns inget optimalt eller bästa värde för denna parameter eftersom dess värde kan ändras enligt dina databassystemkrav.
Ställ in beteendet vid fel
Om ett fel uppstår i vissa scenarier för masskopiering kan vi antingen avbryta masskopieringsprocessen eller fortsätta. Parametern MAXERRORS tillåter oss att ange det maximala antalet fel. Om massinsättningsprocessen når detta maximala felvärde avbryter den massimporten och rullar tillbaka. Standardvärdet för denna parameter är 10.
Till exempel har vi skadade datatyper i 3 rader i CSV-filen. Parametern MAXERRORS är inställd på 2.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2); Hela massinsättningsoperationen avbryts eftersom det finns fler fel än parametervärdet MAXERRORS.
Om vi ändrar parametern MAXERRORS till 4, kommer bulk insert-satsen att hoppa över dessa rader med fel och infoga korrekta datastrukturerade rader. Massinsättningsprocessen kommer att slutföras.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales Om vi använder både BATCHSIZE och MAXERRORS samtidigt, kommer masskopieringsprocessen inte att avbryta hela infogningsoperationen. Det kommer bara att avbryta den delade delen.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales Ta en titt på bilden nedan som visar resultatet av skriptexekveringen:
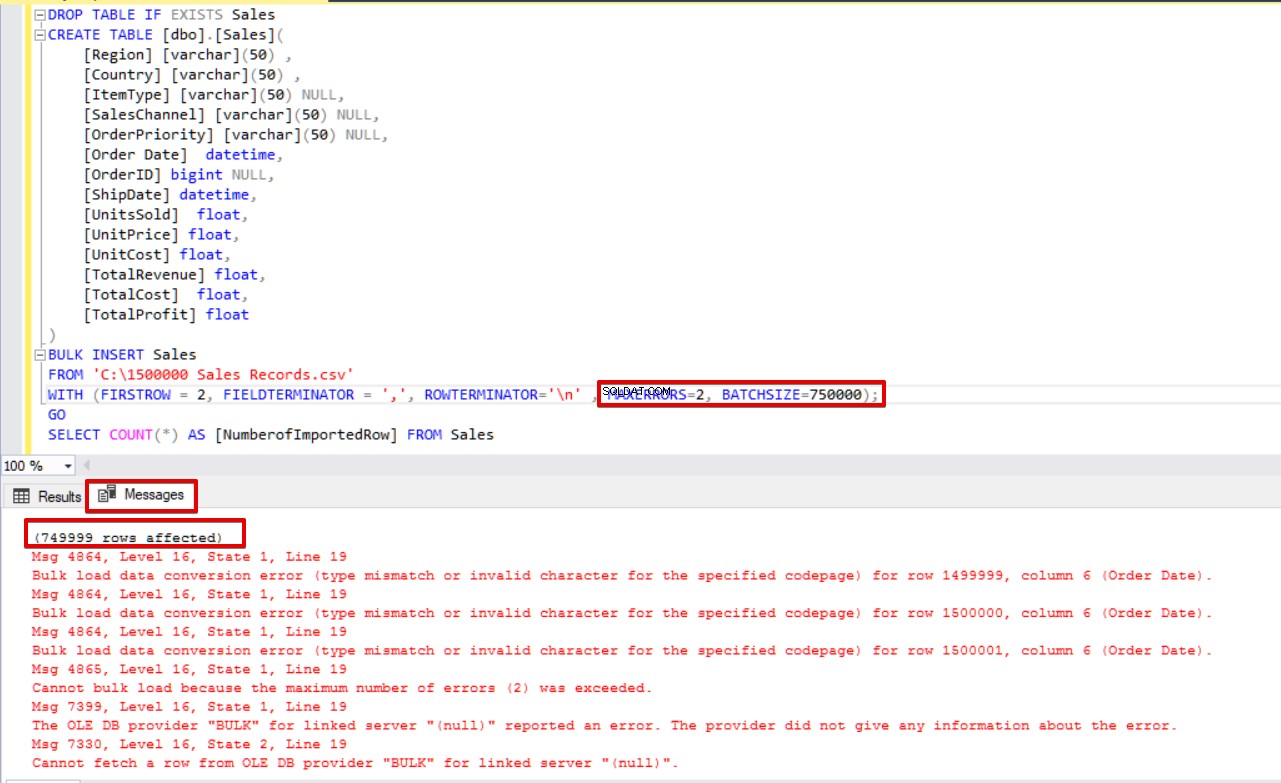
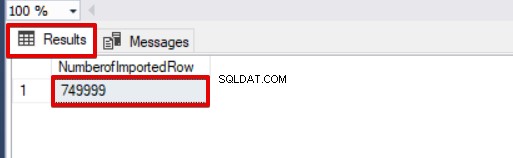
Andra alternativ för massinsättningsprocessen
FIRE_TRIGGERS – aktivera utlösare i destinationstabellen under massinsättningsoperationen
Som standard aktiveras inte infogningstriggarna som anges i måltabellen under massinsättningsprocessen. Men i vissa situationer kanske vi vill aktivera dem.
Lösningen använder alternativet FIRE_TRIGGERS i bulkinfogningssatser. Men observera att det kan påverka och minska bulkskärets funktionsprestanda. Det beror på att trigger/triggers kan göra separata operationer i databasen.
Först ställer vi inte in FIRE_TRIGGERS-parametern, och massinsättningsprocessen kommer inte att aktivera insättningsutlösaren. Se nedanstående T-SQL-skript:
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
DROP TABLE IF EXISTS SalesLog
CREATE TABLE SalesLog (OrderIDLog bigint)
GO
CREATE TRIGGER OrderLogIns ON Sales
FOR INSERT
AS
BEGIN
SET NOCOUNT ON
INSERT INTO SalesLog
SELECT OrderId from inserted
end
GO
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
SELECT Count(*) FROM SalesLogNär det här skriptet körs aktiveras inte infogningsutlösaren eftersom alternativet FIRE_TRIGGERS inte är inställt.
Låt oss nu lägga till alternativet FIRE_TRIGGERS till bulkinsert-satsen:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n',
FIRE_TRIGGERS);
GO
SELECT Count(*) as [NumberOfRowsinTriggerTable] FROM SalesLog 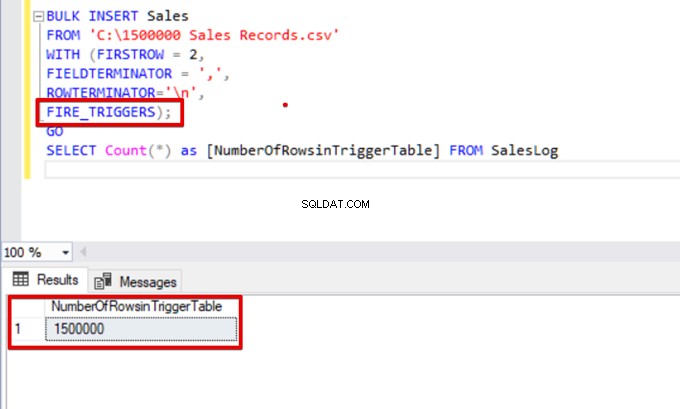
CHECK_CONSTRAINTS – aktivera en kontrollbegränsning under bulkinsertoperationen
Kontrollbegränsningar tillåter oss att upprätthålla dataintegritet i SQL Server-tabeller. Syftet med begränsningen är att kontrollera infogade, uppdaterade eller raderade värden enligt deras syntaxreglering. Som t.ex. NOT NULL-begränsningen ger att NULL-värdet inte kan ändra en specificerad kolumn.
Här fokuserar vi på begränsningar och bulkinsert-interaktioner. Som standard ignoreras alla kontroll- och främmande nyckelbegränsningar under massinsättningsprocessen. Men det finns några undantag.
Enligt Microsoft, "UNIKA och PRIMARY KEY-begränsningar upprätthålls alltid. Vid import till en teckenkolumn där NOT NULL-begränsningen är definierad, infogar BULK INSERT en tom sträng när det inte finns något värde i textfilen."
I följande T-SQL-skript lägger vi till en kontrollbegränsning i kolumnen OrderDate, som styr orderdatumet större än 01.01.2016.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
ALTER TABLE [Sales] ADD CONSTRAINT OrderDate_Check
CHECK(OrderDate >'20160101')
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
GO
SELECT COUNT(*) AS [UnChekedData] FROM
Sales WHERE OrderDate <'20160101'Som ett resultat hoppar massinsättningsprocessen över kontrollbegränsningskontrollen. SQL Server indikerar dock att kontrollbegränsningen inte är betrodd:
SELECT is_not_trusted ,* FROM sys.check_constraints where name='OrderDate_Check'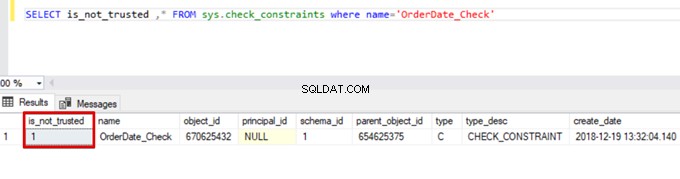
Detta värde indikerar att någon infogat eller uppdaterat vissa data i den här kolumnen genom att hoppa över kontrollbegränsningen. Samtidigt kan den här kolumnen innehålla inkonsekventa data om den begränsningen.
Försök att köra bulkinsert-satsen med alternativet CHECK_CONSTRAINTS. Resultatet är enkelt:check constraint returnerar ett fel på grund av felaktig data.
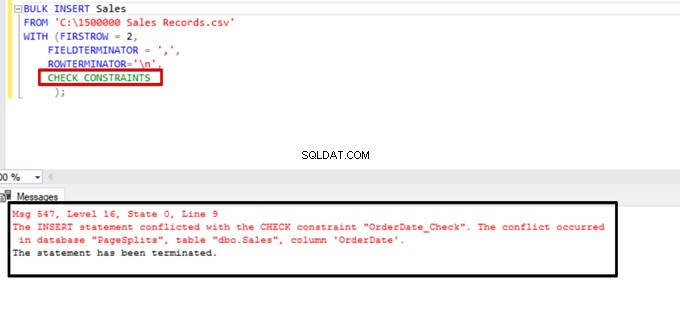
TABLOCK – öka prestandan i flera massinlägg i en måltabell
Det primära syftet med låsmekanismen i SQL Server är att skydda och säkerställa dataintegritet. I huvudkonceptet för SQL Server-låsningsartikeln kan du hitta detaljer om låsmekanismen.
Vi kommer att fokusera på processlåsdetaljer för massinsättning.
Om du kör satsen bulk insert utan TABLELOCK-alternativet, förvärvar den låsningen av rader eller tabeller enligt låshierarkin. Men i vissa fall kanske vi vill köra flera massinsättningsprocesser mot en destinationstabell och därmed minska operationstiden.
Först exekverar vi två bulk insert-satser samtidigt och analyserar låsmekanismens beteende. Öppna två frågefönster i SQL Server Management Studio och kör följande massinsättningssatser samtidigt.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
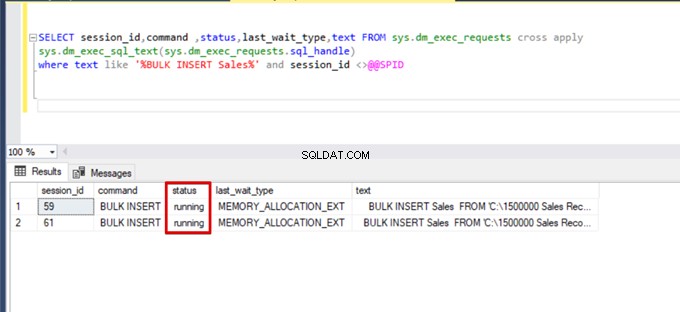
);Kör följande DMV-fråga (Dynamic Management View) – det hjälper till att övervaka statusen för massinsättningsprocessen:
SELECT session_id,command ,status,last_wait_type,text FROM sys.dm_exec_requests cross apply
sys.dm_exec_sql_text(sys.dm_exec_requests.sql_handle)
where text like '%BULK INSERT Sales%' and session_id <>@@SPID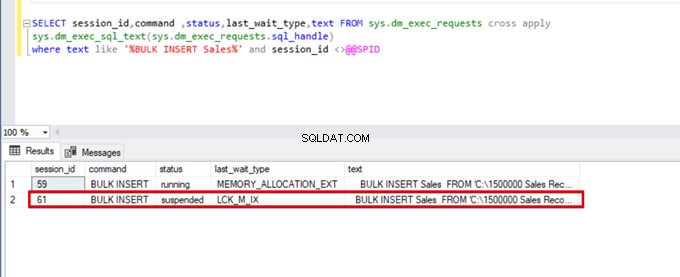
Som du kan se i bilden ovan, session 61, är bulkinsertprocessens status avstängd på grund av låsning. Om vi verifierar problemet låser session 59 destinationstabellen för massinsättning. Sedan väntar session 61 på att släppa detta lås för att fortsätta massinsättningsprocessen.
Nu lägger vi till alternativet TABLOCK till bulkinfogningssatserna och kör frågorna.
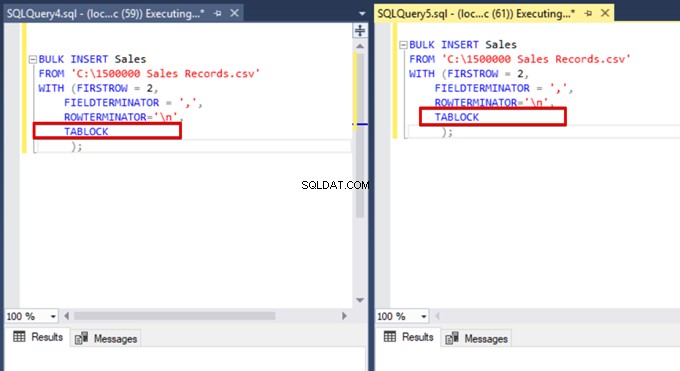
När vi kör DMV-övervakningsfrågan igen kan vi inte se någon avstängd massinsättningsprocess eftersom SQL Server använder en viss låstyp som kallas bulkuppdateringslås (BU). Denna låstyp tillåter bearbetning av flera massinsättningsoperationer mot samma tabell samtidigt. Detta alternativ minskar också den totala tiden för massinsättningsprocessen.
När vi utför följande fråga under massinsättningsprocessen kan vi övervaka låsdetaljerna och låstyperna:
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'OBJECT'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()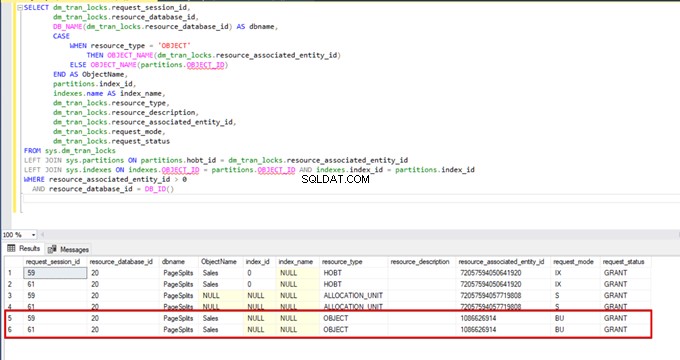
Slutsats
Den aktuella artikeln utforskade alla detaljer om bulkinsert-operation i SQL Server. Särskilt nämnde vi kommandot BULK INSERT och dess inställningar och alternativ. Vi analyserade också olika scenarier nära verkliga problem.
Användbart verktyg:
dbForge Data Pump – ett SSMS-tillägg för att fylla SQL-databaser med externa källdata och migrera data mellan system.