MongoDB är en NoSQL-databas som stöder en mängd olika indatadatakällor. Den kan lagra data i flexibla JSON-liknande dokument, vilket innebär att fält eller metadata kan variera från dokument till dokument och datastrukturen kan ändras över tiden. Dokumentmodellen gör datan lätt att arbeta med genom att mappa till objekten i applikationskoden. MongoDB är också känd som en distribuerad databas i sin kärna, så hög tillgänglighet, horisontell skalning och geografisk distribution är inbyggda och lätta att använda. Den kommer med möjligheten att sömlöst modifiera parametrar för modellträning. Dataforskare kan enkelt slå samman struktureringen av data med denna modellgenerering.
Vad är maskininlärning?
Machine Learning är vetenskapen om att få datorerna att lära sig och agera som människor gör och förbättra sin inlärning över tid på ett autonomt sätt. Inlärningsprocessen börjar med observationer eller data, såsom exempel, direkt erfarenhet eller instruktioner, för att leta efter mönster i data och fatta bättre beslut i framtiden baserat på de exempel vi tillhandahåller. Det primära syftet är att låta datorerna lära sig automatiskt utan mänsklig inblandning eller hjälp och justera åtgärderna därefter.
En rik programmerings- och frågemodell
MongoDB erbjuder både inbyggda drivrutiner och certifierade kopplingar för utvecklare och datavetare som bygger maskininlärningsmodeller med data från MongoDB. PyMongo är ett bra bibliotek för att bädda in MongoDB-syntax i Python-kod. Vi kan importera alla funktioner och metoder i MongoDB för att använda dem i vår maskininlärningskod. Det är en utmärkt teknik för att få flerspråkig funktionalitet i en enda kod. Den ytterligare fördelen är att du kan använda de grundläggande funktionerna i dessa programmeringsspråk för att skapa en effektiv applikation.
Frågespråket MongoDB med rika sekundära index gör det möjligt för utvecklare att bygga applikationer som kan fråga och analysera data i flera dimensioner. Data kan nås med enstaka nycklar, intervall, textsökning, grafer och geospatiala frågor genom komplexa sammanställningar och MapReduce-jobb, vilket ger svar på millisekunder.
För att parallellisera databehandling över ett distribuerat databaskluster tillhandahåller MongoDB aggregeringspipeline och MapReduce. MongoDB:s aggregeringspipeline är modellerad enligt konceptet för databehandlingspipelines. Dokument går in i en pipeline i flera steg som omvandlar dokumenten till ett aggregerat resultat med hjälp av inbyggda operationer som körs inom MongoDB. De mest grundläggande pipeline-stegen tillhandahåller filter som fungerar som frågor och dokumenttransformationer som ändrar formen på utdatadokumentet. Andra pipelineoperationer tillhandahåller verktyg för att gruppera och sortera dokument efter specifika fält samt verktyg för att aggregera innehållet i arrayer, inklusive arrays av dokument. Dessutom kan pipseline-steg använda operatörer för uppgifter som att beräkna medelvärde eller standardavvikelser över samlingar av dokument och manipulera strängar. MongoDB tillhandahåller också inbyggda MapReduce-operationer i databasen, med hjälp av anpassade JavaScript-funktioner för att utföra kartan och minska etapper.
Förutom sitt ursprungliga frågeramverk erbjuder MongoDB även en högpresterande anslutning för Apache Spark. Anslutningen exponerar alla Sparks bibliotek, inklusive Python, R, Scala och Java. MongoDB-data materialiseras som DataFrames och Dataset för analys med maskininlärning, grafer, streaming och SQL API:er.
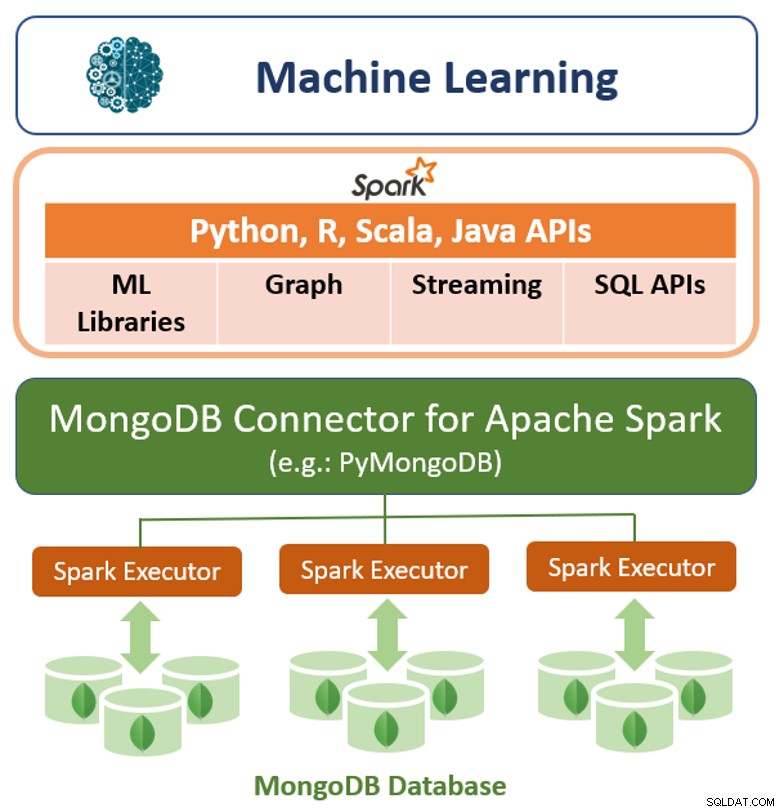
MongoDB Connector för Apache Spark kan dra fördel av MongoDB:s aggregeringspipeline och sekundära index för att extrahera, filtrera och bearbeta endast den mängd data som behövs - till exempel analysera alla kunder som finns i en specifik geografi. Detta skiljer sig mycket från enkla NoSQL-datalager som inte stöder vare sig sekundära index eller aggregering i databasen. I dessa fall skulle Spark behöva extrahera all data baserat på en enkel primärnyckel, även om endast en delmängd av dessa data krävs för Spark-processen. Detta innebär mer bearbetningskostnader, mer hårdvara och längre tid till insikt för datavetare och ingenjörer. För att maximera prestanda över stora, distribuerade datamängder kan MongoDB Connector för Apache Spark samlokalisera Resilient Distributed Dataset (RDDs) med MongoDB-källnoden, och därigenom minimera datarörelsen över klustret och minska latensen.
Prestanda, skalbarhet och redundans
Modelutbildningstiden kan minskas genom att bygga maskininlärningsplattformen ovanpå ett prestanda och skalbart databaslager. MongoDB erbjuder ett antal innovationer för att maximera genomströmningen och minimera fördröjningen av maskininlärningsarbetsbelastningar:
- WiredTiger är känd som standardlagringsmotorn för MongoDB, utvecklad av arkitekterna av Berkeley DB, den mest utbredda programvaran för inbäddad datahantering i världen. WiredTiger skalar på moderna arkitekturer med flera kärnor. Genom att använda en mängd olika programmeringstekniker som riskpekare, låsfria algoritmer, snabb låsning och meddelandeöverföring, maximerar WiredTiger beräkningsarbete per CPU-kärna och klockcykel. För att minimera on-disk overhead och I/O använder WiredTiger kompakta filformat och lagringskomprimering.
- För de mest latenskänsliga maskininlärningsapplikationerna kan MongoDB konfigureras med In-Memory-lagringsmotorn. Baserad på WiredTiger ger denna lagringsmotor användarna fördelarna med in-memory computing, utan att byta bort den rika frågeflexibilitet, realtidsanalys och skalbar kapacitet som erbjuds av konventionella diskbaserade databaser.
- För att parallellisera modellträning och skala indatauppsättningar bortom en enda nod använder MongoDB en teknik som kallas sharding, som distribuerar bearbetning och data över kluster av råvaruhårdvara. MongoDB-sharding är helt elastisk och balanserar automatiskt om data över klustret när indatauppsättningen växer, eller när noder läggs till och tas bort.
- Inom ett MongoDB-kluster distribueras data från varje shard automatiskt till flera repliker som finns på separata noder. MongoDB-replikuppsättningar ger redundans för att återställa träningsdata i händelse av ett misslyckande, vilket minskar kostnaderna för kontroll.
MongoDB:s Tunable Consistency
MongoDB är starkt konsekvent som standard, vilket gör det möjligt för maskininlärningsapplikationer att omedelbart läsa vad som har skrivits till databasen, och på så sätt undviker utvecklarkomplexiteten som påtvingas av så småningom konsistenta system. Stark konsekvens ger de mest exakta resultaten för maskininlärningsalgoritmer; i vissa scenarier är det dock acceptabelt att handla konsistens mot specifika prestationsmål genom att distribuera frågor över ett kluster av MongoDB sekundära replikuppsättningsmedlemmar.
Flexibel datamodell i MongoDB
MongoDB:s dokumentdatamodell gör det enkelt för utvecklare och datavetare att lagra och aggregera data av någon form av struktur inuti databasen, utan att ge upp sofistikerade valideringsregler för att styra datakvaliteten. Schemat kan modifieras dynamiskt utan en applikations- eller databasstopp som är ett resultat av kostsamma schemaändringar eller omdesign som ådras av relationsdatabassystem.
Att spara modeller i en databas och ladda dem med python är också en enkel och mycket krävd metod. Att välja MongoDB är också en fördel eftersom det är en dokumentdatabas med öppen källkod och även en ledande NoSQL-databas. MongoDB fungerar också som en koppling för apache spark-distribuerat ramverk.
MongoDB:s dynamiska natur
MongoDB:s dynamiska natur gör det möjligt att använda den i databasmanipuleringsuppgifter för att utveckla Machine Learning-applikationer. Det är ett mycket effektivt och enkelt sätt att genomföra en analys av datamängder och databaser. Resultatet av analysen kan användas för att träna maskininlärningsmodeller. Det har rekommenderats att dataanalytiker och maskininlärningsprogrammerare ska behärska MongoDB och tillämpa det i många olika applikationer. MongoDB:s aggregeringsramverk används för datavetenskapligt arbetsflöde för att utföra dataanalys för många applikationer.
Slutsats
MongoDB erbjuder flera olika funktioner såsom:flexibel datamodell, rik programmering, datamodell, frågemodell och dess inställbara konsistens som gör träning och användning av maskininlärningsalgoritmer mycket enklare än med traditionella relationsdatabaser. Att köra MongoDB som backend-databasen kommer att möjliggöra lagring och berikning av maskininlärningsdata möjliggör uthållighet och ökad effektivitet.