Detta är del 2 i den här bloggserien. Du kan läsa del 1 här: Digital transformation är en dataresa från kant till insikt
Denna bloggserie följer tillverknings-, drift- och försäljningsdata för en ansluten fordonstillverkare när data går igenom stadier och transformationer som vanligtvis upplevs i ett stort tillverkningsföretag i framkanten av nuvarande teknologi. Den första bloggen introducerade ett falskt anslutet fordonstillverkningsföretag, The Electric Car Company (ECC), för att illustrera tillverkningsdatavägen genom datalivscykeln. För att åstadkomma detta använder ECC Cloudera Data Platform (CDP) för att förutsäga händelser och för att få en uppifrån-och-ned-vy av bilens tillverkningsprocess inom dess fabriker över hela världen.
Efter att ha slutfört steget för datainsamling i föregående blogg, är ECC:s nästa steg i datalivscykeln Databerikning. ECC kommer att berika insamlad data och göra den tillgänglig för att användas i analys och modellskapande senare i datalivscykeln. Nedan finns hela uppsättningen av steg i datalivscykeln, och varje steg i livscykeln kommer att stödjas av ett dedikerat blogginlägg (se fig. 1):
- Datainsamling – dataintag och övervakning vid kanten (oavsett om kanten är industriella sensorer eller människor i ett fordonsutställningsrum)
- Databerikning – bearbetning, aggregering och hantering av datapipeline för att göra data redo för vidare analys
- Rapportering – leverera affärsinsikt (försäljningsanalys och prognoser, budgetering som exempel)
- Visning – kontrollera och driva väsentlig affärsverksamhet (återförsäljarverksamhet, produktionsövervakning)
- Predictive Analytics – prediktiv analys baserad på AI och maskininlärning (prediktivt underhåll, efterfrågebaserad lageroptimering som exempel)
- Säkerhet och styrning – en integrerad uppsättning säkerhets-, förvaltnings- och styrtekniker över hela datalivscykeln

Fig. 1 Företagsdatalivscykeln
Databerikande utmaning
ECC behöver en heltäckande överblick och gedigen förståelse för all data som är relaterad till tillverkningen, återförsäljarens verksamhet och transport av deras fordon. De måste också snabbt identifiera problem med data, till exempel driftsensorer som avger data som kan inkludera falska temperaturspikar orsakade av oplanerade maskinstopp eller plötsliga uppstarter. Data som inte har något samband med processen när underhållsarbetare tar bort en sensor från en syradoppningstank under rutininspektioner, till exempel, bör inte beaktas i analysen.
Dessutom står ECC inför följande datautmaningar som måste lösas för att framgångsrikt flytta motortillverkningen genom dess leveranskedja. Dessa datautmaningar inkluderar följande:
- Hämta data i olika format från olika källor: Datateknikpipelines kräver att data tas in från olika källor och i många olika format. Oavsett om data hämtas från sensorer som sitter på produktionslinjen, som stödjer tillverkningsoperationer eller ERP-data som styr försörjningskedjan, måste allt sammanföras för vidare analys.
- Filtrera bort redundant eller irrelevant data: Att ta bort dubbletter eller ogiltiga data och säkerställa att återstående data är korrekta är ett nyckelsteg för att förbereda data för vidare användning i avancerad prediktiv analys.
- Förmåga att identifiera ineffektiva processer: ECC kräver förmågan att se vilka dataprocesser som tar mest tid och resurser, vilket gör det enkelt att rikta in sig på underpresterande delar av pipelinen för att påskynda den övergripande processen.
- Förmåga att övervaka alla processer från en enda ruta: ECC kräver ett centraliserat system som tillåter dem att övervaka alla pågående dataprocesser samt en möjlighet att utöka sin nuvarande infrastruktur samtidigt som transparensen bibehålls.
Utvalda datauppsättningar av hög kvalitet är ryggraden i alla avancerade analysinitiativ. För att uppnå detta måste ett ramverk för datateknik användas för att tillåta byggandet av alla rör och rörsystem som behövs för att flytta, manipulera och hantera data för de olika fordonsdelarna i datalivscykeln.
Bygga en pipeline med Cloudera Data Engineering
Innan data berikas och diskuteras i den första bloggen kommer IT- och OT-dataströmmar som samlats in från fabriken att rengöras, manipuleras och modifieras. Fabriks-ID, maskin-ID, tidsstämpel, artikelnummer och serienummer kan fångas från en QR-kod som är tryckt på elmotorn. När motorn monteras i det anslutna fordonet, samlas data in som modelltyp, VIN och basfordonskostnad.
Efter att fordonet har sålts registreras försäljningsinformationen som kundnamn, kontaktinformation, slutligt försäljningspris och kundplats separat. Dessa uppgifter kommer att vara avgörande för att kontakta kunden för eventuella återkallelser eller riktat förebyggande underhåll. Geolokaliseringsdata lagras också, vilket kommer att hjälpa till att kartlägga kundernas platser till latituder och longituder för att bättre förstå var dessa motorer finns efter att ha sålts i ett fordon.
ECC kommer att använda Cloudera Data Engineering (CDE) för att hantera ovanstående datautmaningar (se fig. 2). CDE kommer sedan att göra data tillgänglig för Cloudera Data Warehouse (CDW), där den kommer att göras tillgänglig för avancerade analyser och rapporter om affärsintelligens. CDE-stegen beskrivs nedan.
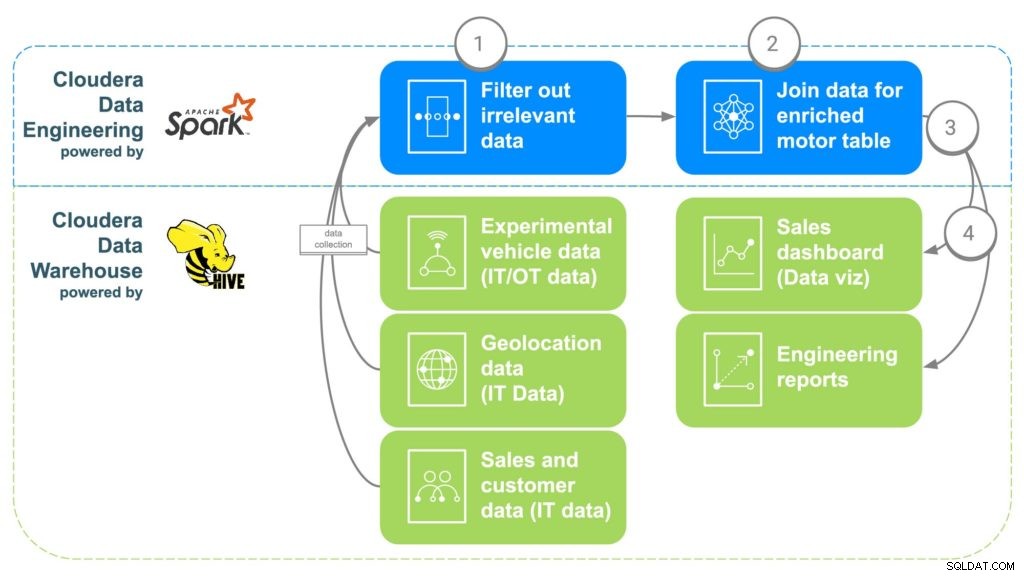
Fig. 2 ECC-dataanrikningspipeline
STEG 1:Filtrera och separera data
Det första steget i att använda CDE är att skapa ett PySpark-jobb som tar in data från dessa olika "råa" källor från steg 1. Detta är en möjlighet att filtrera all irrelevant data som till exempel kunder under 16 år eftersom det är vanligtvis minimiåldern för körning. Dubblettdata och annan irrelevant data kan också filtreras eller separeras bort.
STEG 2:Kombinera data
För att kombinera all data kommer CDE att korrelera gemensamma länkar. Först kommer bilförsäljningsdata att knytas till kunden som köpt bilen för att få kundens metadata, såsom kontaktuppgifter, ålder, lön etc. Geolokaliseringsdata kommer sedan att användas för att få mer exakt platsinformation för kunden , vilket kommer att hjälpa till att kartlägga motorerna senare. Delinstallationsdata kommer att användas för att identifiera serienumren för varje motor som installerades i kundens bil. Slutligen kommer fabriksdata att justeras för att matcha motorns serienummer som identifierar vilken fabrik, maskin och när varje specifik motor skapades.
STEG 3:Skicka data till Cloudera Data Warehouse
När all data väl har samlats i en berikad tabell kommer ett enkelt Apache Spark-kommando att skriva data till en ny tabell i Cloudera Data Warehouse. Detta kommer att göra informationen tillgänglig för alla datavetare som kanske vill komma åt den för att göra ytterligare analyser.
STEG 4:Generera instrumentpaneler och rapporter för datavisualisering
Med all information samlad på ett ställe kan rapporter nu skapas som låter anställda fatta bättre informerade beslut och öppna möjligheter som inte fanns. Värmekartor kan göras för att spåra motorns plats och korrelera eventuella problem med potentiella geografiska platser, såsom fel på grund av extrem kyla eller värme. Dessa data kan också användas för att spåra exakt vilka kunder som kan påverkas om det uppstod ett problem på en viss fabrik under ett tidsintervall, vilket gör det enkelt att spåra kunder som kan behöva återkallas eller förebyggande underhåll.
Slutsats
Cloudera Data Engineering gör det möjligt för ECC att bygga en pipeline som kan korrelera tillverknings- och reservdelsdata, kundanvändningstyp, miljöförhållanden, försäljningsinformation med mera för att förbättra kundnöjdheten och fordonens tillförlitlighet. ECC uppnådde sina mål och tog sig an deras utmaningar genom att spåra data relaterade till tillverkningen av dess motorer och dra nytta av det på följande sätt:
- ECC förkortade tid till värde genom att orkestrera och automatisera datapipelines för att leverera utvalda datauppsättningar av hög kvalitet på ett säkert och transparent sätt från olika datakällor.
- ECC kunde identifiera relevant data och filtrera bort all överflödig och dubblerad data.
- ECC kunde uppnå datapipelineövervakning från en enda ruta, samtidigt som den var i stånd att bli varnad för att fånga upp problem tidigt genom visuell felsökning för att snabbt lösa problem innan verksamheten påverkades.
Leta efter nästa blogg som kommer att fördjupa sig i rapportering som kommer att visa hur ECC-ingenjörer kör ad-hoc-förfrågningar i CDW mot dessa kurerade data samt sammanfogar data till andra relevanta källor i ett företagsdatalager. CDW underlättar att samla all data och tillhandahåller ett inbyggt datavisualiseringsverktyg för att gå från sökta resultat till instrumentpaneler. Håll utkik för nästa!
Fler resurser för datainsamling
För att se allt detta i praktiken, klicka på de relaterade länkarna nedan för att lära dig mer databerikning:
- Video – Om du vill se och höra hur detta byggdes, se videon på länken.
- Självstudier – Om du vill göra detta i din egen takt, se en detaljerad genomgång med skärmdumpar och rad för rad instruktioner om hur du ställer in och utför detta.
- Meetup – Om du vill prata direkt med experter från Cloudera, gå med i en virtuell träff för att se en livestreampresentation. Det kommer att finnas tid för direkta frågor och svar i slutet.
- Användare – Klicka på länken för att se mer tekniskt innehåll specifikt för användare.