Enligt Wikipedia är "En bulkinsert en process eller metod som tillhandahålls av ett databashanteringssystem för att ladda flera rader med data till en databastabell." Om vi justerar denna förklaring i enlighet med BULK INSERT-satsen, tillåter bulk-insert import av externa datafiler till SQL Server. Antag att vår organisation har en CSV-fil med 1 500 000 rader och vi vill importera den här filen till en viss tabell i SQL Server, så att vi enkelt kan använda BULK INSERT-satsen i SQL Server. Visst kan vi hitta flera importmetoder för att hantera denna CSV-filimportprocess, t.ex. vi kan använda bcp (b ulk c opy p rogram), SQL Server Import och Export Wizard eller SQL Server Integration Service-paket. Men BULK INSERT-satsen är mycket snabbare och robust än att använda andra metoder. En annan fördel med bulkinsert-satsen är att den erbjuder flera parametrar som hjälper till att bestämma inställningarna för bulk-insättningsprocessen.
Till en början kommer vi att starta ett mycket grundläggande prov och sedan går vi igenom olika sofistikerade scenarier.
Förberedelser
Innan vi startar proverna behöver vi en exempel-CSV-fil. Därför kommer vi att ladda ner en exempel-CSV-fil från E for Excel-webbplatsen, där du kan hitta olika exempel på CSV-filer med ett annat radnummer. Du hittar länken i slutet av artikeln. I våra scenarier kommer vi att använda 1 500 000 försäljningsposter. Ladda ner en zip-fil och packa upp CSV-filen och placera den på din lokala enhet.

Importera CSV-fil till SQL Server-tabellen
Scenario-1:Destination och CSV-fil har lika många kolumner
I detta första scenario kommer vi att importera CSV-filen till destinationstabellen i den enklaste formen. Jag placerade min exempel-CSV-fil på C:-enheten och nu kommer vi att skapa en tabell som vi importerar data från CSV-filen.
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
Följande BULK INSERT-sats importerar CSV-filen till försäljningstabellen.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
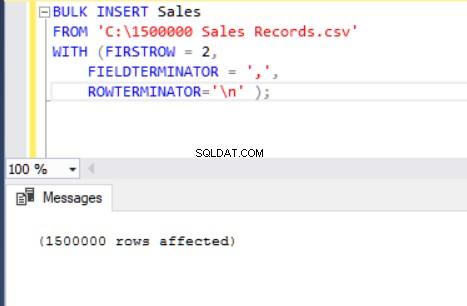
Nu kommer vi att förklara parametrarna för ovanstående bulkinsert-sats.
FIRSTROW-parametern anger startpunkten för insert-satsen. I exemplet nedan vill vi hoppa över kolumnrubriker så vi ställer in den här parametern till 2.

FIELDTERMINATOR definierar tecknet som skiljer fält från varandra. SQL Server upptäcker varje fält på ett sådant sätt. ROWTERMINATOR skiljer sig inte mycket från FIELDTERMINATOR. Det definierar separationskaraktären för rader. I exempel-CSV-filen är fieldterminator mycket tydlig och det är ett kommatecken (,). Men hur kan vi upptäcka en fältterminator? Öppna CSV-filen i Notepad++ och navigera sedan till Visa->Visa symbol->Visa alla charter, och ta reda på CRLF-tecken i slutet av varje fält.
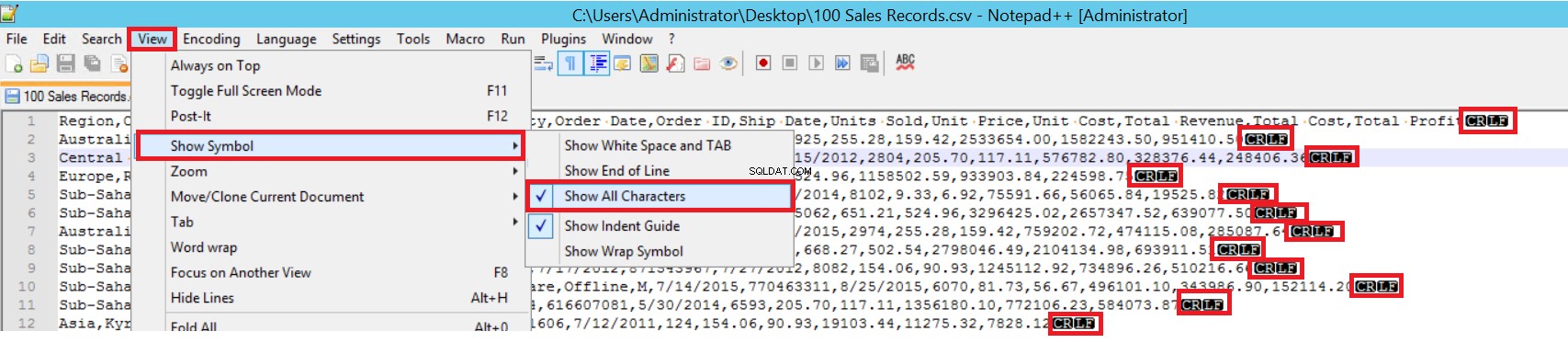
CR =Carriage Return och LF =Linjematning. De används för att markera en radbrytning i en textfil och det indikeras av tecknet "\n" i bulk infogningssatsen.
En annan metod för att importera en CSV-fil till en tabell med hjälp av bulkinfogning är att använda parametern FORMAT. Observera att FORMAT-parametern endast är tillgänglig i SQL Server 2017 och senare versioner.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
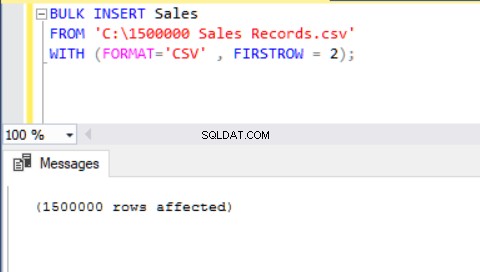
Nu ska vi analysera ett annat scenario.
Scenario-2:Måltabellen har fler kolumner än CSV-filen
I det här scenariot lägger vi till en primärnyckel i tabellen Försäljning och det här fallet bryter mappningarna för likhetskolumnen. Nu kommer vi att skapa försäljningstabellen med en primärnyckel, försöka importera CSV-filen genom kommandot bulk insert och sedan får vi ett felmeddelande.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
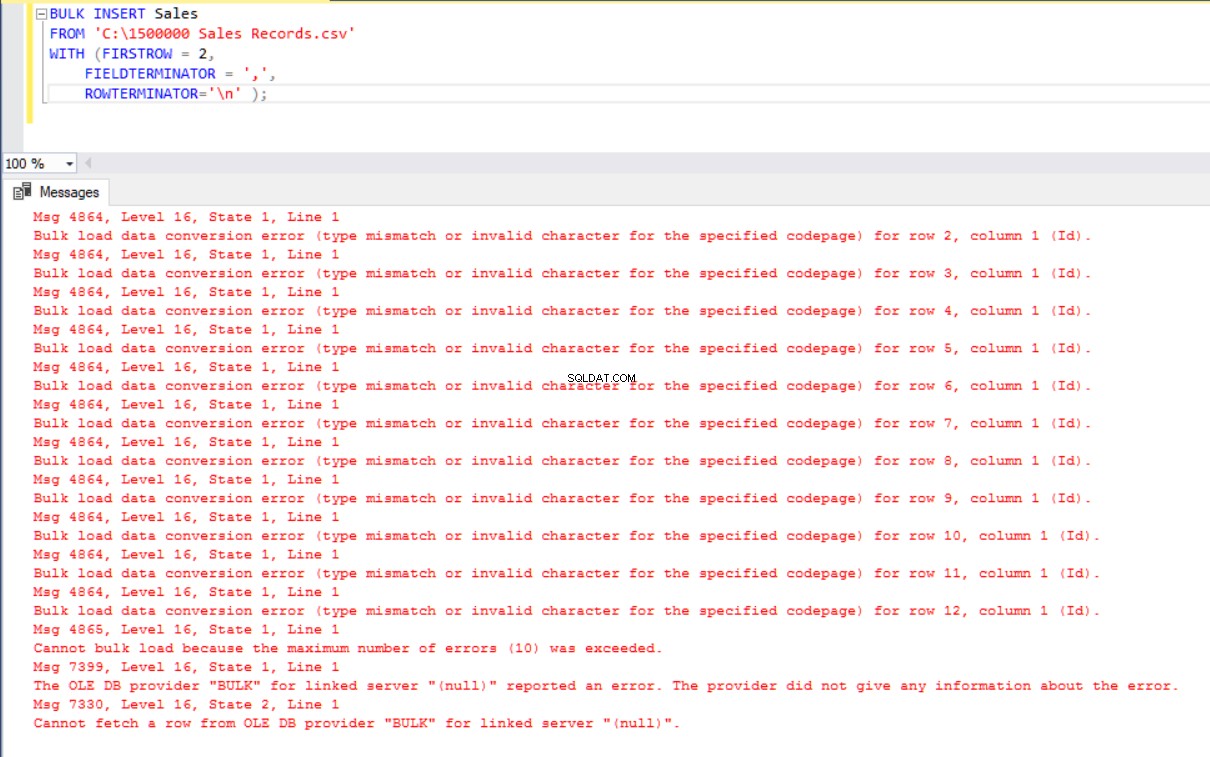
För att övervinna detta fel kommer vi att skapa en vy av försäljningstabellen med mappningskolumner till CSV-filen och importera CSV-data över denna vy till tabellen Försäljning.
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Scenario-3:Hur separerar man och laddar CSV-filen i liten batchstorlek?
SQL Server skaffar en lås till destinationstabell under massinsättningsoperationen. Som standard, om du inte ställer in parametern BATCHSIZE, öppnar SQL Server en transaktion och infogar hela CSV-data i denna transaktion. Men om du ställer in parametern BATCHSIZE delar SQL Server upp CSV-data enligt detta parametervärde. I följande exempel kommer vi att dela upp hela CSV-data i flera uppsättningar med 300 000 rader vardera. Således kommer data att importeras vid 5 gånger.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 );
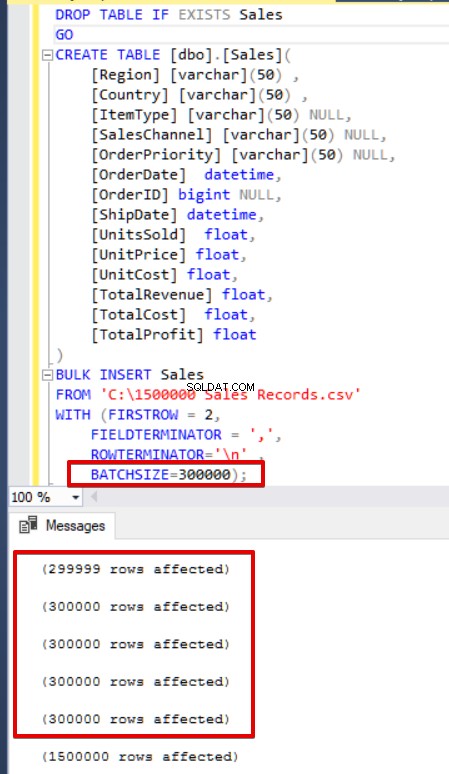
Om din bulkinsert-sats inte innehåller parametern batch size (BATCHSIZE), kommer ett fel att uppstå och SQL Server återställer hela bulk-insättningsprocessen. Å andra sidan, om du ställer in batchstorleksparametern till bulk insert-sats, återställer SQL Server endast denna delade del där felet uppstod. Det finns inget optimalt eller bästa värde för denna parameter eftersom detta parametervärde kan ändras enligt dina databassystemkrav.
Scenario-4:Hur man avbryter importprocessen när ett felmeddelande visas?
I vissa scenarier för masskopiering, om ett fel uppstår, kanske vi vill antingen avbryta masskopieringsprocessen eller fortsätta processen. Parametern MAXERRORS tillåter oss att ange det maximala antalet fel. Om massinsättningsprocessen når detta maximala felvärde kommer massimporten att avbrytas och återställas. Standardvärdet för denna parameter är 10.
I följande exempel kommer vi avsiktligt att korrumpera datatypen i 3 rader i CSV-filen och ställa in parametern MAXERRORS till 2. Som ett resultat avbryts hela bulkinfogningen eftersom felnumret överskrider parametern max fel.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2);
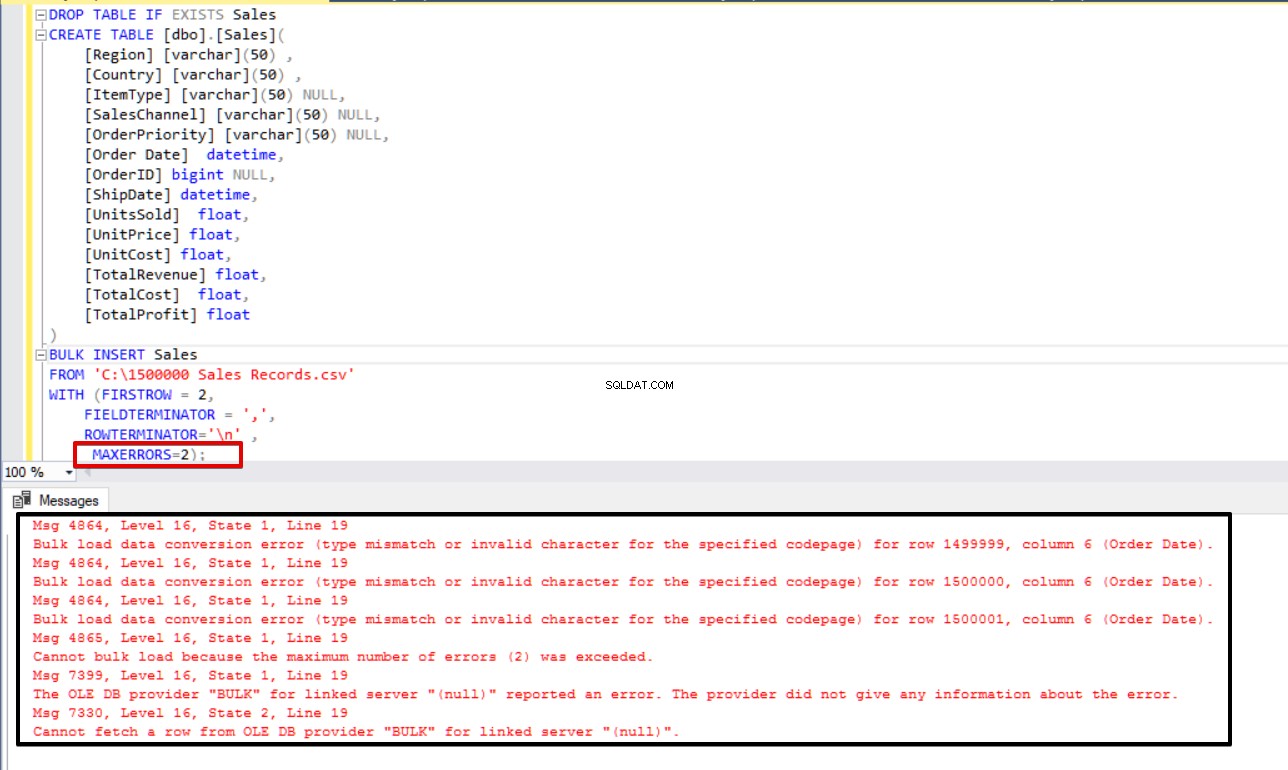
Nu kommer vi att ändra parametern max error till 4. Som ett resultat kommer bulk insert-satsen att hoppa över dessa rader och infoga korrekta datastrukturerade rader och slutföra massinsättningsprocessen.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
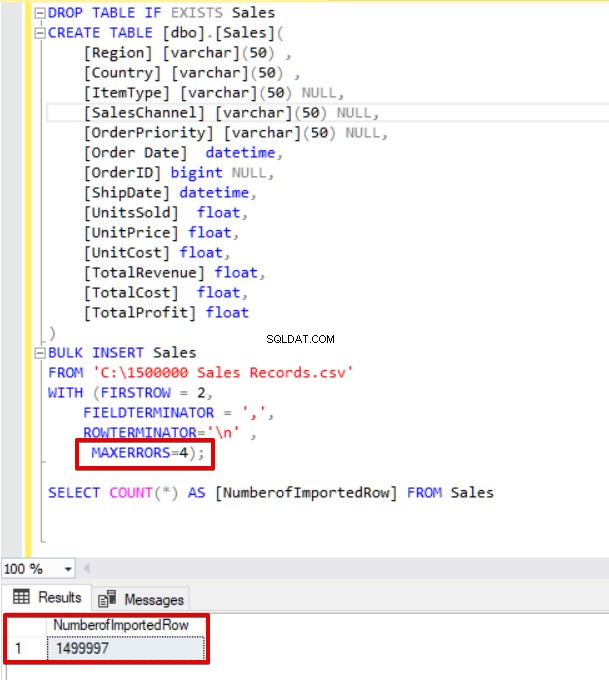
Dessutom, om vi använder båda parametrarna för batchstorlek och maximala fel samtidigt, kommer masskopieringsprocessen inte att avbryta hela infogningsoperationen, den avbryter bara den delade delen.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
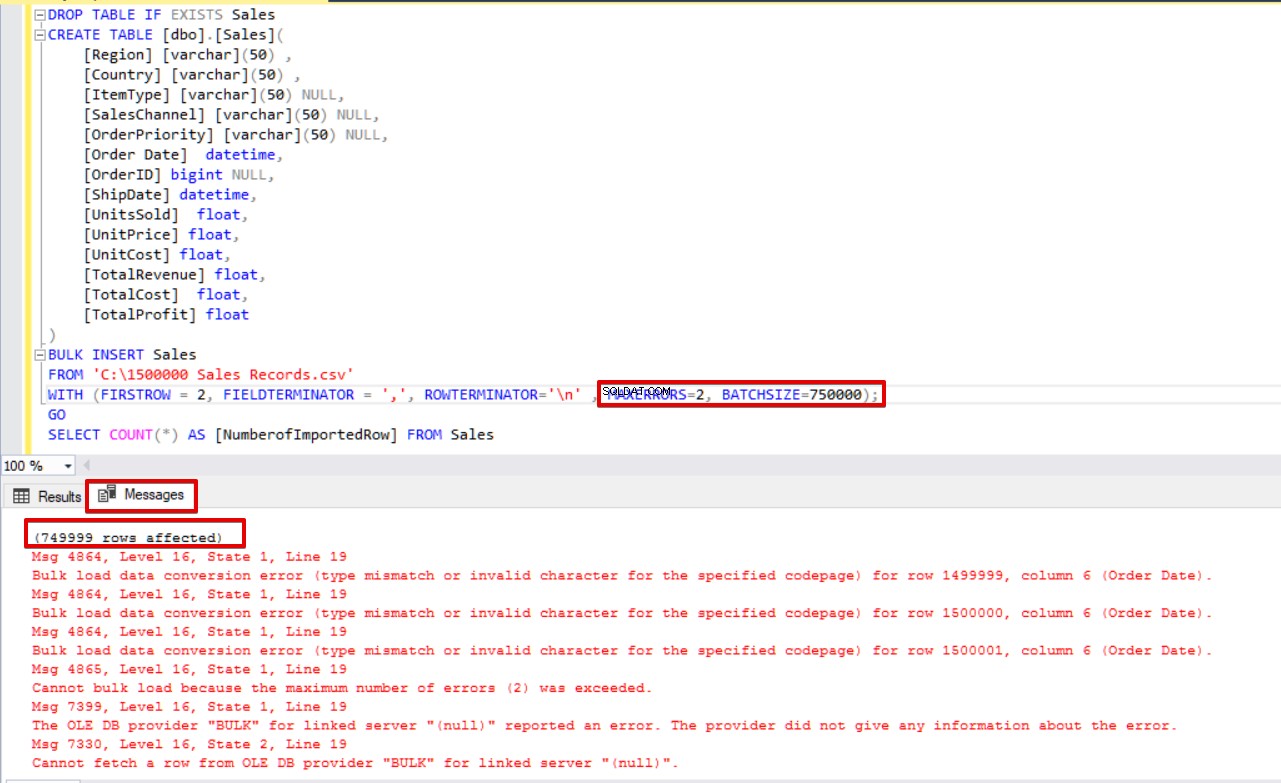
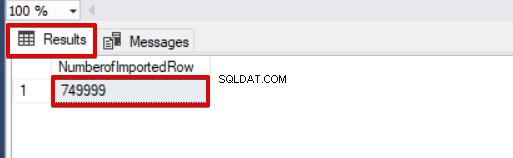
I den här första delen av den här artikelserien diskuterade vi grunderna för att använda bulkinsert-operationen i SQL Server och analyserade flera scenarier som ligger nära de verkliga problemen.
SQL Server Bulk Insert – Del 2
Användbara länkar:
Bulkinsats
E för Excel – Exempel på CSV-filer/Datauppsättningar för testning (till 1,5 miljoner poster)
Ladda ner Notepad++
Användbart verktyg:
dbForge Data Pump – ett SSMS-tillägg för att fylla SQL-databaser med externa källdata och migrera data mellan system.