Underhåll är något som ett driftteam inte kan undvika. Servrarna måste hålla jämna steg med den senaste mjukvaran, hårdvaran och tekniken för att säkerställa att systemen är stabila och körs med lägsta möjliga risk, samtidigt som de använder nyare funktioner för att förbättra den övergripande prestandan.
Det finns utan tvekan en lång lista med underhållsuppgifter som måste utföras av systemadministratörer, särskilt när det kommer till kritiska system. Vissa av uppgifterna måste utföras med jämna mellanrum, som dagligen, veckovis, månadsvis och årligen. Vissa måste göras omedelbart, snarast. Ändå bör underhållsarbete inte leda till ytterligare ett större problem, och allt underhåll måste hanteras med extra försiktighet för att undvika avbrott i verksamheten.
Att få tveksamt tillstånd och falsklarm är vanligt medan underhåll pågår. Detta förväntas eftersom servern under underhållsperioden inte kommer att fungera som den ska förrän underhållsuppgiften är klar. ClusterControl, den heltäckande hanterings- och övervakningsplattformen för dina databaser med öppen källkod, kan konfigureras för att förstå dessa omständigheter för att förenkla dina underhållsrutiner, utan att offra övervaknings- och automationsfunktionerna den erbjuder.
Underhållsläge
ClusterControl introducerade underhållsläge i version 1.4.0, där du kan lägga in en enskild nod i underhåll som förhindrar ClusterControl att larma och skicka meddelanden under den angivna varaktigheten. Underhållsläge kan konfigureras från ClusterControl UI och även använda ClusterControl CLI-verktyget "s9s". Från användargränssnittet, gå bara till Noder -> välj en nod -> Nodåtgärder -> Schemalägg underhållsläge :
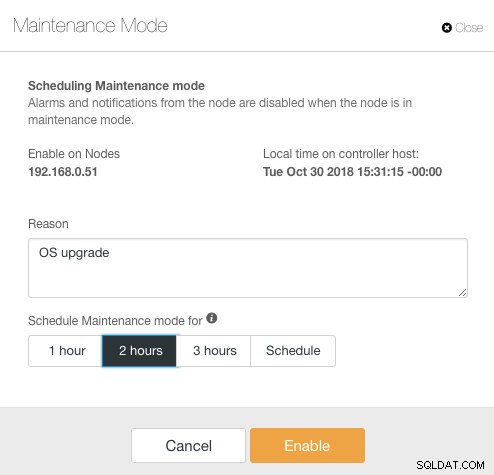
Här kan man ställa in underhållsperioden för en fördefinierad tid eller schemalägga den därefter. Du kan också skriva ner anledningen till att schemalägga uppgraderingen, användbart för granskningsändamål. Du bör se följande meddelande när underhållsläget är aktivt:
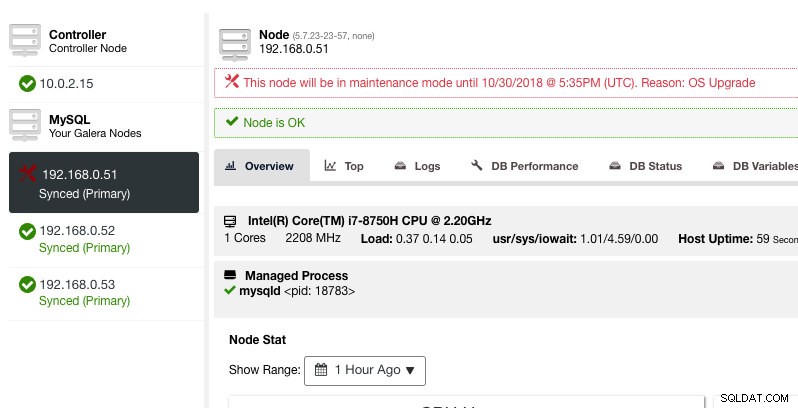
ClusterControl kommer inte att försämra noden, därför förblir nodens tillstånd som det är om du inte utför någon åtgärd som ändrar tillståndet. Larm och aviseringar för denna nod kommer att återaktiveras när underhållsperioden är över, eller operatören inaktiverar den uttryckligen genom att gå till Nodåtgärder -> Inaktivera underhållsläge .
Observera att om automatisk nodåterställning är aktiverad kommer ClusterControl alltid att återställa en nod oavsett underhållslägesstatus. Glöm inte att inaktivera nodåterställning för att undvika att ClusterControl stör dina underhållsuppgifter, detta kan göras från den översta sammanfattningsfältet.
Underhållsläget kan också konfigureras via ClusterControl CLI eller "s9s". Du kan använda kommandot "s9s underhåll" för att lista ut och manipulera underhållsperioderna. Följande kommandorad schemalägger ett underhållsfönster på en timme för nod 192.168.1.121 i morgon:
$ s9s maintenance --create \
--nodes=192.168.1.121 \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="Upgrading software."För mer information och exempel, se s9s underhållsdokumentation.
Klusteromfattande underhållsläge
När detta skrivs måste underhållslägeskonfigurationen konfigureras per hanterad nod. För klusteromfattande underhåll måste man upprepa schemaläggningsprocessen för varje hanterad nod i klustret. Detta kan vara opraktiskt om du har ett stort antal noder i ditt kluster, eller om underhållsintervallet är mycket kort mellan två uppgifter.
Lyckligtvis kan ClusterControl CLI (a.k.a s9s) användas som en lösning för att övervinna denna begränsning. Du kan använda "s9s-noder" för att lista ut och manipulera de hanterade noderna i ett kluster. Den här listan kan upprepas för att schemalägga ett klusteromfattande underhållsläge vid en given tidpunkt med kommandot "s9s maintenance".
Låt oss titta på ett exempel för att förstå detta bättre. Tänk på följande Percona XtraDB-kluster med tre noder som vi har:
$ s9s nodes --list --cluster-name='PXC57' --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PXC57 10.0.2.15 9500 Up and running.
go-M 5.7.23 1 PXC57 192.168.0.51 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.52 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.53 3306 Up and running.
Total: 4Klustret har totalt 4 noder - 3 databasnoder med en ClusterControl-nod. Den första kolumnen, STAT, visar nodens roll och status. Det första tecknet är nodens roll - "c" betyder kontroller och "g" betyder Galera databasnod. Anta att vi bara vill schemalägga databasnoderna för underhåll, vi kan filtrera bort utdata för att få värdnamnet eller IP-adressen där den rapporterade STAT har "g" i början:
$ s9s nodes --list --cluster-name='PXC57' --long --batch | grep ^g | awk {'print $5'}
192.168.0.51
192.168.0.52
192.168.0.53Med en enkel iteration kan vi sedan schemalägga ett klusteromfattande underhållsfönster för varje nod i klustret. Följande kommando upprepar underhållsskapandet baserat på alla IP-adresser som finns i klustret med hjälp av en for-loop, där vi planerar att starta underhållsoperationen samma tid imorgon och avsluta en timme senare:
$ for host in $(s9s nodes --list --cluster-id='PXC57' --long --batch | grep ^g | awk {'print $5'}); do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="OS upgrade"; done
f92c5370-004d-4735-bba0-8c1bd26b9b98
9ff7dd8c-f2cb-4446-b14b-a5c2b915b853
103d715d-d0bc-4402-9326-1a053bc5d36bDu bör se en utskrift av 3 UUID, den unika strängen som identifierar varje underhållsperiod. Vi kan sedan verifiera med följande kommando:
$ s9s maintenance --list --long
ST UUID OWNER GROUP START END HOST/CLUSTER REASON
-h f92c537 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.51 OS upgrade
-h 9ff7dd8 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.52 OS upgrade
-h 103d715 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.53 OS upgrade
Total: 3Från ovanstående utdata fick vi en lista över schemalagda underhållstider för varje databasnod. Under den schemalagda tiden kommer ClusterControl varken att larma eller skicka ut meddelanden om den hittar oegentligheter i klustret.
Iteration av underhållsläge
Vissa underhållsrutiner måste göras med jämna mellanrum, t.ex. backuper, hushållning och städningsuppgifter. Under underhållstiden förväntar vi oss att servern beter sig annorlunda. Men varje servicefel, tillfällig otillgänglighet eller hög belastning skulle säkert orsaka förödelse för vårt övervakningssystem. För frekventa och korta underhållstider kan detta visa sig vara mycket irriterande och att hoppa över de upphöjda falska alarmen kan ge dig en bättre sömn under natten.
Aktivering av underhållsläge kan dock även utsätta servern för en större risk eftersom strikt övervakning ignoreras under en viss tidsperiod. Därför är det förmodligen en bra idé att förstå vilken typ av underhållsåtgärd vi vill utföra innan du aktiverar underhållsläget. Följande checklista bör hjälpa oss att fastställa vår policy för underhållsläge:
- Båda noder – Vilka noder är involverade i underhållet?
- Konsekvenser - Vad händer med noden när underhållsarbetet pågår? Kommer den att vara otillgänglig, högbelastad eller startas om?
- Längd – Hur lång tid tar underhållsåtgärden att slutföra?
- Frekvens – Hur ofta ska underhållet köras?
Låt oss lägga det i ett användningsfall. Tänk att vi har ett Percona XtraDB-kluster med tre noder med en ClusterControl-nod. Förutsatt att alla våra servrar körs på virtuella maskiner och säkerhetskopieringspolicyn för virtuella datorer kräver att alla virtuella datorer säkerhetskopieras varje dag från 01:00, en nod i taget. Under denna säkerhetskopiering kommer noden att frysas i max 10 minuter och noden som hanteras och övervakas av ClusterControl kommer att vara otillgänglig tills säkerhetskopieringen är klar. Ur ett Galera Cluster-perspektiv försvinner inte hela klustret eftersom klustret förblir kvorum och den primära komponenten inte påverkas.
Baserat på arten av underhållsuppgiften kan vi sammanfatta det som följande:
- Berörda noder – Alla noder för kluster-ID 1 (3 databasnoder och 1 ClusterControl-nod).
- Konsekvens – den virtuella datorn som säkerhetskopieras kommer att vara otillgänglig tills den är klar.
- Längd – Varje VM-säkerhetskopiering tar cirka 5 till 10 minuter att slutföra.
- Frekvens – VM-säkerhetskopian är schemalagd att köras dagligen, med start från 01:00 på den första noden.
Vi kan sedan komma ut med en utförandeplan för att schemalägga vårt underhållsläge:
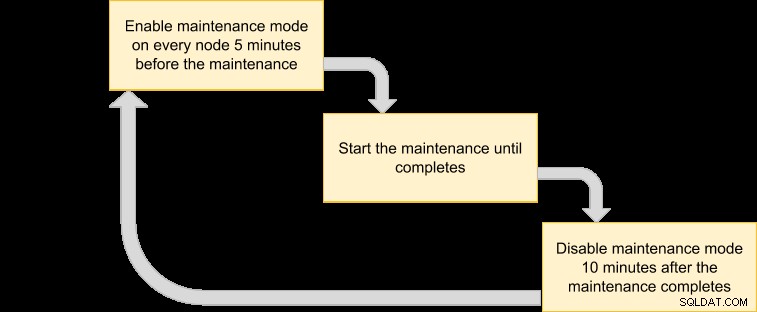
Eftersom vi vill att alla noder i klustret ska säkerhetskopieras av VM-hanteraren, lista helt enkelt noderna för motsvarande kluster-ID:
$ s9s nodes --list --cluster-id=1
192.168.0.51 10.0.2.15 192.168.0.52 192.168.0.53Ovanstående utdata kan användas för att schemalägga underhåll över hela klustret. Om du till exempel kör följande kommando kommer ClusterControl att aktivera underhållsläge för alla noder under kluster-ID 1 från och med nu till de kommande 50 minuterna:
$ for host in $(s9s nodes --list --cluster-id=1); do \
s9s maintenance --create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="Backup VM"; doneMed kommandot ovan kan vi konvertera det till en exekveringsfil genom att lägga in det i ett skript. Skapa en fil:
$ vim /usr/local/bin/enable_maintenance_modeOch lägg till följande rader:
for host in $(s9s nodes --list --cluster-id=1)
do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="VM Backup"
doneSpara den och se till att filbehörigheten är körbar:
$ chmod 755 /usr/local/bin/enable_maintenance_modeAnvänd sedan cron för att schemalägga skriptet så att det körs 5 minuter till 01:00 dagligen, precis innan säkerhetskopieringen av den virtuella datorn börjar kl. 01:00:
$ crontab -e
55 0 * * * /usr/local/bin/enable_maintenance_modeLadda om cron-demonen för att säkerställa att vårt skript står i kö:
$ systemctl reload crond # or service crond reloadDet är allt. Vi kan nu utföra vårt dagliga underhåll utan att bli avlyssnat av falska larm och e-postmeddelanden tills underhållet är klart.
Bonusunderhållsfunktion - Hoppa över nodåterställning
Med automatisk återställning aktiverad är ClusterControl smart nog att upptäcka ett nodfel och kommer att försöka återställa en misslyckad nod efter en 30-sekunders respitperiod, oavsett underhållslägesstatus. Visste du att ClusterControl kan konfigureras för att avsiktligt hoppa över nodåterställning för en viss nod? Detta kan vara till stor hjälp när du måste utföra ett brådskande underhåll utan att veta tidsperioden och resultatet av underhållet.
Föreställ dig till exempel att en korruption av filsystemet inträffade och att filsystemkontroll och reparation krävs efter en hård omstart. Det är svårt att i förväg avgöra hur mycket tid det skulle behöva för att slutföra denna operation. Således kan vi helt enkelt använda en flaggfil för att signalera ClusterControl att hoppa över återställning för noden.
Lägg först till följande rad i /etc/cmon.d/cmon_X.cnf (där X är kluster-ID) på ClusterControl-noden:
node_recovery_lock_file=/root/do_not_recoverStarta sedan om cmon-tjänsten för att ladda ändringen:
$ systemctl restart cmon # service cmon restartSe slutligen till att den angivna filen finns på noden som vi vill hoppa över för ClusterControl-återställning:
$ touch /root/do_not_recoverOavsett status för automatisk återställning och underhållsläge kommer ClusterControl endast att återställa noden när denna flaggfil inte finns. Administratören är sedan ansvarig för att skapa och ta bort filen på databasnoden.
Det var allt, gott folk. Lycka till med underhållet!