Flera JOINS i en enda fråga
Multiple JOINS förknippas normalt med flera samlingar, men du måste ha en grundläggande förståelse för hur INNER JOIN fungerar (se mina tidigare inlägg om detta ämne). Förutom våra två kollektioner vi hade tidigare; enheter och studenter, låt oss lägga till en tredje samling och märka den sport. Fyll sportsamlingen med uppgifterna nedan:
{
"_id" : 1,"tournamentsPlayed" : 6,
"gamesParticipated" : [{"hockey" : "midfielder","football" : "stricker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge","South Africa", "Rio Brazil"]
}
{
"_id" : 2,"tournamentsPlayed" : 3,
"gamesParticipated" : [{"hockey" : "goalkeeper","football" : "stricker", "handball" : "midfielder"}],
"sportPlaces" : ["Ukraine","India", "Argentina"]
}
{
"_id" : 3,"tournamentsPlayed" : 10,
"gamesParticipated" : [{"hockey" : "stricker","football" : "goalkeeper","tabletennis" : "doublePlayer"}],
"sportPlaces" : ["China","Korea","France"]
}Vi skulle till exempel vilja returnera all data för en student med _id-fältvärdet lika med 1. Normalt skulle vi skriva en fråga för att hämta för _id-fältvärdet från studentsamlingen, och sedan använda det returnerade värdet för att fråga efter data i de två andra samlingarna. Följaktligen kommer detta inte att vara det bästa alternativet, särskilt om en stor uppsättning dokument är inblandade. Ett bättre tillvägagångssätt skulle vara att använda Studio3T-programmets SQL-funktion. Vi kan fråga vår MongoDB med det normala SQL-konceptet och sedan försöka grovjustera den resulterande Mongo-skalkoden för att passa vår specifikation. Låt oss till exempel hämta all data med _id lika med 1 från alla samlingar:
SELECT *
FROM students
INNER JOIN units
ON students._id = units._id
INNER JOIN sports
ON students._id = sports._id
WHERE students._id = 1;Det resulterande dokumentet blir:
{
"students" : {"_id" : NumberInt(1),"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5},
"units" : {"_id" : NumberInt(1),"grades" : {Maths" : "A","English" : "A","Science" : "A","History" : "B"}
},
"sports" : {
"_id" : NumberInt(1),"tournamentsPlayed" : NumberInt(6),
"gamesParticipated" : [{"hockey" : "midfielder", "football" : "striker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge","South Africa","Rio Brazil"]
}
}Från fliken Frågekod kommer motsvarande MongoDB-kod att vara:
db.getCollection("students").aggregate(
[{ "$project" : {"_id" : NumberInt(0),"students" : "$$ROOT"}},
{ "$lookup" : {"localField" : "students._id","from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$unwind" : {"path" : "$units","preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id","from" : "sports", "foreignField" : "_id","as" : "sports"}},
{ "$unwind" : {"path" : "$sports", "preserveNullAndEmptyArrays" : false}},
{ "$match" : {"students._id" : NumberLong(1)}}
]
);När jag tittar på det returnerade dokumentet är jag personligen inte så nöjd med datastrukturen, särskilt med inbäddade dokument. Som du kan se finns det _id-fält som returneras och för enheterna behöver vi kanske inte betygsfältet bäddas in i enheterna.
Vi skulle vilja ha ett enhetsfält med inbäddade enheter och inte några andra fält. Detta leder oss till den grova låten. Liksom i de tidigare inläggen, kopiera koden med hjälp av kopieringsikonen som tillhandahålls och gå till aggregeringsrutan, klistra in innehållet med hjälp av klistra in-ikonen.
Först och främst bör $match-operatorn vara det första steget, så flytta den till första positionen och ha något sånt här:
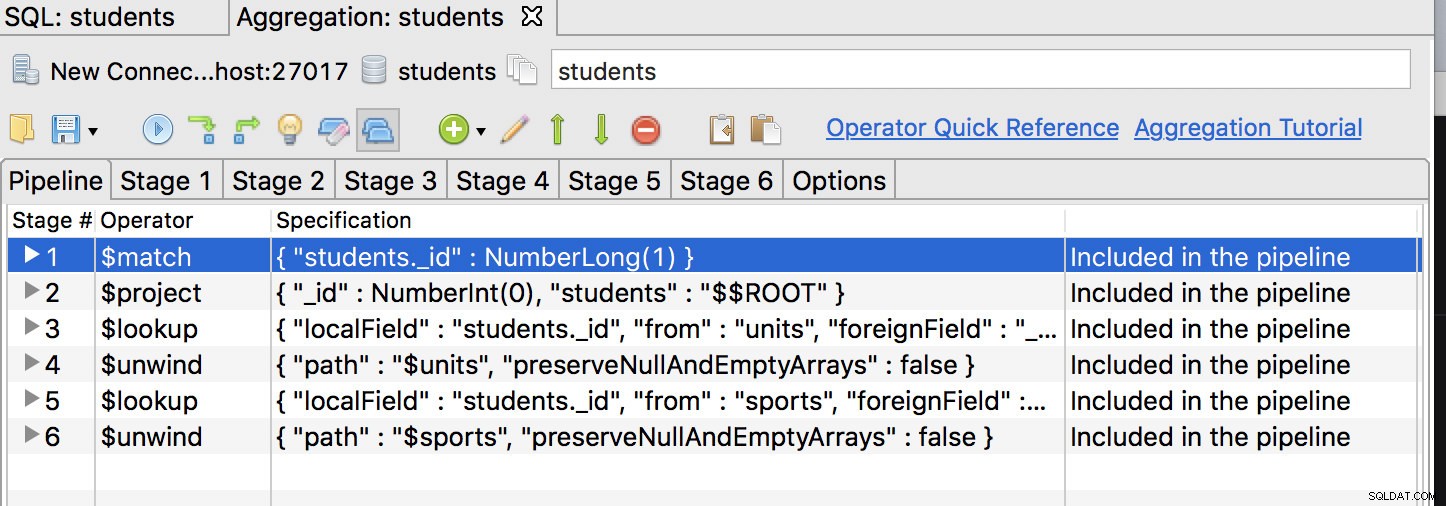
Klicka på fliken första steget och ändra frågan till:
{
"_id" : NumberLong(1)
}Vi måste sedan modifiera frågan ytterligare för att ta bort många inbäddningssteg av vår data. För att göra det lägger vi till nya fält för att fånga in data för de fält vi vill eliminera, dvs.:
db.getCollection("students").aggregate(
[
{ "$project" : { "_id" : NumberInt(0), "students" : "$$ROOT"}},
{ "$match" : {"students._id" : NumberLong(1)}},
{ "$lookup" : { "localField" : "students._id", "from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$addFields" : { "_id": "$students._id","units" : "$units.grades"}},
{ "$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id", "from" : "sports", "foreignField" : "_id", "as" : "sports"}},
{ "$unwind" : { "path" : "$sports","preserveNullAndEmptyArrays" : false}},
{ "$project" : {"sports._id" : 0.0}}
]
);Som du kan se har vi i finjusteringsprocessen introducerat nya fältenheter som kommer att skriva över innehållet i den tidigare aggregeringspipelinen med betyg som ett inbäddat fält. Vidare har vi skapat ett _id-fält för att indikera att data var i relation till eventuella dokument i samlingarna med samma värde. Det sista $project-stadiet är att ta bort _id-fältet i sportdokumentet så att vi kan ha en snyggt presenterad data enligt nedan.
{ "_id" : NumberInt(1),
"students" : {"name" : "James Washington", "age" : 15.0, "grade" : "A", "score" : 10.5},
"units" : {"Maths" : "A","English" : "A", "Science" : "A","History" : "B"},
"sports" : {
"tournamentsPlayed" : NumberInt(6),
"gamesParticipated" : [{"hockey" : "midfielder","football" : "striker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge", "South Africa", "Rio Brazil"]
}
}Vi kan också begränsa vilka fält som ska returneras från SQL-synpunkt. Till exempel kan vi returnera elevens namn, enheter som denna elev gör och antalet turneringar som spelas med flera JOINS med koden nedan:
SELECT students.name, units.grades, sports.tournamentsPlayed
FROM students
INNER JOIN units
ON students._id = units._id
INNER JOIN sports
ON students._id = sports._id
WHERE students._id = 1;Detta ger oss inte det mest lämpliga resultatet. Så som vanligt, kopiera det och klistra in i sammanställningsrutan. Vi finjusterar med koden nedan för att få rätt resultat.
db.getCollection("students").aggregate(
[
{ "$project" : { "_id" : NumberInt(0), "students" : "$$ROOT"}},
{ "$match" : {"students._id" : NumberLong(1)}},
{ "$lookup" : { "localField" : "students._id", "from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$addFields" : {"units" : "$units.grades"}},
{ "$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id", "from" : "sports", "foreignField" : "_id", "as" : "sports"}},
{ "$unwind" : { "path" : "$sports","preserveNullAndEmptyArrays" : false}},
{ "$project" : {"name" : "$students.name", "grades" : "$units.grades", "tournamentsPlayed" : "$sports.tournamentsPlayed"}
}}
]
);Detta aggregeringsresultat från SQL JOIN-konceptet ger oss en snygg och presentabel datastruktur som visas nedan.
{
"name" : "James Washington",
"grades" : {"Maths" : "A", "English" : "A", "Science" : "A", "History" : "B"},
"tournamentsPlayed" : NumberInt(6)
}Ganska enkelt, eller hur? Datan är ganska presentabel som om den lagrades i en enda samling som ett enda dokument.
VÄNSTER YTTRE JOIN
LEFT OUTER JOIN används normalt för att visa dokument som inte överensstämmer med det mest porträtterade förhållandet. Den resulterande uppsättningen av en LEFT OUTER-join innehåller alla rader från båda samlingarna som uppfyller WHERE-satskriterierna, samma som en INNER JOIN-resultatuppsättning. Dessutom kommer alla dokument från den vänstra samlingen som inte har matchande dokument i den högra samlingen också att inkluderas i resultatuppsättningen. Fälten som väljs från den högra sidotabellen returnerar NULL-värden. Alla dokument i den högra samlingen, som inte har matchande kriterier från den vänstra samlingen, returneras dock inte.
Ta en titt på dessa två samlingar:
studenter
{"_id" : 1,"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5}
{"_id" : 2,"name" : "Clinton Ariango","age" : 14.0,"grade" : "B","score" : 7.5}
{"_id" : 4,"name" : "Mary Muthoni","age" : 16.0,"grade" : "A","score" : 11.5}Enheter
{"_id" : 1,"Maths" : "A","English" : "A","Science" : "A","History" : "B"}
{"_id" : 2,"Maths" : "B","English" : "B","Science" : "A","History" : "B"}
{"_id" : 3,"Maths" : "A","English" : "A","Science" : "A","History" : "A"}I studentsamlingen har vi inte _id-fältvärdet satt till 3 men i enhetssamlingen har vi. Likaså finns det inget _id-fältvärde 4 i enhetssamlingen. Om vi använder studentsamlingen som vårt vänstra alternativ i JOIN-metoden med frågan nedan:
SELECT *
FROM students
LEFT OUTER JOIN units
ON students._id = units._idMed denna kod får vi följande resultat:
{
"students" : {"_id" : 1,"name" : "James Washington","age" : 15,"grade" : "A","score" : 10.5},
"units" : {"_id" : 1,"grades" : {"Maths" : "A","English" : "A", "Science" : "A","History" : "B"}}
}
{
"students" : {"_id" : 2,"name" : "Clinton Ariango", "age" : 14,"grade" : "B", "score" : 7.5 }
}
{
"students" : {"_id" : 3,"name" : "Mary Muthoni","age" : 16,"grade" : "A","score" : 11.5},
"units" : {"_id" : 3,"grades" : {"Maths" : "A","English" : "A","Science" : "A","History" : "A"}}
}Det andra dokumentet har inte enhetsfältet eftersom det inte fanns något matchande dokument i enhetssamlingen. För denna SQL-fråga kommer motsvarande Mongo-kod att vara
db.getCollection("students").aggregate(
[
{
"$project" : {"_id" : NumberInt(0), "students" : "$$ROOT"}},
{
"$lookup" : {"localField" : "students._id", "from" : "units", "foreignField" : "_id", "as" : "units"}
},
{
"$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : true}
}
]
);Naturligtvis har vi lärt oss om finjustering, så att du kan gå vidare och strukturera om aggregationspipelinen så att den passar det slutresultat du vill ha. SQL är ett mycket kraftfullt verktyg när det gäller databashantering. Det är ett brett ämne i sig, du kan också prova att använda IN- och GROUP BY-satserna för att få korrespondentkoden för MongoDB och se hur det fungerar.
Slutsats
Att vänja sig vid en ny (databas)teknik utöver den man är van att arbeta med kan ta mycket tid. Relationella databaser är fortfarande vanligare än de icke-relationella. Ändå, med introduktionen av MongoDB, har saker och ting förändrats och folk skulle vilja lära sig det så snabbt som möjligt på grund av dess tillhörande kraftfulla prestanda.
Att lära sig MongoDB från grunden kan vara lite tråkigt, men vi kan använda kunskapen om SQL för att manipulera data i MongoDB, hämta den relativa MongoDB-koden och finjustera den för att få de mest lämpliga resultaten. Ett av verktygen som är tillgängliga för att förbättra detta är Studio 3T. Den erbjuder två viktiga funktioner som underlättar driften av komplexa data, det vill säga:SQL-frågefunktion och Aggregationsredigeraren. Finjusteringsfrågor kommer inte bara att säkerställa att du får det bästa resultatet utan också förbättra prestandan när det gäller tidsbesparing.