Läs mer om arkitekturen för nästan realtidsdataintag för att transformera och berika dataströmmar med Apache Flume, Apache Kafka och RocksDB i Santander UK.
Cloudera Professional Services har arbetat med Santander UK för att bygga ett nästan realtid (NRT) transaktionsanalyssystem på Apache Hadoop. Målet är att fånga, transformera, berika, räkna och lagra en transaktion inom några sekunder efter att ett kortköp äger rum. Systemet tar emot bankens korttransaktioner för privatkunder och beräknar tillhörande trendinformation aggregerad av kontoinnehavare och över ett antal dimensioner och taxonomier. Denna information skickas sedan säkert till Santanders "Spendlytics"-app (se nedan) för att göra det möjligt för kunder att analysera sina senaste utgiftsmönster.
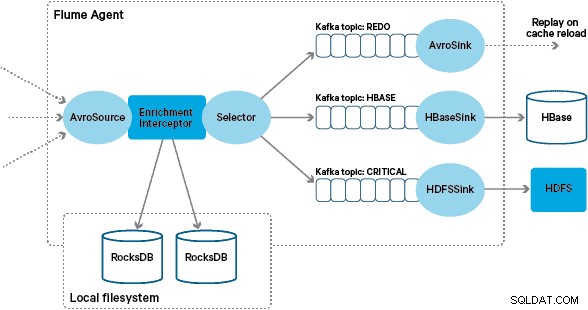
Apache HBase valdes som den underliggande lagringslösningen på grund av dess förmåga att stödja slumpmässiga skrivningar med hög genomströmning och slumpmässiga läsningar med låg latens. NRT-kravet uteslöt dock att utföra transformationer och berikning av transaktionerna i batch, så dessa måste göras medan transaktionerna strömmas in i HBase. Detta inkluderar att förvandla meddelanden från XML till Avro och berika dem med trendvänlig information, som varumärkes- och säljarinformation.
Det här inlägget beskriver hur Santander använder Apache Flume, Apache Kafka och RocksDB för att transformera, berika och strömma transaktioner till HBase. Detta är en implementering av NRT Event Processing with External Context strömmande mönster som beskrivs av Ted Malaska i det här inlägget.
Flafka
Det första beslutet Santander var tvungen att fatta var hur man bäst strömmade data till HBase. Flume är nästan alltid det bästa valet för att streama intag i Hadoop med tanke på dess enkelhet, tillförlitlighet, rika utbud av källor och sänkor och inneboende skalbarhet.
Nyligen har utmärkt integration till Kafka lagts till, vilket leder till den oundvikligen namngivna Flafka. Flume kan tillhandahålla garanterad händelseleverans genom sin filkanal, men möjligheten att spela upp händelser och den extra flexibiliteten och framtidssäkran Kafka ger var nyckeldrivkrafterna för integrationen.
I den här arkitekturen använder Santander Kafka-kanaler för att tillhandahålla en pålitlig, självbalanserande och skalbar intagsbuffert där alla transformationer och bearbetning är representerade i kedjade Kafka-ämnen. I synnerhet använder vi i stor utsträckning Flafkas källa och sänka, och Flumes förmåga att utföra bearbetning under flygning med interceptorer. Detta hindrade oss från att behöva koda vår egen Kafka-producent och konsument, och gjorde det möjligt för Santander att dra full nytta av Cloudera Manager för att konfigurera, distribuera och övervaka agenterna och mäklarna.
Transformation
Transaktioner som fångas upp av kärnbankssystemen levereras till Flume som XML-meddelanden, efter att ha lästs från källdatabasen via loggreplikering. (Att anpassa en databaslogg till Kafka-ämnen på detta sätt är ett allt vanligare mönster och i kombination med loggkomprimering kan det ge en "senaste vy" av databasen för användningsfall för ändring av datafångst.)
Flume lagrar dessa XML-meddelanden i ett "rå" Kafka-ämne. Härifrån, och som en föregångare till all annan bearbetning, beslutades att omvandla den semistrukturerade XML-en till strukturerade binära poster för att underlätta standardiserad nedströmsbehandling. Denna bearbetning utförs av en anpassad Flume Interceptor som omvandlar XML-meddelanden till en generisk Avro-representation, som tillämpar specifika typer där så är lämpligt och faller tillbaka till en strängrepresentation där det inte är fallet. All efterföljande NRT-bearbetning lagrar sedan härledda resultat i Avro i dedikerade Kafka-ämnen, vilket gör det enkelt att ta del av strömmen och få ett händelseflöde när som helst i bearbetningskedjan.
Om mer komplex händelsebearbetning krävdes – till exempel aggregering med Spark Streaming – skulle det vara en trivial fråga att konsumera ett eller flera av dessa ämnen och publicera till nya härledda ämnen. (Apache Avro är ett naturligt val för detta format:det är ett kompakt binärt protokoll som stöder schemautveckling, har en flexibel schemadefinition och stöds i hela Hadoop-stacken. Avro håller snabbt på att bli en de facto-standard för interim och allmän datalagring i ett företagsdatanav och är perfekt placerat för omvandling till Apache Parquet för analytiska arbetsbelastningar.)
Berikning
Inspirationen till designen av strömningsanrikningslösningen kom från ett O’Reilly Radar-inlägg skrivet av Jay Kreps. I sitt inlägg beskriver Jay fördelarna med att använda en lokal butik för att göra det möjligt för en strömprocessor att fråga eller ändra en lokal stat som svar på dess input, i motsats till att ringa fjärranrop till en distribuerad databas.
På Santander anpassade vi detta mönster för att tillhandahålla lokala referensbutiker som används för att fråga och berika transaktioner när de strömmar genom Flume. Varför inte bara använda HBase som referensbutik? Tja, ett typiskt mönster för den här typen av problem är att helt enkelt lagra tillståndet i HBase och låta anrikningsmekanismen fråga den direkt. Vi beslutade oss för detta tillvägagångssätt av ett par anledningar. För det första är referensdatan relativt liten och skulle passa in i en enda HBase-region, vilket troligen orsakar en region-hotspot. För det andra betjänar HBase den kundinriktade Spendlytics-appen och Santander ville inte att den extra belastningen skulle påverka applatensen, eller vice versa. Detta är också anledningen till att vi beslutade att inte använda HBase för att ens starta upp de lokala butikerna vid start.
Så genom att förse varje Flume Agent med en snabb lokal butik för att berika evenemang under flygning, kan Santander ge bättre prestandagarantier för både anrikning under flygning och Spendlytics-appen. Vi bestämde oss för att använda RocksDB för att implementera de lokala butikerna eftersom det kan ge snabb åtkomst till stora mängder off-heap data (eliminerar bördan på GC), och det faktum att den har ett Java API för att göra det lättare att använda från en anpassad Flume Interceptor. Detta tillvägagångssätt räddade oss från att behöva koda vår egen off-heap-butik. RocksDB kan enkelt bytas ut mot en annan lokal butiksimplementering, men i det här fallet passade det perfekt för Santanders användningsfall.
Den anpassade implementeringen av Flume enrichment Interceptor bearbetar händelser från det uppströms "transformerade" ämnet, frågar sin lokala butik för att berika dem och skriver resultaten till nedströms Kafka-ämnen beroende på resultatet. Denna process illustreras mer i detalj nedan.
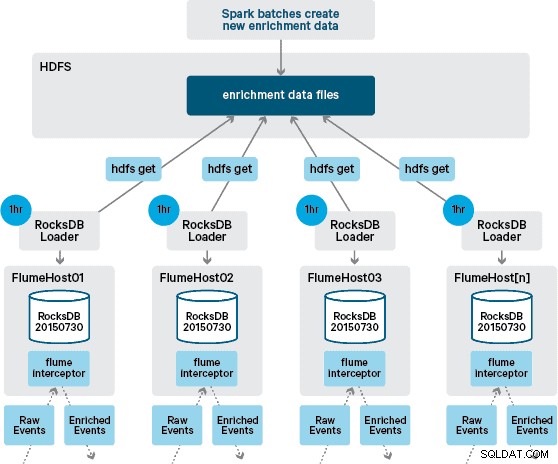
Vid det här laget undrar du kanske:Hur genereras lokala butiker utan HBase-försedd beständighet? Referensdatan består av ett antal olika datauppsättningar som måste sammanfogas. Dessa datauppsättningar uppdateras i HDFS dagligen och utgör indata till en schemalagd Apache Spark-applikation, som genererar RocksDB-butikerna. Nygenererade RocksDB-butiker placeras i HDFS tills de laddas ner av Flume Agents för att säkerställa att händelseströmmen berikas med den senaste informationen.
Helst skulle vi inte behöva vänta på att alla dessa datauppsättningar är tillgängliga i HDFS innan de kunde bearbetas. Om så var fallet skulle referensdatauppdateringar kunna strömmas genom Flafka pipeline för att kontinuerligt upprätthålla det lokala referensdatatillståndet.
I vår första design hade vi planerat att skriva och schemalägga ett skript via cron för att polla HDFS för att leta efter nya versioner av RocksDB-butikerna, ladda ner dem från HDFS när de är tillgängliga. Även om på grund av de interna kontrollerna och styrningen av Santanders produktionsmiljöer, var denna mekanism tvungen att integreras i samma Flume Interceptor som används för att utföra anrikningen (den söker efter uppdateringar en gång i timmen, så det är inte en dyr operation). När en ny version av butiken är tillgänglig skickas en uppgift till en arbetstråd för att ladda ner den nya butiken från HDFS och ladda den i RocksDB. Denna process sker i bakgrunden medan anrikningsinterceptorn fortsätter att bearbeta strömmen. När den nya versionen av butiken har laddats in i RocksDB växlar Interceptor till den senaste versionen och den utgångna butiken raderas. Samma mekanism används för att starta RocksDB-butikerna från en kallstart innan Interceptor börjar försöka berika händelser.
Framgångsrikt berikade meddelanden skrivs till ett Kafka-ämne för att idempotent skrivas till HBase med hjälp av HBaseEventSerializer.
Medan händelseströmmen bearbetas kontinuerligt, kan nya versioner av den lokala butiken endast genereras dagligen. Omedelbart efter att en ny version av den lokala butiken har laddats upp av Flume anses den vara fräsch”, även om den blir allt mer inaktuell innan en ny version finns tillgänglig. Följaktligen ökar antalet "cachemissar" tills en nyare version av den lokala butiken är tillgänglig. Till exempel kan ny och uppdaterad varumärkes- och handelsinformation läggas till referensdatan, men tills den görs tillgänglig för Flumes anrikning kan Interceptor-transaktioner misslyckas med att berikas, eller berikas med inaktuell information som senare måste avstämt efter att det har bevarats i HBase.
För att hantera det här fallet skrivs cachemissar (händelser som inte kan berikas) till ett "gör om" Kafka-ämne med hjälp av en Flume Selector. Ämnet om göra om spelas sedan upp igen i anrikningsinterceptorns källämne när en ny lokal butik är tillgänglig.
För att förhindra "giftmeddelanden" (händelser som kontinuerligt misslyckas med berikning), bestämde vi oss för att lägga till en räknare till en händelses header innan vi lägger till den i redo-ämnet. Händelser som uppträder upprepade gånger om det ämnet omdirigeras så småningom till ett "kritiskt" ämne, som skrivs till HDFS för senare inspektion och åtgärdande. Detta tillvägagångssätt illustreras i det första diagrammet.
Slutsats
För att sammanfatta de viktigaste punkterna från det här inlägget:
- Att använda en kedja av Kafka-ämnen för att lagra mellanliggande delad data som en del av din inmatningspipeline är ett effektivt mönster.
- Du har flera alternativ för att bevara och fråga om tillstånd eller referensdata i din NRT-inmatningspipeline. Föredrag HBase för detta ändamål som det vanliga mönstret när tilläggsdata är stor, men överväg användningen av inbäddade lokala butiker (som RocksDB) eller JVM-minne för när du använder HBase är inte praktiskt.
- Fejlhantering är viktig. (Se #1 för hjälp med det.)
I ett uppföljande inlägg kommer vi att beskriva hur vi använder HBase-samprocessorer för att tillhandahålla per kund aggregering av historiska inköpstrender, och hur offlinetransaktioner bearbetas i batch med hjälp av (Cloudera Labs-projekt) SparkOnHBase (som nyligen togs in i HBase trunk). Vi kommer också att beskriva hur lösningen utformades för att möta kundens krav på hög tillgänglighet över datacenter.
James Kinley, Ian Buss och Rob Siwicki är lösningsarkitekter på Cloudera.