SCUMM (Severalnines ClusterControl Unified Monitoring &Management) är en agentbaserad lösning med agenter installerade på databasnoderna. Den tillhandahåller en uppsättning övervakningspaneler som har Prometheus som datalager med dess elastiska frågespråk och multidimensionella datamodell. Prometheus skrapar mätdata från exportörer som körs på databasvärdarna.
ClusterControl SCUMM-arkitekturen introducerades med version 1.7.0 som utökar övervakningsfunktionaliteten för MySQL, Galera Cluster, PostgreSQL och ProxySQL.
Den nya ClusterControl 1.7.1 lägger till högupplöst övervakning för MongoDB-system.
 ClusterControl MongoDB instrumentpanelslista
ClusterControl MongoDB instrumentpanelslista I den här artikeln kommer vi att beskriva de två huvudinstrumentpanelerna för MongoDB-miljöer. MongoDB Server och MongoDB Replicaset.
Dashboard och statistiklista
Listan över instrumentpaneler och deras mätvärden:
| MongoDB Server | |
|---|---|
| Namn ReplSet Name Serverupptid OpsCounters Anslutningar WT - Samtidiga biljetter (läs) WT - Samtidiga biljetter (skriv) WT - Cache Global Lock Asserts |
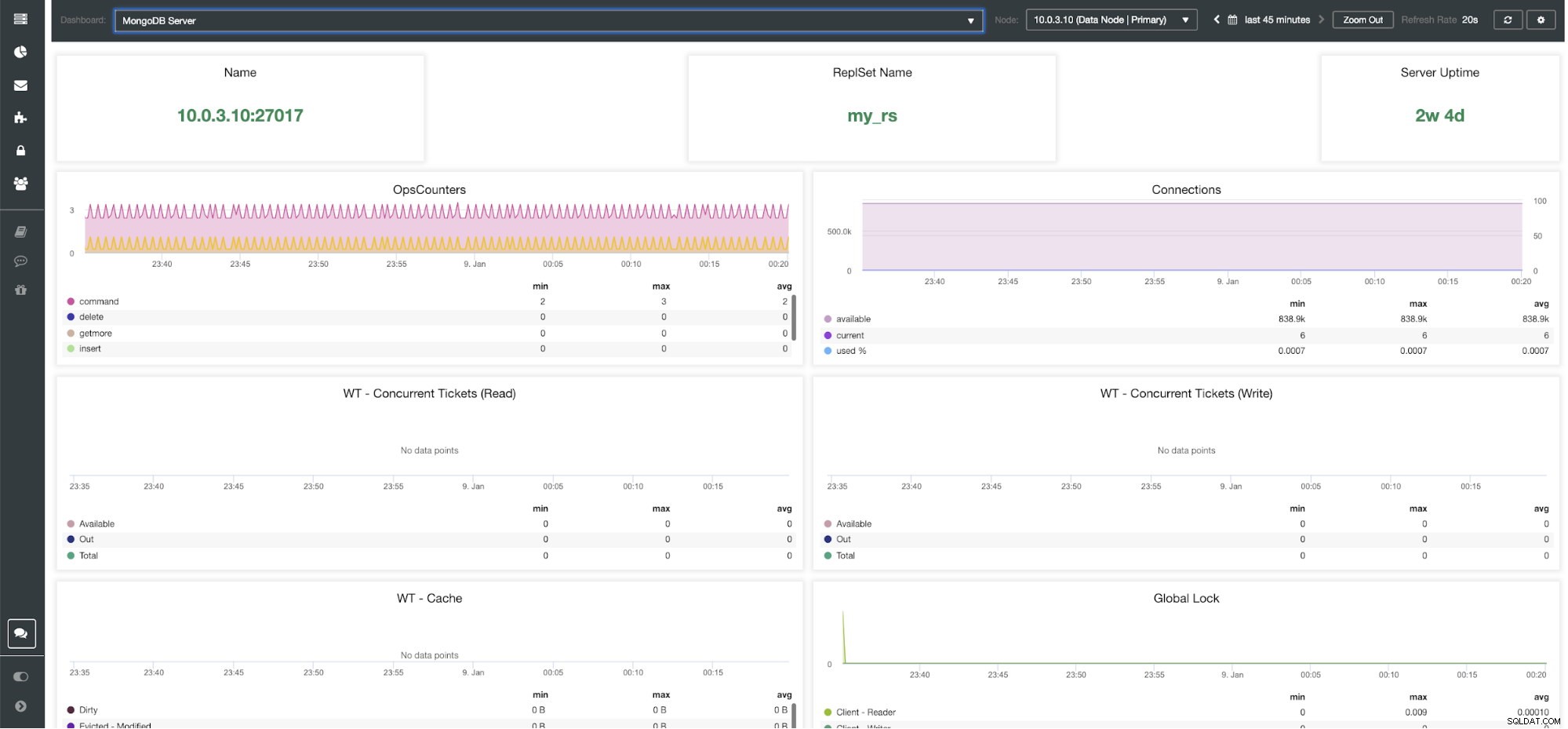 ClusterControl MongoDB Server Dashboard
ClusterControl MongoDB Server Dashboard| MongoDB ReplicaSet | |
|---|---|
| ReplSet Size ReplSet Name PRIMÄR Serverversion Replikuppsättningar och medlemmar Oplogfönster per repluppsättning Replikeringsutrymme Totalt PRIMÄR/SEKUNDÄR online per repluppsättning Öppna markörer per repluppsättning Repluppsättning - markörer med tidsgräns per uppsättning Max replikeringsfördröjning per repluppsättning Oplogstorlek Opsräknare Ping Time to Replica Set Members from PRIMARY(s) |
 ClusterControl MongoDB ReplicaSet Dashboard
ClusterControl MongoDB ReplicaSet Dashboard Databassystem är starkt beroende av OS-resurser, så du kan också hitta två extra instrumentpaneler för Systemöversikt och Klusteröversikt över din MongoDB-miljö.
| Systemöversikt | |
|---|---|
| Serverdrifttid CPU-kärnor Totalt RAM Genomsnittlig belastning CPU-användning RAM-användning Diskutrymmesanvändning Nätverksanvändning Disk IOPS Disk IO Util % Disk Throughput |
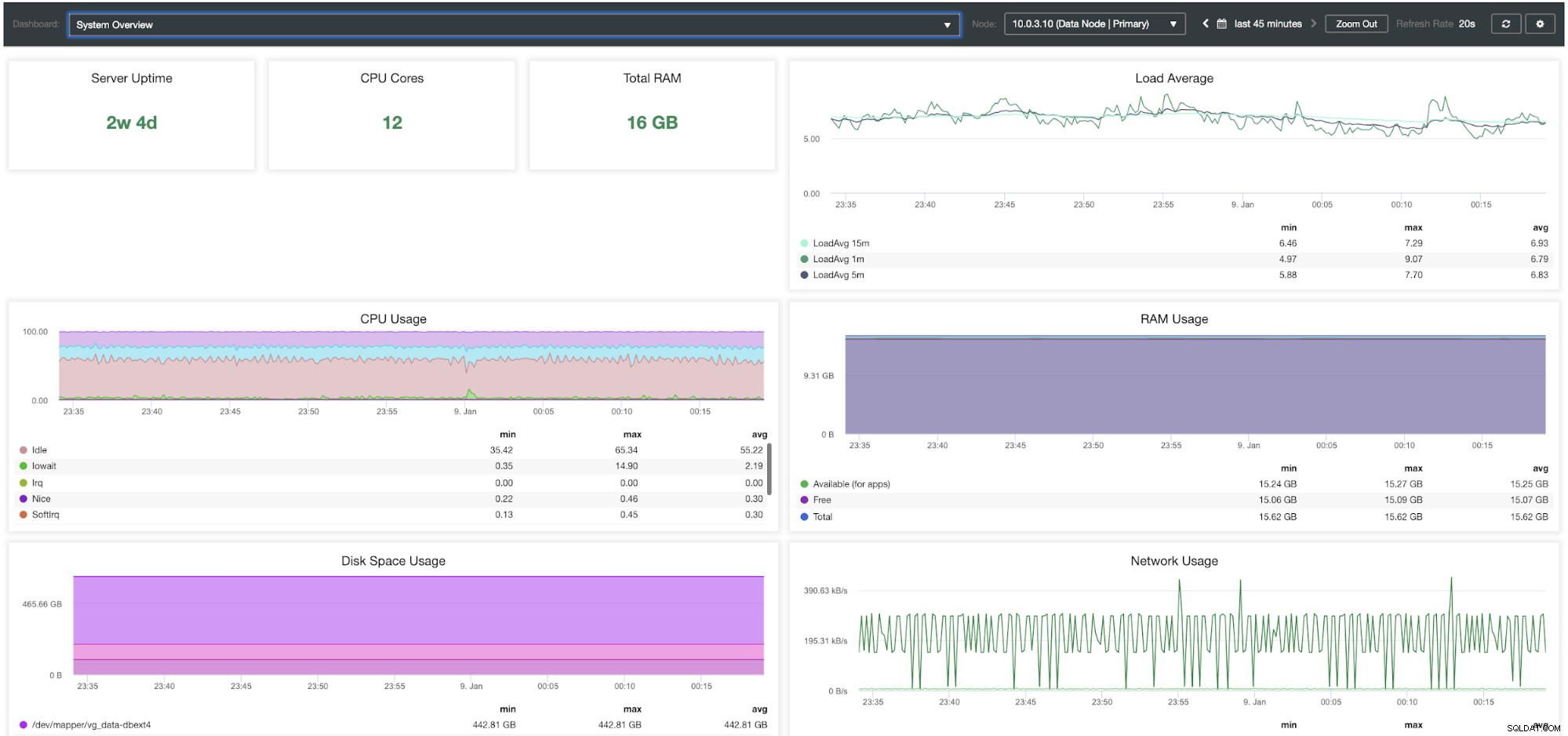 ClusterControl System Översikt Dashboard
ClusterControl System Översikt Dashboard| Klusteröversikt | |
|---|---|
| Belastning medelvärde 1m Belastningsmedelvärde 5m Belastningsmedelvärde 15m Minne tillgängligt för applikationer Nätverk TX Nätverk RX Diskläs IOPS Diskskrivning IOPS Diskskrivning + Läs IOPS |
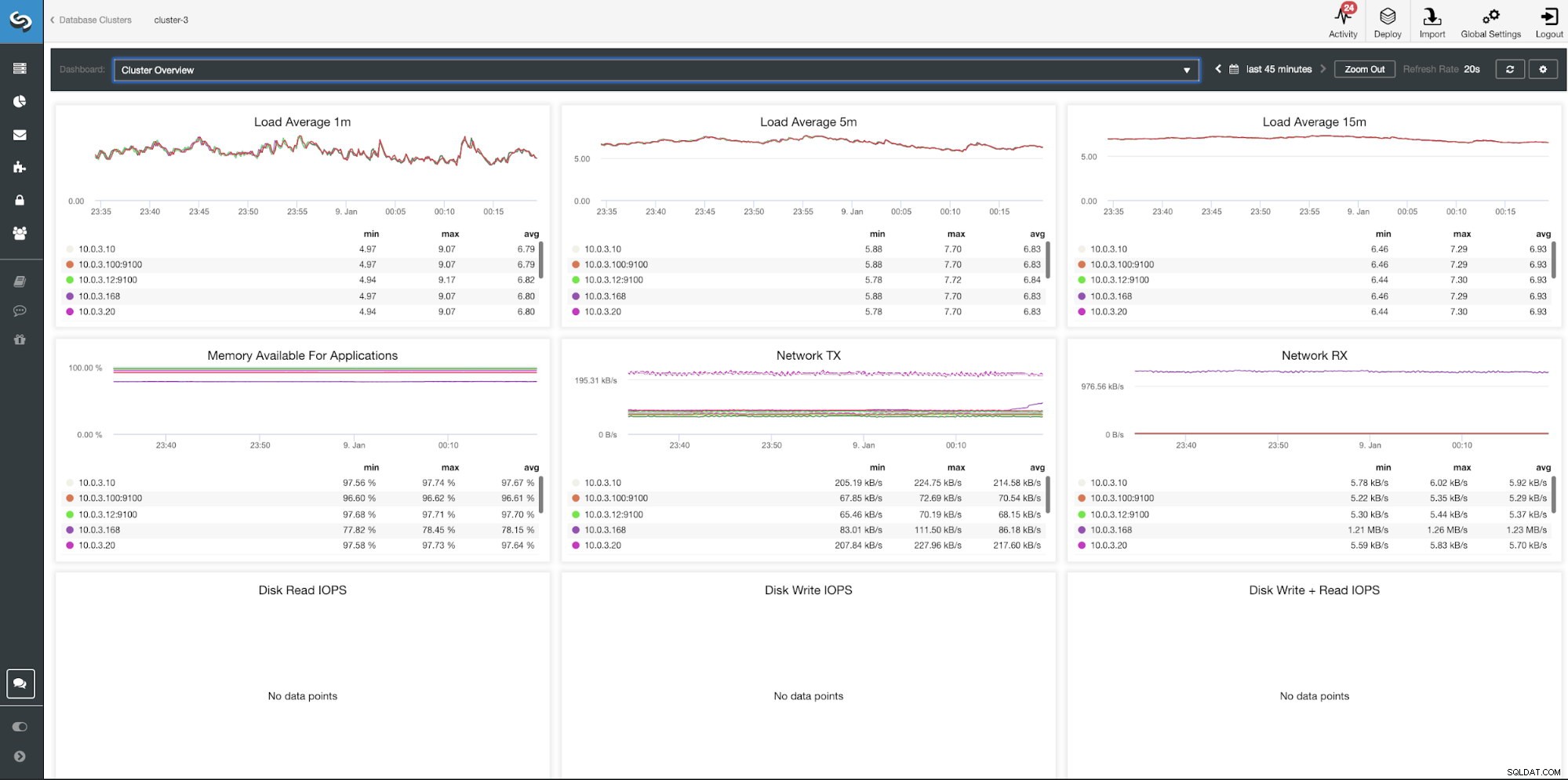 ClusterControl Clusteröversikt Dashboard
ClusterControl Clusteröversikt Dashboard MongoDB Server Dashboard
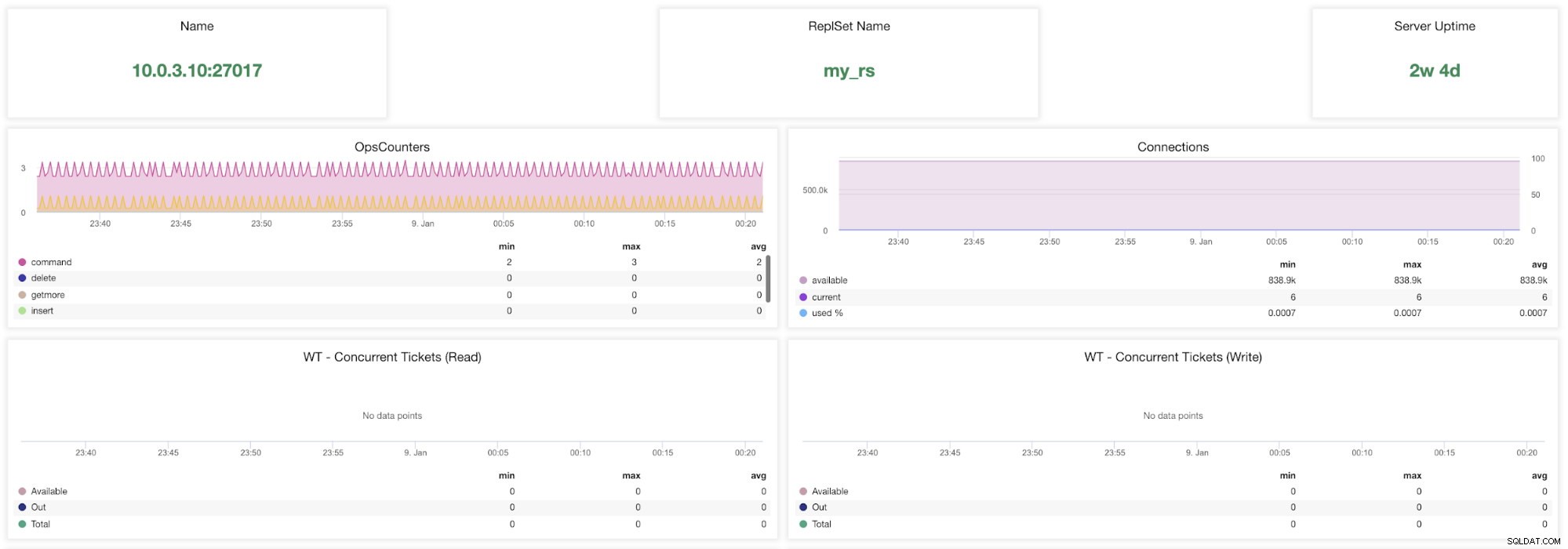 ClusterControl MongoDB-statistik
ClusterControl MongoDB-statistik Namn - Serveradress och porten.
ReplsSet Name - Presenterar namnet på replikuppsättningen där servern tillhör.
Serverdrifttid - Tid sedan senaste omstart av servern.
Ops Couters - Antal förfrågningar som tagits emot under den valda tidsperioden fördelat på typen av operation. Dessa siffror inkluderar alla mottagna operationer, inklusive sådana som inte lyckades.
Anslutningar - Det här diagrammet visar en av de viktigaste mätvärdena att titta på - antalet mottagna anslutningar under den valda tidsperioden inklusive misslyckade förfrågningar. Onormal trafikbelastning kan leda till prestandaproblem. Om MongoDB tar slut på anslutningar kanske det inte kan hantera inkommande förfrågningar i tid.
WT - samtidiga biljetter (läs) / WT - samtidiga biljetter (skriv) Dessa två grafer visar läs- och skrivbiljetter som kontrollerar samtidighet i WiredTiger (WT). WT-biljetter styr hur många läs- och skrivoperationer som kan köras på lagringsmotorn samtidigt. När tillgängliga läs- och skrivbiljetter sjunker till noll är antalet samtidiga köroperationer lika med de konfigurerade läs-/skrivvärdena. Detta innebär att alla andra operationer måste vänta tills en av de löpande trådarna avslutar sitt arbete på lagringsmotorn innan de körs.
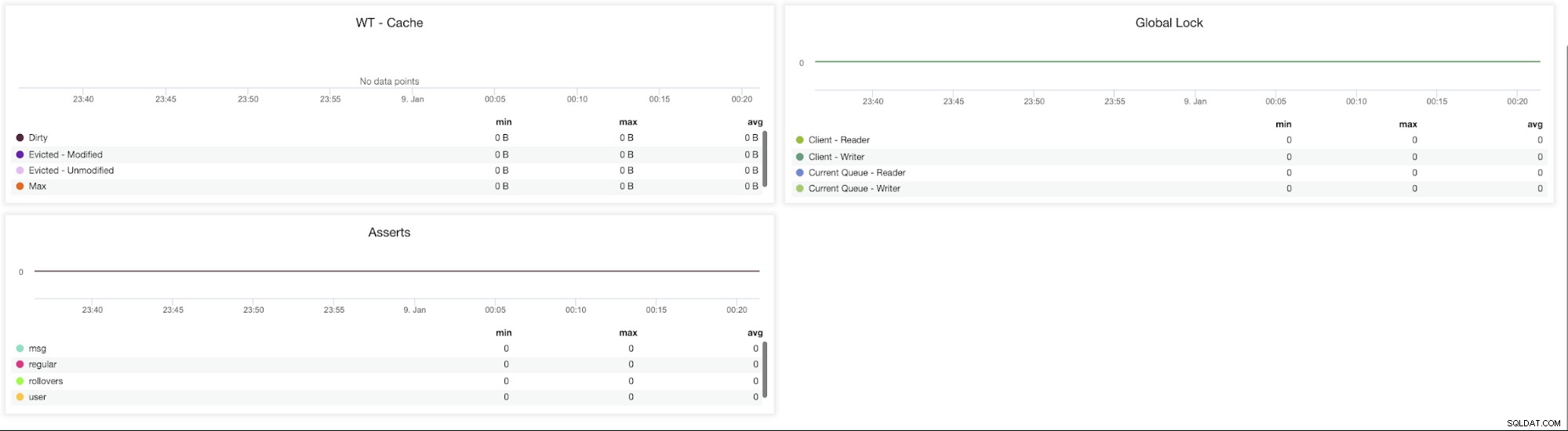 ClusterControl MongoDB-statistik
ClusterControl MongoDB-statistik WT - Cache (Dirty, Evicted - Modified, Evicted - Unmodified, Max) - Storleken på cachen är den enskilt viktigaste ratten för WiredTiger. Som standard reserverar MongoDB 3.x 50 % (60 % i 3.2) av det tillgängliga minnet för sin datacache.
Globalt lås (Client-Read, Client - Write, Current Queue - Reader, Current Queue - Writer) - Dåliga schemadesignmönster eller tunga läs- och skrivförfrågningar från många klienter kan orsaka omfattande låsning. När detta inträffar finns det ett behov av att upprätthålla konsistens och undvika skrivkonflikter.
För att uppnå detta använder MongoDB multi-granularity-locking som gör att låsoperationer kan ske på olika nivåer, såsom en global, databas eller samlingsnivå .
Förstående (msg, regular, rollovers, user) - Det här diagrammet visar antalet påståenden som höjs varje sekund. Höga värden och avvikelser från trender bör ses över.
MongoDB ReplicaSet Dashboard
Mätvärdena som visas i den här instrumentpanelen spelar bara roll om du använder en replikuppsättning.
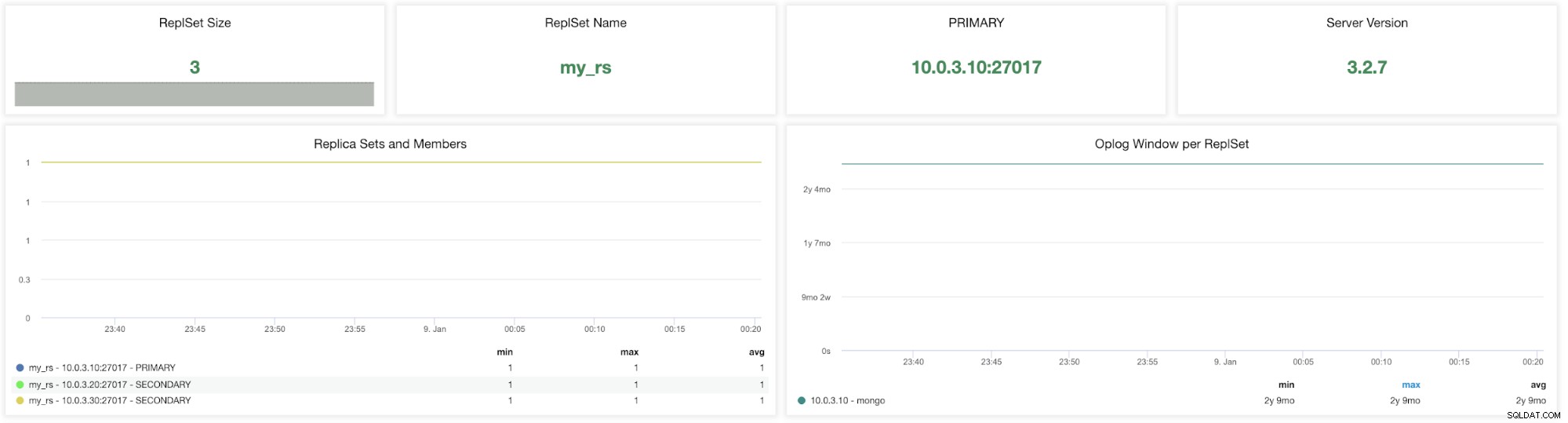 ClusterControl MongoDB ReplicaSet Metrics
ClusterControl MongoDB ReplicaSet Metrics Replikauppsättningsstorlek - Antalet medlemmar i replikuppsättningen. Standardinstallationen av replikuppsättningar för produktionssystemet är en replikuppsättning med tre medlemmar. Generellt sett rekommenderas att en replikuppsättning har ett udda antal röstberättigade medlemmar. Feltolerans för en replikuppsättning är antalet medlemmar som kan bli otillgängliga och fortfarande lämna tillräckligt många medlemmar i uppsättningen för att välja en primär. Feltoleransen för tre medlemmar är en, för fem är det två osv.
ReplSet Name - Det är namnet som tilldelas i MongoDB-konfigurationsfilen. Namnet hänvisar till /etc/mongod.conf replSet-värde.
PRIMÄR - Den primära noden tar emot alla skrivoperationer och registrerar alla andra ändringar av sin datauppsättning i sin operationslogg. Värdet är att identifiera IP-adressen och porten för din primära nod i MongoDB-replikuppsättningsklustret.
Serverversion - Identifiera serverversionen. ClusterControl version 1.7.1 stöder MongoDB version 3.2/3.4/3.6/4.0.
Replika uppsättningar och medlemmar (min, max, avg) - Det här diagrammet kan hjälpa dig att identifiera aktiva medlemmar över tidsperioden. Du kan spåra det lägsta, högsta och genomsnittliga antalet primära och sekundära noder och hur dessa siffror förändrades över tiden. Alla avvikelser kan påverka feltolerans och klustertillgänglighet.
Oplog-fönster per repluppsättning - Replikeringsfönstret är ett viktigt mått att titta på. MongoDB-oploggen är en enda samling som har begränsats i en (förinställd) storlek. Det kan beskrivas som skillnaden mellan den första och den sista tidsstämpeln i oplog.rs. Det är hur lång tid en sekundär kan vara offline innan initial synkronisering behövs för att synkronisera instansen. Dessa mätvärden informerar dig om hur mycket tid du har kvar innan vår nästa transaktion tas bort från oploggen.
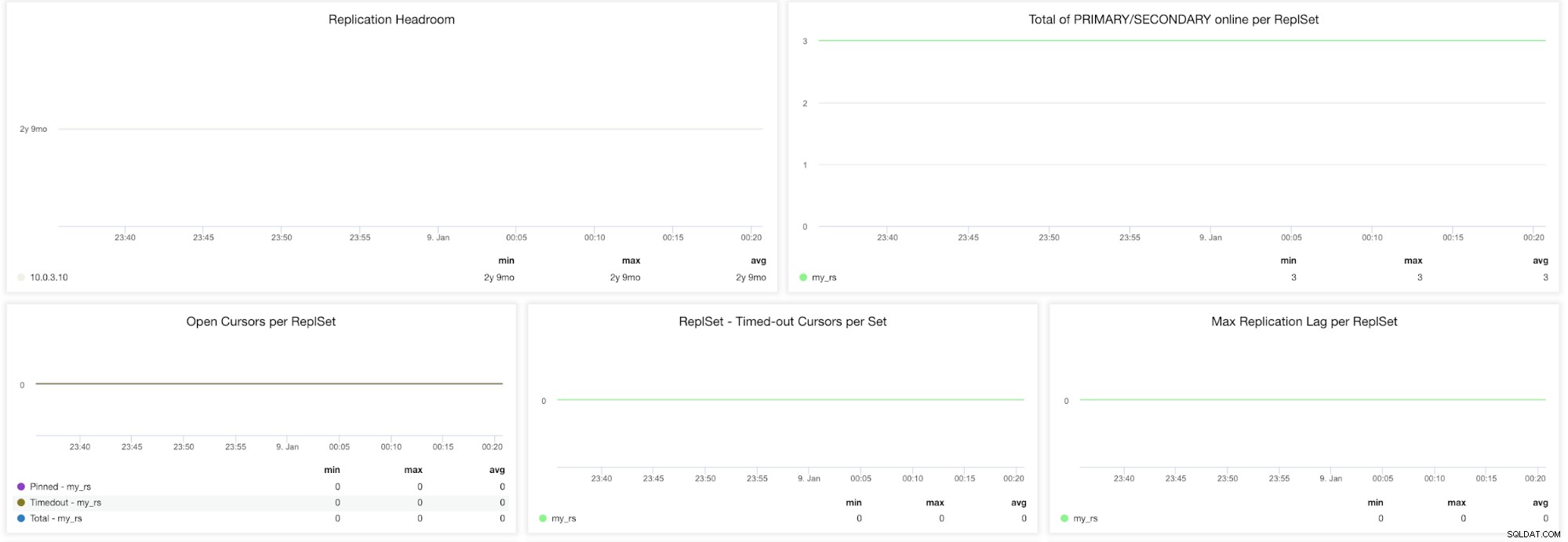 ClusterControl MongoDB ReplicaSet Metrics
ClusterControl MongoDB ReplicaSet Metrics Replikeringsutrymme - Den här grafen visar skillnaden mellan primärens oplogfönster och replikeringsfördröjningen för de sekundära noderna. MongoDB-oploggen är begränsad i storlek och om noden släpar för långt kommer den inte att kunna komma ikapp. Om detta händer kommer full synkronisering att utfärdas och detta är en dyr operation som alltid måste undvikas.
Totalt PRIMÄR/SEKUNDÄR online per ReplSet - Totalt antal klusternoder under tidsperioden.
Öppna markörer per repluppsättning (fästa, timeout, totalt) - En läsbegäran kommer med en markör som är en pekare till datamängden för resultatet. Den förblir öppen på servern och förbrukar därför minne såvida den inte avslutas av standardinställningen för MongoDB. Du bör identifiera icke-aktiva markörer och klippa av dem för att spara på minnet.
ReplSet - Timeout Cursors per SetsMax Replikeringsfördröjning per ReplSet - Replikeringsfördröjning är mycket viktigt att hålla ett öga på om du skalar ut läsningar genom att lägga till fler sekundärer. MongoDB kommer bara att använda dessa sekundärer om de inte ligger för långt efter. Om sekundären har replikeringsfördröjning riskerar du att leverera inaktuella data som redan har skrivits över på den primära.
OplogSize - Vissa arbetsbelastningar kan kräva större oplogstorlek. Uppdateringar av flera dokument samtidigt, raderingar motsvarar samma mängd data som en infogning eller det betydande antalet uppdateringar på plats.
OpsConters - Den här grafen visar antalet exekverade frågor.
Ping Time to Replica Set Member from Primary - Detta låter dig upptäcka replikuppsättningsmedlemmar som är nere eller inte kan nås från den primära noden.
Avslutande kommentarer
Den nya ClusterControl 1.7.1 MongoDB-instrumentpanelsfunktionen är tillgänglig i Community Edition gratis. Databasoperationsteam kan dra nytta av det genom att använda högupplösta grafer, särskilt när de utför sina dagliga rutiner som orsaksanalyser och kapacitetsplanering.
Det är bara en fråga om ett klick för att distribuera nya övervakningsagenter. ClusterControl installerar Prometheus-agenter, konfigurerar mätvärden och bibehåller åtkomst till Prometheus-exportörernas konfiguration via dess GUI, så att du bättre kan hantera parameterkonfiguration som samlarflaggor för exportörerna (Prometheus).
Genom att tillräckligt övervaka antalet läs- och skrivförfrågningar kan du förhindra resursöverbelastning, snabbt hitta orsaken till potentiella överbelastningar och veta när du ska skala upp.