Med den växande komplexiteten i databasinställningar vänder sig många SysAdmins och DBA:er till ett agentlöst tillvägagångssätt för att underlätta bördan av databasövervakningsutmaningar. ClusterControls agentfria övervakning låter dig övervaka databaser utan att installera agentprogramvara på varje övervakat system. ClusterControl implementerar övervakning med hjälp av en fjärrdatainsamlare som använder SSH-protokollet.
Innan vi dyker rakt in i detaljerna kring agentfri övervakning, låt oss först klargöra omfattningen och innebörden av övervakning i vårt sammanhang här. Övervakning kommer efter datatrend – processen för insamling och lagring av mätvärden – vilket gör det möjligt för övervakningssystemet att bearbeta den insamlade informationen för att skapa motivering för justering, varning och visning av trenddata för rapportering.
Från och med version 1.7.0 (släppt december 2018) stöder ClusterControl två övervakningsmetoder:
- Agentless övervakning (standard)
- Agentbaserad övervakning med Prometheus
Det här inlägget kommer att gå igenom hur du övervakar dina databasservrar och kluster med ClusterControls agentfria övervakning. Om du letar efter mer information om ClusterControls agentbaserade övervakning kan du hänvisa till den här dokumentationen.
I allmänhet utför ClusterControl agentfria övervaknings-, varnings- och trenduppgifter med följande tre metoder:
- SSH – Insamling av värdstatistik (process, statistik för belastningsbalanserare, resursanvändning, förbrukning, etc.) med hjälp av SSH-bibliotek
- Databasklient – Insamling av databasstatistik (status, frågor, variabler, användning, etc.) med hjälp av respektive databasklientbibliotek
- Rådgivare – Miniprogram skrivna med ClusterControl DSL och körs i själva ClusterControl för övervakning, justering och varningsändamål
SSH står för Secure Shell, ett säkert nätverksprotokoll som används av de flesta Linux-baserade servrar för fjärradministration. ClusterControl Controller, eller CMON, är backend-tjänsten som utför automations-, hanterings-, övervaknings- och schemaläggningsuppgifter, byggd ovanpå C++.
ClusterControl DSL (Domain Specific Language) låter dig utöka funktionaliteten för din ClusterControl-plattform genom att skapa rådgivare, autotuners eller "miniprogram." DSL-syntaxen är baserad på JavaScript, med tillägg för att ge tillgång till ClusterControls interna datastrukturer och funktioner. DSL låter dig köra SQL-satser, köra skalkommandon/program över alla dina klustervärdar och hämta resultat som ska bearbetas för rådgivare/varningar eller andra åtgärder.
Övervakningsverktyg
Alla nödvändiga verktyg uppfylls av installationsskriptet eller installeras automatiskt av ClusterControl under databasens distributionsskede eller om den nödvändiga filen/binären/paketet inte finns på målservern innan ett jobb körs. Generellt sett kräver ClusterControl-övervakningsplikt endast OpenSSH-serverpaket på de övervakade värdarna. ClusterControl använder libssh-klientbibliotek för att samla in värddata för de övervakade värdarna – CPU, minne, disk, nätverk, IO, process, etc. OpenSSH-klientpaket krävs på ClusterControl-värden endast för att ställa in lösenordslös SSH och felsökningsändamål. Andra SSH-implementationer som Dropbear och TinySSH stöds inte.
När databasstatistik och mätvärden samlas in ansluter ClusterControl Controller (CMON) till databasservern direkt via databasklientbibliotek – libmysqlclient (MySQL/MariaDB och ProxySQL), libpq (PostgreSQL) och libmongocxx (MongoDB) ). Det är därför det är viktigt att ställa in korrekta privilegier för en ClusterControl-server ur en databasservers perspektiv. För MySQL-baserade kluster kräver ClusterControl databasanvändaren "cmon" medan för andra databaser kan vilket användarnamn som helst användas för övervakning, så länge det ges superanvändarprivilegier. För det mesta kommer ClusterControl att ställa in de nödvändiga privilegierna (eller använda den angivna databasanvändaren) automatiskt under klusterimporten eller klusterdistributionen.
ClusterControl kräver följande verktyg för lastbalanserare:
- Maxctrl på MariaDB MaxScale-servern
- netcat och/eller socat på HAProxy-servern för att ansluta till HAProxy-socket-filen och hämta övervakningsdata
- ProxySQL kräver en mysql-klient på ProxySQL-servern
Följande diagram illustrerar både värd- och databasövervakningsprocesser som exekveras av ClusterControl med hjälp av libssh- och databasklientbibliotek:
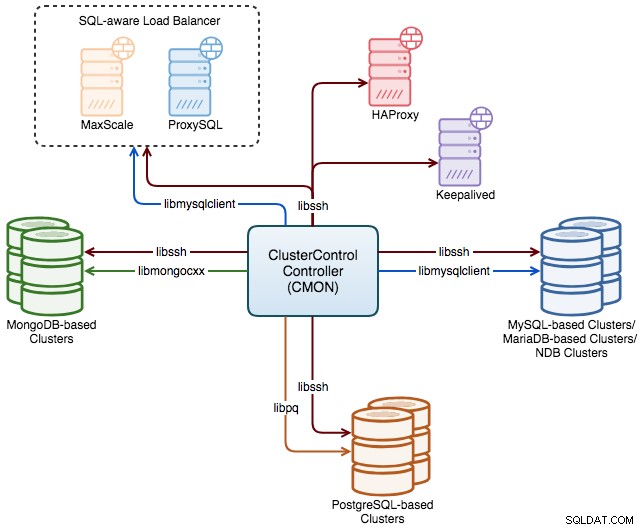
Även om övervakningstrådar inte behöver databasklientpaket installerade på den övervakade värden, det rekommenderas starkt att ha dem för förvaltningsändamål. Till exempel kommer MySQL-klientpaketet med mysql, mysqldump, mysqlbinlog och mysqladmin-program, som kommer att användas av ClusterControl vid säkerhetskopiering och punkt-i-tid återställning.
Övervakningsmetoder
För insamling av värd- och lastbalanseringsstatistik, utför ClusterControl den här uppgiften via SSH med superanvändarbehörighet. Därför är lösenordslös SSH med superanvändarbehörighet avgörande för att ClusterControl ska kunna köra de nödvändiga kommandona på distans med korrekt eskalering. Med denna pull-metod finns det ett par fördelar jämfört med andra mekanismer:
- Agentless – Det finns inget behov av att en agent installeras, konfigureras och underhålls.
- Enhet av hanterings- och övervakningskonfigurationen – SSH kan användas för att hämta övervakningsstatistik eller pusha hanteringsjobb på målnoderna.
- Förenkla implementeringen – Det enda kravet är korrekt lösenordslös SSH-inställning, och det är allt. SSH är också mycket säkert och krypterat.
- Centraliserad installation – En ClusterControl-server kan hantera flera servrar och kluster, förutsatt att den har tillräckliga resurser.
Däremot har dragmekanismen också följande nackdelar:
- Övervakningsdata är endast korrekt ur ClusterControls perspektiv. Till exempel, om det finns ett nätverksfel och ClusterControl förlorar kommunikationen till den övervakade värden, kommer samplingen att hoppas över till nästa tillgängliga cykel.
- Det kommer att finnas nätverksoverhead för övervakning med hög granularitet på grund av ökad samplingsfrekvens där ClusterControl behöver upprätta fler anslutningar till varje målvärd.
- ClusterControl kommer att fortsätta att försöka återupprätta anslutningen till målnoden eftersom den inte har någon agent som kan göra detta åt dess räkning.
- Redundant datasampling om du har mer än en ClusterControl-server som övervakar ett kluster eftersom varje ClusterControl-server måste hämta övervakningsdata för sig själv.
För MySQL-frågeövervakning, från och med ClusterControl 1.9.0 (släppt juli 2021), stöder ClusterControl två typer:
- Agentless frågeövervakning (standard)
- Agentbaserad frågeövervakning med CMON-frågeagent, vilket kräver ytterligare steg för att aktivera det. Endast för MySQL-baserade och PostgreSQL-baserade databaser.
Agentless query monitoring övervakar frågorna på två olika sätt:
- Frågor hämtas från PERFORMANCE_SCHEMA genom att fråga schemat på databasnoden via SSH.
- Om PERFORMANCE_SCHEMA är inaktiverat eller otillgängligt kommer ClusterControl att analysera innehållet i den långsamma frågeloggen via SSH.
Om Performance Schema är aktiverat kommer ClusterControl att använda det för att leta efter långsamma frågor. Annars kommer ClusterControl att analysera innehållet i MySQL långsamma frågelogg (via slow_query_log=ON dynamisk variabel) baserat på följande flöde:
- Starta långsam logg (under MySQL-körning).
- Kör den under en kort tid (en sekund eller ett par sekunder).
- Stopplogg.
- Parse log.
- Trunkera logg (ny loggfil).
- Gå till 1.
De insamlade frågorna hashas, beräknas och sammanfattas (normalisera, genomsnitt, räkna, sortera) och lagras sedan i CMON-databasen ClusterControl. Observera att för denna samplingsmetod finns det en liten chans att vissa frågor inte kommer att fångas upp, särskilt under delarna "stopplogg, parselogg, trunkering av logg". Du kan aktivera Performance Schema om detta inte är ett alternativ.
Endast frågor som överskrider den långa frågetiden kommer att listas här med hjälp av långsam frågelogg. Anta att uppgifterna inte är korrekt ifyllda och du tror att det borde finnas något där, kan det vara så att antingen:
- ClusterControl samlade inte in tillräckligt med frågor för att sammanfatta och fylla i data. Försök att minska den långa frågetiden.
- Du har konfigurerat konfigurationsalternativ för långsam frågelogg i my.cnf på MySQL-servern, och Åsidosätt lokal fråga är avstängd. Om du verkligen vill använda värdet du definierade i my.cnf, måste du förmodligen sänka long_query_time-värdet så att ClusterControl kan beräkna ett mer exakt resultat.
- Du har en annan ClusterControl-nod som också drar Slow Query-loggen (om du har en standby ClusterControl-server). Tillåt endast en ClusterControl-server att göra det här jobbet.
Du kan också använda ClusterControl Query Monitor för MySQL, MariaDB och Percona Server.
För PostgreSQL-frågeövervakning kräver ClusterControl modulen pg_stat_statements för att spåra exekveringsstatistik för alla SQL-satser. Den fyller pg_stat_statements vyer och funktioner när frågorna visas i användargränssnittet (under fliken Query Monitor).
Intervaller och timeouts
ClusterControl Controller (cmon) är en flertrådad process. Som standard ansluter ClusterControl Controllers samplingstråd till varje övervakad värd en gång och upprätthåller en beständig anslutning tills värden släpper eller kopplar från vid sampling av värdstatistik. Det kan skapa fler anslutningar beroende på de jobb som tilldelats värden eftersom de flesta av hanteringsjobben körs i sin egen tråd. Till exempel körs klusteråterställning på återställningstråden, Advisor-exekvering körs på en cron-tråd och processövervakning körs på processinsamlartråden.
ClusterControl-övervakningstråden utför följande samplingsoperationer i följande intervall:
- MySQL-fråga/statusstatistik:varje sekund
- Processinsamling (/proc):var 10:e sekund
- Serverdetektering:var tionde sekund
- Värdstatistik (/proc, /sys):var 30:e sekund (kan konfigureras via host_stats_collection_interval)
- Databasstatistik (endast PostgreSQL och MongoDB):var 30:e sekund (konfigurerbar via db_stats_collection_interval)
- Databasschemastatistik:var tredje timme (kan konfigureras via db_schema_stats_collection_interval)
- Belastningsbalansmätvärden:var 15:e sekund (konfigurerbar via lb_stats_collection_interval)
De imperativa skripten (rådgivare) kan använda SSH- och databasklientbibliotek som följer med CMON med följande begränsningar:
- 5 sekunders hård gräns för SSH-körning.
- 10 sekunders standardgräns för databasanslutning, konfigurerbar via net_read_timeout, net_write_timeout, connect_timeout i CMON-konfigurationsfilen.
- 60 sekunder av den totala skriptexekveringstiden innan CMON fult avbryter det.
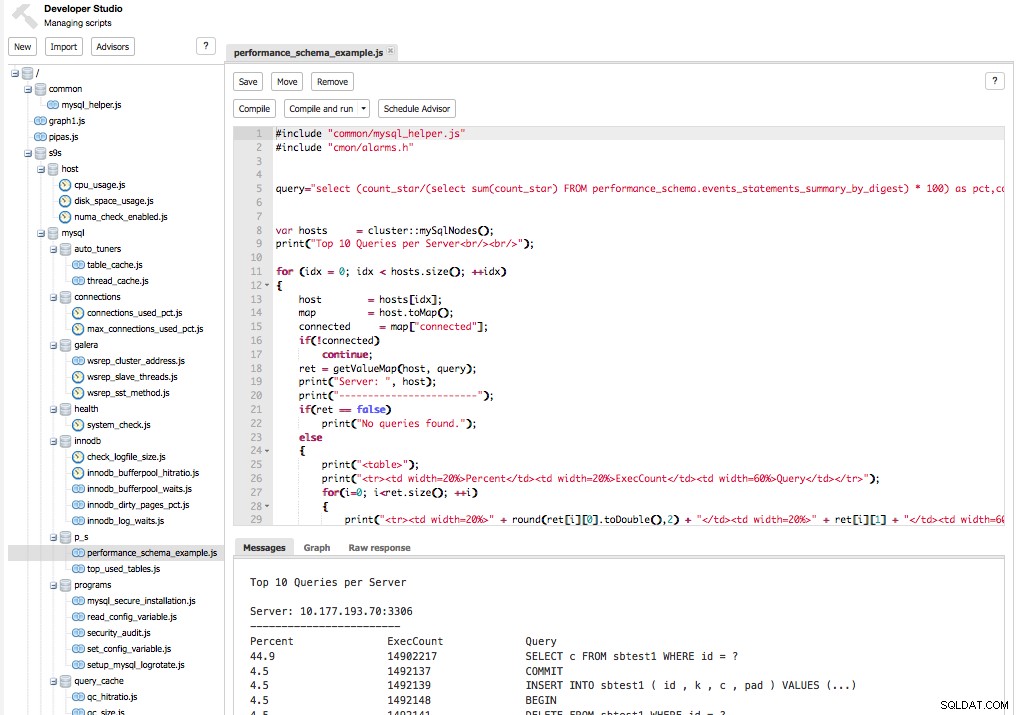
Rådgivare kan skapas, kompileras, testas och schemaläggas direkt från ClusterControls användargränssnitt under Manage → Developer Studio . Följande skärmdump visar ett exempel på en rådgivare för att extrahera topp 10 frågor från PERFORMANCE_SCHEMA:
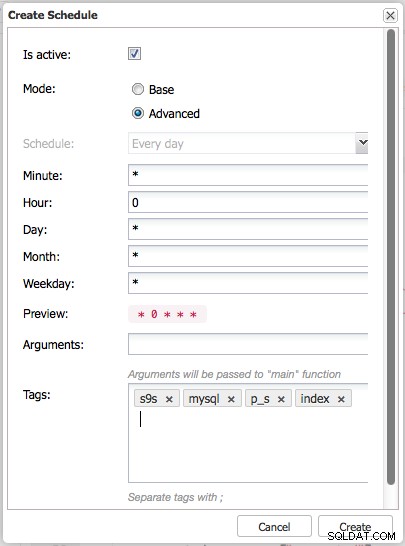
Utförandet av rådgivare beror på om det är aktiverat och schemaläggningstiden i cron-format:
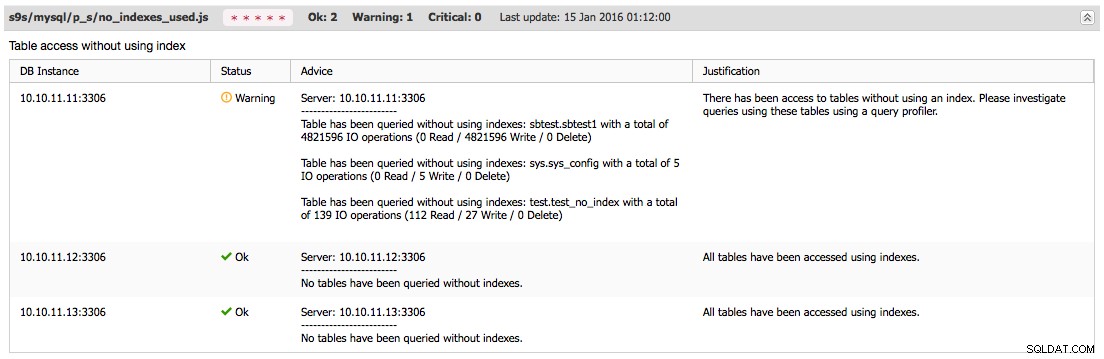
Resultaten av körningen visas under Prestanda → Rådgivare , som visas i följande skärmdump:
För mer information om vilka rådgivare som tillhandahålls som standard, kolla in vår utvecklare Studio produktsida.
Data lagras direkt i CMON-databasen för kortintervallsövervakningsdata som MySQL-frågor och status. Övervakningsdata med långa intervaller som veckovisa/månatliga/årliga datapunkter aggregeras var 60:e sekund och lagras i minnet i 10 minuter. Dessa beteenden är inte konfigurerbara på grund av arkitekturens design.
Parametrar
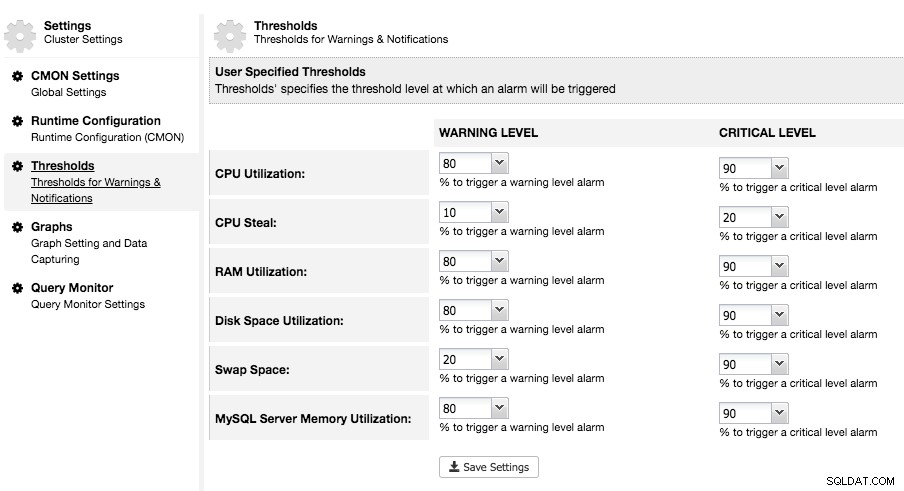
ClusterControl har många parametrar som passar din övervaknings- och varningspolicy. De flesta av dem är konfigurerbara via ClusterControl UI → välj ett kluster → Inställningar . Fliken "Inställningar" ger många alternativ för att konfigurera varningar, trösklar, meddelanden, graflayout, databasräknare, frågeövervakning och så vidare. Till exempel kan varningar och kritiska trösklar konfigureras enligt följande:
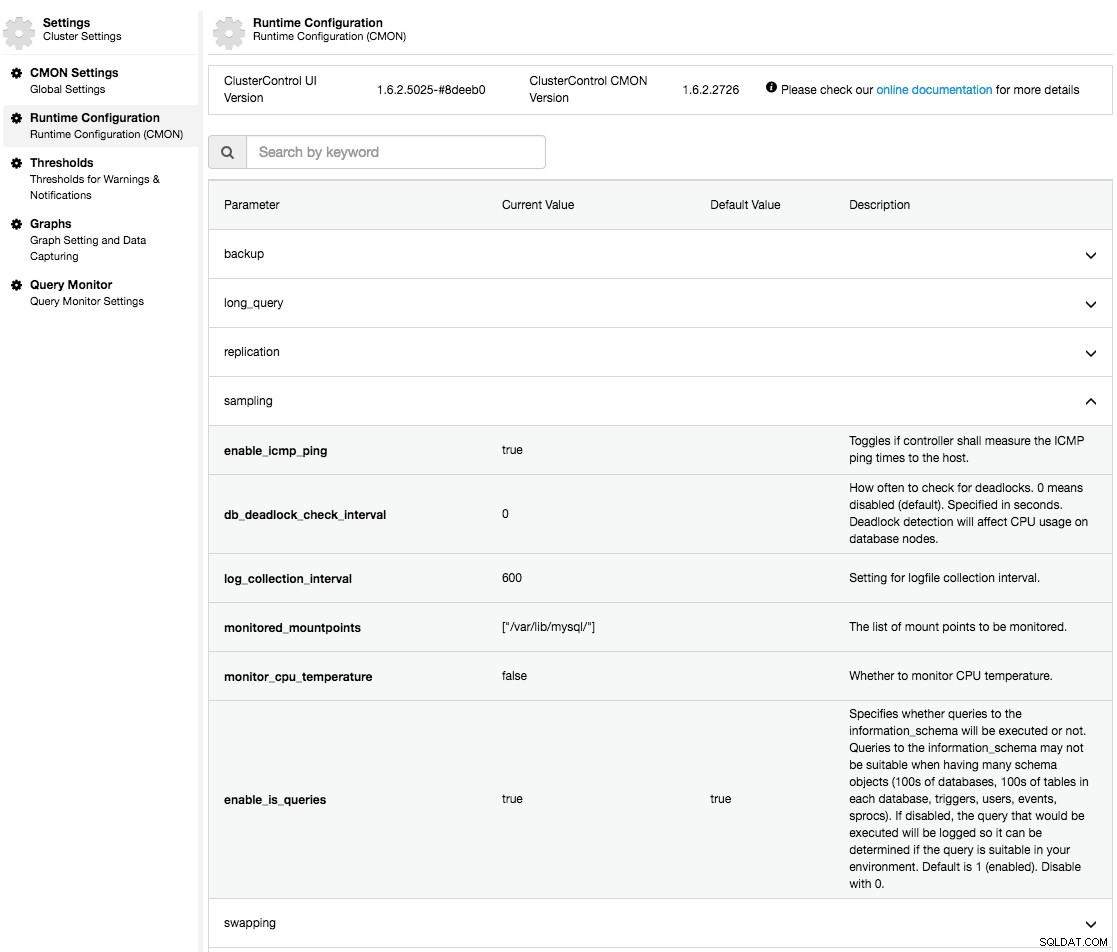
sidan "Runtime Configuration" visar en sammanfattad lista över den aktiva ClusterControl Controller (CMON) körtidskonfigurationsparametrar:
Det finns mer än 170 ClusterControl Controller-konfigurationsalternativ totalt, och några av de avancerade inställningarna kan konfigureras övervakning och varningspolicy finjustering. Några av dessa inkluderar:
- monitor_cpu_temperature
- swap_warning
- swap_critical
- redobuffer_warning
- redobuffer_critical
- indexmemory_warning
- indexmemory_critical
- datamemory_warning
- datamemory_critical
- tablespace_warning
- tablespace_critical
- redolog_warning
- redolog_critical
- max_replication_lag
- long_query_time
- log_queries_not_using_indexes
- query_monitor_use_local_settings
- enable_query_monitor
- enable_query_monitor_auto_purge_ps
Du kan ändra parametrarna som listas på sidan "Runtime Configuration" genom att antingen använda UI- eller CMON-konfigurationsfilen som finns på /etc/cmon.d/cmon_X.cnf, där X är kluster-ID. Du kan lista ut alla konfigurationsalternativ som stöds för CMON genom att använda följande kommando:
$ cmon --help-configSluta tankar
Agentless övervakning har blivit en av de mest effektiva metoderna för att hantera allt mer komplexa databasinfrastrukturer. Det minskar bördan av många utmaningar i samband med databasövervakning och är lätt att hantera.
Det finns många agentfria övervakningsverktyg tillgängliga idag. Men inte många av dem erbjuder också en komplett plattform full av funktioner som hjälper dig att hantera alla andra aspekter av dina databaskluster. För att se vad mer ClusterControl kan göra, se till att ladda ner din egen kostnadsfria 30-dagars testversion.
Letar du efter ett agentbaserat alternativ till databasövervakning? Kolla in ClusterControls agentbaserade databasövervakningsinfrastruktur – SCUMM.