Nuförtiden är det ganska vanligt att ha en databas replikerad i en annan server/datacenter, och det är också ett måste i vissa fall. Det finns olika anledningar att replikera dina databaser till en helt separat miljö.
- Migrera till ett annat datacenter.
- Uppgraderingskrav (hårdvara/programvara).
- Underhåll ett helt synkroniserat operativt system på en Disaster Recovery-webbplats (DR) som kan ta över när som helst
- Behåll en slavdatabas som en del av en billigare DR-plan.
- För krav på geografisk plats (data måste vara lokalt i ett specifikt land).
- Ha en testmiljö.
- Syfte med felsökning.
- Rapporteringsdatabas.
Och det finns olika sätt att utföra denna replikeringsuppgift:
- Säkerhetskopiera/återställa :Att säkerhetskopiera en produktionsdatabas och återställa den i en ny server/miljö är det klassiska sättet att göra detta på, men det är också ett gammaldags sätt eftersom du inte kommer att hålla dina data uppdaterade och du måste vänta för varje återställningsprocess om du behöver lite nyare data. Om du har ett kluster (master-slave, multi-master), och om du vill återskapa det, bör du återställa den initiala säkerhetskopian och sedan återskapa resten av noderna, vilket kan vara en tidskrävande uppgift.
- Klonkluster :Den liknar den föregående men processen för säkerhetskopiering och återställning är för hela klustret, inte bara en specifik databasserver. På detta sätt kan du klona hela klustret i samma uppgift och du behöver inte återskapa resten av noderna manuellt. Denna metod har fortfarande problemet med att hålla data uppdaterad mellan kloner.
- Replikering :Detta sätt inkluderar alternativet för säkerhetskopiering/återställning, men efter den första återställningen kommer replikeringsprocessen att hålla dina data synkroniserade med huvudnoden. På detta sätt, om du har ett databaskluster, måste du återställa säkerhetskopian till en nod och återskapa alla noder manuellt.
I den här bloggen kommer vi att se en ny ClusterControl 1.7.4-funktion som låter dig använda en blandning av metoden som vi nämnde tidigare för att förbättra denna uppgift.
Vad är kluster-till-kluster-replikering?
Replikering mellan två kluster är inte samma sak som att utöka ett kluster till att köras över två datacenter. När vi ställer in replikering mellan två kluster har vi faktiskt två separata system som kan fungera autonomt. Replikering används för att hålla dem synkroniserade, så att slavsystemet har ett uppdaterat tillstånd och kan ta över.
Från ClusterControl 1.7.4 är det möjligt att skapa ett nytt kluster genom att direkt klona ett körande källkluster eller genom att använda en ny säkerhetskopia av källklustret.
Efter kloning av klustret kommer du att ha ett slavkluster (SC) som tar emot data och ett masterkluster (MC) som skickar ändringar till slavklustret.
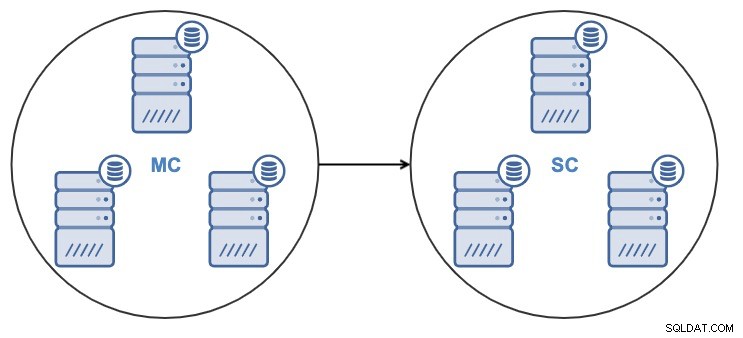
ClusterControl stöder kluster-till-klusterreplikering för följande klustertyper:
- Percona XtraDB Cluster version 5.6.x och senare.
- MariaDB Galera Cluster version 10.x och senare.
- PostgreSQL 9.6 och senare.
Kluster-till-klusterreplikering för Percona XtraDB / MariaDB Galera Cluster
För MySQL-baserade motorer krävs GTID för att använda den här funktionen, och asynkron replikering mellan master- och slavklustret kommer att användas.
Det finns ett par åtgärder att utföra för att förbereda det aktuella klustret för det här jobbet. Först måste minst en nod på det aktuella klustret ha de binära loggarna aktiverade. Sedan måste du lägga till backupanvändaren som konfigurerats i databasnoden i ClusterControl-konfigurationsfilen, som kommer att användas för hanteringsuppgifter. Alla dessa åtgärder kan utföras genom att använda ClusterControl UI eller ClusterControl CLI.
Nu är du redo att skapa Percona XtraDB/MariaDB Galera kluster-till-kluster-replikering. När jobbet är klart har du:
- En nod i slavklustret kommer att replikera från en nod i masterklustret.
- Replikeringen kommer att vara dubbelriktad mellan klustren.
- Alla noder i slavklustret kommer att vara skrivskyddade som standard. Det är möjligt att inaktivera skrivskyddad flagga på noderna en efter en.
- Aktiv-aktiv klustring rekommenderas endast om applikationer endast rör osammanhängande datamängder på något av klustret eftersom motorn inte erbjuder någon konfliktdetektering eller lösning.
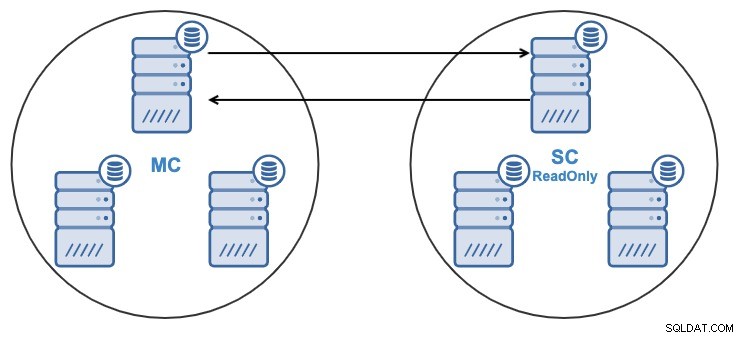
Från både ClusterControl UI eller ClusterControl CLI kommer du att kunna:
- Skapa det här replikeringsklustret.
- Aktivera Active-Active-konfigurationen.
- Ändra klustertopologin.
- Bygg om ett replikeringskluster.
- Stoppa/starta en replikeringsslav.
- Återställ replikeringsslav (endast implementerad med ClusterControl CLI atm).
Överväganden
- Säkerhetskopieringsanvändaren måste läggas till manuellt i ClusterControl-konfigurationsfilen.
- Användaruppgifterna för backup måste vara desamma i både det nuvarande och det nya klustret.
- MySQL-rotlösenordet som angavs när slavklustret skapades måste vara detsamma som root-lösenordet som används i Master-klustret.
Kända begränsningar
- Automatisk failover stöds inte ännu. Om mastern misslyckas, är det administratörens ansvar att failover till en annan master.
- Det är bara möjligt att "ÅTERSTÄLLA" en replikeringsslav från ClusterControl CLI eftersom den inte är implementerad i ClusterControl UI ännu.
- Det är bara möjligt att bygga om ett kluster som är i skrivskyddat läge. Alla noder i ett kluster måste vara skrivskyddade för att räknas som skrivskyddade kluster.
Kluster-till-klusterreplikering för PostgreSQL
ClusterControl Cluster-to-Cluster-replikering stöds på PostgreSQL med strömmande replikering.
Som ett krav måste det finnas en PostgreSQL-server med ClusterControl-rollen 'master', och när du ställer in slavklustret måste administratörsuppgifterna vara identiska med Master Cluster.
Nu är du redo att skapa PostgreSQL-kluster-till-kluster-replikeringen. När jobbet är klart har du:
- En nod i slavklustret kommer att replikera från en nod i masterklustret.
- Replikeringen kommer att vara enkelriktad mellan klustren.
- Noden i slavklustret kommer att vara skrivskyddad.
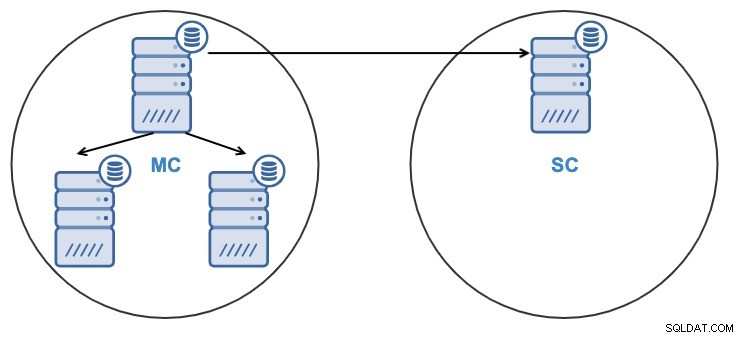
Från både ClusterControl UI eller ClusterControl CLI kommer du att kunna:
- Skapa det här replikeringsklustret.
- Bygg om ett replikeringskluster.
- Stoppa/starta en replikeringsslav.
Övervägande
- Administratörsuppgifterna måste vara identiska i master- och slavklustret.
Kända begränsningar
- Slavklustrets maximala storlek är en nod.
- Slavklustret kan inte iscensättas från en säkerhetskopia.
- Topologiändringar stöds inte.
- Endast enkelriktad replikering stöds.
Slutsats
Med den här nya ClusterControl-funktionen behöver du inte göra varje steg för att skapa en klusterreplikering separat eller manuellt, och som ett resultat av att använda den kommer du att spara tid och ansträngning. Ge det ett försök!