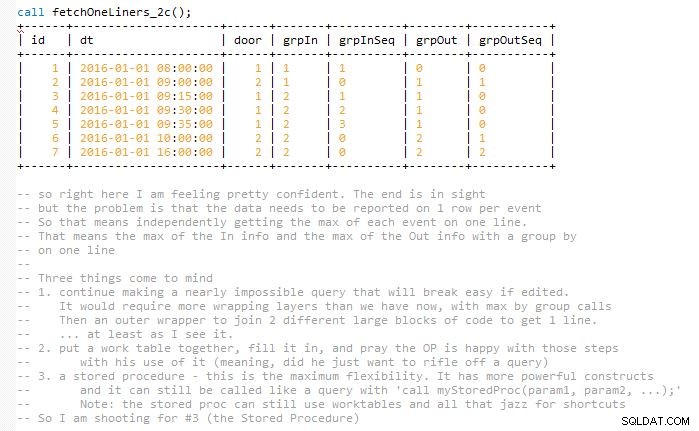
Detta strävar efter att hålla lösningen lätt underhållbar utan att slutföra den slutliga frågan i ett skott, vilket nästan skulle ha fördubblat sin storlek (i mina tankar). Detta beror på att resultaten måste matchas och representeras på en rad med matchade In- och Ut-händelser. Så i slutet använder jag några arbetsbord. Det implementeras i en lagrad procedur.
Den lagrade proceduren använder flera variabler som tas in med en cross join . Tänk på korskopplingen som bara en mekanism för att initiera variabler. Variablerna underhålls säkert, så jag tror, i andan av denna dokument
refereras ofta till i variabelfrågor. De viktiga delarna av referensen är säker hantering av variabler på en linje som tvingar dem att ställas in innan andra kolumner använder dem. Detta uppnås genom greatest() och least() funktioner som har högre prioritet än variabler som sätts utan användning av dessa funktioner. Observera också att coalesce() används ofta för samma ändamål. Om deras användning verkar konstigt, som att ta det största av ett tal som är känt för att vara större än 0 eller 0, är det väl medvetet. Avsiktlig framtvinga prioritetsordningen för variabler som sätts.
Kolumnerna i frågan heter saker som dummy2 etc är kolumner som utdata inte användes, men de användes för att ställa in variabler inuti, säg, greatest() eller annan. Detta nämndes ovan. Utdata som 7777 var en platshållare i den 3:e luckan, eftersom något värde behövdes för if() som användes. Så ignorera allt det där.
Jag har inkluderat flera skärmdumpar av koden när den fortskred lager för lager för att hjälpa dig att visualisera resultatet. Och hur dessa iterationer av utveckling långsamt viks in i nästa fas för att expandera på föregående.
Jag är säker på att mina kamrater skulle kunna förbättra detta i en fråga. Jag kunde ha avslutat det på det sättet. Men jag tror att det skulle ha resulterat i en förvirrande röra som skulle gå sönder om den berördes.
Schema:
create table attendance2(Id int, DateTime datetime, Door char(20), Active_door char(20));
INSERT INTO attendance2 VALUES
( 1, '2016-01-01 08:00:00', 'In', ''),
( 2, '2016-01-01 09:00:00', 'Out', ''),
( 3, '2016-01-01 09:15:00', 'In', ''),
( 4, '2016-01-01 09:30:00', 'In', ''),
( 5, '2016-01-01 09:35:00', '', 'On'),
( 6, '2016-01-01 10:00:00', 'Out', ''),
( 7, '2016-01-01 16:00:00', '', 'Off');
drop table if exists oneLinersDetail;
create table oneLinersDetail
( -- architect this depending on multi-user concurrency
id int not null,
dt datetime not null,
door int not null,
grpIn int not null,
grpInSeq int not null,
grpOut int not null,
grpOutSeq int not null
);
drop table if exists oneLinersSummary;
create table oneLinersSummary
( -- architect this depending on multi-user concurrency
id int not null,
grpInSeq int null,
grpOutSeq int null,
checkIn datetime null, -- we are hoping in the end it is not null
checkOut datetime null -- ditto
);
Lagrad procedur:
DROP PROCEDURE IF EXISTS fetchOneLiners;
DELIMITER $$
CREATE PROCEDURE fetchOneLiners()
BEGIN
truncate table oneLinersDetail; -- architect this depending on multi-user concurrency
insert oneLinersDetail(id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq)
select id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq
from
( select id,dt,door,
if(@lastEvt!=door and door=1,
greatest(@grpIn:example@sqldat.com+1,0),
7777) as dummy2, -- this output column we don't care about (we care about the variable being set)
if(@lastEvt!=door and door=2,
greatest(@grpOut:example@sqldat.com+1,0),
7777) as dummy3, -- this output column we don't care about (we care about the variable being set)
if (@lastEvt!=door,greatest(@flip:=1,0),least(@flip:=0,1)) as flip,
if (door=1 and @flip=1,least(@grpOutSeq:=0,1),7777) as dummy4,
if (door=1 and @flip=1,greatest(@grpInSeq:=1,0),7777) as dummy5,
if (door=1 and @flip!=1,greatest(@grpInSeq:example@sqldat.comnSeq+1,0),7777) as dummy6,
if (door=2 and @flip=1,least(@grpInSeq:=0,1),7777) as dummy7,
if (door=2 and @flip=1,greatest(@grpOutSeq:=1,0),7777) as dummy8,
if (door=2 and @flip!=1,greatest(@grpOutSeq:example@sqldat.com+1,0),7777) as dummy9,
@grpIn as grpIn,
@grpInSeq as grpInSeq,
@grpOut as grpOut,
@grpOutSeq as grpOutSeq,
@lastEvt:=door as lastEvt
from
( select id,`datetime` as dt,
CASE
WHEN Door='in' or Active_door='on' THEN 1
ELSE 2
END as door
from attendance2
order by id
) xD1 -- derived table #1
cross join (select @grpIn:=0,@grpInSeq:=0,@grpOut:=0,@grpOutSeq:=0,@lastEvt:=-1,@flip:=0) xParams
order by id
) xD2 -- derived table #2
order by id;
-- select * from oneLinersDetail;
truncate table oneLinersSummary; -- architect this depending on multi-user concurrency
insert oneLinersSummary (id,grpInSeq,grpOutSeq,checkIn,checkOut)
select distinct grpIn,null,null,null,null
from oneLinersDetail
order by grpIn;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpIn,max(grpInSeq) m
from oneLinersDetail
where door=1
group by grpIn
) d1
on d1.grpIn=ols.id
set ols.grpInSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpOut,max(grpOutSeq) m
from oneLinersDetail
where door=2
group by grpOut
) d1
on d1.grpOut=ols.id
set ols.grpOutSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=1 and old.grpIn=ols.id and old.grpInSeq=ols.grpInSeq
set ols.checkIn=old.dt;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=2 and old.grpOut=ols.id and old.grpOutSeq=ols.grpOutSeq
set ols.checkOut=old.dt;
-- select * from oneLinersSummary;
-- dump out the results
select id,checkIn,checkOut
from oneLinersSummary
order by id;
-- rows are left in those two tables (oneLinersDetail,oneLinersSummary)
END$$
DELIMITER ;
Test:
call fetchOneLiners();
+----+---------------------+---------------------+
| id | checkIn | checkOut |
+----+---------------------+---------------------+
| 1 | 2016-01-01 08:00:00 | 2016-01-01 09:00:00 |
| 2 | 2016-01-01 09:35:00 | 2016-01-01 16:00:00 |
+----+---------------------+---------------------+
Detta är slutet på svaret. Nedanstående är för en utvecklares visualisering av stegen som ledde fram till slutförandet av den lagrade proceduren.
Versioner av utveckling som ledde fram till slutet. Förhoppningsvis hjälper detta till med visualiseringen i motsats till att bara släppa en medelstor förvirrande kodbit.
Steg A
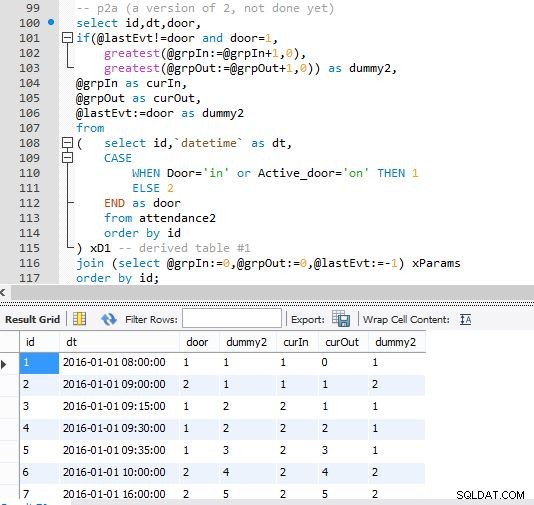
Steg B
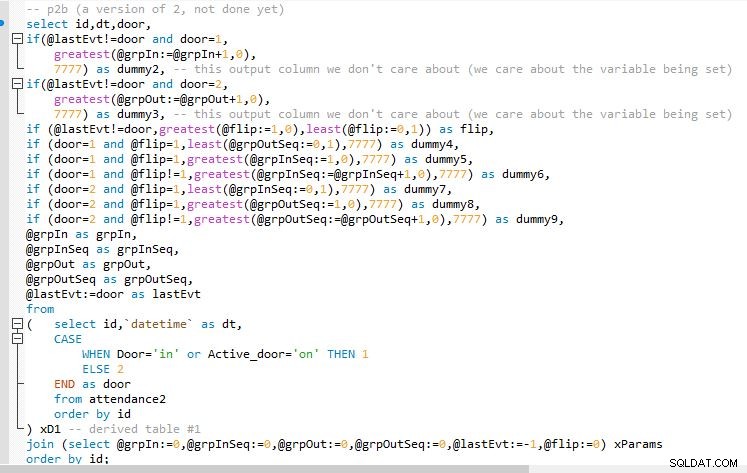
Utdata från steg B

Steg C
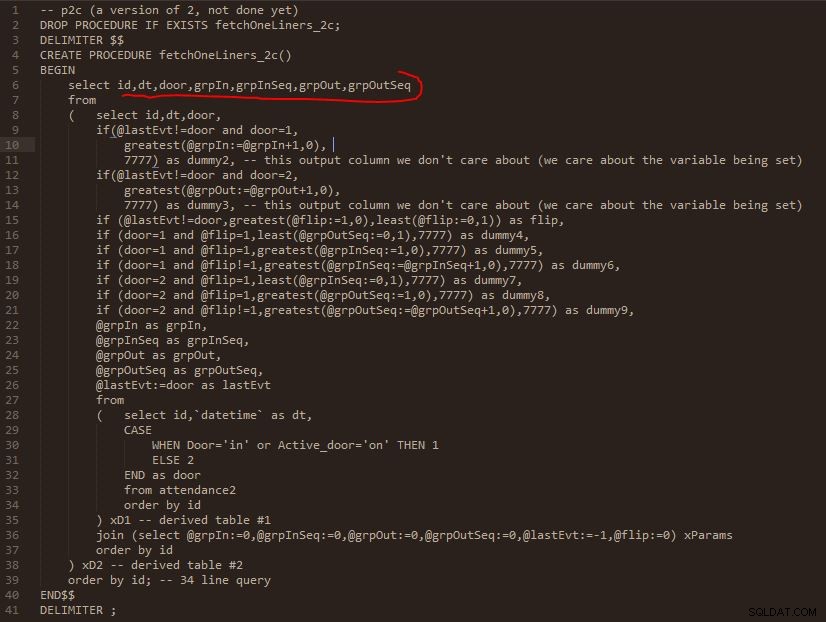
Utdata från steg C