Att utvärdera vilket strömmande arkitektoniskt mönster som bäst matchar ditt användningsfall är en förutsättning för en framgångsrik produktionsinstallation.
Apache Hadoop-ekosystemet har blivit en föredragen plattform för företag som vill bearbeta och förstå storskalig data i realtid. Tekniker som Apache Kafka, Apache Flume, Apache Spark, Apache Storm och Apache Samza pressar allt mer på vad som är möjligt. Det är ofta frestande att kombinera storskaliga användningsfall för streaming, men i verkligheten tenderar de att brytas ner i några olika arkitektoniska mönster, med olika komponenter i ekosystemet som är bättre lämpade för olika problem.
I det här inlägget kommer jag att beskriva de fyra stora strömningsmönstren som vi har stött på med kunder som driver företagsdatahubbar i produktionen, och förklara hur man implementerar dessa mönster arkitektoniskt på Hadoop.
Strömmande mönster
De fyra grundläggande strömningsmönstren (som ofta används i tandem) är:
- Strömintag: Innebär kvarstående händelser med låg latens till HDFS, Apache HBase och Apache Solr.
- Händelsebearbetning i nära realtid (NRT) med extern kontext: Utför åtgärder som varning, flaggning, transformering och filtrering av händelser när de anländer. Åtgärder kan vidtas baserat på sofistikerade kriterier, såsom modeller för upptäckt av anomalier. Vanliga användningsfall, som NRT-bedrägeriupptäckt och -rekommendation, kräver ofta låga latenser under 100 millisekunder.
- NRT Event Partitioned Processing: Liknar NRT-händelsebearbetning, men drar fördelar av att partitionera data – som att lagra mer relevant extern information i minnet. Det här mönstret kräver också bearbetningsfördröjningar under 100 millisekunder.
- Komplex topologi för aggregationer eller ML: Strömbehandlingens heliga graal:får svar i realtid från data med en komplex och flexibel uppsättning operationer. Eftersom resultaten ofta beror på fönsterberäkningar och kräver mer aktiv data, skiftar fokus från ultralåg latens till funktionalitet och noggrannhet.
I följande avsnitt kommer vi att gå in på rekommenderade sätt att implementera sådana mönster på ett testat, beprövat och underhållbart sätt.
Streamingintag
Traditionellt har Flume varit det rekommenderade systemet för strömmande intag. Dess stora bibliotek med källor och diskbänkar täcker alla grunder för vad man ska konsumera och var man ska skriva. (För information om hur du konfigurerar och hanterar Flume, Använda Flume , O'Reilly Media-boken av Cloudera Software Engineer/Flume PMC-medlem Hari Shreedharan, är en fantastisk resurs.)
Under det senaste året har Kafka också blivit populärt på grund av kraftfulla funktioner som uppspelning och replikering. På grund av överlappningen mellan Flumes och Kafkas mål är deras förhållande ofta förvirrande. Hur passar de ihop? Svaret är enkelt:Kafka är ett rör som liknar Flumes kanalabstraktion, om än ett bättre rör på grund av dess stöd för funktionerna som nämns ovan. Ett vanligt tillvägagångssätt är att använda Flume för källan och diskbänken, och Kafka för röret mellan dem.
Diagrammet nedan illustrerar hur Kafka kan fungera som UpStream-datakällan till Flume, DownStream-destinationen för Flume eller Flume-kanalen.
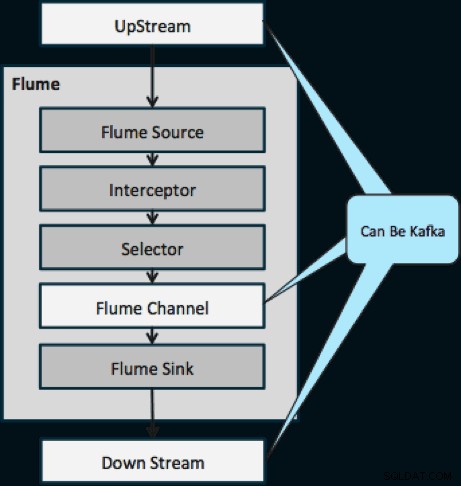
Designen som illustreras nedan är massivt skalbar, stridshärdad, centralt övervakad genom Cloudera Manager, feltolerant och stöder replay.
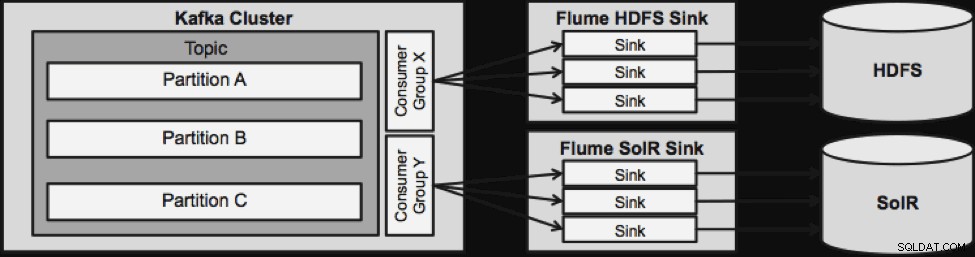
En sak att notera innan vi går till nästa strömmande arkitektur är hur denna design elegant hanterar misslyckanden. Flume Sinks drar från en Kafka Consumer Group. Konsumentgruppen spårar ämnets offset med hjälp av Apache ZooKeeper. Om en flamdisk försvinner kommer Kafka Consumer att omfördela lasten till de återstående diskbänkarna. När Flume Sink kommer upp igen kommer konsumentgruppen att distribuera igen.
NRT-händelsebearbetning med extern kontext
För att upprepa, ett vanligt användningsfall för detta mönster är att titta på händelser som strömmar in och fatta omedelbara beslut, antingen för att transformera data eller för att vidta någon form av extern åtgärd. Beslutslogiken beror ofta på externa profiler eller metadata. Ett enkelt och skalbart sätt att implementera detta tillvägagångssätt är att lägga till en Source- eller Sink Flume-interceptor till din Kafka/Flume-arkitektur. Med blygsam inställning är det inte svårt att uppnå latenser på låga millisekunder.
Flume Interceptors tar händelser eller partier av händelser och tillåter användarkod att modifiera eller vidta åtgärder baserat på dem. Användarkoden kan interagera med lokalt minne eller ett externt lagringssystem som HBase för att få profilinformation som behövs för beslut. HBase kan vanligtvis ge oss vår information på cirka 4-25 millisekunder beroende på nätverk, schemadesign och konfiguration. Du kan också ställa in HBase på ett sätt så att det aldrig är nere eller avbryts, inte ens vid fel.
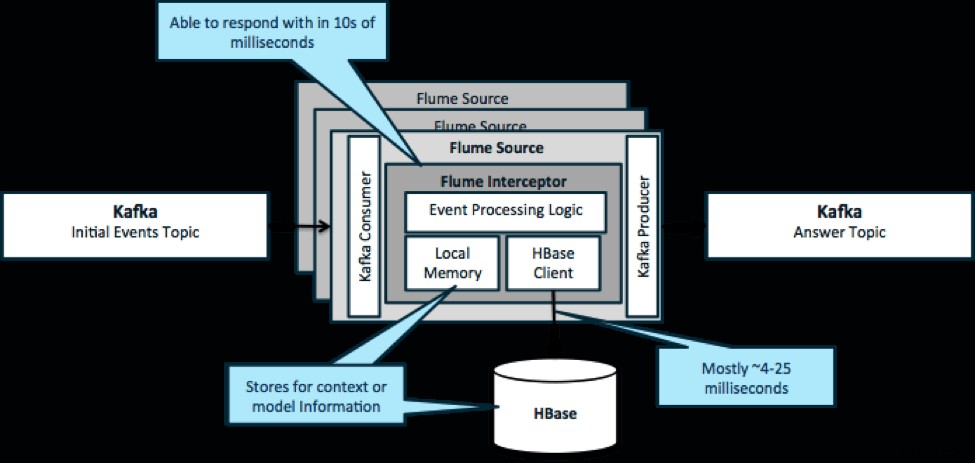
Implementering kräver nästan ingen kodning utöver den applikationsspecifika logiken i interceptorn. Cloudera Manager erbjuder ett intuitivt användargränssnitt för att distribuera denna logik genom paket samt koppla upp, konfigurera och övervaka tjänsterna.
NRT-partitionerad händelsebearbetning med extern kontext
I arkitekturen som illustreras nedan (opartitionerad lösning) skulle du behöva ringa ut ofta till HBase eftersom extern kontext som är relevant för särskilda händelser inte passar i det lokala minnet på Flume-interceptorerna.
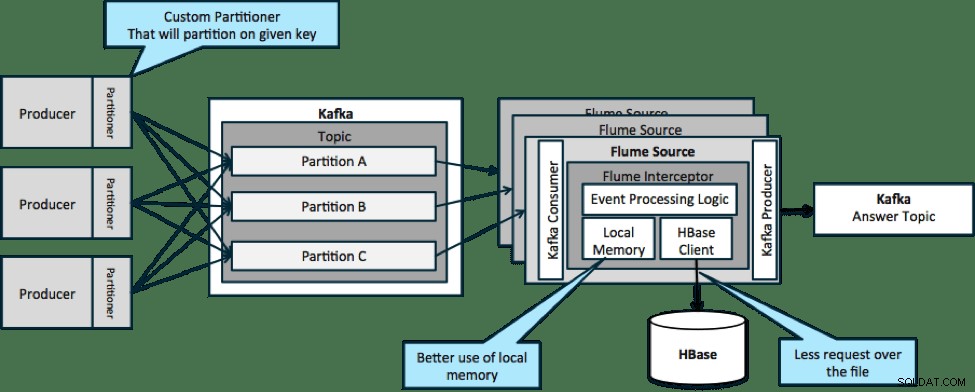
Men om du definierar en nyckel för att partitionera dina data kan du matcha inkommande data med den delmängd av kontextdata som är relevant för den. Om du partitionerar data 10 gånger behöver du bara ha kvar 1/10 av profilerna i minnet. HBase är snabb, men lokalt minne är snabbare. Kafka låter dig definiera en anpassad partitionerare som den använder för att dela upp dina data.
Observera att Flume inte är absolut nödvändigt här; rotlösningen här bara en Kafka-konsument. Så du kan bara använda en konsument i YARN eller en MapReduce-applikation som endast är en MapReduce.
Komplex topologi för aggregationer eller ML
Fram till denna punkt har vi undersökt verksamheten på händelsenivå. Men ibland behöver du mer komplexa operationer som räkningar, medelvärden, sessionisering eller maskininlärning som bygger på databatch. I det här fallet är Spark Streaming det perfekta verktyget av flera anledningar:
- Det är lätt att utveckla jämfört med andra verktyg. Sparks rika och koncisa API:er gör det enkelt att bygga ut komplexa topologier.
- Liknande kod för streaming och batchbearbetning. Med några få ändringar kan koden för små batcher i realtid användas för enorma batcher offline. Förutom att minska kodstorleken, minskar detta tillvägagångssätt den tid som krävs för testning och integration.
- Det finns en motor att känna till. Det finns en kostnad som går till att utbilda personalen i egenskaperna och interna delar av distribuerade processmotorer. Standardisering på Spark konsoliderar denna kostnad för både streaming och batch.
- Mikrobatchning hjälper dig skala på ett tillförlitligt sätt. Att kvittera på batchnivå möjliggör mer genomströmning och möjliggör lösningar utan rädsla för dubbelsändning. Mikrobatchning hjälper också till att skicka ändringar till HDFS eller HBase när det gäller prestanda i stor skala.
- Integration av Hadoop-ekosystem är inbakad. Spark har djup integration med HDFS, HBase och Kafka.
- Ingen risk för dataförlust. Tack vare WAL och Kafka undviker Spark Streaming dataförlust i händelse av fel.
- Det är lätt att felsöka och köra. Du kan felsöka och stega igenom din kod Spark Streaming i en lokal IDE utan ett kluster. Dessutom ser koden ut som normal funktionell programmeringskod så det tar inte mycket tid för en Java- eller Scala-utvecklare att ta steget. (Python stöds också.)
- Streaming är inbyggt tillståndsfullt. I Spark Streaming är staten en förstklassig medborgare, vilket betyder att det är lätt att skriva stateful streaming-applikationer som är motståndskraftiga mot nodfel.
- Som de facto standard får Spark långsiktiga investeringar från hela ekosystemet.
När detta skrivs fanns det cirka 700 commits till Spark som helhet under de senaste 30 dagarna – jämfört med andra strömmande ramverk som Storm, med 15 commits under samma tid. - Du har tillgång till ML-bibliotek.
Sparks MLlib blir enormt populär och dess funktionalitet kommer bara att öka. - Du kan använda SQL där det behövs.
Med Spark SQL kan du lägga till SQL-logik till din streamingapplikation för att minska kodkomplexiteten.
Slutsats
Det finns mycket kraft i streaming och flera möjliga mönster, men som du har lärt dig i det här inlägget kan du göra riktigt kraftfulla saker med minimal kodning om du vet vilket mönster som matchar ditt användningsfall bäst.
Ted Malaska är en lösningsarkitekt på Cloudera, en bidragsgivare till Spark, Flume och HBase, och en medförfattare till O'Reilly-boken, Hadoop Applications Architecture.