Ville hoppa in med möjlighet att lösa din uppgift med ren BigQuery (Standard SQL)
Förutsättningar/antaganden :källdata finns i sandbox.temp.id1_id2_pairs
Du bör ersätta detta med ditt eget eller om du vill testa med dummy-data från din fråga - du kan skapa den här tabellen enligt nedan (naturligtvis ersätt sandbox.temp med ditt eget project.dataset )
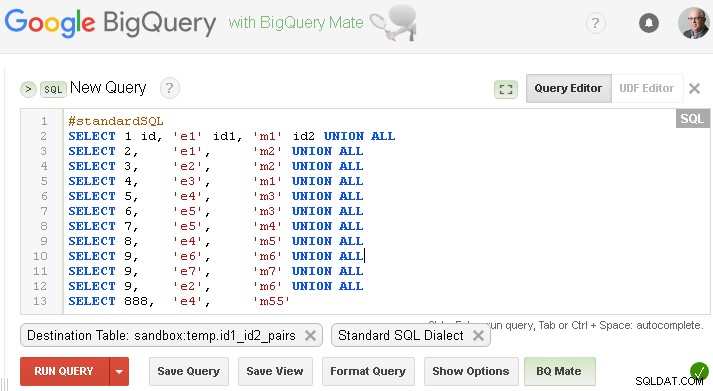
Se till att du ställer in respektive destinationstabell
Obs :du kan hitta alla respektive frågor (som text) längst ner i det här svaret, men för närvarande illustrerar jag mitt svar med skärmdumpar - så allt presenteras - fråga, resultat och använda alternativ
Så det kommer att finnas tre steg:
Steg 1 - Initiering
Här gör vi bara initial gruppering av id1 baserat på anslutningar med id2:
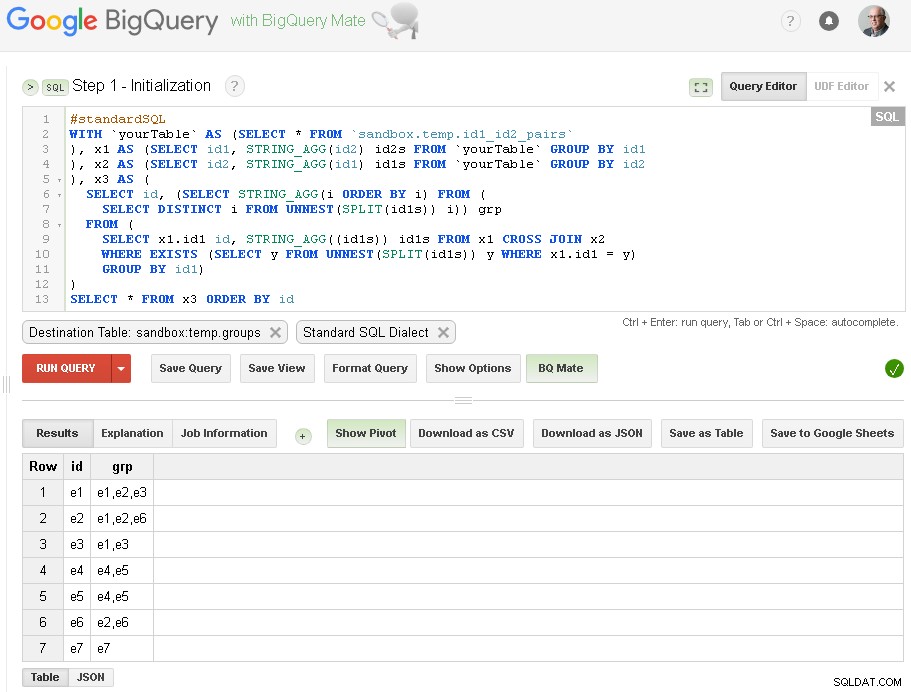
Som du kan se här - skapade vi en lista över alla id1-värden med respektive anslutningar baserat på enkel ennivåanslutning genom id2
Utdatatabellen är sandbox.temp.groups
Steg 2 - Grupper iterationer
I varje iteration kommer vi att berika gruppering baserat på redan etablerade grupper.
Källan till frågan är utdatatabellen från föregående steg (sandbox.temp.groups ) och Destination är samma tabell (sandbox.temp.groups ) med Skriv över
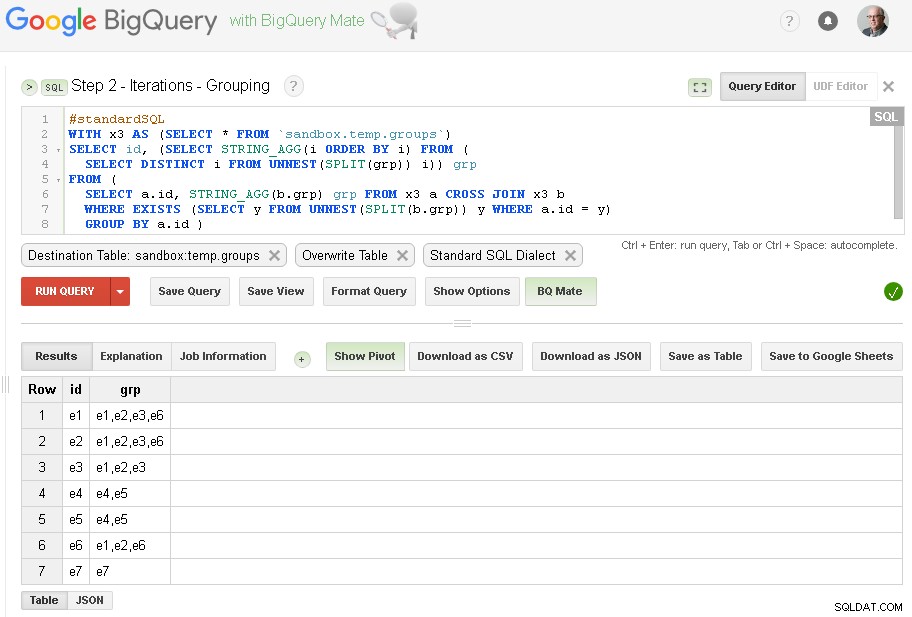
Vi kommer att fortsätta iterationer tills när antalet hittade grupper är detsamma som i föregående iteration
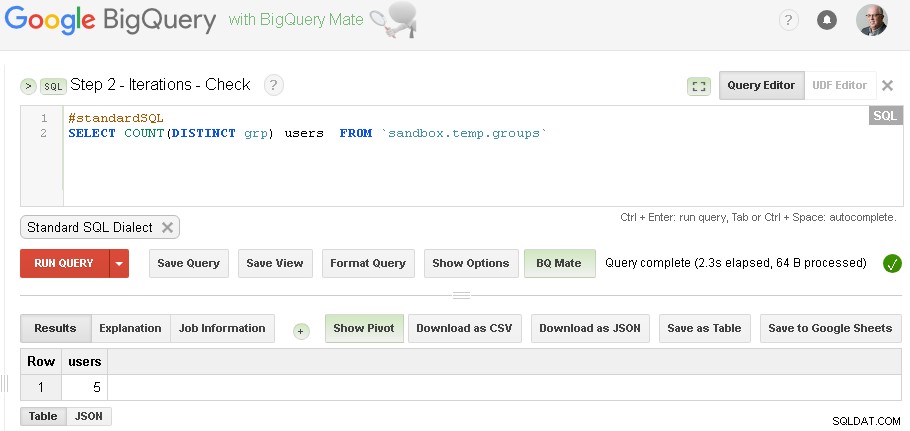
Obs :du kan bara ha två BigQuery Web UI-flikar öppna (som det visas ovan) och utan att ändra någon kod är det bara att köra gruppering och sedan kontrollera igen och igen tills iterationen konvergerar
(för specifik data som jag använde i avsnittet med krav - jag hade tre iterationer - första iterationen gav 5 användare, andra iterationen gav 3 användare och tredje iterationen gav igen 3 användare - vilket indikerade att vi gjorde med iterationer.
Naturligtvis, i verkliga livet - antalet iterationer kan vara fler än bara tre - så vi behöver någon form av automatisering (se respektive avsnitt längst ner i svaret).
Steg 3 – Slutlig gruppering
När id1-gruppering är klar – vi kan lägga till slutlig gruppering för id2
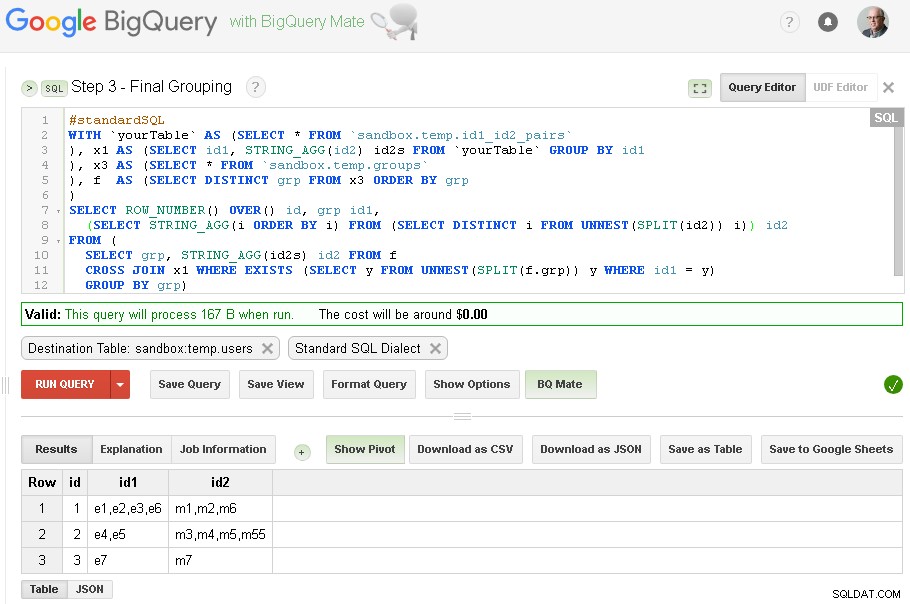
Slutresultatet är nu i sandbox.temp.users tabell
Använda frågor (glöm inte att ställa in respektive destinationstabeller och överskrivningar vid behov enligt ovan beskrivna logik och skärmdumpar):
Förutsättningar:
#standardSQL
SELECT 1 id, 'e1' id1, 'm1' id2 UNION ALL
SELECT 2, 'e1', 'm2' UNION ALL
SELECT 3, 'e2', 'm2' UNION ALL
SELECT 4, 'e3', 'm1' UNION ALL
SELECT 5, 'e4', 'm3' UNION ALL
SELECT 6, 'e5', 'm3' UNION ALL
SELECT 7, 'e5', 'm4' UNION ALL
SELECT 8, 'e4', 'm5' UNION ALL
SELECT 9, 'e6', 'm6' UNION ALL
SELECT 9, 'e7', 'm7' UNION ALL
SELECT 9, 'e2', 'm6' UNION ALL
SELECT 888, 'e4', 'm55'
Steg 1
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x2 AS (SELECT id2, STRING_AGG(id1) id1s FROM `yourTable` GROUP BY id2
), x3 AS (
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(id1s)) i)) grp
FROM (
SELECT x1.id1 id, STRING_AGG((id1s)) id1s FROM x1 CROSS JOIN x2
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(id1s)) y WHERE x1.id1 = y)
GROUP BY id1)
)
SELECT * FROM x3
Steg 2 - Gruppering
#standardSQL
WITH x3 AS (select * from `sandbox.temp.groups`)
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(grp)) i)) grp
FROM (
SELECT a.id, STRING_AGG(b.grp) grp FROM x3 a CROSS JOIN x3 b
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(b.grp)) y WHERE a.id = y)
GROUP BY a.id )
Steg 2 - Kontrollera
#standardSQL
SELECT COUNT(DISTINCT grp) users FROM `sandbox.temp.groups`
Steg 3
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x3 as (select * from `sandbox.temp.groups`
), f AS (SELECT DISTINCT grp FROM x3 ORDER BY grp
)
SELECT ROW_NUMBER() OVER() id, grp id1,
(SELECT STRING_AGG(i ORDER BY i) FROM (SELECT DISTINCT i FROM UNNEST(SPLIT(id2)) i)) id2
FROM (
SELECT grp, STRING_AGG(id2s) id2 FROM f
CROSS JOIN x1 WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(f.grp)) y WHERE id1 = y)
GROUP BY grp)
Automation :
Naturligtvis kan ovanstående "process" exekveras manuellt i fall om iterationer konvergerar snabbt - så du kommer att sluta med 10-20 körningar. Men i mer verkliga fall kan du enkelt automatisera detta med vilken klient
som helst efter eget val