Jag skrev tidigare om egenskapen Actual Rows Read. Den talar om hur många rader som faktiskt läses av en indexsökning, så att du kan se hur selektivt sökpredikatet är jämfört med selektiviteten hos sökpredikatet plus restpredikatet kombinerat.
Men låt oss ta en titt på vad som faktiskt händer inom Seek-operatören. För jag är inte övertygad om att "Faktiska rader läser" nödvändigtvis är en korrekt beskrivning av vad som händer.
Jag vill titta på ett exempel som frågar efter adresser av särskilda adresstyper för en kund, men principen här skulle lätt kunna tillämpas på många andra situationer om formen på din fråga passar, som att leta upp attribut i en nyckel-värde-partabell, till exempel.
SELECT AddressTypeID, FullAddress FROM dbo.Addresses WHERE CustomerID = 783 AND AddressTypeID IN (2,4,5);
Jag vet att jag inte har visat dig något om metadata – jag återkommer till det om en minut. Låt oss fundera över den här frågan och vilken typ av index vi vill ha för den.
För det första känner vi till kund-ID exakt. En jämställdhetsmatchning som denna gör den i allmänhet till en utmärkt kandidat för den första kolumnen i ett index. Om vi hade ett index på den här kolumnen kunde vi dyka rakt in i adresserna för den kunden – så jag skulle säga att det är ett säkert antagande.
Nästa sak att tänka på är det filtret på AddressTypeID. Att lägga till en andra kolumn till nycklarna i vårt index är helt rimligt, så låt oss göra det. Vårt index är nu på (CustomerID, AddressTypeID). Och låt oss INKLUDERA FullAddress också, så att vi inte behöver göra några uppslagningar för att slutföra bilden.
Och jag tror att vi är klara. Vi bör säkert kunna anta att det ideala indexet för denna fråga är:
CREATE INDEX ixIdealIndex ON dbo.Addresses (CustomerID, AddressTypeID) INCLUDE (FullAddress);
Vi skulle potentiellt kunna deklarera det som ett unikt index – vi ska titta på effekten av det senare.
Så låt oss skapa en tabell (jag använder tempdb, eftersom jag inte behöver den för att fortsätta efter detta blogginlägg) och testa detta.
CREATE TABLE dbo.Addresses ( AddressID INT IDENTITY(1,1) PRIMARY KEY, CustomerID INT NOT NULL, AddressTypeID INT NOT NULL, FullAddress NVARCHAR(MAX) NOT NULL, SomeOtherColumn DATE NULL );
Jag är inte intresserad av begränsningar för främmande nyckel, eller vilka andra kolumner det kan finnas. Jag är bara intresserad av mitt idealindex. Så skapa det också, om du inte redan har gjort det.
Min plan verkar ganska perfekt.
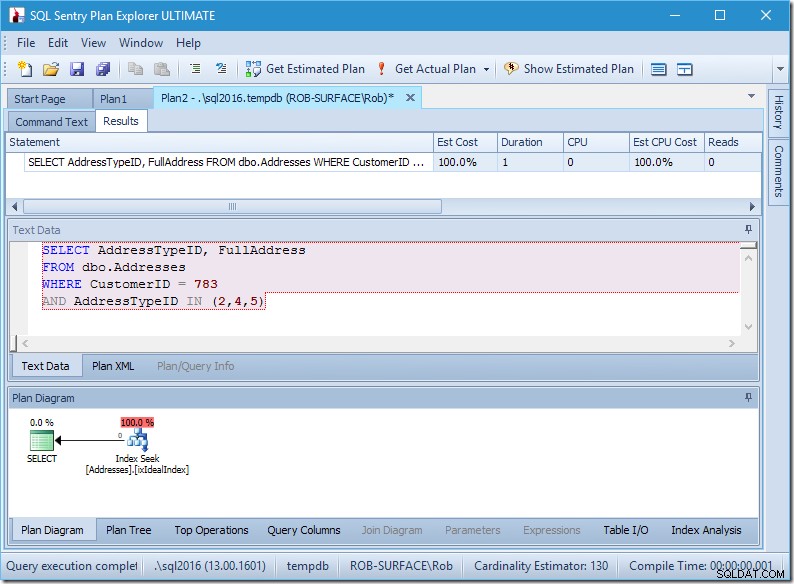
Jag har en indexsökning, och det är allt.
Visst, det finns inga data, så det finns inga läsningar, ingen CPU, och det går ganska snabbt också. Om bara alla frågor kunde justeras lika bra som denna.
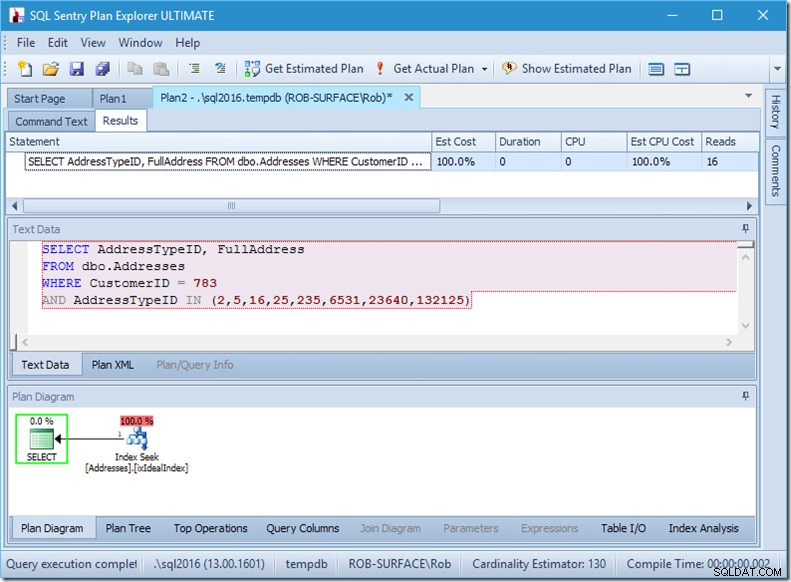
Låt oss se vad som händer lite närmare genom att titta på egenskaperna hos Seek.
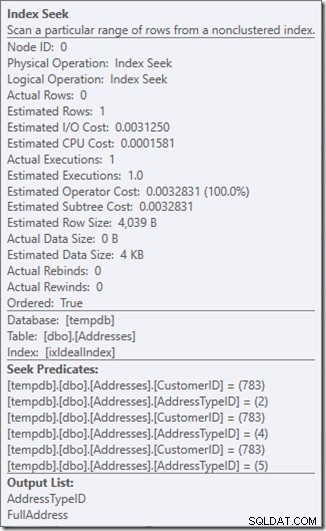
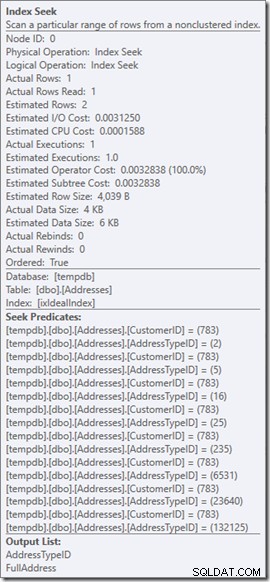
Vi kan se Seek Predicates. Det finns sex. Tre om CustomerID, och tre om AddressTypeID. Vad vi faktiskt har här är tre uppsättningar av sökpredikat, som indikerar tre sökoperationer inom den enda sökoperatorn. Den första sökningen letar efter kund 783 och adresstyp 2. Den andra söker efter 783 och 4, och den sista 783 och 5. Vår sökoperatör dök upp en gång, men det pågick tre sökningar inuti den.
Vi har inte ens data, men vi kan se hur vårt index kommer att användas.
Låt oss lägga in lite dummydata så att vi kan titta på några av effekterna av detta. Jag kommer att lägga in adresser för typ 1 till 6. Varje kund (över 2000, baserat på storleken på master..spt_values ) kommer att ha en adress av typ 1. Det kanske är den primära adressen. Jag låter 80 % ha en typ 2-adress, 60 % en typ 3 och så vidare, upp till 20 % för typ 5. Rad 783 kommer att få adresser av typ 1, 2, 3 och 4, men inte 5. Jag skulle hellre ha gått med slumpmässiga värden, men jag vill se till att vi är på samma sida för exemplen.
WITH nums AS (
SELECT row_number() OVER (ORDER BY (SELECT 1)) AS num
FROM master..spt_values
)
INSERT dbo.Addresses (CustomerID, AddressTypeID, FullAddress)
SELECT num AS CustomerID, 1 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
UNION ALL
SELECT num AS CustomerID, 2 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 8
UNION ALL
SELECT num AS CustomerID, 3 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 6
UNION ALL
SELECT num AS CustomerID, 4 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 4
UNION ALL
SELECT num AS CustomerID, 5 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 2
; Låt oss nu titta på vår fråga med data. Två rader kommer ut. Det är som förut, men vi ser nu de två raderna komma ut från sökoperatorn och vi ser sex läsningar (uppe till höger).
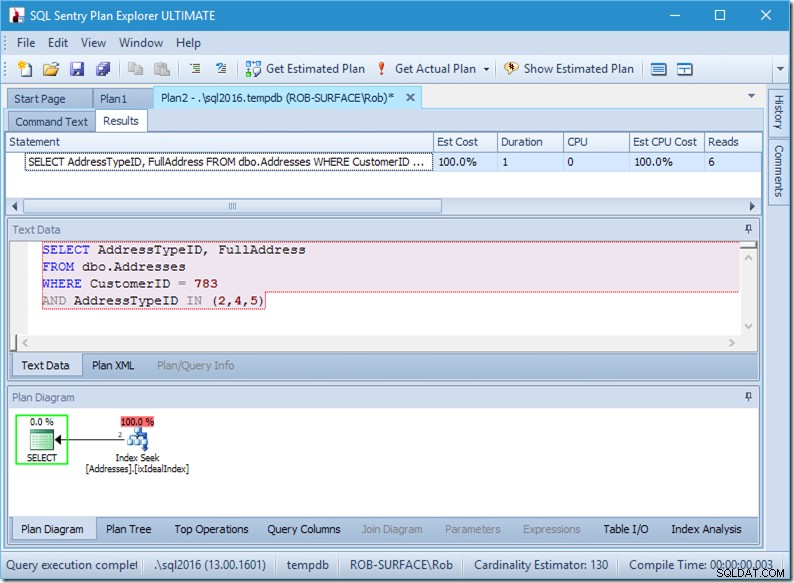
Sex läsningar är vettigt för mig. Vi har ett litet bord och indexet passar på bara två nivåer. Vi gör tre sökningar (inom vår ena operatör), så motorn läser rotsidan, tar reda på vilken sida man ska gå ner till och läser den och gör det tre gånger.
Om vi bara skulle leta efter två AddressTypeIDs, skulle vi bara se fyra läsningar (och i det här fallet en enda rad som matas ut). Utmärkt.
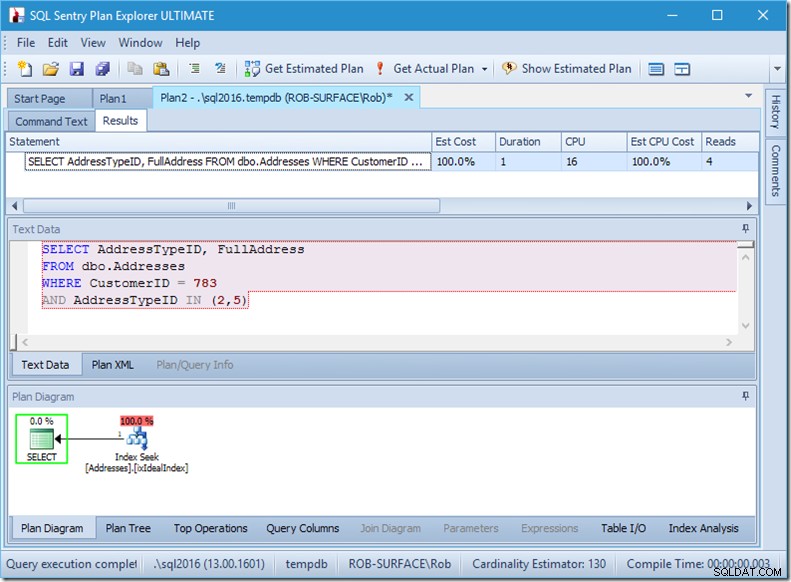
Och om vi letade efter 8 adresstyper, skulle vi se 16.
Ändå visar var och en av dessa att de faktiska raderna avläst exakt matchar de faktiska raderna. Ingen ineffektivitet alls!
Låt oss gå tillbaka till vår ursprungliga fråga och leta efter adresstyperna 2, 4 och 5 (som returnerar 2 rader) och fundera över vad som händer i sökningen.
Jag kommer att anta att frågemotorn redan har gjort jobbet för att ta reda på att indexsökningen är rätt operation och att den har sidnumret för indexroten till hands.
Vid det här laget laddar den in den sidan i minnet, om den inte redan finns där. Det är den första läsningen som räknas med i verkställandet av sökningen. Sedan hittar den sidnumret för raden den letar efter och läser in den sidan. Det är den andra läsningen.
Men vi slänger ofta bort den där biten "lokaliserar sidnumret".
Genom att använda DBCC IND(2, N'dbo.Address', 2); (den första 2 är databas-id eftersom jag använder tempdb; den andra 2 är index-id för ixIdealIndex ), kan jag upptäcka att 712 i fil 1 är sidan med den högsta IndexLevel. I skärmdumpen nedan kan jag se att sida 668 är IndexLevel 0, som är rotsidan.

Så nu kan jag använda DBCC TRACEON(3604); DBCC PAGE (2,1,712,3); för att se innehållet på sidan 712. På min dator får jag 84 rader som kommer tillbaka, och jag kan säga att kund-ID 783 kommer att finnas på sidan 1004 i fil 5.
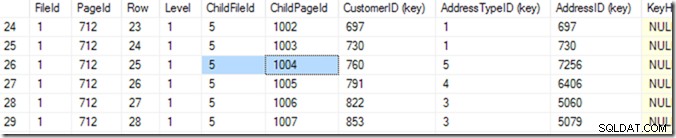
Men jag vet detta genom att bläddra igenom min lista tills jag ser den jag vill ha. Jag började med att scrolla ner lite, och kom sedan upp igen, tills jag hittade raden jag ville ha. En dator kallar detta en binär sökning, och den är lite mer exakt än jag. Den letar efter raden där kombinationen (Kund-ID, AddressTypeID) är mindre än den jag letar efter, med nästa sida större eller samma som den. Jag säger "samma" eftersom det kan vara två som matchar, spridda över två sidor. Den vet att det finns 84 rader (0 till 83) med data på den sidan (det läser det i sidhuvudet), så den börjar med att kontrollera rad 41. Därifrån vet den vilken halva den ska söka i, och (i) detta exempel), kommer den att läsa rad 20. Några fler läsningar (gör 6 eller 7 totalt)* och den vet att rad 25 (se kolumnen som heter 'Row' för detta värde, inte radnumret från SSMS ) är för liten, men rad 26 är för stor – så 25 är svaret!
*I en binär sökning kan sökningen vara marginellt snabbare om den har tur när den delar upp blocket i två om det inte finns någon mittfack, och beroende på om den mellersta luckan kan elimineras eller inte.
Nu kan den gå in på sida 1004 i fil 5. Låt oss använda DBCC PAGE på den.
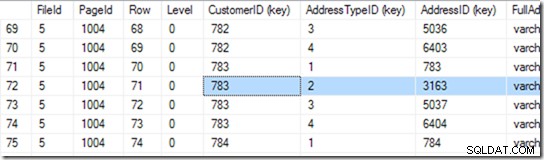
Den här ger mig 94 rader. Den gör ytterligare en binär sökning för att hitta början av intervallet som den letar efter. Den måste titta igenom 6 eller 7 rader för att hitta det.
"Början av serien?" Jag hör dig fråga. Men vi letar efter adress typ 2 för kund 783.
Okej, men vi förklarade inte detta index som unikt. Så det kan bli två. Om den är unik kan sökningen göra en singelsökning och kan snubbla över den under den binära sökningen, men i det här fallet måste den slutföra den binära sökningen för att hitta den första raden i intervallet. I det här fallet är det rad 71.
Men vi stannar inte här. Nu måste vi se om det verkligen finns en andra! Så den läser också rad 72 och finner att paret CustomerID+AddressTypeiD verkligen är för stort, och dess sökning är klar.
Och detta händer tre gånger. Tredje gången hittar den ingen rad för kund 783 och adresstyp 5, men den vet inte detta i förväg och måste fortfarande slutföra sökningen.
Så raderna som faktiskt läses över dessa tre sökningar (för att hitta två rader att mata ut) är mycket mer än antalet som returneras. Det finns cirka 7 på indexnivå 1, och cirka 7 fler på bladnivån bara för att hitta början av intervallet. Sedan står det raden vi bryr oss om, och sedan raden efter det. Det låter mer som 16 för mig, och det gör det tre gånger, vilket ger ungefär 48 rader.
Men faktiska rader läser handlar inte om antalet rader som faktiskt läses, utan antalet rader som returneras av sökpredikatet, som testas mot restpredikatet. Och i det är det bara de två raderna som hittas av de tre sökningarna.
Du kanske tänker vid det här laget att det finns en viss mängd ineffektivitet här. Den andra sökningen skulle också ha läst sidan 712, kontrollerat samma 6 eller 7 rader där, och sedan läst sidan 1004 och letat igenom den... liksom den tredje sökningen.
Så det kanske hade varit bättre att få det här på en enda sökning och bara läsa sidan 712 och sidan 1004 en gång var. När allt kommer omkring, om jag gjorde det här med ett pappersbaserat system, skulle jag ha sökt efter kund 783 och sedan skannat igenom alla deras adresstyper. För jag vet att en kund inte brukar ha många adresser. Det är en fördel jag har jämfört med databasmotorn. Databasmotorn vet genom sin statistik att en sökning kommer att vara bäst, men den vet inte att sökningen bara bör gå ner en nivå, när den kan säga att den har vad som verkar som Ideal Index.
Om jag ändrar min fråga för att ta tag i ett antal adresstyper, från 2 till 5, får jag nästan det beteende jag vill ha:
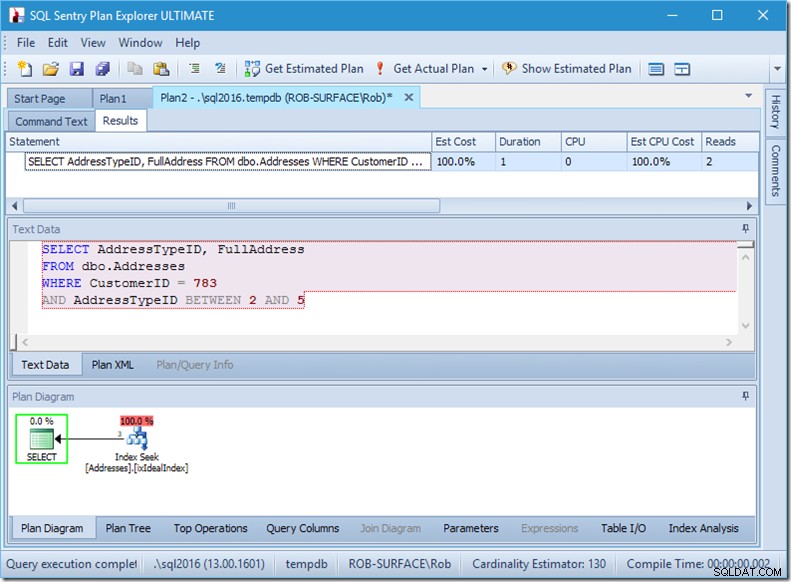
Titta – läsningarna är nere i 2, och jag vet vilka sidor det är...
…men mina resultat är felaktiga. Eftersom jag bara vill ha adresstyperna 2, 4 och 5, inte 3. Jag måste säga till den att den inte ska ha 3, men jag måste vara försiktig med hur jag gör detta. Titta på de två följande exemplen.
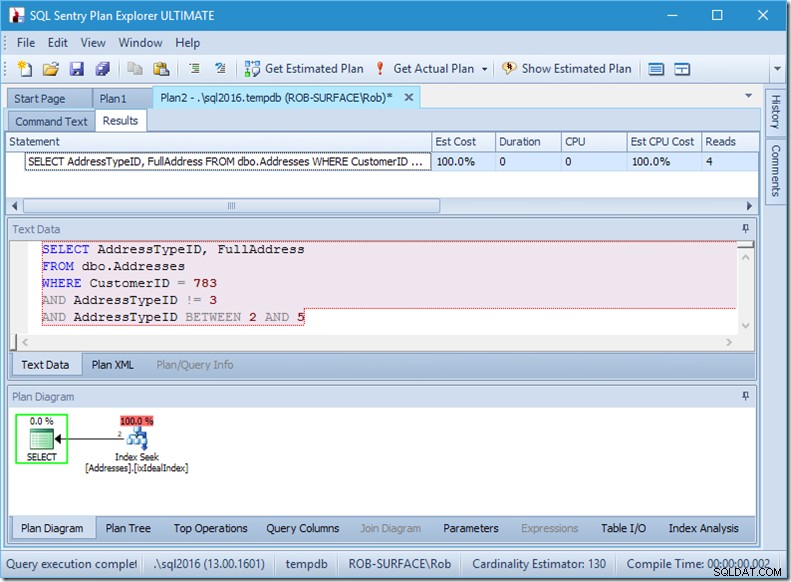
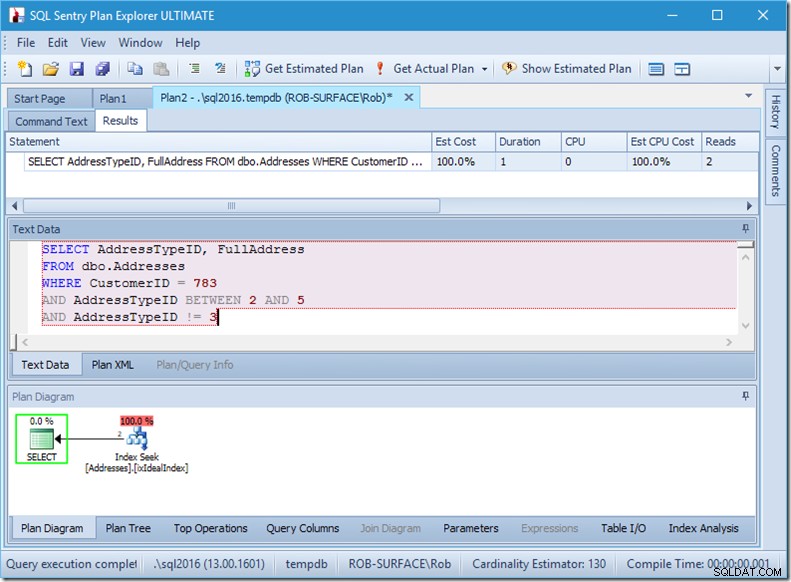
Jag kan försäkra dig om att predikatordningen inte spelar någon roll, men här gör det helt klart. Om vi sätter "inte 3" först, gör den två sökningar (4 läsningar), men om vi sätter "inte 3" tvåa, gör den en enda sökning (2 läsningar).
Problemet är att AddressTypeID !=3 konverteras till (AddressTypeID> 3 ELLER AddressTypeID <3), vilket sedan ses som två mycket användbara sökpredikat.
Så jag föredrar att använda ett icke-sargerbart predikat för att tala om att jag bara vill ha adresstyperna 2, 4 och 5. Och det kan jag göra genom att ändra AddressTypeID på något sätt, som att lägga till noll till det.
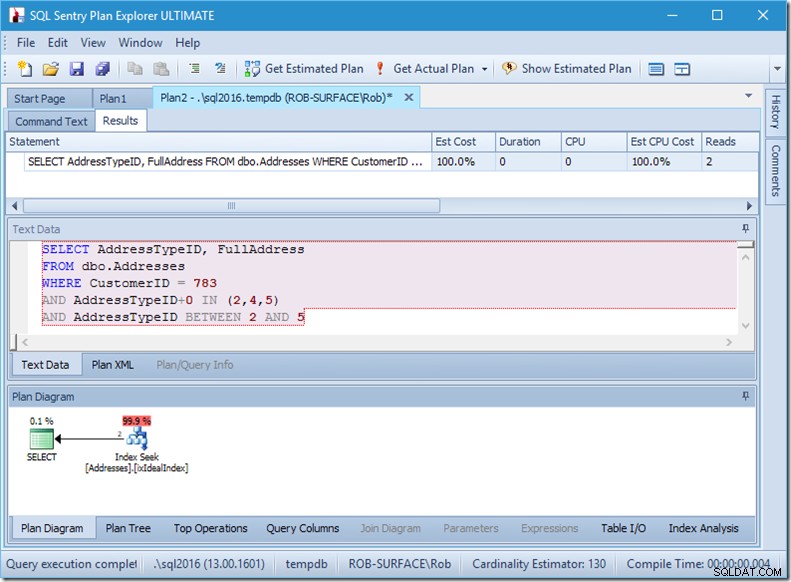
Nu har jag en fin och snäv skanning inom en enda sökning, och jag ser fortfarande till att min fråga bara returnerar de rader jag vill ha.
Åh, men den där Real Rows Read-egenskapen? Det är nu högre än egenskapen Faktiska rader, eftersom sökpredikatet hittar adresstyp 3, vilket restpredikatet avvisar.
Jag har bytt ut tre perfekta sökningar mot en enda imperfekt sökning, som jag fixar med ett kvarvarande predikat.
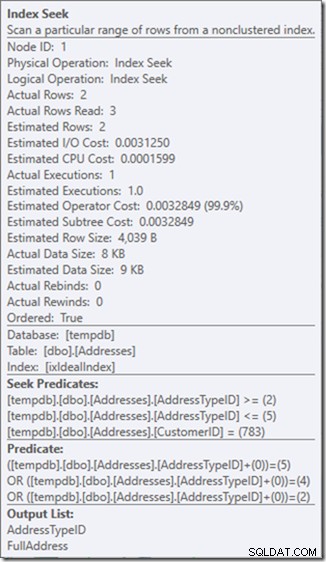
Och för mig är det ibland ett pris värt att betala, och jag får en frågeplan som jag är mycket gladare över. Det är inte nämnvärt billigare, även om det bara har en tredjedel av läsningarna (eftersom det någonsin skulle bli två fysiska läsningar), men när jag tänker på arbetet det gör är jag mycket mer bekväm med vad jag ber om den att göra på det här sättet.