Databasen är en kritisk och vital del av alla företag eller organisationer. De växande trenderna förutspår att 82 % av företagen förväntar sig att antalet databaser kommer att öka under de kommande 12 månaderna. En stor utmaning för varje DBA är att upptäcka hur man tacklar massiv datatillväxt, och detta kommer att bli ett mycket viktigt mål. Hur kan du öka databasprestanda, lägre kostnader och eliminera driftstopp för att ge dina användare den bästa möjliga upplevelsen? Är datakomprimering ett alternativ? Låt oss komma igång och se hur några av de befintliga funktionerna kan vara användbara för att hantera sådana situationer.
I den här artikeln kommer vi att lära oss hur datakomprimeringslösningen kan hjälpa oss att optimera datahanteringslösningen. I den här guiden tar vi upp följande ämnen:
- En översikt över komprimering
- Fördelar med komprimering
- En beskrivning av data är komprimeringstekniker
- Diskussion om olika typer av datakomprimering
- Fakta om datakomprimering
- Implementeringsöverväganden
- och mer...
Kompression
Komprimeringen är en teknik och därmed en resurskänslig operation, men med hårdvaruavvägningar. Man måste tänka på att distribuera datakomprimering för följande fördelar:
- Effektiv utrymmeshantering
- Effektiv kostnadsreduktionsteknik
- Lätt att hantera databassäkerhetskopiering
- Effektiv N/W-bandbreddsanvändning
- Säker och snabbare återställning eller återställning
- Bättre prestanda – minskar systemets minnesfotavtryck
Obs! Om SQL Server är CPU- eller minnesbegränsad kanske komprimering inte passar din miljö.
Datakomprimering gäller för:
- Högar
- Klustrerade index
- Icke-klustrade index
- Partitioner
- Indexerade vyer
Obs! Stora objekt komprimeras inte (till exempel LOB och BLOB)
Lämpar sig bäst för följande applikationer:
- Loggtabeller
- Revisionstabeller
- Faktatabeller
- Rapportering
Introduktion
Datakomprimering är en teknik som har funnits sedan SQL Server 2008. Tanken med datakomprimering är att du selektivt kan välja tabeller, index eller partitioner i en databas. I/O fortsätter att vara en flaskhals för att flytta information mellan in och ut i databasen. Datakomprimering drar fördel av denna typ och hjälper till att öka effektiviteten i en databas. Eftersom vi vet att nätverkshastigheterna är så mycket långsammare än bearbetningshastigheten, är det möjligt att hitta effektivitetsvinster genom att använda processorkraften för att komprimera data i en databas, så att den färdas snabbare. Och använd sedan processorkraft igen för att komprimera data i andra änden. I allmänhet minskar datakomprimering det utrymme som tas upp av data. Tekniken för datakomprimering är tillgänglig för varje databas och den stöds av alla utgåvor av SQL Server 2016 SP1. Innan detta var det bara tillgängligt på SQL Server Enterprise eller Developer-utgåvor, inte på Standard eller Express.
Funktionsstöd

Datakomprimeringstyper
Det finns två typer av datakomprimering tillgängliga inom SQL Server, radnivå och sidnivå.
Kompressionen på radnivå fungerar bakom kulisserna och konverterar alla datatyper med fast längd till typer av variabel längd. Antagandet här är att data ofta lagras med en typ av fast längd, som char 100, och de fyller faktiskt inte hela 100 tecknen för varje post. Små vinster kan uppnås genom att ta bort detta extra utrymme från bordet. Naturligtvis, om dina datatabeller inte använder text och numeriska fält med fast längd, eller om de gör det och du faktiskt lagrar det fullt tillåtna antalet tecken och siffror, kommer komprimeringsvinsterna under radnivåschemat att vara minimala i bästa fall.
Konceptet med komprimering utökas till alla datatyper med fast längd, inklusive char, int och float. SQL Server tillåter att spara utrymme genom att lagra data som om det var en typ av variabel storlek; data kommer att visas och bete sig som en fast längd.
Till exempel, om du lagrade värdet 100 i en int kolumnen behöver SQL Server inte använda alla 32 bitar, istället använder den bara 8 bitar (1 byte).
Komprimering på sidnivå tar saker till en annan nivå. För det första tillämpar den automatiskt komprimering på radnivå på datafält med fast längd, så att du automatiskt får dessa vinster som standard. Utöver det tillämpar den något som kallas prefixkomprimering och en annan teknik som kallas ordbokskomprimering.
Radkomprimering
Radkomprimering är en inre nivå av komprimering som lagrar de fasta teckensträngarna genom att använda format med variabel längd genom att inte lagra de tomma tecknen. Följande steg utförs i komprimeringen på radnivå.
- Alla numeriska datatyper som int , flyta , decimal, och pengar konverteras till datatyper med variabel längd. Till exempel är 125 lagrad i kolumn och datatyp för kolumnen ett heltal. Då vet vi att 4 byte används för att lagra heltalsvärdet. Men 125 kan lagras i 1 byte eftersom 1 byte kan lagra värden från 0 till 255. Så 125 kan lagras som en liten int , så att 3 byte kan sparas.
- Tecken och Nchar datatyper lagras som datatyper med variabel längd. Till exempel lagras "SQL" i en char (20) typ kolumn. Men efter komprimering kommer endast 3 byte att använda. Efter datakomprimeringen lagras inget tomt tecken med denna typ av data.
- Metadata för posten reduceras.
- NULL- och 0-värdena är optimerade och inget utrymme förbrukas.
Sidkomprimering
Sidkomprimering är en avancerad nivå av datakomprimering. Som standard implementerar en sidkomprimering också komprimeringen på radnivå. Sidkomprimering delas in i två typer
- Prefixkomprimering och
- Ordbokskomprimering.
Prefixkomprimering
Vid prefixkomprimering för varje sida, för varje kolumn på sidan, hämtas ett gemensamt värde från alla rader och lagras under rubriken i varje kolumn. Nu på varje rad lagras en referens till det värdet istället för det vanliga värdet.
Ordbokskomprimering
Ordbokskomprimering liknar prefixkomprimering men vanliga värden hämtas från alla kolumner och lagras i den andra raden efter rubriken. Ordbokskomprimering letar efter exakta värdematchningar i alla kolumner och rader på varje sida.
Vi kan utföra rad- och sidnivåkomprimering för följande databasobjekt.
- En tabell lagrad i en hög.
- En hel tabell lagrad som ett klustrat index.
- Indexerad vy.
- Icke-klustrade index.
- Partitionerade index och tabeller.
Obs! Vi kan utföra datakomprimering antingen vid tidpunkten för skapandet som CREATE TABLE, CREATE INDEX eller efter skapandet med ALTER-kommandot med REBUILD-alternativet som ALTER TABLE …. BYGGA OM MED.
Demo
WideWorldImporters databasen används genom hela demon. Dessutom en DW i realtid databas övervägs för komprimeringsoperationen.
Låt oss gå igenom stegen i detalj:
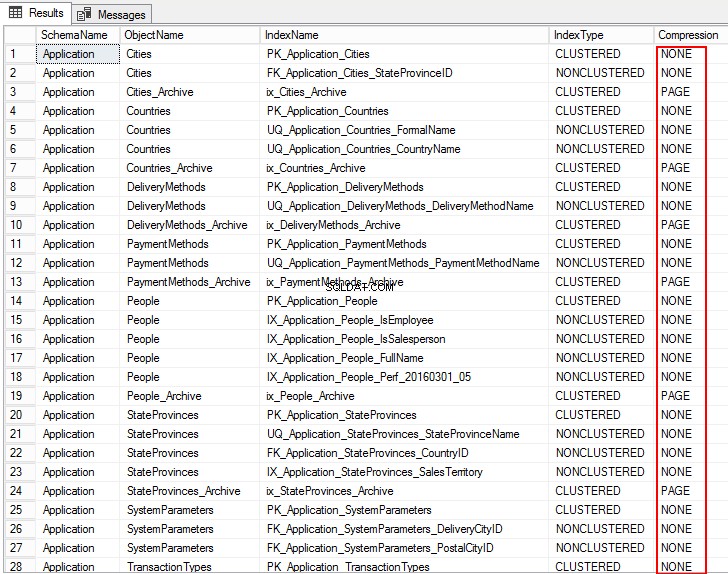
1. För att se komprimeringsinställningar för objekt i databasen, kör följande T-SQL:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' ORDER BY S.name, O.name, I.index_id; GO
Följande utdata visar komprimeringstypen som PAGE, ROW, och för flera tabeller är det INGEN. Det betyder att den inte är konfigurerad för komprimering.
2. För att uppskatta komprimering, kör följande systemlagrade procedur sp_estimate_data_compression_savings . I detta fall exekveras den lagrade proceduren på PurchaseOrderLines-tabellerna.
3. Låt oss ta reda på PurchaseOrderLines-komprimeringsinställningen genom att köra följande T-SQL:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' and o.name ='PurchaseOrderLines' ORDER BY S.name, O.name, I.index_id;
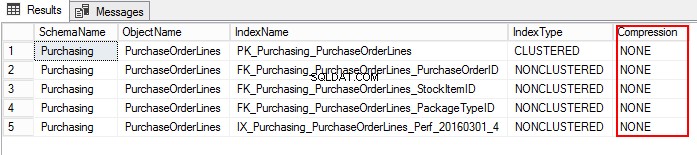
EXEC sp_estimate_data_compression_savings @schema_name = 'Purchasing', @object_name = 'PurchaseOrderLines', @index_id = NULL, @partition_number = NULL, @data_compression = 'Page'; GO

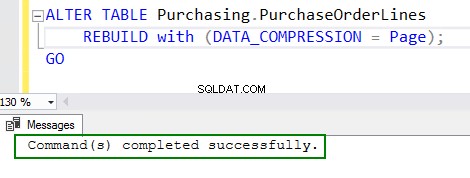
4. Aktivera komprimering genom att köra ALTER-tabellkommandot:
ALTER TABLE Purchasing.PurchaseOrderLines REBUILD with (DATA_COMPRESSION = Page); GO
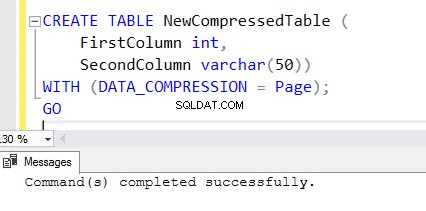
5. För att skapa en ny tabell med den komprimeringsaktiverade funktionen, lägg till WITH-satsen i slutet av CREATE TABLE-satsen. Du kan se nedanstående CREATE TABLE-sats som används för att skapa NewCompressedTable .
CREATE TABLE NewCompressedTable (
FirstColumn int,
SecondColumn varchar(50))
WITH (DATA_COMPRESSION = Page);
GO
Fakta om datakomprimering
Låt oss gå igenom lite av den faktiska informationen om komprimering
- Komprimering kan inte tillämpas på systemtabeller
- En tabell kan inte aktiveras för komprimering när radstorleken överstiger 8060 byte.
- Komprimerad data cachelagras i buffertpoolen; det innebär snabbare svarstider
- Att aktivera komprimering kan göra att frågeplanerna ändras eftersom data lagras med olika antal sidor och antal rader per sida.
- Icke-klustrade index ärver inte komprimeringsegenskapen
- När ett klustrat index skapas på en heap, ärver det klustrade indexet komprimeringstillståndet för högen om inte ett alternativt komprimeringstillstånd anges.
- ROW- och PAGE-nivåkompressionerna kan aktiveras och inaktiveras, offline eller online.
- Om heapinställningen ändras, ska alla icke-klustrade index byggas om.
- Diskutrymmeskraven för att aktivera eller inaktivera rad- eller sidkomprimering är desamma som för att skapa eller bygga om ett index.
- När partitioner delas med användning av ALTER PARTITION-satsen, ärver båda partitionerna datakomprimeringsattributet för den ursprungliga partitionen.
- När två partitioner slås samman, ärver den resulterande partitionen datakomprimeringsattributet för målpartitionen.
- För att byta en partition måste partitionens datakomprimeringsegenskap matcha tabellens komprimeringsegenskap.
- Columnstore-tabeller och index lagras alltid med Columnstore-komprimeringen.
- Datakomprimering är inkompatibelt med glesa kolumner så tabellen kan inte komprimeras.
Realtidsscenario
Låt oss gå igenom datakomprimeringstekniken och förstå nyckelparametrarna för datakomprimering.
För att kontrollera utrymmet som används av varje tabell, kör följande T-SQL. Utdata från frågan ger oss detaljerad information om användningen av varje tabell. Detta skulle vara den avgörande faktorn för implementeringen av datakomprimeringen.
SELECT
t.NAME AS TableName,
i.name as indexName,
sum(p.rows) as RowCounts,
sum(a.total_pages) as TotalPages,
sum(a.used_pages) as UsedPages,
sum(a.data_pages) as DataPages,
(sum(a.total_pages) * 8) / 1024 as TotalSpaceMB,
(sum(a.used_pages) * 8) / 1024 as UsedSpaceMB,
(sum(a.data_pages) * 8) / 1024 as DataSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
WHERE
t.NAME NOT LIKE 'dt%' AND
i.OBJECT_ID > 255 AND
i.index_id <= 1
GROUP BY
t.NAME, i.object_id, i.index_id, i.name
ORDER BY
TotalSpaceMB desc
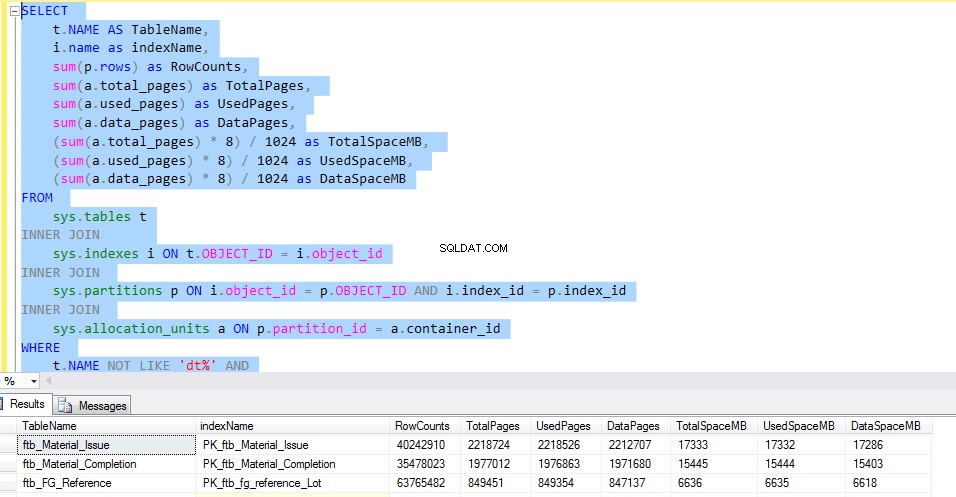
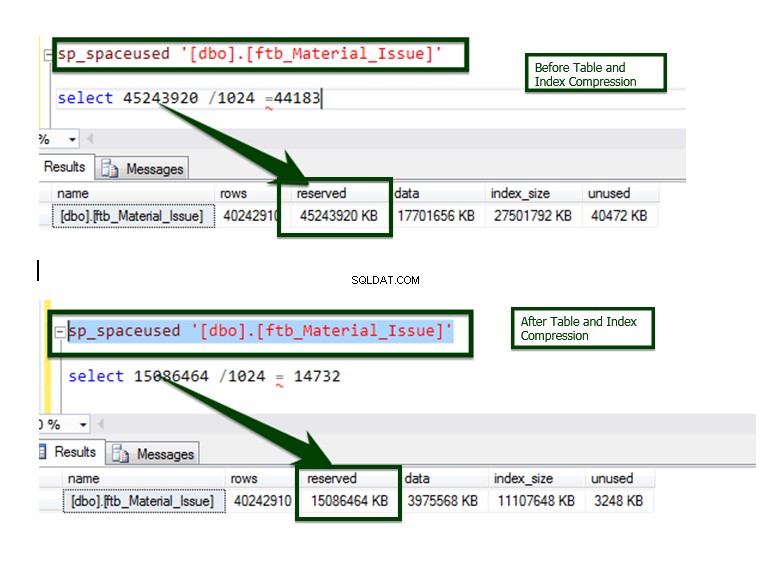
Låt oss överväga ftb_material_Issue faktatabell. Faktatabellen har numeriska BIGINT-datatyper.
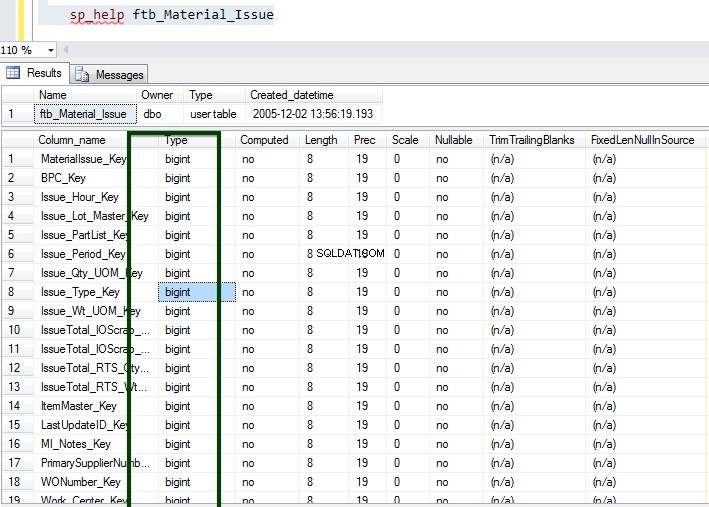
Kör nu den lagrade proceduren sp_spaceused för att förstå detaljerna i tabellen. Du kan lära dig mer om kommandot sp_spaceused här.
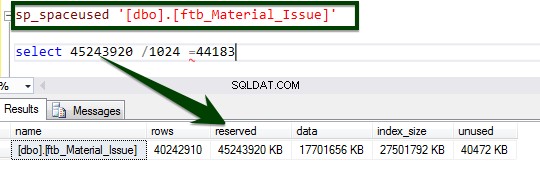
Aktivera komprimeringen på tabellnivå genom att köra följande T-SQL. Följande T-SQL kördes på servern och det tog 34 minuter och 14 sekunder att komprimera sidan på tabellnivå.
ALTER TABLE dbo.ftb_material_Issue REBUILD with (DATA_COMPRESSION = Page);
Du kan se CPU- och I/O-fluktuationer under exekveringen av ALTER-tabellkommandot.
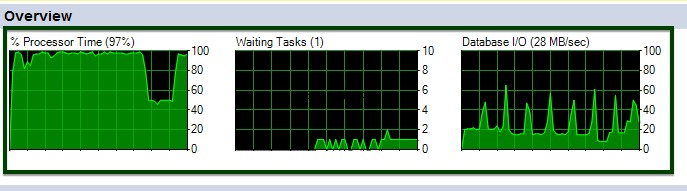
Låt oss nu göra jämförelsen före v/s efter datakomprimering. Bordsstorleken cirka ~45 GB har sänkts till ~15 GB.
Processen implementeras på de flesta av objekten med hjälp av ett automatiserat skript och här är det slutliga resultatet av jämförelsen.
Datajämförelse mellan före och efter indexkomprimeringsoperationen.

Sammanfattning
Datakomprimering är en mycket effektiv teknik för att minska storleken på data; minskad data kräver mindre I/O-processer. Att lägga till komprimering till databasen ökar belastningen på CPU-kraven. Du måste se till att du har tillgänglig bearbetningskapacitet för att hantera dessa ändringar på ett effektivt sätt. Så det är bättre att göra lite forskning först och se vilka typer av vinster som kan förväntas innan du tillämpar ändringarna för att möjliggöra datakomprimering. Det är mycket fördelaktigt i molndatabasinstallationen där kostnaden är inblandad.
Iscensätt kompressionerna (gör inte alla på en gång) och komprimera under perioder med låg aktivitet. Datakomprimering och säkerhetskopieringskomprimering existerar bra samtidigt och kan resultera i ytterligare lagringsutrymmesbesparingar, så varsågod och njut av det.
Komprimeringen minskar inte bara de fysiska filstorlekarna, utan den minskar också disk I/O, vilket kan förbättra prestandan avsevärt för många databasapplikationer, tillsammans med säkerhetskopior av databaser.
Att bestämma sig för att implementera komprimering är lättare om vi känner till den underliggande infrastrukturen och affärskraven. Vi kan definitivt använda den tillgängliga systemproceduren för att förstå och uppskatta kompressionsbesparingar. Denna lagrade procedur ger inte några sådana detaljer som berättar hur komprimeringen kommer att påverka ditt system positivt eller negativt. Det är uppenbart att det finns kompromisser med någon form av komprimering. Om du har samma mönster av enorma data, är komprimering nyckeln till att spara utrymme. Med processorkraften växande och varje system bundet till strukturer med flera kärnor, kan komprimering passa för många system. Jag skulle rekommendera att testa dina system. Testa för att säkerställa att prestandan inte påverkas negativt. Om ett index har många uppdateringar och raderingar kan CPU-kostnaden för att komprimera och dekomprimera data uppväga I/O- och RAM-besparingarna från datakomprimering. Inte varje databas eller tabell kommer automatiskt att vara en bra kandidat att tillämpa komprimering på, så det är bäst att göra lite forskning först för att se vilka typer av vinster som kan förväntas innan du tillämpar ändringarna för att möjliggöra datakomprimering på dina databaser. Du måste testa komprimeringen för att se om den fungerar bra i din miljö, eftersom den kanske inte fungerar bra i databaser med tunga insättningar.
Referenser
Utgåvor och funktioner som stöds av SQL Server 2016
Datakomprimering
Implementering av radkomprimering
Implementering av sidkomprimering