Följande är ett utdrag från vårt whitepaper "Hur man designar högt tillgängliga databasmiljöer med öppen källkod" som kan laddas ner gratis.
Ett par ord om "Hög tillgänglighet"
Idag är hög tillgänglighet ett måste för all seriös driftsättning. Länge borta är dagar då du kunde schemalägga en driftstopp för din databas i flera timmar för att utföra ett underhåll. Om dina tjänster inte är tillgängliga förlorar du kunder och pengar. Att göra en databasmiljö mycket tillgänglig har därför vanligtvis en av de högsta prioriteringarna.
Detta utgör en betydande utmaning för databasadministratörer. Först och främst, hur vet du om din miljö är mycket tillgänglig eller inte? Hur skulle du mäta det? Vilka är stegen du behöver ta för att förbättra tillgängligheten? Hur utformar du din installation för att göra den mycket tillgänglig från början?
Det finns många många HA-lösningar tillgängliga i MySQL (och MariaDB) ekosystem, men hur vet vi vilka vi kan lita på? Vissa lösningar kan fungera under vissa specifika förhållanden, men kan orsaka mer problem när de tillämpas utanför dessa förhållanden. Även en grundläggande funktionalitet som MySQL-replikering, som kan konfigureras på många sätt, kan orsaka betydande skada - till exempel cirkulär replikering med flera skrivbara masters. Även om det är lätt att sätta upp en "multi-master setup" med hjälp av replikering, kan det mycket lätt gå sönder och lämna oss med divergerande datamängder på olika servrar. För en databas, som ofta anses vara den enda källan till sanning, kan äventyrad dataintegritet få katastrofala konsekvenser.
I de följande kapitlen kommer vi att diskutera kraven på hög tillgänglighet i
databasinställningar och hur man designar systemet från grunden.
Mäter hög tillgänglighet
Vad är hög tillgänglighet? För att kunna avgöra om en given miljö är högst tillgänglig eller inte, måste man ha några mått för det. Det finns många sätt du kan mäta hög tillgänglighet, vi kommer att fokusera på några av de mest grundläggande sakerna.
Men låt oss först fundera på vad hela denna höga tillgänglighet handlar om? Vad är dess syfte? Det handlar om att se till att din miljö tjänar sitt syfte. Syfte kan definieras på många sätt, men vanligtvis handlar det om att leverera någon tjänst. I databasvärlden är det vanligtvis något relaterat till data. Det kan vara att skicka data till din interna applikation. Det kan vara att lagra data och göra den frågbar genom analytiska processer. Det kan vara att lagra en del data för dina användare, och tillhandahålla den vid efterfrågan. När vi är tydliga med syftet kan vi fastställa vilka framgångsfaktorer som är involverade. Detta kommer att hjälpa oss att definiera vad hög tillgänglighet betyder i vårt specifika fall.
SLA
Service Level Agreement (SLA). Det är också ganska vanligt att definiera SLA för interna tjänster. Vad är en SLA? Det är en definition av den servicenivå du planerar att tillhandahålla dina kunder. Detta är för att de bättre ska förstå vilken stabilitetsnivå du planerar för en tjänst de köpt eller planerar att köpa. Det finns många metoder du kan använda för att förbereda en SLA men typiska är:
- Tjänstens tillgänglighet (procent)
- Tjänstens lyhördhet – latens (genomsnitt, max, 95 percentil, 99 percentil)
- Paketförlust över nätverket (procent)
- Genomsnittlig kapacitet (genomsnitt, minimum, 95 percentil, 99 percentil)
Det kan dock bli mer komplicerat än så. I en delad miljö med flera användare kan du definiera, låt oss säga, din SLA som:"Tjänsten kommer att vara tillgänglig 99,99 % av tiden, driftstopp deklareras när mer än 2 % av användarna påverkas. Ingen incident kan ta mer än 15 minuter att lösa”. Sådan SLA kan också utökas för att inkludera frågesvarstid:"avbrottstid anropas om 99 percentilen av latens för frågor överstiger 200 millisekunder".
Nio
Tillgänglighet mäts vanligtvis i "nior", låt oss titta närmare på vad exakt en given mängd "nio" garanterar. Tabellen nedan är hämtad från Wikipedia:
| Tillgänglighet % | Nedtid per år | Nedtid per månad | Nedtid per vecka | Nedtid per dag |
|---|---|---|---|---|
| 90 % ("en nio") | 36,5 dagar | 72 timmar | 16,8 timmar | 2,4 timmar |
| 95 % ("ett och en halv nio") | 18,25 dagar | 36 timmar | 8,4 timmar | 1,2 timmar |
| 97 % | 10,96 dagar | 21,6 timmar | 5.04 timmar | 43,2 min |
| 98 % | 7.30 dagar | 14,4 timmar | 3,36 timmar | 28,8 min |
| 99 % ("två nior") | 3,65 dagar | 7.20 timmar | 1,68 timmar | 14,4 min |
| 99,5 % ("två och en halv nior") | 1,83 dagar | 3,60 timmar | 50,4 min | 7,2 min |
| 99,8 % | 17.52 timmar | 86,23 min | 20,16 min | 2,88 min |
| 99,9 % ("tre nior") | 8,76 timmar | 43,8 min | 10,1 min | 1,44 min |
| 99,95 % ("tre och en halv nior") | 4,38 timmar | 21,56 min | 5,04 min | 43,2 s |
| 99,99 % ("fyra nior") | 52,56 min | 4,38 min | 1,01 min | 8,64 s |
| 99,995 % ("fyra och en halv nio") | 26,28 min | 2,16 min | 30,24 s | 4.32 s |
| 99,999 % ("fem nior") | 5,26 min | 25,9 s | 6.05 s | 864,3 ms |
| 99,9999 % ("sex nior") | 31,5 s | 2,59 s | 604,8 ms | 86,4 ms |
| 99,99999 % ("sju nior") | 3,15 s | 262,97 ms | 60,48 ms | 8,64 ms |
| 99,999999 % ("åtta nior") | 315,569 ms | 26,297 ms | 6,048 ms | 0,864 ms |
| 99,9999999 % ("nio nior") | 31,5569 ms | 2,6297 ms | 0,6048 ms | 0,0864 ms |
Som vi kan se eskalerar det snabbt. Fem nior (99 999 % tillgänglighet) motsvarar 5,26 minuters driftstopp under loppet av ett år. Tillgänglighet kan också beräknas i olika, mindre intervall:per månad, per vecka, per dag. Tänk på dessa siffror, eftersom de kommer att vara användbara när vi börjar diskutera kostnaderna för att upprätthålla olika tillgänglighetsnivåer.
Mäta tillgänglighet
För att avgöra om det är stillestånd eller inte måste man ha insikt i miljön. Du måste spåra de mätvärden som definierar tillgängligheten för dina system. Det är viktigt att komma ihåg att du bör mäta det ur en kunds synvinkel och ta den bredare bilden i beaktande. Det spelar ingen roll om dina databaser är uppe om, låt oss säga, på grund av ett nätverksproblem, ingen applikation inte kan nå dem. Varje enskild byggsten i din installation har sin inverkan på tillgängligheten.
Ett av de bra ställena att leta efter tillgänglighetsdata är webbserverloggar. Alla förfrågningar som slutade med fel betyder att något har hänt. Det kan vara HTTP-fel 500 som returneras av programmet, eftersom databasanslutningen misslyckades. Det kan vara programmatiska fel som pekar på vissa databasproblem och som hamnade i Apaches fellogg. Du kan också använda enkel statistik som drifttid för databasservrar, även om det med mer komplexa SLA:er kan vara svårt att avgöra hur otillgängligheten av en databas påverkade din användarbas. Oavsett vad du gör bör du använda mer än ett mått - detta behövs för att fånga problem som kan ha hänt på olika lager i din miljö.
Magiskt nummer:"Tre"
Även om hög tillgänglighet också handlar om redundans, är tre vid databaskluster ett magiskt tal. Det räcker inte att ha två noder för redundans – en sådan setup ger ingen inbyggd hög tillgänglighet. Visst, det kan vara bättre än bara en enda nod, men mänskligt ingripande krävs för att återställa tjänster. Låt oss se varför det är så.
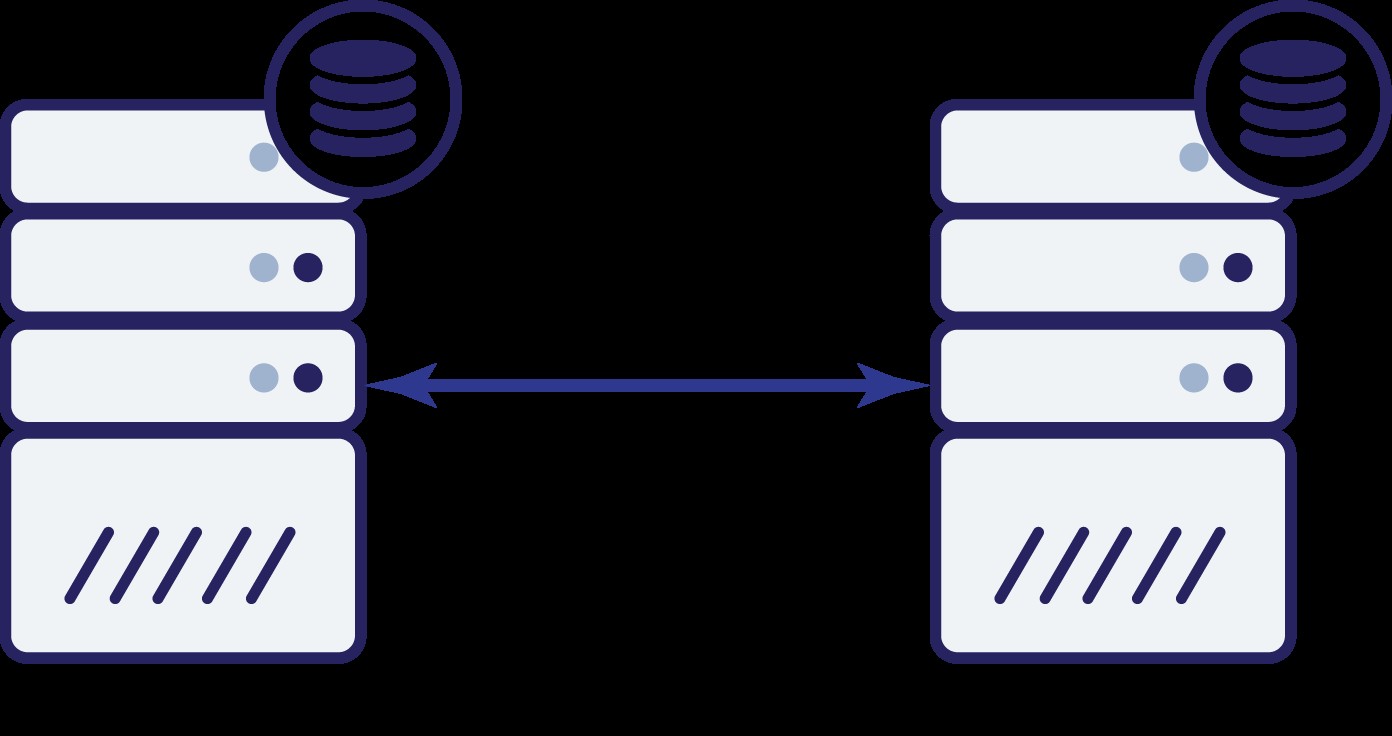
Låt oss anta att vi har två noder, A och B. Det finns en nätverkslänk mellan dem. Låt oss anta att både A och B betjänar skrivningar och applikationen väljer slumpmässigt var den ska ansluta (vilket innebär att en del av applikationen kommer att ansluta till nod A och den andra delen kommer att ansluta till nod B). Låt oss nu föreställa oss att vi har ett nätverksproblem som resulterar i förlorad nätverksanslutning mellan A och B.
Och nu då? Varken A eller B kan känna till tillståndet för den andra noden. Det finns två åtgärder som kan utföras av båda noderna:
- De kan fortsätta acceptera trafik
- De kan sluta fungera och vägra betjäna all trafik
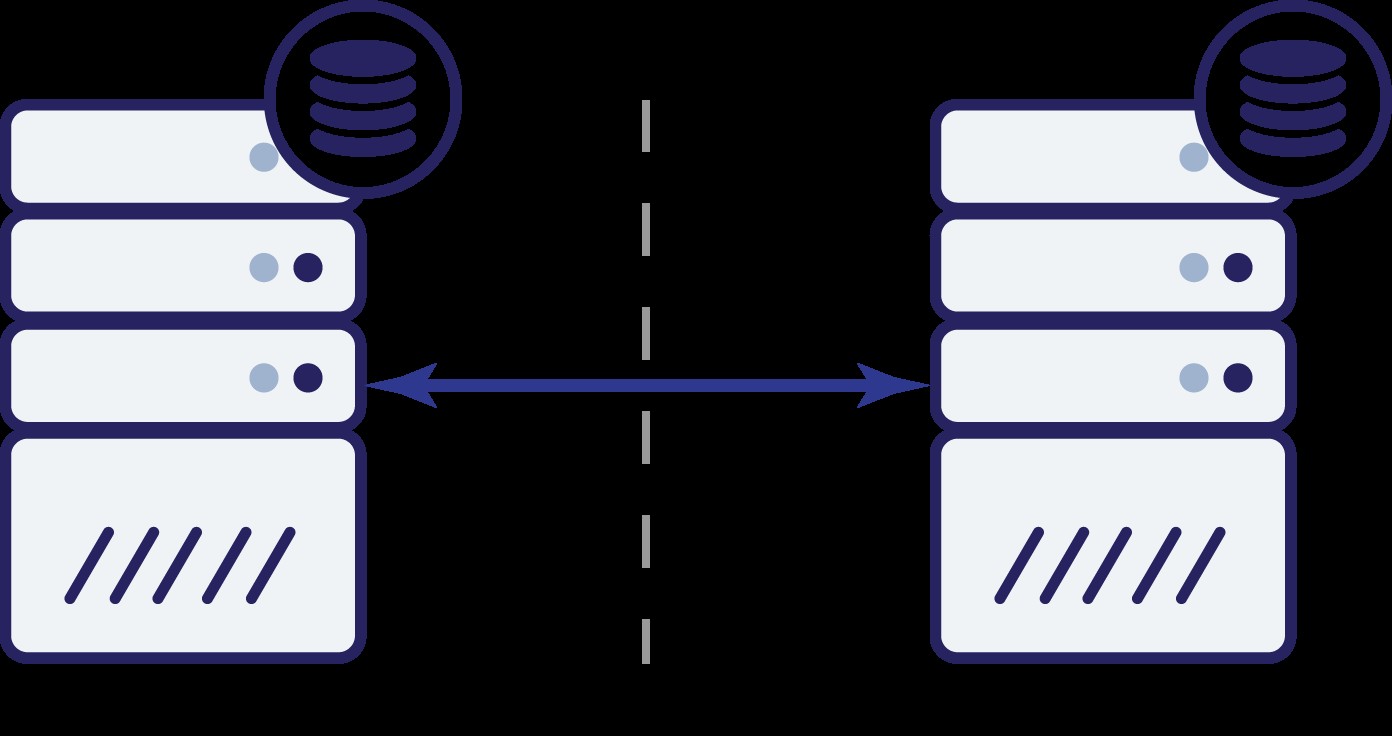
Låt oss tänka på det första alternativet. Så länge den andra noden verkligen är nere är detta den föredragna åtgärden att vidta - vi vill att vår databas ska fortsätta betjäna trafik. Detta är trots allt huvudtanken bakom hög tillgänglighet. Vad skulle dock hända om båda noderna skulle fortsätta att acceptera trafik samtidigt som de kopplas bort från varandra? Ny data kommer att läggas till på båda sidor och datamängderna kommer att bli osynkroniserade. När nätverksproblemet kommer att lösas kommer det att vara en svår uppgift att slå samman dessa två datamängder. Därför är det inte acceptabelt att hålla båda noderna igång. Problemet är - hur kan nod A se om nod B lever eller inte (och vice versa)? Svaret är - det kan det inte. Om all anslutning är nere finns det inget sätt att skilja en misslyckad nod från ett misslyckat nätverk. Som ett resultat är den enda säkra åtgärden att båda noderna upphör med all verksamhet och vägrar
betjäna trafik.
Låt oss nu fundera på hur en tredje nod kan hjälpa oss i en sådan situation.
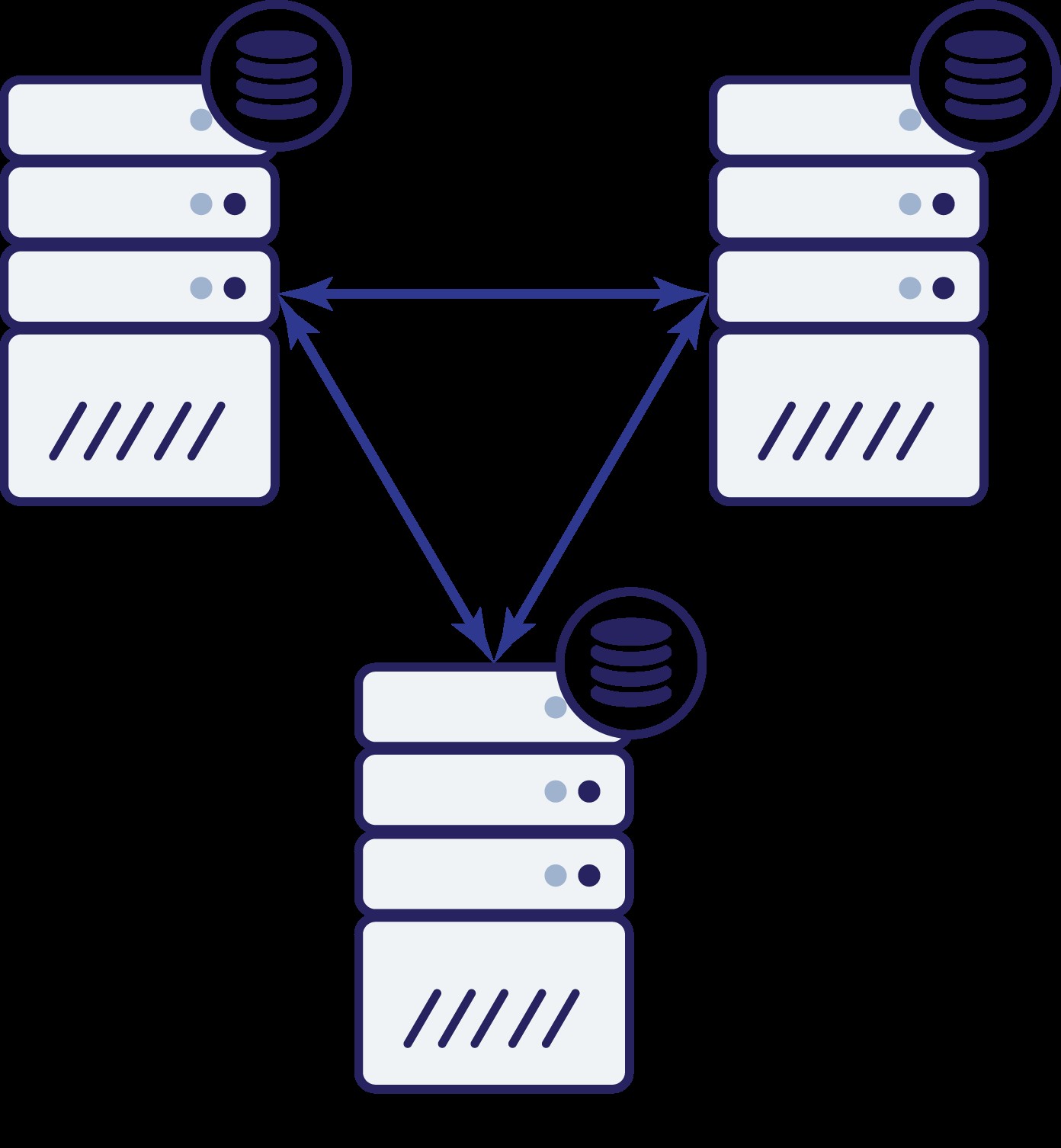
Så vi har nu tre noder:A, B och C. Alla är sammankopplade, alla hanterar läsningar och skrivningar.
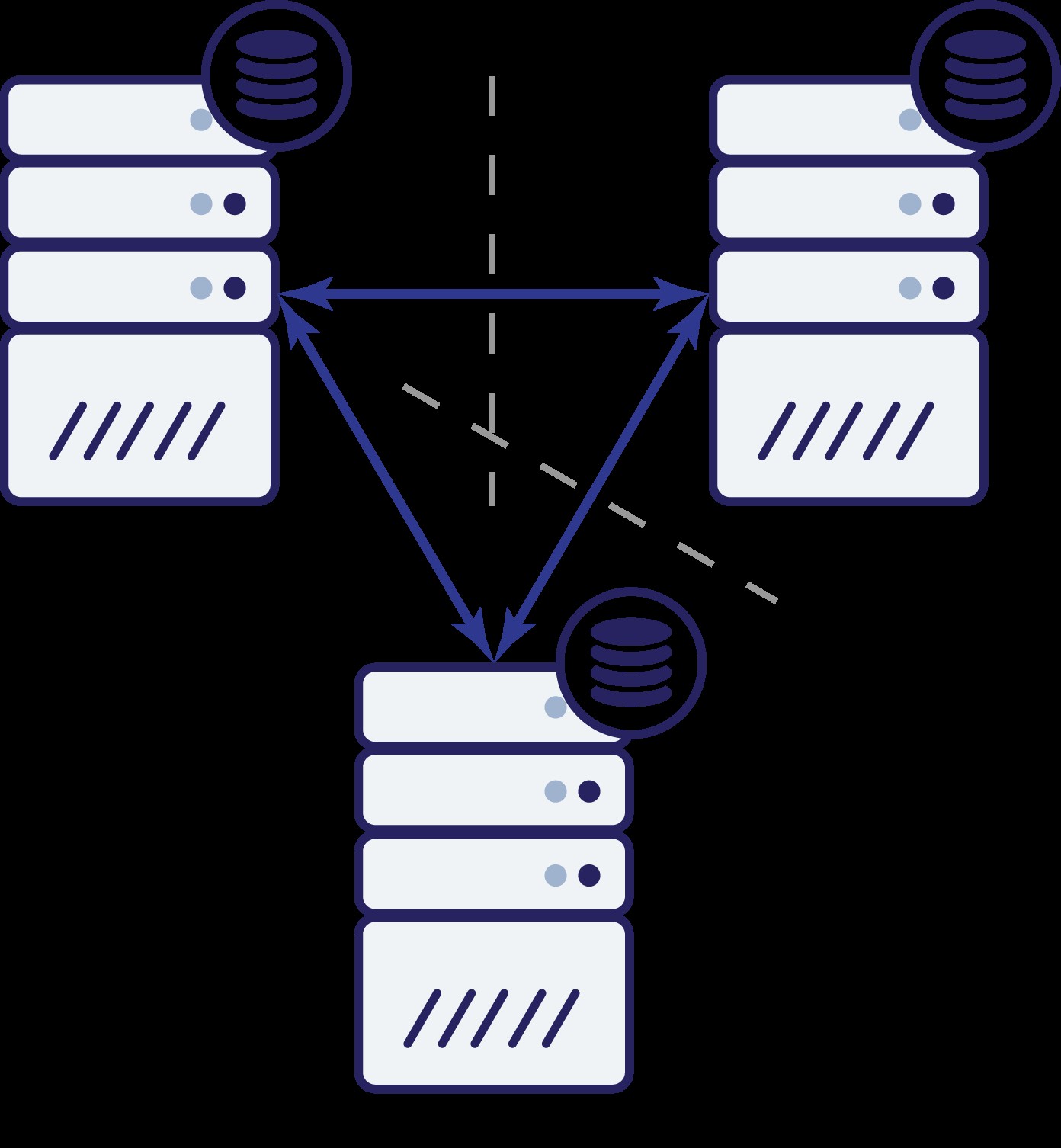
Återigen, som i föregående exempel, har nod B stängts av från resten av klustret på grund av nätverksproblem. Vad kan hända härnäst? Tja, situationen är ganska lik vad vi diskuterade tidigare. Två alternativ - nod B kan antingen vara nere (och resten av klustret ska fortsätta) eller så kan den vara uppe, i vilket fall den inte ska tillåtas hantera någon trafik. Kan vi nu berätta vad klustrets tillstånd är? Faktiskt ja. Vi kan se att nod A och C kan prata med varandra och som ett resultat kan de komma överens om att nod B inte är tillgänglig. De kommer inte att kunna berätta varför det hände, men vad de vet är att av tre noder i klustret har två fortfarande anslutning mellan varandra. Med tanke på att dessa två noder utgör en majoritet av klustret, gör det möjligt att fortsätta hantera trafik. Samtidigt kan nod B också dra av att problemet är på sin sida. Den kan inte komma åt varken nod A eller nod C, vilket gör nod B separerad från resten av klustret. Eftersom den är isolerad och inte är en del av en majoritet (1 av 3), är den enda säkra åtgärden den kan vidta att sluta betjäna trafik och vägra acceptera några frågor, vilket säkerställer att datadrift inte inträffar.
Naturligtvis betyder det inte att du bara kan ha tre noder i klustret. Om du vill ha bättre misslyckandetolerans kanske du vill lägga till fler. Kom dock ihåg att det bör vara ett udda nummer om du vill förbättra hög tillgänglighet. Vi pratade också om "noder" i exemplen ovan. Tänk på att detta även gäller för datacenter, tillgänglighetszoner etc. Om du har två datacenter, som var och en har samma antal noder (låt oss säga tre noder vardera), och du förlorar anslutningen mellan dessa två DC, gäller samma principer här - Du kan inte säga vilken halva av klustret som ska börja hantera trafik. För att kunna berätta det måste du ha en observatör i ett tredje datacenter. Det kan vara ytterligare en uppsättning noder, eller bara en enda värd, med uppgiften
att observera tillståndet för återstående datacetrar och delta i att fatta beslut (ett exempel här skulle vara Galera-medlaren).
Enstaka felpunkter
Hög tillgänglighet handlar om att ta bort single points of failure (SPOF) och inte introducera nya i processen. Vilka är SPOF? Varje del av din infrastruktur som, när den misslyckas, ger driftstopp enligt definitionen i SLA, kallas en SPOF. Infrastrukturdesign kräver ett helhetsgrepp, de olika komponenterna kan inte utformas oberoende av varandra. Troligtvis är du inte ansvarig för hela designen -
databasadministratörer tenderar att fokusera på databaser och inte till exempel nätverkslagret. Ändå måste du ha de andra delarna i åtanke och arbeta med teamen som är ansvariga för dem, för att se till att inte bara den del du ansvarar för är korrekt utformad utan också att de återstående delarna av infrastrukturen designades med hjälp av samma principer. Utöver det, sådan kunskap om hur hela
infrastrukturen är utformad, hjälper dig också att designa databasstacken. Att veta vilka problem som kan hända hjälper till att bygga vissa mekanismer för att förhindra att de påverkar tillgängligheten för databasen.