Tja, att analysera spridningen av SARS-CoV-2-coronaviruset var inte mitt drömanvändningsfall . Men baserat på svaren på Ferry Djajas spårning av Coronavirus COVID-19 nära realtid med SAP HANA XSA-artikeln bestämde jag mig för att lägga till mina två grossiga också.
[Uppdaterad 20-03-30 med de ändrade länkarna till källdata; och den nya kartutgången baserad på den nya datagranulariteten. Tack Douglas Maltby för din kommentar!]
I sitt blogginlägg använde Ferry JavaScript i SAP HANA XSA för att hämta data från CSV-filer som uppdateras dagligen av Johns Hopkins University.
Jag skulle vilja visa dig hur du kan dra och ladda dessa filer till SAP HANA med bara några rader kod tack vare SAP HANA Python Client API for Machine Learning (hana_ml paket).
En del människor var förvirrade med visualiseringen på kartan i slutet — observera att den här artikeln fokuserar på tekniska användningsfall som kopplar samman olika komponenter, inte på att göra djupanalys av coronavirusdata.
Hämta Python-miljö, t.ex. Jupyter
Jag kommer att använda Jupyter i Docker-behållaren för det. Ta en titt på mitt tidigare inlägg Förstå behållare (del 05):delade filer mellan värden och behållare om du inte är bekant med hur man startar det. Du kan också göra samma steg nedan från vilken annan Python-miljö som helst.
Så jag har min behållare myjupyter01 löpning. Jag är ansluten till Jupyter UI enligt beskrivningen i föregående blogg.
Installera hana_ml
Jupyter-bilden jag använde från Docker Hub-registret var jupyter/minimal-notebook . Den innehåller redan några populära databehandlingspaket, som pandas .
Men dessutom måste jag installera hana_ml , som – i sin nuvarande version 1.0.8 – är tillgänglig på PyPI-förrådet:https://pypi.org/project/hana-ml/.
Kommandot för att köra installationen är python -m pip install hana_ml , men eftersom jag kör det från Jupyter notebook med Python3-kärnan måste jag köra det med ! i början:
!python -m pip install hana_ml
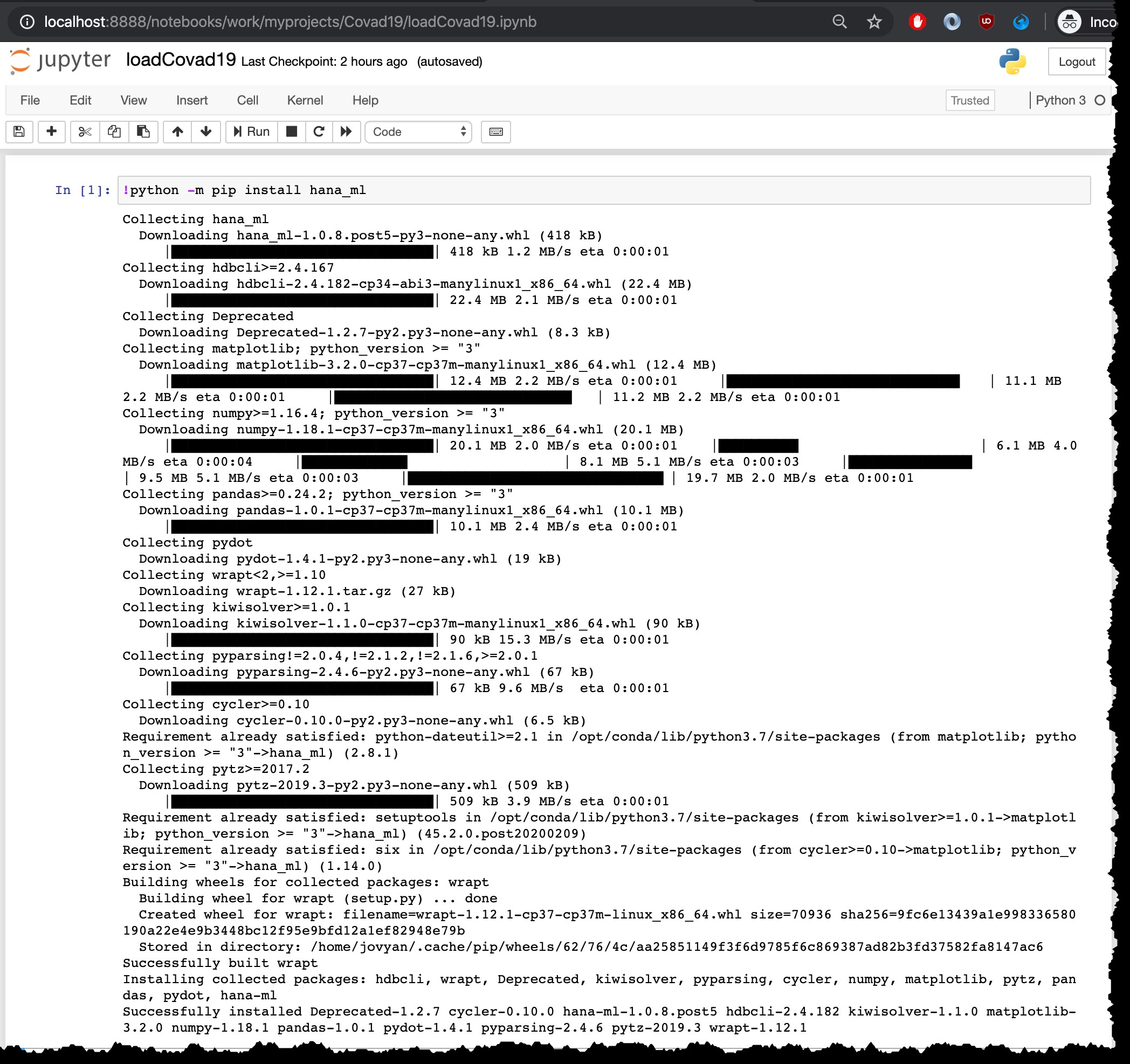
Självklart måste detta installationssteg endast göras en gång. Du behöver inte köra den igen i samma behållare t.ex. när du laddar om de senaste filerna.
Använd pandas för att importera filer med data
Låt oss importera samma tre filer (confirmed , deaths , recovered ) från https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_time_series som Ferry använde i sitt exempel.
import hana_ml, pandas
# Links updated on 2020-03-22
df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv')
df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_global.csv')
df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_recovered_global.csv')
#Links from before March 22nd
#df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Confirmed.csv')
#df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Deaths.csv')
#df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Recovered.csv')
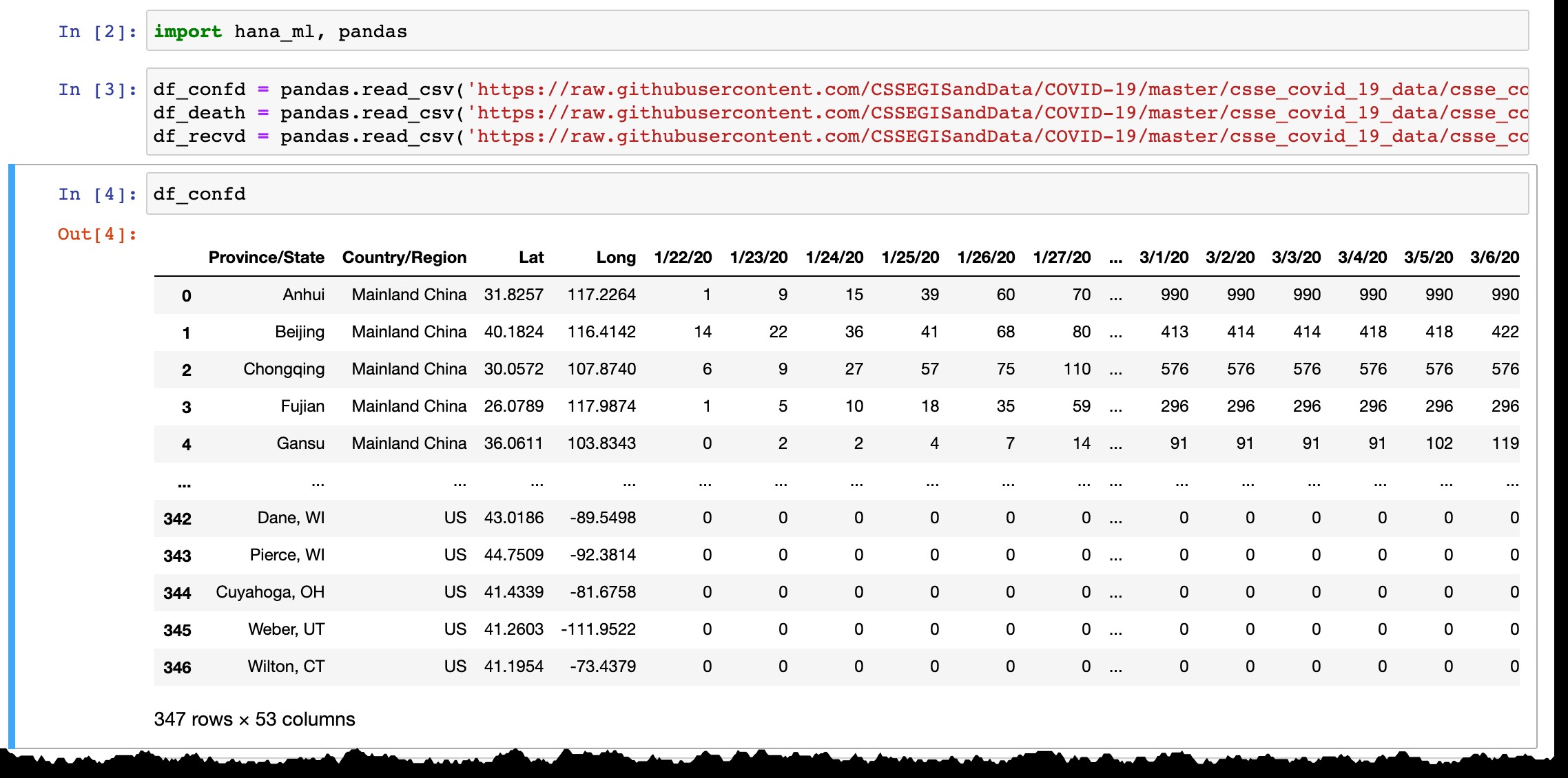
Som du kan se från förhandsvisningen av Pandas dataram, listar den bara länder eller provinser med bekräftade fall, och varje dag läggs den nya kolumnen till med de senaste uppgifterna från föregående dag. Rader läggs till när de första fallen bekräftas i den nya regionen.
Använd pandas för att formatera om dataramen
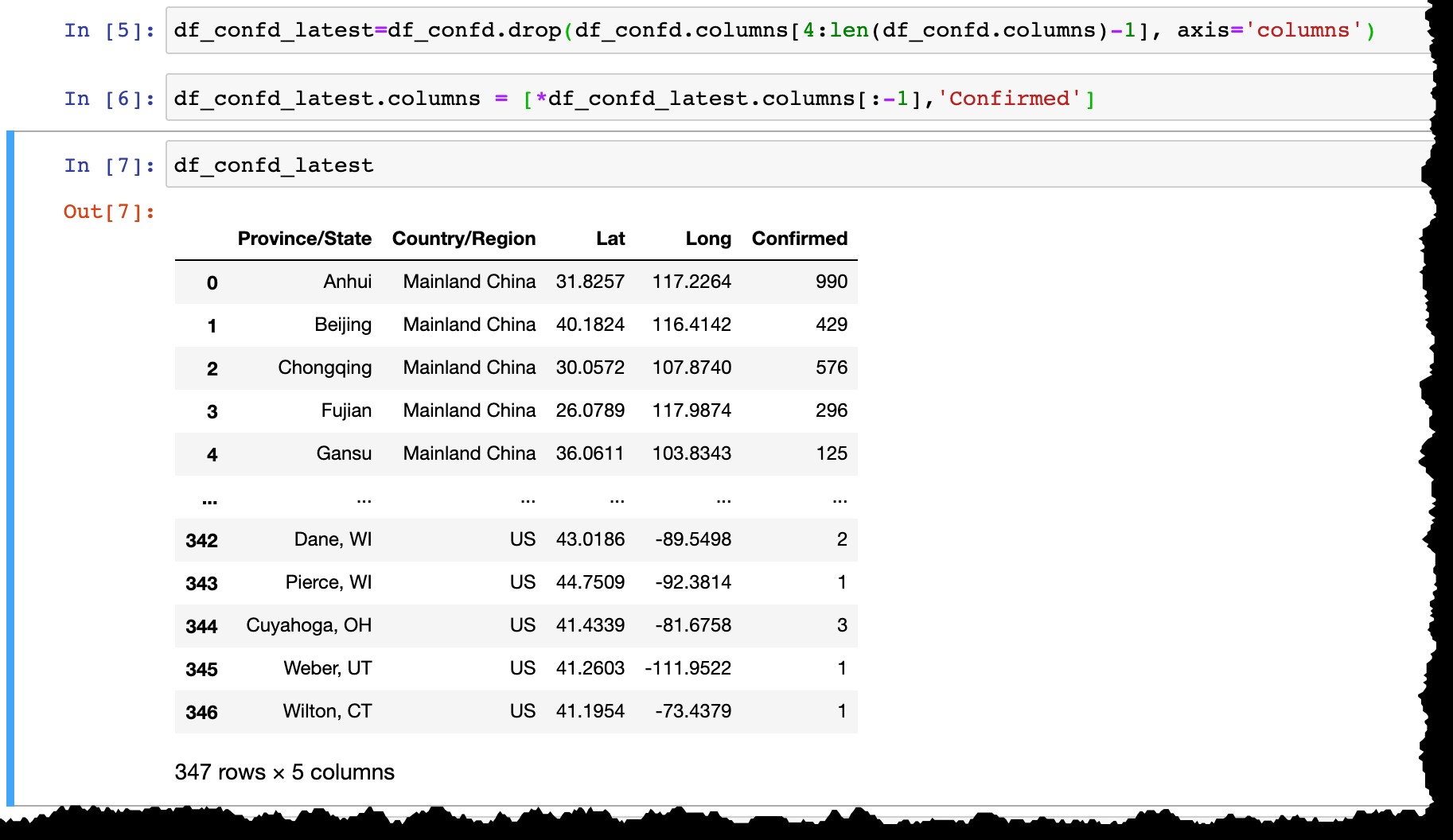
Innan vi behåller data i SAP HANA, låt oss:
- Ta bort alla datumkolumner utom den sista,
- Byt namn på den sista kolumnen från det faktiska datumet (som dagens
3/10/20tillConfirmed).
df_confd_latest=df_confd.drop(df_confd.columns[4:len(df_confd.columns)-1], axis='columns')
df_confd_latest.columns = [*df_confd_latest.columns[:-1],'Confirmed']
Använd hana_ml för att bevara data i SAP HANA-tabellen
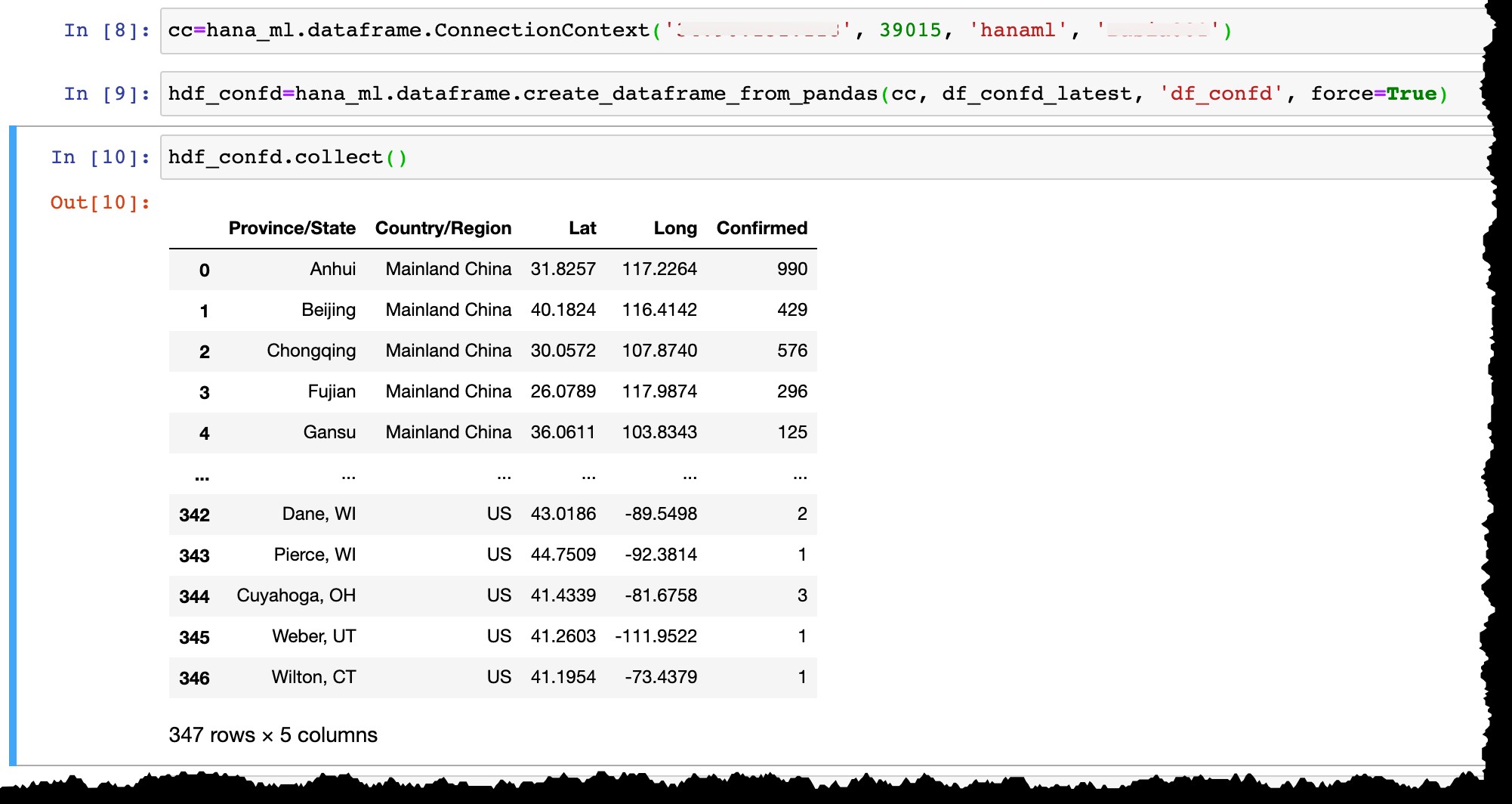
Låt mig nu ansluta till min instans av SAP HANA Express med användaren hanaml som redan finns där...
cc=hana_ml.dataframe.ConnectionContext('12.34.567.890', 39015, 'hanaml', 'MyPasswordReusedEverywhere')
…och konvertera Pandas dataram df_confd_latest in i en HANA-dataram hdf_confd .
hdf_confd=hana_ml.dataframe.create_dataframe_from_pandas(cc, df_confd_latest, 'df_confd', force=True)
När HANA-dataramen har skapats:
- En fysisk kolumntabell skapas i HANA och data från Pandas dataram infogas där,
- HANA-dataram
hdf_confdi Python lagrar ingen data i din bärbara dator, utan pekar bara på en tabellHANAML.df_confdi SAP HANA-serverminnet, och alla Python-operationer på HANA-dataramen exekeras fysiskt i HANA db utan att flytta data mellan servern och en klient, - För att visa resultatet av eventuella operationer måste vi använda
collect()metod för att konvertera HANA-dataram till Pandas (och som ett resultat för att överföra data från HANA db-servern till den lokala klienten).
Använd DBeaver för att kontrollera data i SAP HANA...
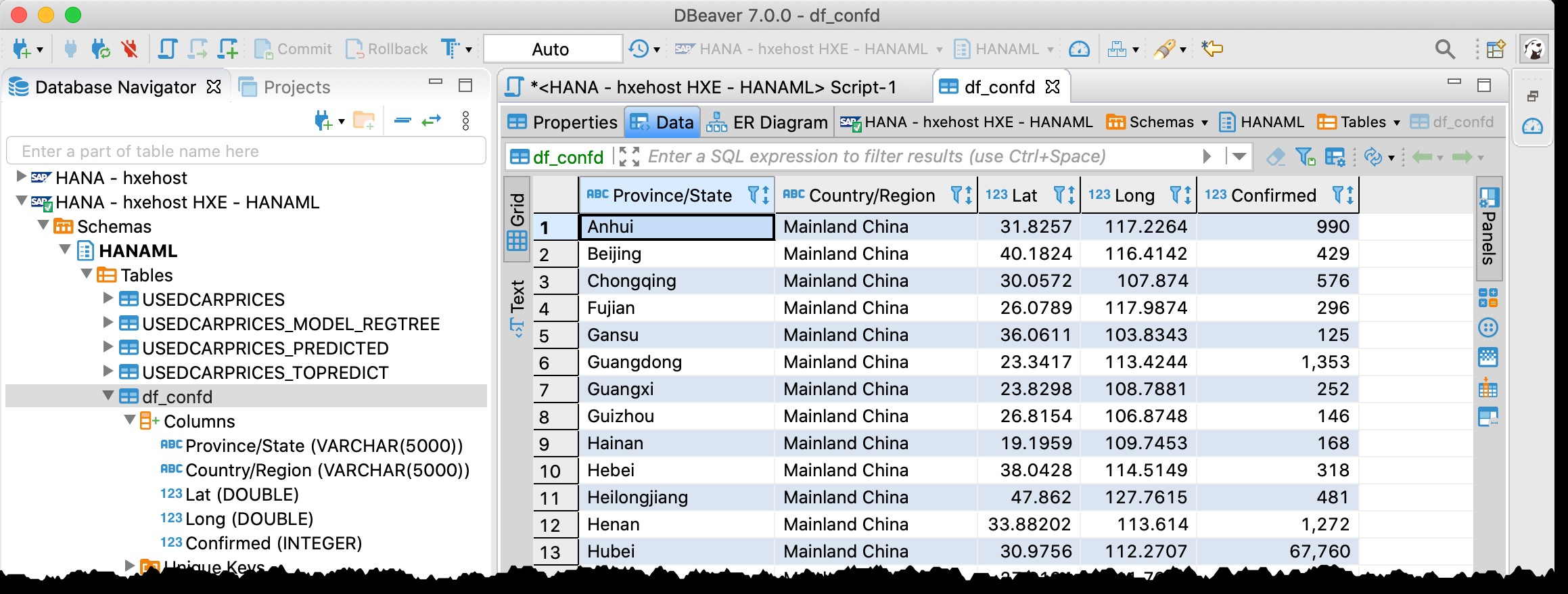
Du kanske minns att jag redan använder DBeaver – det kostnadsfria databasverktyget som stöder SAP HANA – i mitt tidigare inlägg "GeoArt med SAP HANA och DBeaver".
Jag använder det nu igen, och jag kan faktiskt hitta tabellen df_confd i schemat HANAML med all data från Pandas källdataram.
...och gör en rumslig förhandsgranskning
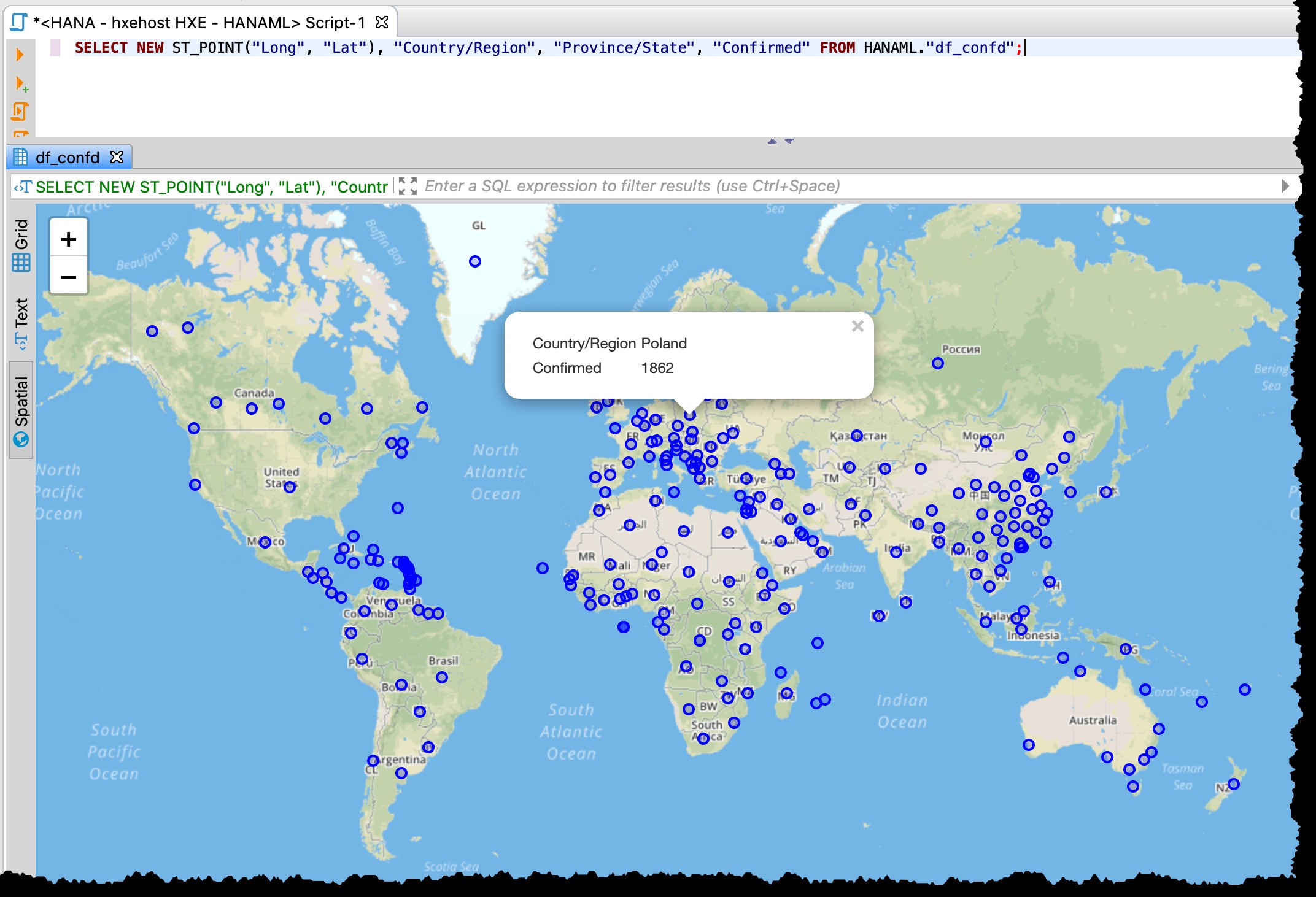
Eftersom tabellen innehåller latitud- och longitudkolumner kan jag visualisera påverkade länder/stater direkt från DBeaver med följande SQL med hjälp av förhandsgranskning av rumslig data.
SELECT NEW ST_POINT("Long", "Lat"), "Country/Region", "Province/State", "Confirmed" FROM HANAML."df_confd";
Jag behövde ändra kartprojektionen till EPSG:4326 för att få dessa punkter på kartan. Och DBeaver visar mig resten av postdata när jag klickar på någon punkt.
[Nedan är den gamla skärmdumpen från 2020-03-11, som också visar den olika granulariteten hos t.ex. USA-data som användes vid den tiden]
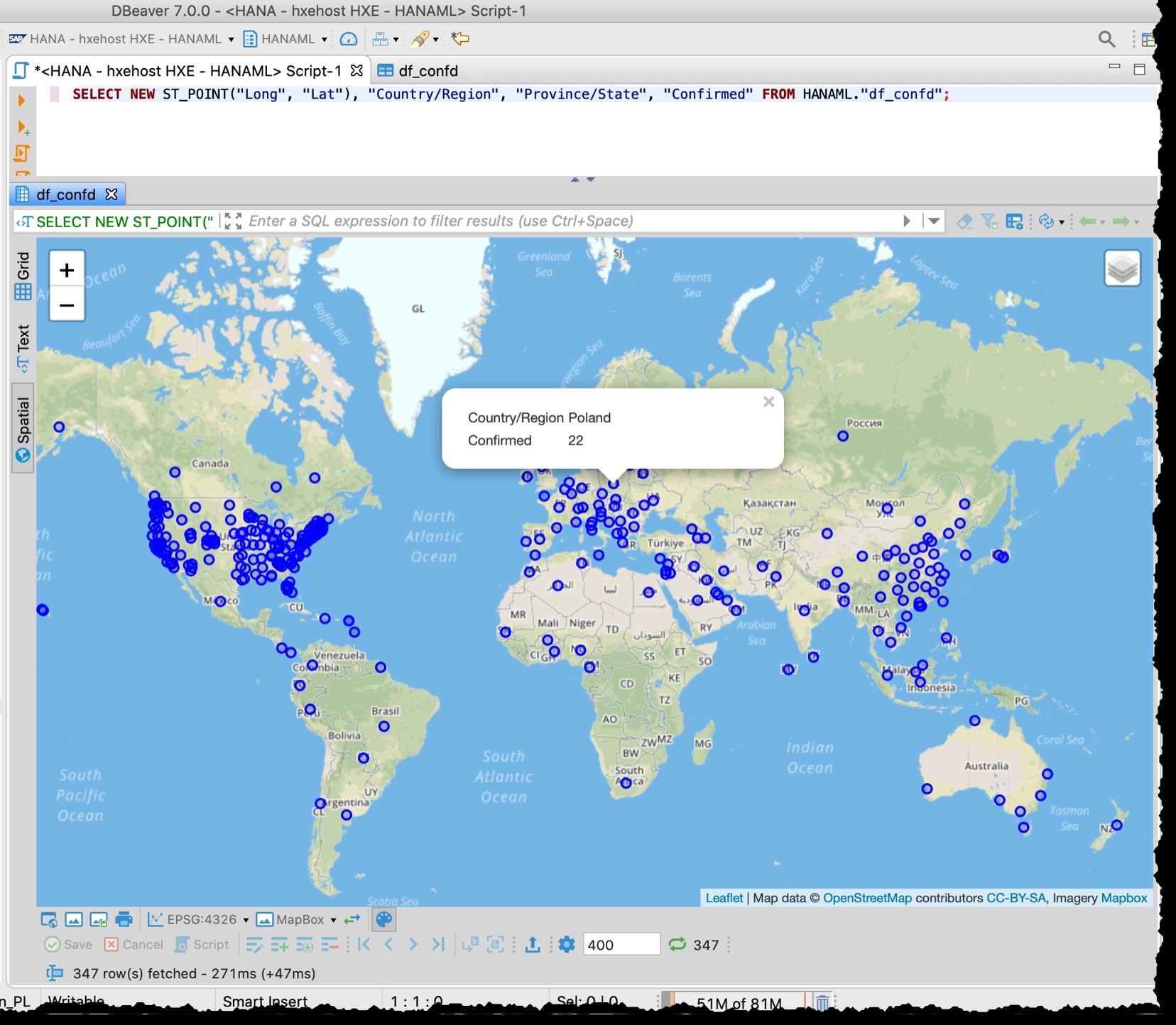
DBeaver spatial preview är inte ett komplett geospatialt visuellt utforskningsverktyg. Ändå är det tillräckligt bra för att se berörda länder/regioner (beroende på granulariteten i källfilerna).
Om du skulle vara intresserad av att lära dig mer om hana_ml …
… då skulle jag definitivt rekommendera att kolla Hands-On Tutorial:Machine Learning push-down till SAP HANA med Python av Andreas Forster.
HANA ML är en del av det nya "Advanced Analytics with SAP HANA"-ämnet för CodeJam-evenemang. Tyvärr på grund av coronasituationen var vi tvungna att ställa in den första arrangerad av Jakob Flaman i Bern denna månad. En annan arrangeras av Ewelina Pękała den 27 maj i Katowice:https://www.eventbrite.com/e/sap-codejam-katowice-registration-99016299417. Förhoppningsvis blir situationen normal vid den tidpunkten, och vi kommer inte att behöva avbryta denna också.