Versionstester är vanligtvis ett av stegen i hela distributionsprocessen. Du skriver koden och sedan verifierar du hur den beter sig i en iscensättningsmiljö och sedan, slutligen, distribuerar du den nya koden i produktionen. Databaser är interna i alla typer av applikationer, och därför är det viktigt att verifiera hur de databasrelaterade ändringarna förändrar applikationen. Det är möjligt att verifiera det på ett par sätt; en av dem skulle vara att använda en dedikerad kopia. Låt oss ta en titt på hur det kan göras.
Uppenbarligen vill du inte att den här processen ska vara manuell – den bör vara en del av ditt företags CI/CD-processer. Beroende på exakt applikation, miljö och processer du har på plats, kan du använda repliker skapade ad hoc eller repliker som alltid är en del av databasmiljön.
Sättet som Galera Cluster fungerar är att det hanterar schemaändringar på ett specifikt sätt. Det är möjligt att utföra en schemaändring på en enda nod i klustret men det är knepigt, eftersom det inte stöder alla möjliga schemaändringar, och det kommer att påverka produktionen om något går fel. En sådan nod skulle behöva byggas om helt med SST, vilket innebär att en av de återstående Galera-noderna måste agera som donator och överföra all sin data över nätverket.
Ett alternativ är att använda en replik eller till och med ett helt extra Galera-kluster som fungerar som en replik. Självklart måste processen automatiseras för att den ska kunna kopplas in i utvecklingspipelinen. Det finns många sätt att göra detta:skript eller många verktyg för orkestrering av infrastruktur som Ansible, Chef, Puppet eller Salt stack. Vi kommer inte att beskriva dem i detalj, men vi vill att du visar de steg som krävs för att hela processen ska fungera korrekt, och vi överlåter implementeringen i ett av verktygen till dig.
Automatisk releasetest
Först och främst vill vi kunna distribuera en ny databas enkelt. Den bör förses med de senaste data, och detta kan göras på många sätt - du kan kopiera data från produktionsdatabasen till testservern; det är det enklaste att göra. Alternativt kan du använda den senaste säkerhetskopian - ett sådant tillvägagångssätt har ytterligare fördelar med att testa säkerhetskopieringsåterställningen. Verifiering av säkerhetskopiering är ett måste i alla typer av seriösa installationer, och att återuppbygga testinställningar är ett utmärkt sätt att dubbelkontrollera att återställningsprocessen fungerar. Det hjälper dig också att ta tid på återställningsprocessen - att veta hur lång tid det tar att återställa din säkerhetskopia hjälper dig att korrekt bedöma situationen i ett katastrofåterställningsscenario.
När data har tillhandahållits i databasen kanske du vill ställa in den noden som en replik av ditt primära kluster. Det har sina för- och nackdelar. Om du kunde köra om all din trafik till den fristående noden skulle det vara perfekt - i sådana fall finns det inget behov av att ställa in replikeringen. Vissa av lastbalanserarna, som ProxySQL, låter dig spegla trafiken och skicka dess kopia till en annan plats. Å andra sidan är replikering det näst bästa. Ja, du kan inte köra skrivningar direkt på den noden som tvingar dig att planera hur du ska köra frågorna igen eftersom det enklaste sättet att bara svara på det inte kommer att fungera. Å andra sidan kommer alla skrivningar så småningom att exekveras via SQL-tråden, så du behöver bara planera hur du ska hantera SELECT-frågor.
Beroende på den exakta ändringen kanske du vill testa schemaändringsprocessen. Schemaändringar är ganska vanliga att utföra, och de kan till och med ha allvarliga prestandapåverkan på databasen. Därför är det viktigt att verifiera dem innan de appliceras i produktionen. Vi vill titta på den tid som behövs för att utföra ändringen och verifiera om ändringen kan tillämpas på noder separat eller krävs för att utföra ändringen på hela topologin samtidigt. Detta kommer att berätta för oss vilken process vi ska använda för en given schemaändring.
Använda ClusterControl för att förbättra automatiseringen av releasetesterna
ClusterControl kommer med en uppsättning funktioner som kan användas för att hjälpa dig att automatisera releasetesterna. Låt oss ta en titt på vad den erbjuder. För att göra det tydligt är funktionerna vi kommer att visa tillgängliga på ett par sätt. Det enklaste sättet är att använda UI, men det är onödigt vad du vill göra om du har automatisering i tankarna. Det finns ytterligare två sätt att göra det:Kommandoradsgränssnitt till ClusterControl och RPC API. I båda fallen kan jobb utlösas från externa skript, så att du kan koppla in dem till dina befintliga CI/CD-processer. Det kommer också att spara massor av tid, eftersom att distribuera klustret kan bara vara en fråga om att utföra ett kommando istället för att ställa in det manuellt.
Distribuera testklustret
Först och främst kommer ClusterControl med en möjlighet att distribuera ett nytt kluster och tillhandahålla det med data från den befintliga databasen. Bara den här funktionen gör att du enkelt kan implementera provisionering av staging-servern.
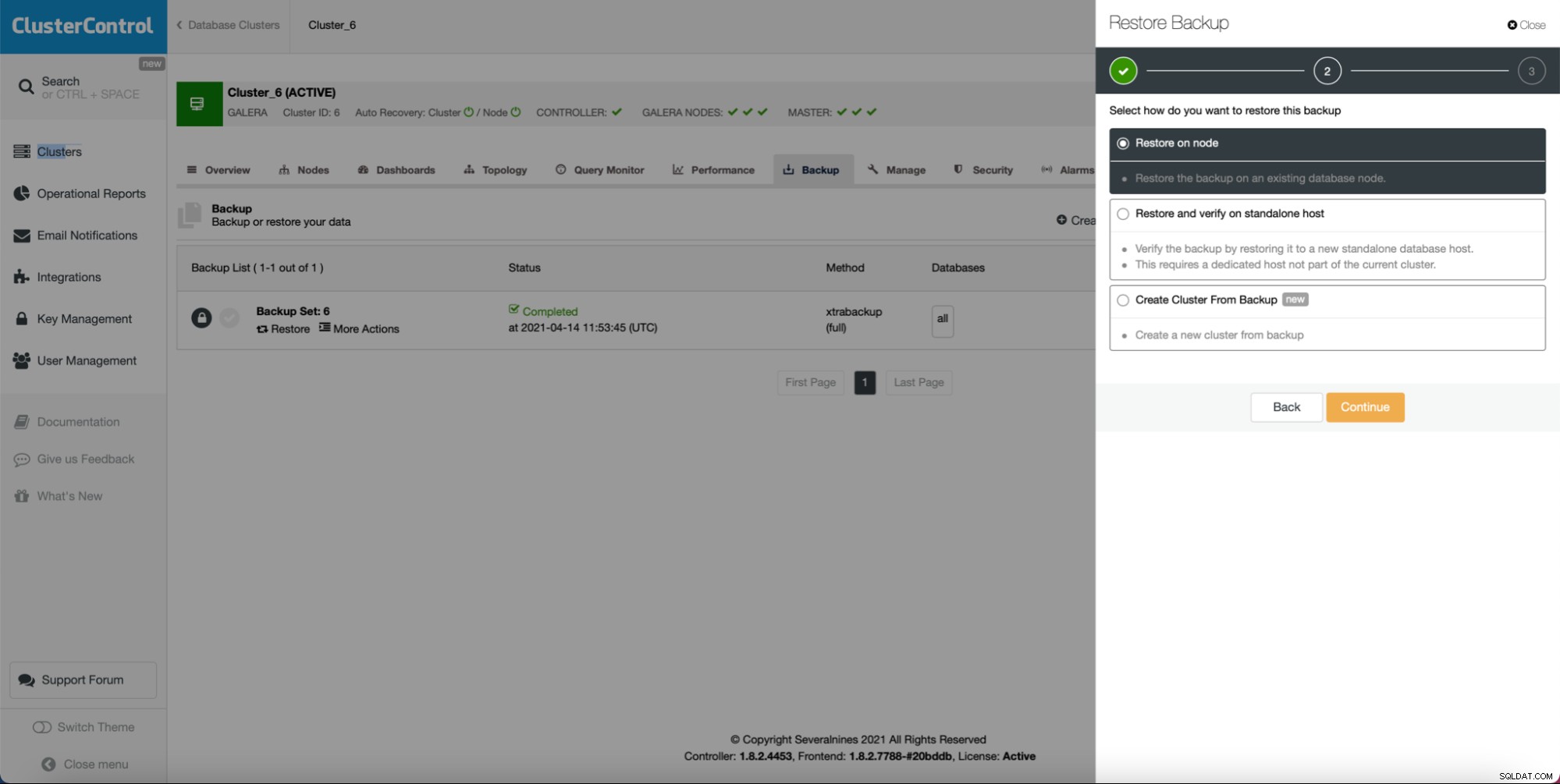
Som du kan se, så länge du har en säkerhetskopia skapad kan skapa ett nytt kluster och tillhandahålla det med hjälp av data från säkerhetskopian:
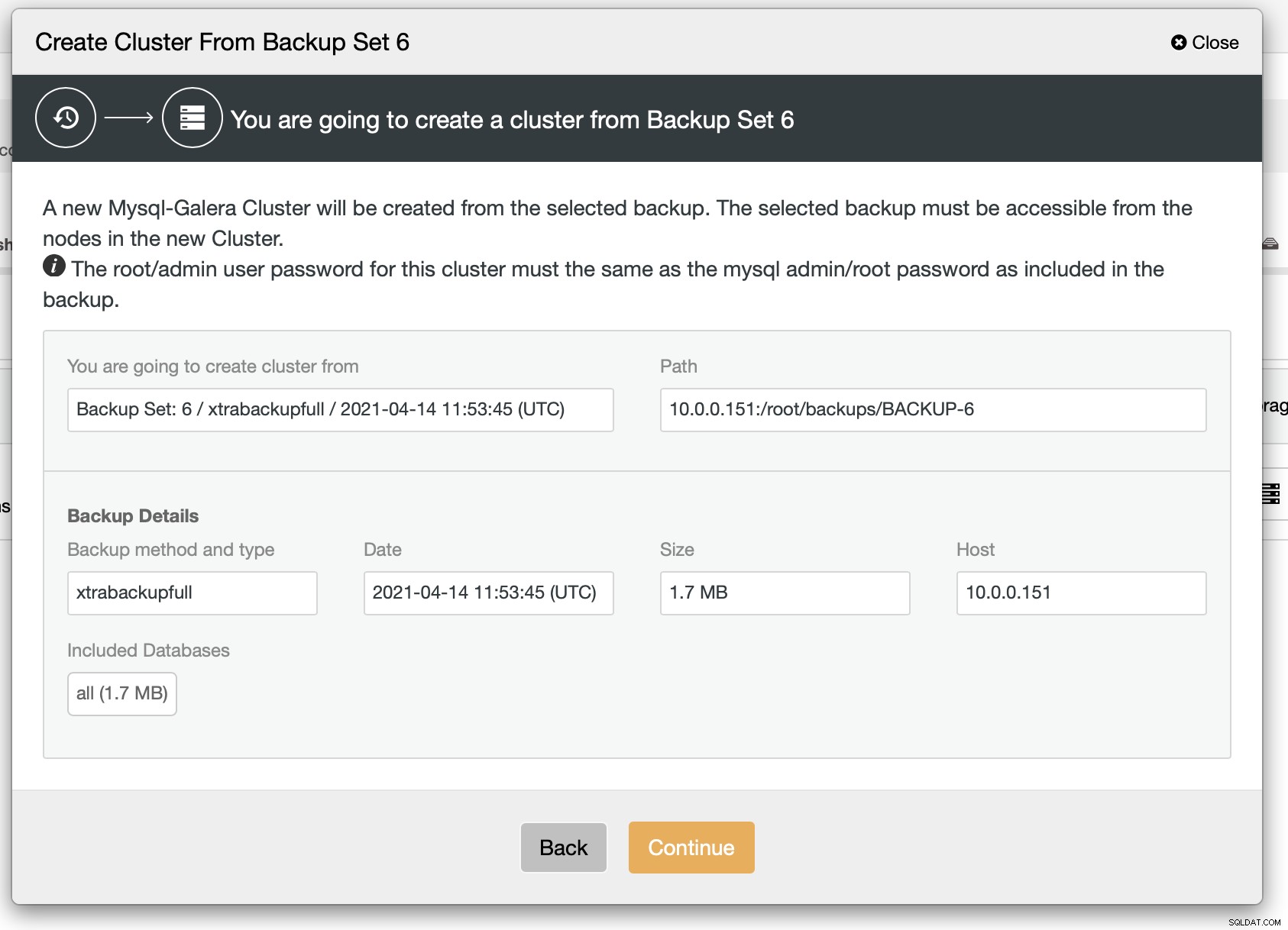
Som vi kan se finns det en snabb sammanfattning av vad som kommer att hända. Om du klickar på Fortsätt går du vidare.
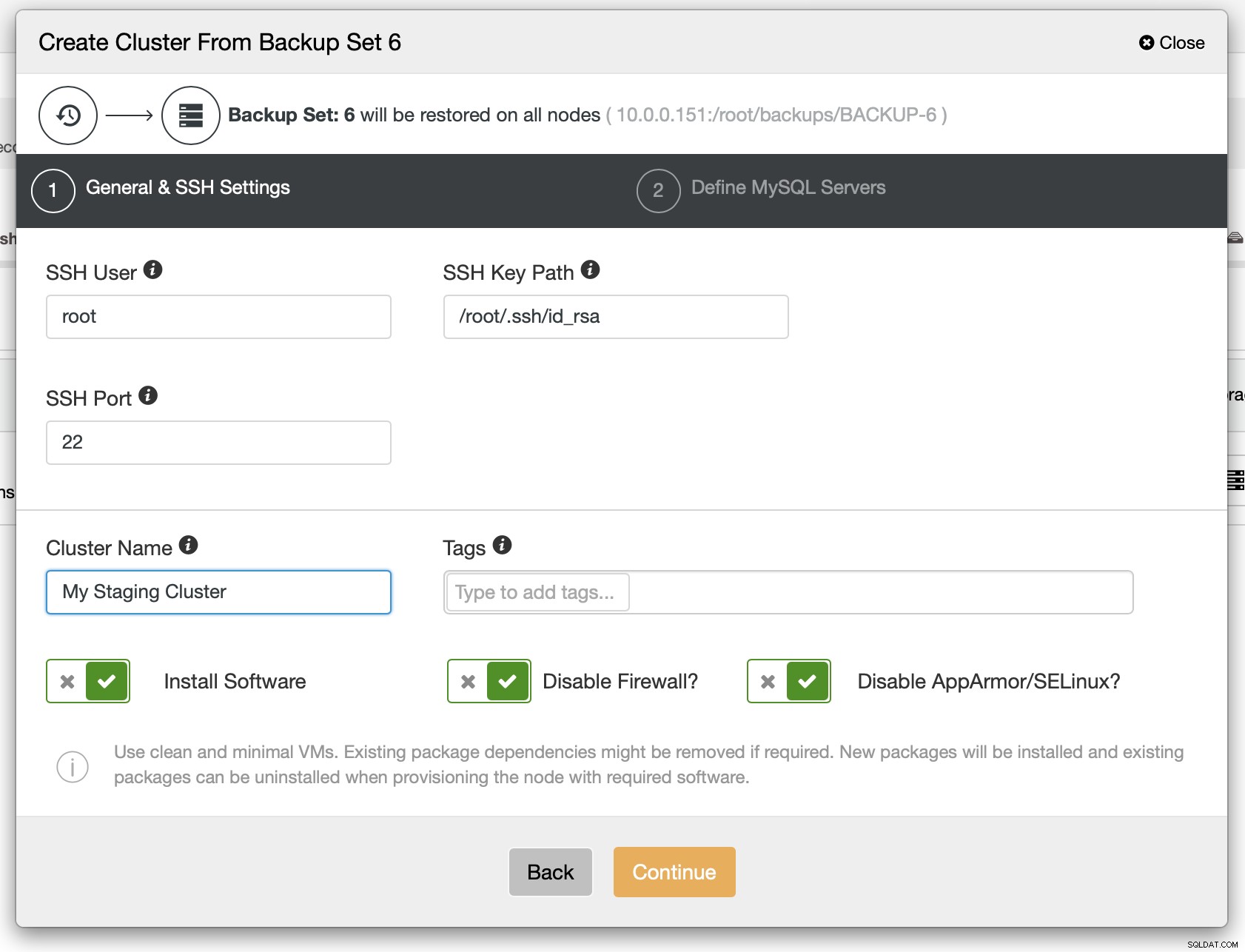
Som ett nästa steg bör du definiera SSH-anslutningen - den måste vara på plats innan ClusterControl kan distribuera noderna.
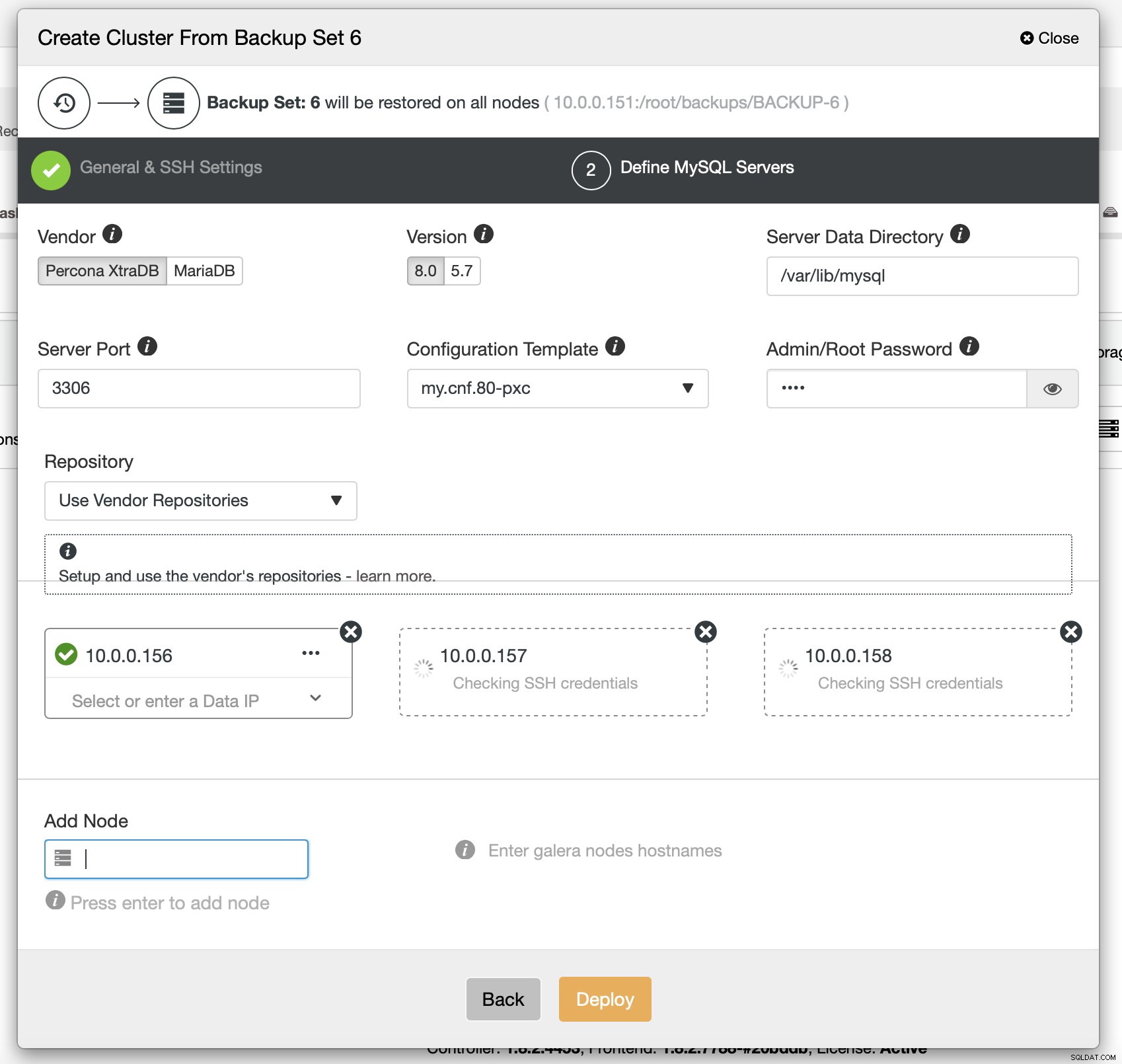
Slutligen måste du välja (bland annat) leverantör, version och värdnamn för de noder som du vill använda i klustret. Det är bara det.
CLI-kommandot som skulle åstadkomma samma sak ser ut så här:
s9s cluster --create --cluster-type=galera --nodes="10.0.0.156;10.0.0.157;10.0.0.158" --vendor=percona --cluster-name=PXC --provider-version=8.0 --os-user=root --os-key-file=/root/.ssh/id_rsa --backup-id=6Konfigurera ProxySQL för att spegla trafiken
Om vi har ett kluster distribuerat kanske vi vill skicka produktionstrafiken till det för att verifiera hur det nya schemat hanterar befintlig trafik. Ett sätt att göra detta är att använda ProxySQL.
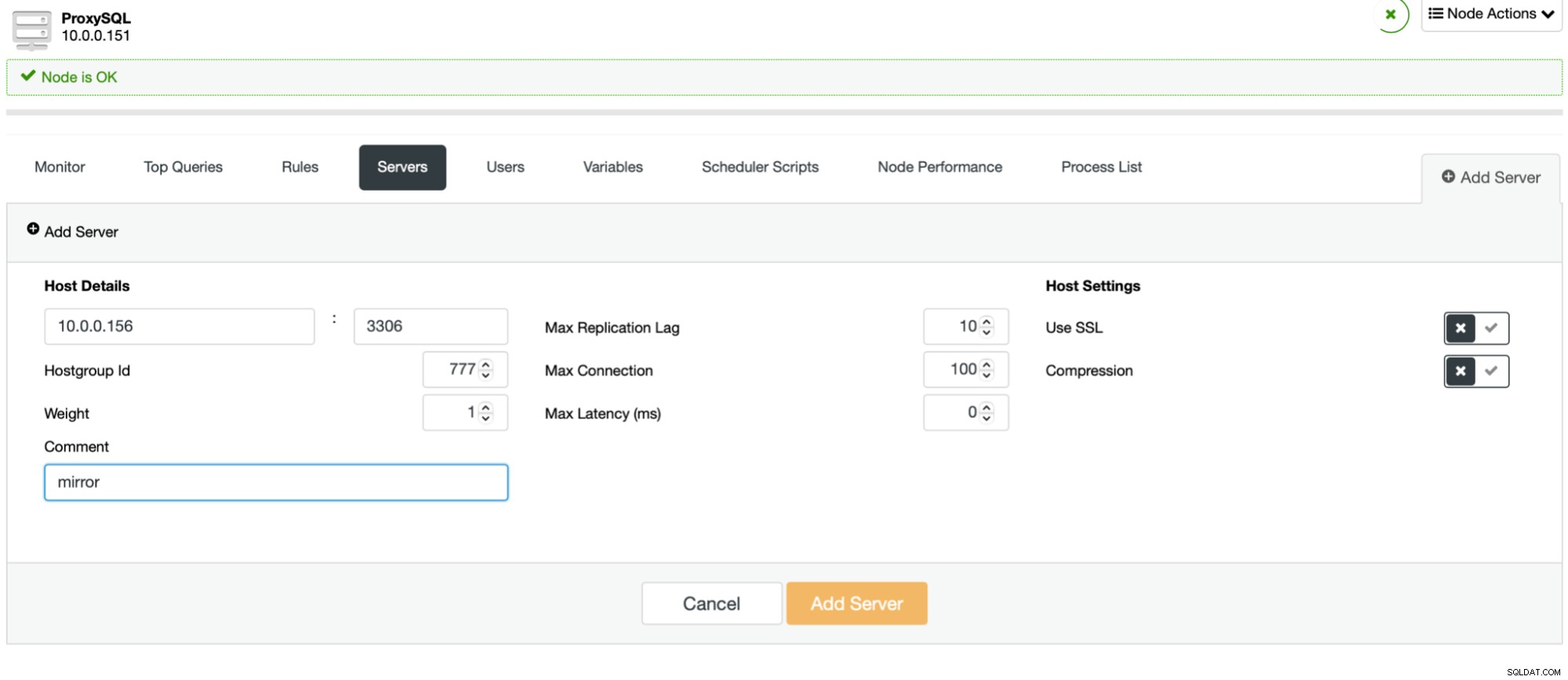
Processen är enkel. Först bör du lägga till noderna till ProxySQL. De bör tillhöra en separat värdgrupp som inte används ännu. Se till att ProxySQL-övervakaren kommer att kunna komma åt dem.
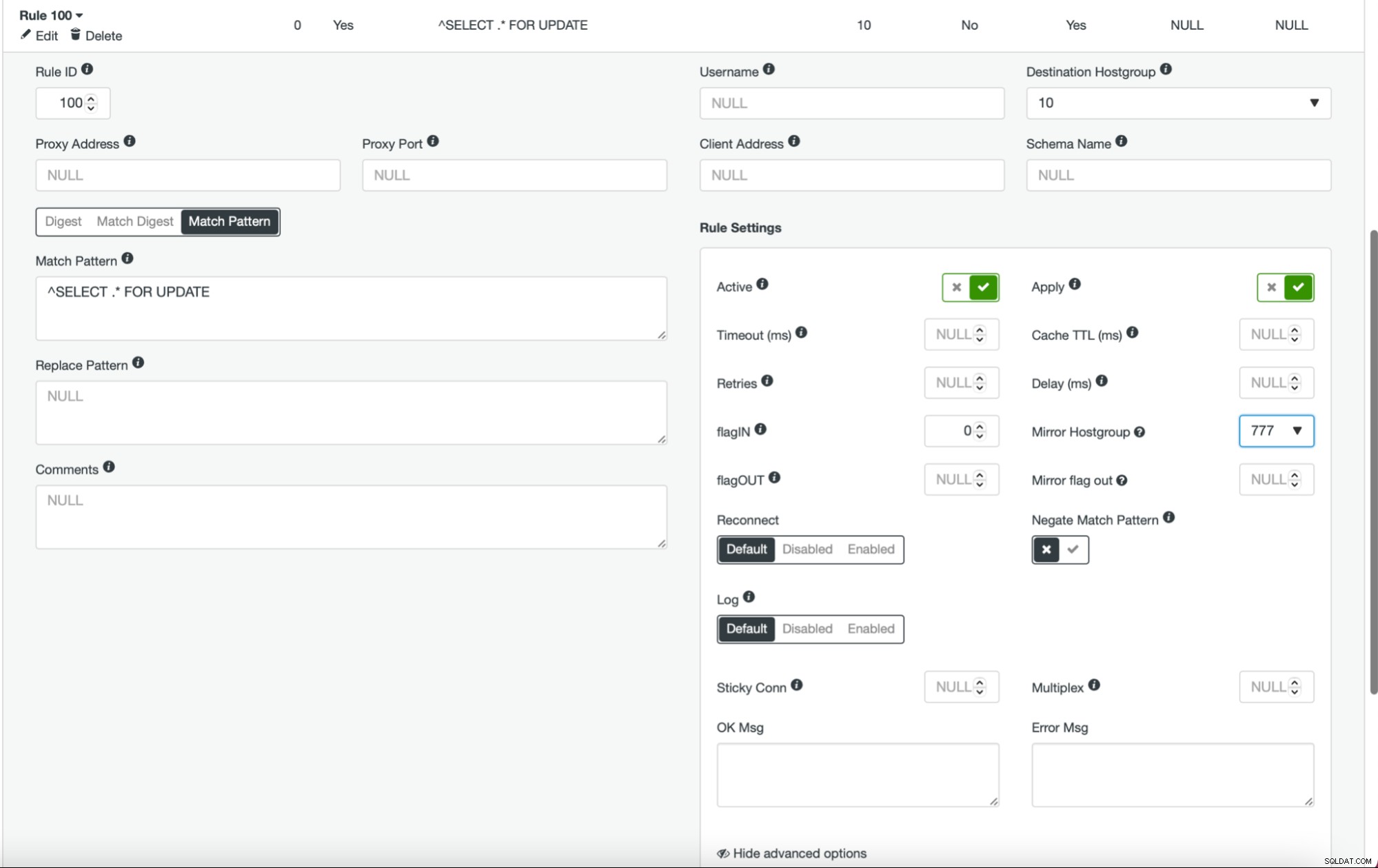
När detta är gjort och du har alla (eller några) av dina noder konfigurerade i värdgruppen, kan du redigera frågereglerna och definiera Spegelvärdgruppen (den är tillgänglig i de avancerade alternativen). Om du vill göra det för all trafik, vill du förmodligen redigera alla dina frågeregler på detta sätt. Om du bara vill spegla SELECT-frågor, bör du redigera lämpliga frågeregler. När detta är gjort bör ditt iscensättningskluster börja ta emot produktionstrafik.
Distribuerar kluster som en slav
Som vi diskuterade tidigare skulle en alternativ lösning vara att skapa ett nytt kluster som kommer att fungera som en replik av den befintliga installationen. Med ett sådant tillvägagångssätt kan vi få alla skrivningar testade automatiskt med hjälp av replikeringen. SELECT kan testas med det tillvägagångssätt som vi beskrev ovan - spegling genom ProxySQL.
Utsättningen av ett slavkluster är ganska okomplicerat.
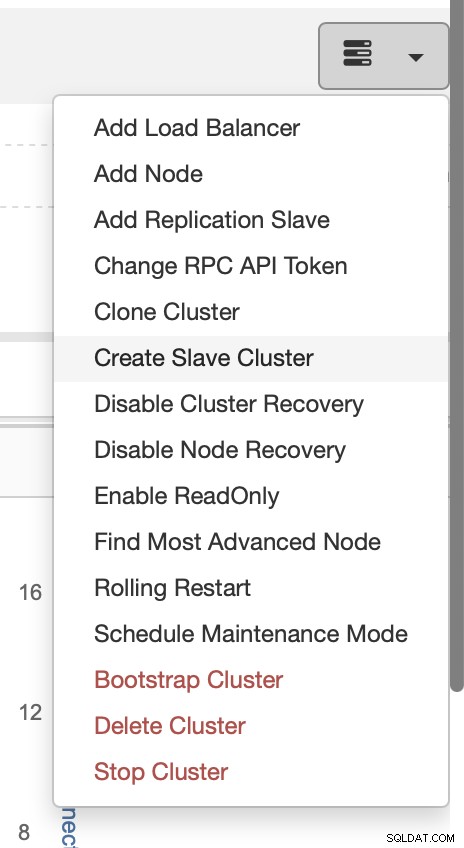
Välj jobbet Skapa slavkluster.
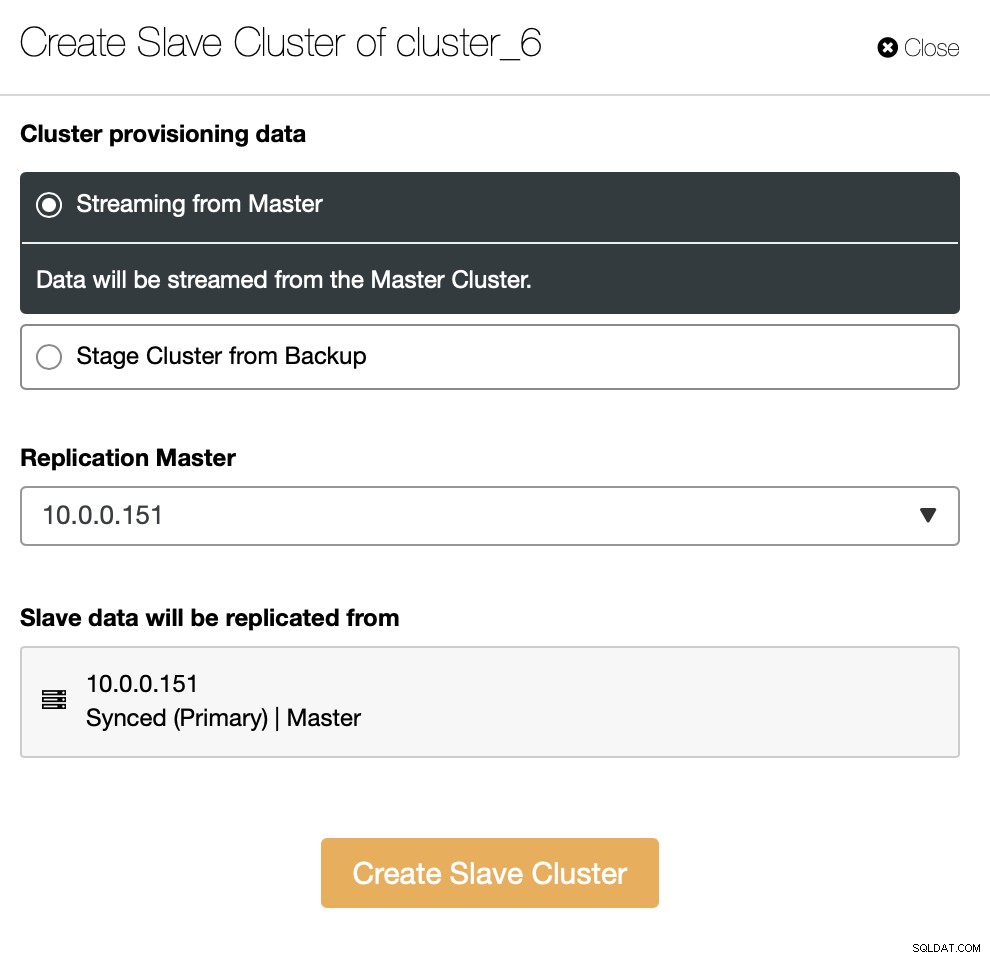
Du måste bestämma hur du vill ha replikeringen. Du kan få all data överförd från mastern till de nya noderna.
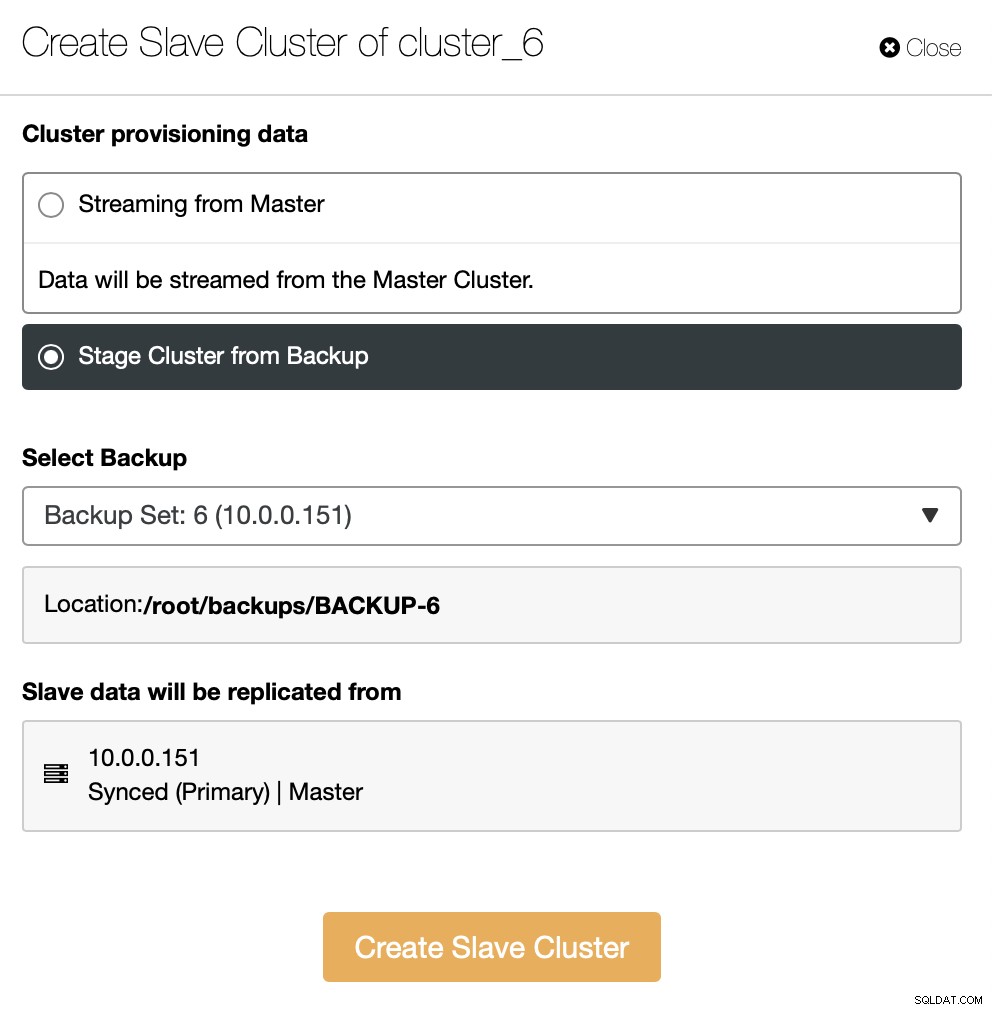
Som ett alternativ kan du använda befintlig säkerhetskopia för att tillhandahålla det nya klustret. Detta kommer att bidra till att minska arbetsbelastningen på masternoden - istället för att överföra all data, måste endast transaktioner som utfördes mellan det att säkerhetskopieringen skapades och det ögonblick då replikeringen har ställts in överföras.
Resten är att följa standardinstallationsguiden, definiera SSH-anslutning, version, leverantör, värdar och så vidare. När det väl har distribuerats kommer du att se klustret på listan.
Alternativ lösning till användargränssnittet är att åstadkomma detta via RPC.
{
"command": "create_cluster",
"job_data": {
"cluster_name": "",
"cluster_type": "galera",
"company_id": null,
"config_template": "my.cnf.80-pxc",
"data_center": 0,
"datadir": "/var/lib/mysql",
"db_password": "pass",
"db_user": "root",
"disable_firewall": true,
"disable_selinux": true,
"enable_mysql_uninstall": true,
"generate_token": true,
"install_software": true,
"port": "3306",
"remote_cluster_id": 6,
"software_package": "",
"ssh_keyfile": "/root/.ssh/id_rsa",
"ssh_port": "22",
"ssh_user": "root",
"sudo_password": "",
"type": "mysql",
"user_id": 5,
"vendor": "percona",
"version": "8.0",
"nodes": [
{
"hostname": "10.0.0.155",
"hostname_data": "10.0.0.155",
"hostname_internal": "",
"port": "3306"
},
{
"hostname": "10.0.0.159",
"hostname_data": "10.0.0.159",
"hostname_internal": "",
"port": "3306"
},
{
"hostname": "10.0.0.160",
"hostname_data": "10.0.0.160",
"hostname_internal": "",
"port": "3306"
}
],
"with_tags": []
}
}Gå framåt
Om du är intresserad av att lära dig mer om hur du kan integrera dina processer med ClusterControl, vill vi peka dig mot dokumentationen, där vi har ett helt avsnitt om att utveckla lösningar där ClusterControl spelar en betydande roll:
https://docs.severalnines.com/docs/clustercontrol/developer-guide/cmon-rpc/
https://docs.severalnines.com/docs/clustercontrol/user-guide-cli/
Vi hoppas att du tyckte att den här korta bloggen var informativ och användbar. Om du har några frågor om att integrera ClusterControl i din miljö, vänligen kontakta oss, så ska vi göra vårt bästa för att hjälpa dig.