Jag satte ihop ett exempel på transformation(högerklicka och välj spara länk) baserat på vad du angett. Det enda steget jag känner mig lite osäker på är de sista tabellingångarna. Jag skriver i princip kopplingsdata till tabellen och låter den misslyckas om en specifik relation redan finns.
obs!
Den här lösningen uppfyller inte riktigt "Alla tillvägagångssätt bör inkludera en del från validering och en återställningsstrategi om en insättning misslyckas eller misslyckas med att upprätthålla referensintegritet." kriterier, även om det förmodligen inte kommer att misslyckas. Om du verkligen vill ställa in något komplext kan vi, men detta borde definitivt få dig att gå igång med dessa transformationer.

Dataflöde för steg
1. Vi börjar med att läsa in din fil. I mitt fall konverterade jag det till CSV men tab är också bra. 
2. Nu ska vi infoga de anställdas namn i Employee-tabellen med en combination lookup/update .Efter infogningen lägger vi till anställd_id till vår dataström som id och ta bort EmployeeName från dataströmmen.

3. Här använder vi bara steget Välj värden för att byta namn på id fält till anställd_id 
4. Infoga jobbtitlar precis som vi gjorde anställda och lägg till titel-id:t till vår dataström och radera även JobLevelHistory från dataströmmen.

5. Byt enkelt namn på titel-id till title_id (se steg 3) 
6. Infoga kontor, hämta ID:n, ta bort OfficeHistory från strömmen.

7. Byt enkelt namn på office-id till office_id (se steg 3)

8. Kopiera data från det sista steget till två strömmar med värdena employee_id,office_id och employee_id,title_id respektive.

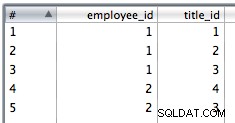
9. Använd en tabellinfogning för att infoga kopplingsdata. Jag har valt att ignorera infogningsfel eftersom det kan finnas dubbletter och PK-begränsningarna kommer att göra att vissa rader misslyckas.
Utdatatabeller




