
Vad är Couchbase
Couchbase Server är en distribuerad JSON-dokumentdatabas med öppen källkod. Den exponerar ett utskalat, nyckel-värdelager med hanterad cache för dataoperationer under millisekunder, specialbyggda indexerare för effektiva frågor och en kraftfull frågemotor för exekvering av SQL-liknande frågor. För mobila miljöer och Internet of Things-miljöer körs Couchbase också inbyggt på enheten och hanterar synkronisering till servern.
Varför Couchbase?
Couchbase Server är en distribuerad JSON-dokumentdatabas med öppen källkod. Den exponerar ett utskalat, nyckel-värdelager med hanterad cache för dataoperationer under millisekunder, specialbyggda indexerare för effektiva frågor och en kraftfull frågemotor för exekvering av SQL-liknande frågor. För mobila miljöer och Internet of Things-miljöer körs Couchbase också inbyggt på enheten och hanterar synkronisering till servern.
Couchbase Server är specialiserad på att tillhandahålla datahantering med låg latens för storskaliga interaktiva webb-, mobil- och IoT-applikationer. Vanliga krav som Couchbase Server designades för att uppfylla inkluderar:
- Enhetligt programmeringsgränssnitt
- Fråga
- Sök
- Mobil och IoT
- Analytics
- Kärndatabasmotor
- Utskalad arkitektur
- Memory-first-arkitektur
- Big data och SQL-integrationer
- Säkerhet i full stack
- Behållar- och molndistributioner
- Hög tillgänglighet
Många databaser kan uppfylla ett eller flera av dessa krav men kräver avvägningar när de körs i produktion med verksamhetskritiska applikationer i internetskala. Till exempel kan en lösning ge datamodellflexibilitet men kan sakna förmågan att lägga till eller ta bort noder utan att påverka drifttiden eller prestanda. En annan lösning kan visa god skrivskalbarhet utan att kunna indexera eller ändra datamodellen i farten. Couchbase Server är designad för att ge en produktiv utvecklar- och administrationsupplevelse samtidigt som den ger prestanda i skala, oavsett om det är i molnet, i en container, på plats eller på en edge-enhet.
Nosql Performance Benchmark
Nytt benchmark som jämför MongoDB, DataStax och Couchbase Server visar att Couchbase är den mest skalbara, bäst presterande NoSQL-databasen.
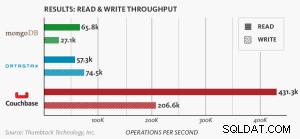
Nodbaserat benchmark .
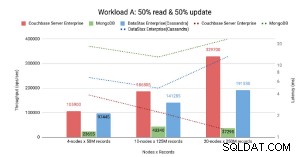
Enligt CAP Theorem Couchbase .
Cap-sats

Couchbase är på CP- och AP-diagram.
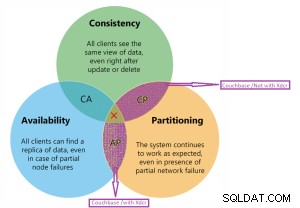
Couchbase CP och AP diagram detalj.
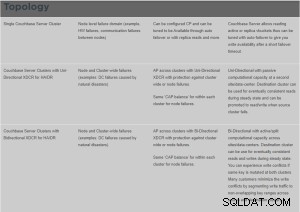
Vad är XDCR?
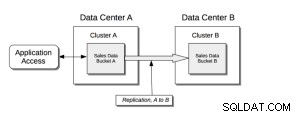
Cross Data Center Replication (XDCR) replikerar data mellan kluster:detta ger skydd mot datacenterfel och ger även högpresterande dataåtkomst för globalt distribuerade, verksamhetskritiska applikationer.
XDCR replikerar data från en specifik bucket på källklustret till en specifik bucket på målklustret. Data från källbucket skjuts till målbucket med hjälp av en XDCR-agent, som körs på källklustret, med hjälp av Database Change Protocol. Vilken hink som helst (Couchbase eller Ephemeral) på vilket kluster som helst kan anges som en källa eller ett mål för en eller flera XDCR-definitioner.
En fullständig arkitektonisk beskrivning av XDCR finns i Cross Data Center Replication (XDCR). Du kanske vill bekanta dig med informationen som tillhandahålls där, innan du utför rutinerna i detta avsnitt.
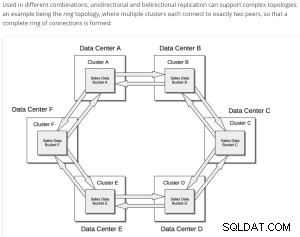
Xdcr grundläggande struktur;
Förhandskrav;
- Bekräfta att ditt kluster har rätt storlek och kan hantera nya XDCR-strömmar. Till exempel behöver XDCR 1-2 extra CPU-kärnor per ström och i vissa fall kommer det att kräva mer RAM och nätverksresurser också. Om ett kluster inte har rätt storlek för den befintliga arbetsbelastningen plus de nya XDCR-strömmarna, kan XDCR konkurrera om serverresurser och ha en negativ inverkan på övergripande prestanda.
- Couchbase Server använder TCP/IP-port 8091 för att utbyta information om klusterkonfiguration. Om du kommunicerar med ett destinationskluster över en dedikerad anslutning eller internet bör du se till att alla noder i destinations- och källklustret kan kommunicera med varandra via portarna 8091 och 8092.
Portar listade efter kommunikationsväg
| XDCR (kluster-till-kluster) |
|
Couchbase lagrar data både på disk och i RAM. Standardbeteendet är att skriva dokumentet till disken vid någon godtycklig tidpunkt (vanligtvis snabbt) efter lagring i RAM. Detta lämnar ett kort fönster där nodfel kan resultera i förlust av data.
I alla fall, efter att ha skrivit till RAM, kommer dokumentet så småningom att skrivas till disk. Couchbase håller en diskskrivkö som du kan kontrollera på statistikrapportsidan i hanteringskonsolen. Nu synkroniserar CB skrivningar över klustret, och jag tror att en skrivning kommer att synkroniseras över ett kluster innan Couchbase kommer att bekräfta att skrivningen hände (t.ex. innan skrivmetoden återvänder till den som ringer).
Om du har fler dokument än tillgängligt RAM-minne kommer endast de dokument som oftast används att lagras i RAM-minnet för snabb hämtning, medan alla andra "avhysas" till disken.
Råd;
När hinkstorleken minskade från 200 GB till 10 GB i källkod blev replikeringen snabbare nog. Med andra ord, om storleken på hinken är stor och trots att alla data är i ram, har jag sett att replikeringen hade 10 sekunders mellanrum.
Källa och mål har samma linux-inställning och samma resurser. Detta är bara ett råd.
Prod bucket resident måste vara %100. Eftersom replikeringshastigheten är viktig.
Bucket replication best settings ; XDCR Source Nozzles per Node: 2 --> 8 XDCR Target Nozzles per Node: 2 --> 24 (Nozzles=Channel=parallel , as cpu core) XDCR Checkpoint Interval (sn): 1800 --> 60 Control frequency is low, but not as much as waiting in the queue. The higher this value, the longer it takes for XDCR queues to grow. XDCR Batch Count: 500 --> 2000 It is beneficial to increase by 2.3 times. It also sends so many data groups at the same time. XDCR Batch Size (kB): 2048 --> 8192 It is beneficial to increase by 2.3 times. At the same time, it sends such a large amount of data. XDCR Failure Retry Interval: 10 --> 10 It is used for retry attempts in network errors. XDCR Optimistic Replication Threshold: 256 --> 1024 --> 256 --> 128 Increasing or decreasing this value appropriately can speed up replication, collect data above 1 mb and send it in bulk. But collection can be a waste of time and waiting in the queue. This is the compressed document size in bytes. 0 - 2097152 Bytes (20MB). Default is 256 Bytes. XDCR retrieves metadata for documents larger than this size at once before copying the uncompressed document to a destination set. This option improves XDCR latency. XDCR Statistics Collection Interval (ms): 1000 --> 1000 XDCR Logging Level: info --> info
Råd;
Jag rekommenderar att källan och målet har samma inställning och har samma resurser.
Dessa är hinkinställningar, klusterinställningar, cpu, minne, diskkvalitet etc.
Xdcr-replikering är bara datareplikering. Innan replikering måste du skapa metadata för hink.
Om du vill skapar du användare, index, visning, händelse etc.
Som ytterligare information;
Du kan göra xdcr-replikering på communityversion.
Du kan göra xdcr-replikering på företagsversion. Detta kräver ytterligare licens. Om du inte använder standby som prod är det ingen hög avgift.
Couchbases andra kontakter för XDCR; Elasticsearch, Hadoop, Kafka, Spark, Talend, SQL (ODBC / JDBC)
Couchbase-hantering kan göras via WEB UI, REST API och CLI. I synnerhet är webbanvändargränssnittet väldigt enkelt och okomplicerat att använda. Du kan göra många operationella transaktioner och frågor via användargränssnittet.
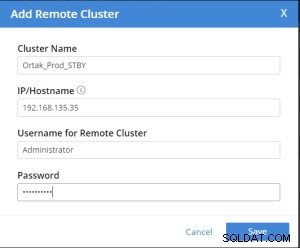
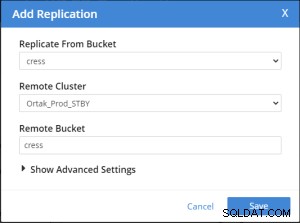
Replication Summary; Stby=Xdcr=Target=Remote same term. A different name xdcr cluster is established with the same features. The buckets with the same name with the same features are created in the xdcr cluster. In Prod, add remote server and xdcr information are entered in the xdcr tab. Prod in xdcr tab with add remote cluster; Cluster Name= Xdcr couchbase name IP/Hostname= Xdcr ip / hostname Username=Xdcr Admin username Password=Xdcr Admin user password Prod in xdcr tab with add bucket replication; Replicate From Bucket = Bucket name in the prod Remote Cluster = Added Xdcr name Remote Bucket = Bucket name added in Xdcr
Minnesinställningar för Xdcr-klusterinställningar ges enligt serverminnesvärdet.
Bör vara ledig storlek för serverminne.
Xdcr behöver ytterligare minne i produktklustret.
Multiple couchbase-bucket-replikering är möjlig.
Exempel XDCR-replikering enkel operation;
Xdcr-fliken vald på couchbase-hemsidan.

Lägg till fjärrklusterfliken är vald på den valda xdcr-fliken .

Lägg till fjärrkluster görs efter .
Lägg till replikeringsfliken är vald på den valda xdcr-fliken .
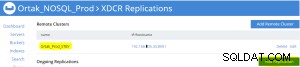
Replikeringsoperationen Lägg till hink görs efter .
Bästa parametrarna för xdcr-prestanda . Men det kan ställas in igen för ditt system.

Replikeringsstatus på xdcr-fliken för källan (prod)
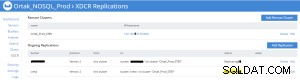
Bucket Replication Statistics
Replikeringsprestanda på mål;

Replikeringsprestanda på källan;

Referenser;
1-) https://resources.couchbase.com/nosql_comparison_web/altoros-nosql-performance-benchmark
2-) https://docs.couchbase.com/
3-) https://www.businesswire.com/news/home/20140625005778/en/Couchbase-Blows-Past-Competition-in-NoSQL-Performance-Benchmark
4-) https://www.quora.com/What-is-the-relation-between-SQL-NoSQL-the-CAP-theorem-and-ACID
Fatih Gençali – Couchbase-certifieringar

