Att flytta din data till en offentlig molntjänst är ett stort beslut. Alla stora molnleverantörer erbjuder molndatabastjänster, där Amazon RDS för MySQL förmodligen är den mest populära.
I den här bloggen kommer vi att titta närmare på vad det är, hur det fungerar och jämföra dess för- och nackdelar.
RDS (Relational Database Service) är ett Amazon Web Services-erbjudande. Kort sagt är det en Database as a Service, där Amazon distribuerar och driver din databas. Den tar hand om uppgifter som säkerhetskopiering och patchning av databasprogramvaran, samt hög tillgänglighet. Ett fåtal databaser stöds av RDS, men vi är här främst intresserade av MySQL - Amazon stöder MySQL och MariaDB. Det finns också Aurora, som är Amazons klon av MySQL, förbättrad, särskilt när det gäller replikering och hög tillgänglighet.
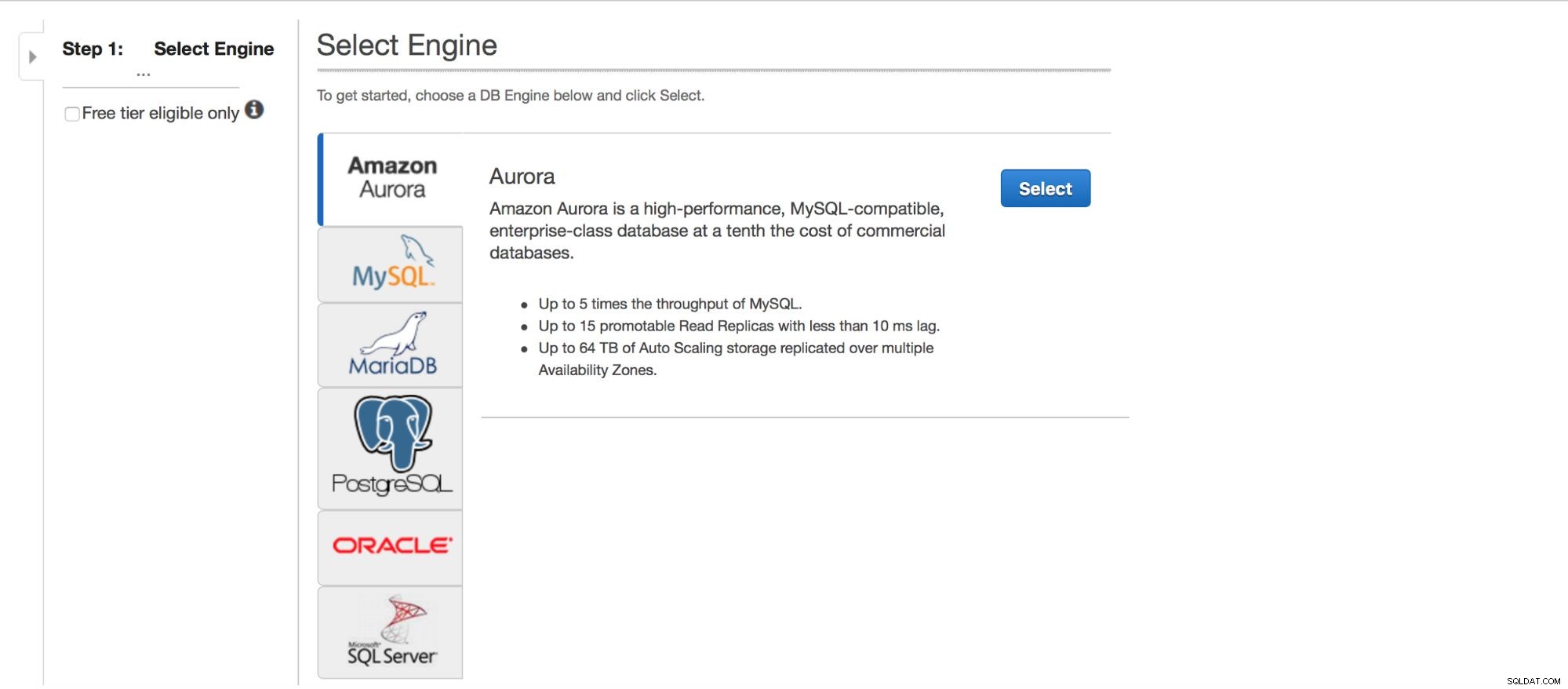
Distribuera MySQL via RDS
Låt oss ta en titt på distributionen av MySQL via RDS. Vi valde MySQL och sedan presenteras vi för ett par distributionsmönster att välja mellan.
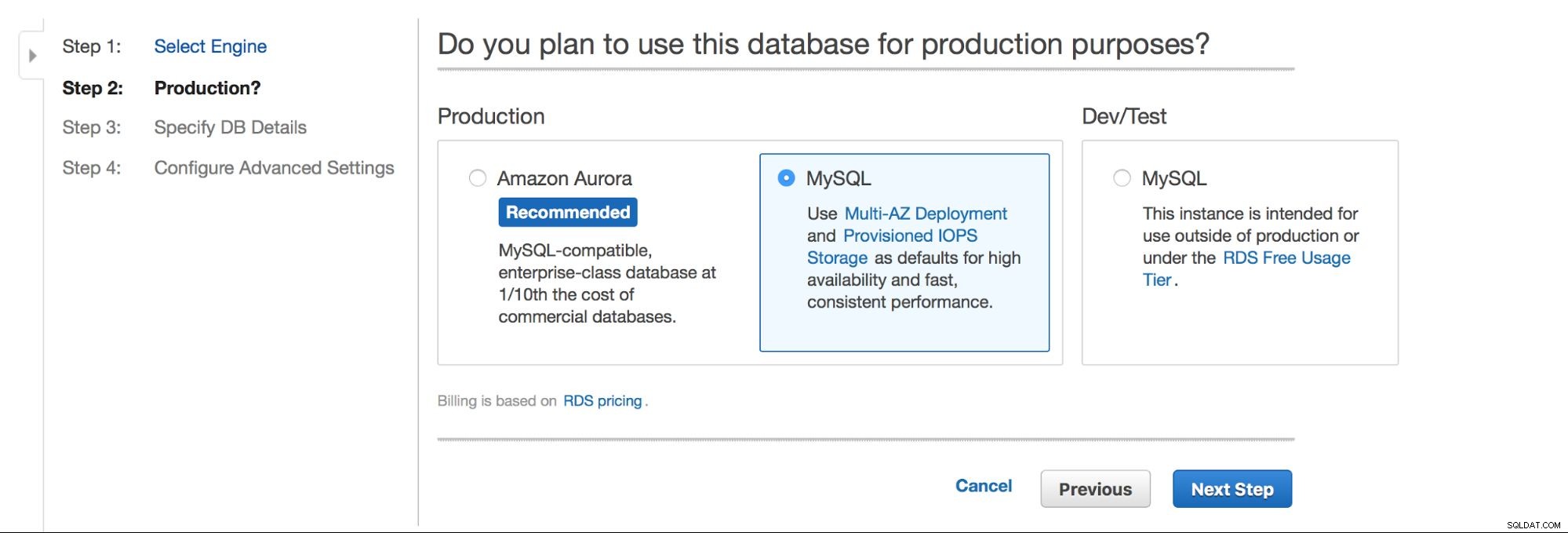
Huvudvalet är – vill vi ha hög tillgänglighet eller inte? Aurora marknadsförs också.
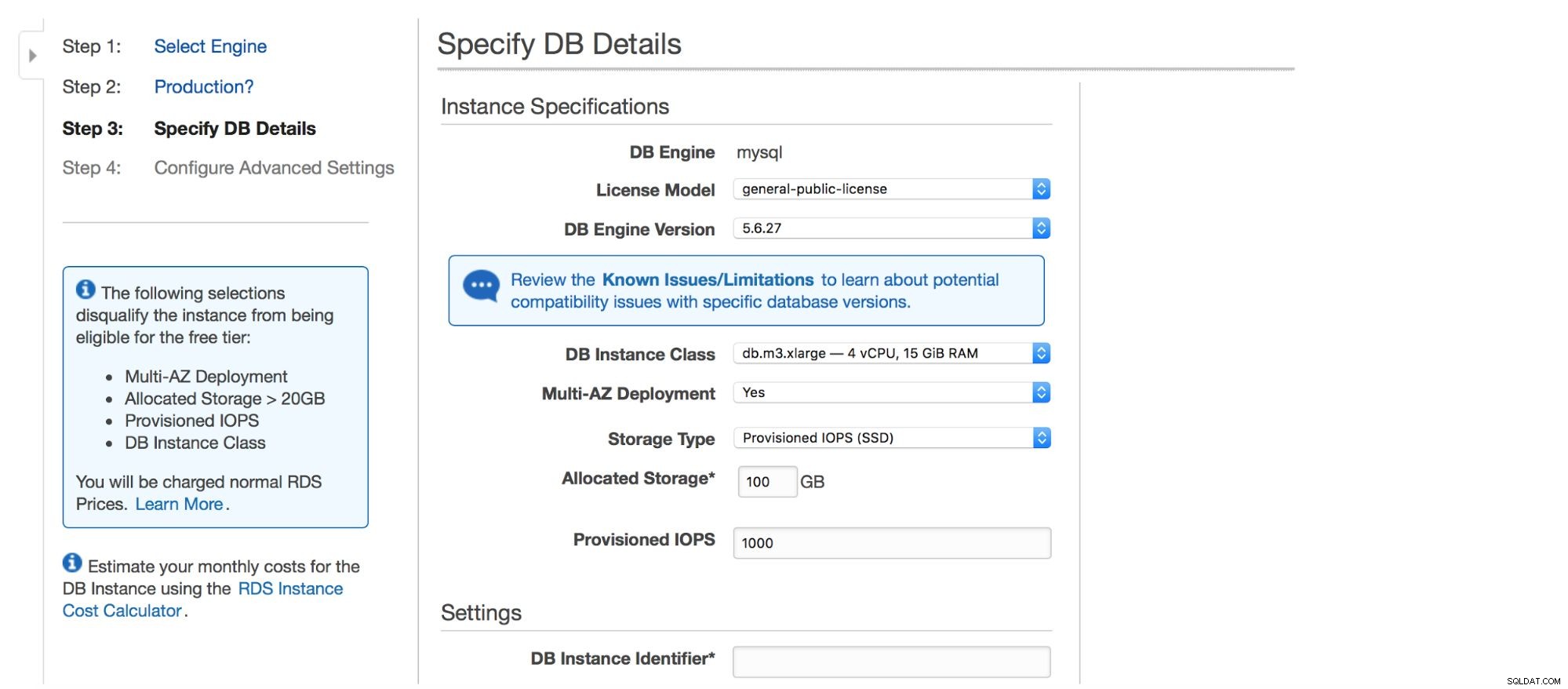
Nästa dialogruta ger oss några alternativ att anpassa. Du kan välja en av många MySQL-versioner - flera 5.5, 5.6 och 5.7 versioner är tillgängliga. Databasinstans – du kan välja mellan typiska instansstorlekar som är tillgängliga i en viss region.
Nästa alternativ är ett ganska viktigt val - vill du använda multi-AZ-distribution eller inte? Allt handlar om hög tillgänglighet. Om du inte vill använda multi-AZ-distribution kommer en enda instans att installeras. I händelse av fel kommer en ny att snurras upp och dess datavolym kommer att återmonteras till den. Denna process tar lite tid, under vilken din databas inte kommer att vara tillgänglig. Naturligtvis kan du minimera denna påverkan genom att använda slavar och marknadsföra en av dem, men det är inte en automatiserad process. Om du vill ha automatiserad hög tillgänglighet bör du använda multi-AZ-distribution. Det som kommer att hända är att två databasinstanser kommer att skapas. En är synlig för dig. En andra instans, i en separat tillgänglighetszon, är inte synlig för användaren. Den kommer att fungera som en skuggkopia, redo att ta över trafiken när den aktiva noden misslyckas. Det är fortfarande inte en perfekt lösning eftersom trafiken måste bytas från den misslyckade instansen till den skuggiga. I våra tester tog det ~45s att utföra en failover, men det kan naturligtvis bero på instansstorlek, I/O-prestanda etc. Men det är mycket bättre än icke-automatiserad failover där endast slavar är inblandade.
Slutligen har vi lagringsinställningar - typ, storlek, PIOPS (i tillämpliga fall) och databasinställningar - identifierare, användare och lösenord.
I nästa steg väntar några fler alternativ på användarinput.
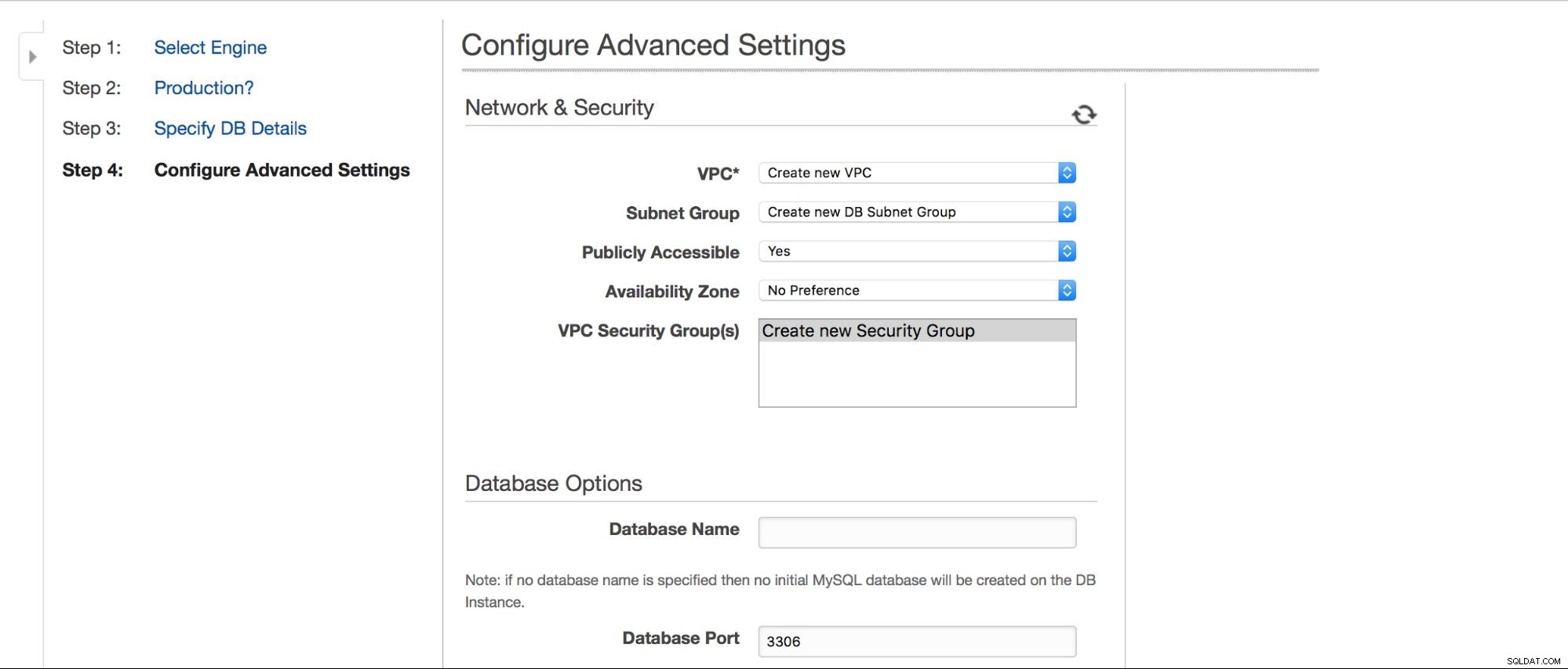
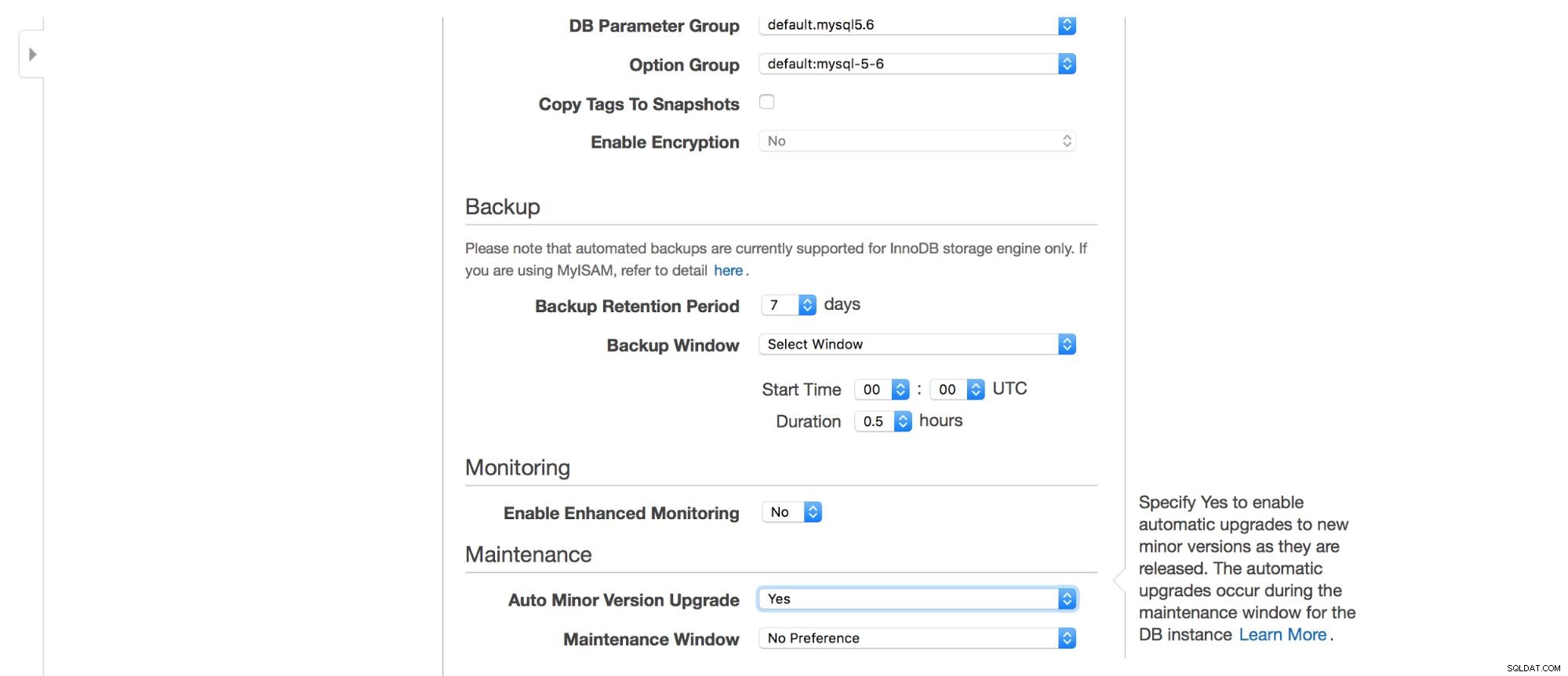
Vi kan välja var instansen ska skapas:VPC, subnät, om den ska vara allmänt tillgänglig eller inte (som i - ska en offentlig IP tilldelas RDS-instansen), tillgänglighetszon och VPC Security Group. Sedan har vi databasalternativ:första schemat som ska skapas, port-, parameter- och alternativgrupper, om metadatataggar ska inkluderas i ögonblicksbilder eller inte, krypteringsinställningar.
Därefter, alternativ för säkerhetskopiering – hur länge vill du behålla dina säkerhetskopior? När vill du att de ska tas? Liknande installation är relaterad till underhåll - ibland måste Amazon-administratörer utföra underhåll på din RDS-instans - det kommer att ske inom ett fördefinierat fönster som du kan ställa in här. Observera att det inte finns något alternativ att inte välja minst 30 minuter för underhållsfönstret, det är därför det är väldigt viktigt att ha multi-AZ-instanser i produktion. Underhåll kan resultera i omstart av noden eller brist på tillgänglighet under en tid. Utan multi-AZ måste du acceptera den driftstoppen. Med multi-AZ-distribution sker failover.
Slutligen har vi inställningar relaterade till ytterligare övervakning - vill vi ha det aktiverat eller inte?
Hantera RDS
I det här kapitlet kommer vi att titta närmare på hur man hanterar MySQL RDS. Vi kommer inte att gå igenom alla tillgängliga alternativ där ute, men vi vill lyfta fram några av funktionerna som Amazon har gjort tillgängliga.
Ögonblicksbilder
MySQL RDS använder EBS-volymer som lagring, så det kan använda EBS-ögonblicksbilder för olika ändamål. Säkerhetskopiering, slavar - allt baserat på ögonblicksbilder. Du kan skapa ögonblicksbilder manuellt eller så kan de tas automatiskt när ett sådant behov uppstår. Det är viktigt att komma ihåg att EBS-ögonblicksbilder i allmänhet (inte bara på RDS-instanser), lägger till en del overhead till I/O-operationer. Om du vill ta en ögonblicksbild, förvänta dig att din I/O-prestanda sjunker. Såvida du inte använder multi-AZ-distribution, det vill säga. I sådana fall kommer "skugga"-instansen att användas som en källa till ögonblicksbilder och ingen påverkan kommer att vara synlig på produktionsinstansen.
Severalnines DevOps Guide to Database ManagementLär dig om vad du behöver veta för att automatisera och hantera dina databaser med öppen källkod Ladda ner gratisSäkerhetskopiering
Säkerhetskopieringar är baserade på ögonblicksbilder. Som nämnts ovan kan du definiera ditt backupschema och retention när du skapar en ny instans. Naturligtvis kan du redigera dessa inställningar efteråt, genom alternativet "ändra instans".
Du kan när som helst återställa en ögonblicksbild - du måste gå till avsnittet ögonblicksbild, välja den ögonblicksbild du vill återställa, och du kommer att presenteras med en dialogruta som liknar den du såg när du skapade en ny instans. Detta är inte en överraskning eftersom du bara kan återställa en ögonblicksbild till en ny instans - det finns inget sätt att återställa den på en av de befintliga RDS-instanserna. Det kan komma som en överraskning, men även i molnmiljö kan det vara vettigt att återanvända hårdvara (och instanser du redan har). I en delad miljö kan prestandan för en enda virtuell instans skilja sig – du kanske föredrar att hålla dig till den prestandaprofil som du redan är bekant med. Tyvärr är det inte möjligt i RDS.
Ett annat alternativ i RDS är punkt-i-tidsåterställning – mycket viktig funktion, ett krav för alla som behöver ta väl hand om hennes data. Här är saker mer komplexa och mindre ljusa. Till att börja med är det viktigt att komma ihåg att MySQL RDS döljer binära loggar från användaren. Du kan ändra ett par inställningar och lista skapade binloggar, men du har inte direkt tillgång till dem - för att göra någon åtgärd, inklusive använda dem för återställning, kan du bara använda UI eller CLI. Detta begränsar dina alternativ till vad Amazon tillåter dig att göra, och det låter dig återställa din säkerhetskopia upp till den senaste "återställbara tiden" som råkar beräknas i 5 minuters intervall. Så om din data har tagits bort klockan 9:33a kan du återställa den endast upp till tillståndet klockan 9:30a. Tidpunktsåterställning fungerar på samma sätt som att återställa ögonblicksbilder – en ny instans skapas.
Utskalning, replikering
MySQL RDS tillåter utskalning genom att lägga till nya slavar. När en slav skapas tas en ögonblicksbild av mastern och den används för att skapa en ny värd. Den här delen fungerar ganska bra. Tyvärr kan du inte skapa någon mer komplex replikeringstopologi som en som involverar mellanliggande masters. Du kan inte skapa en master - master setup, som lämnar någon HA i händerna på Amazon (och multi-AZ-distributioner). Vad vi kan säga finns det inget sätt att aktivera GTID (inte för att du skulle kunna dra nytta av det eftersom du inte har någon kontroll över replikeringen, ingen CHANGE MASTER i RDS), bara vanliga, gammaldags binlog-positioner.
Brist på GTID gör det inte möjligt att använda flertrådsreplikering - medan det är möjligt att ställa in ett antal arbetare med RDS-parametergrupper, utan GTID är detta oanvändbart. Huvudproblemet är att det inte finns något sätt att lokalisera en enda binär loggposition i händelse av en krasch - vissa arbetare kunde ha varit bakom, andra kunde vara mer avancerade. Om du använder den senast tillämpade händelsen kommer du att förlora data som ännu inte har tillämpats av de "släpande" arbetarna. Om du kommer att använda den äldsta händelsen kommer du med största sannolikhet att få "duplicerade nyckel"-fel orsakade av händelser som tillämpas av de arbetare som är mer avancerade. Naturligtvis finns det ett sätt att lösa det här problemet, men det är inte trivialt och det är tidskrävande - definitivt inget du lätt kan automatisera.
Användare som skapats på MySQL RDS har inte SUPER-privilegier så operationer, som är enkla i fristående MySQL, är inte triviala i RDS. Amazon bestämde sig för att använda lagrade procedurer för att ge användaren möjlighet att utföra några av dessa operationer. Vad vi kan säga täcks ett antal potentiella problem även om det inte alltid har varit fallet - vi kommer ihåg när du inte kunde rotera till nästa binära logg på mastern. En masterkrasch + binlogkorruption kan göra alla slavar trasiga - nu finns det en procedur för det:rds_next_master_log .
En slav kan manuellt befordras till en master. Detta skulle tillåta dig att skapa någon sorts HA ovanpå multi-AZ-mekanismen (eller kringgå den) men det har gjorts meningslöst av det faktum att du inte kan omslava någon av befintliga slavar till den nya mastern. Kom ihåg att du inte har någon kontroll över replikeringen. Detta gör hela övningen meningslös - om inte din mästare kan ta emot all din trafik. Efter att ha marknadsfört en ny master kan du inte göra failover till den eftersom den inte har några slavar för att hantera din belastning. Att snurra upp nya slavar kommer att ta tid eftersom EBS-ögonblicksbilder måste skapas först och detta kan ta timmar. Sedan måste du värma upp infrastrukturen innan du kan belasta den.
Brist på SUPER-privilegier
Som vi nämnde tidigare ger RDS inte användarna SUPER-privilegier och detta blir irriterande för någon som är van vid att ha det på MySQL. Ta det för givet att du under de första veckorna kommer att lära dig hur ofta det krävs att du gör saker som du gör ganska ofta - som att döda frågor eller använda prestandaschemat. I RDS måste du hålla dig till en fördefinierad lista över lagrade procedurer och använda dem istället för att göra saker direkt. Du kan lista alla med följande fråga:
SELECT specific_name FROM information_schema.routines;Precis som med replikering täcks ett antal uppgifter, men om du hamnade i en situation som ännu inte är täckt, har du ingen tur.
Interoperabilitet och hybridmolninställningar
Detta är ett annat område där RDS saknar flexibilitet. Låt oss säga att du vill bygga en blandad moln/lokal installation - du har en RDS-infrastruktur och du vill skapa ett par slavar på plats. Det största problemet du kommer att ställas inför är att det inte finns något sätt att flytta data från RDS förutom att ta en logisk dumpning. Du kan ta ögonblicksbilder av RDS-data men du har inte tillgång till dem och du kan inte flytta dem bort från AWS. Du har inte heller fysisk tillgång till instansen för att använda xtrabackup, rsync eller ens cp. Det enda alternativet för dig är att använda mysqldump, mydumper eller liknande verktyg. Detta ökar komplexiteten (teckenuppsättning och sorteringsinställningar kan orsaka problem) och är tidskrävande (det tar lång tid att dumpa och ladda data med hjälp av logiska säkerhetskopieringsverktyg).
Det är möjligt att ställa in replikering mellan RDS och en extern instans (på båda sätten, så att migrera data till RDS är också möjligt), men det kan vara en mycket tidskrävande process.
Å andra sidan, om du vill stanna i en RDS-miljö och spänna din infrastruktur över Atlanten eller från USA:s öst- till västkust, låter RDS dig göra det - du kan enkelt välja en region när du skapar en ny slav.
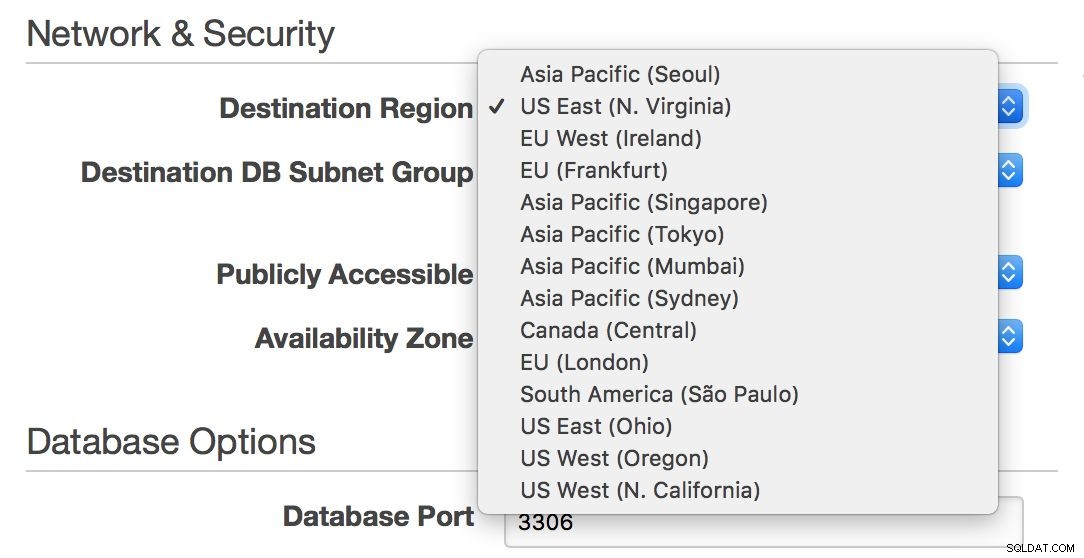
Tyvärr, om du vill flytta din master från en region till en annan, är detta praktiskt taget inte möjligt utan driftstopp - om inte din enda nod kan hantera all din trafik.
Säkerhet
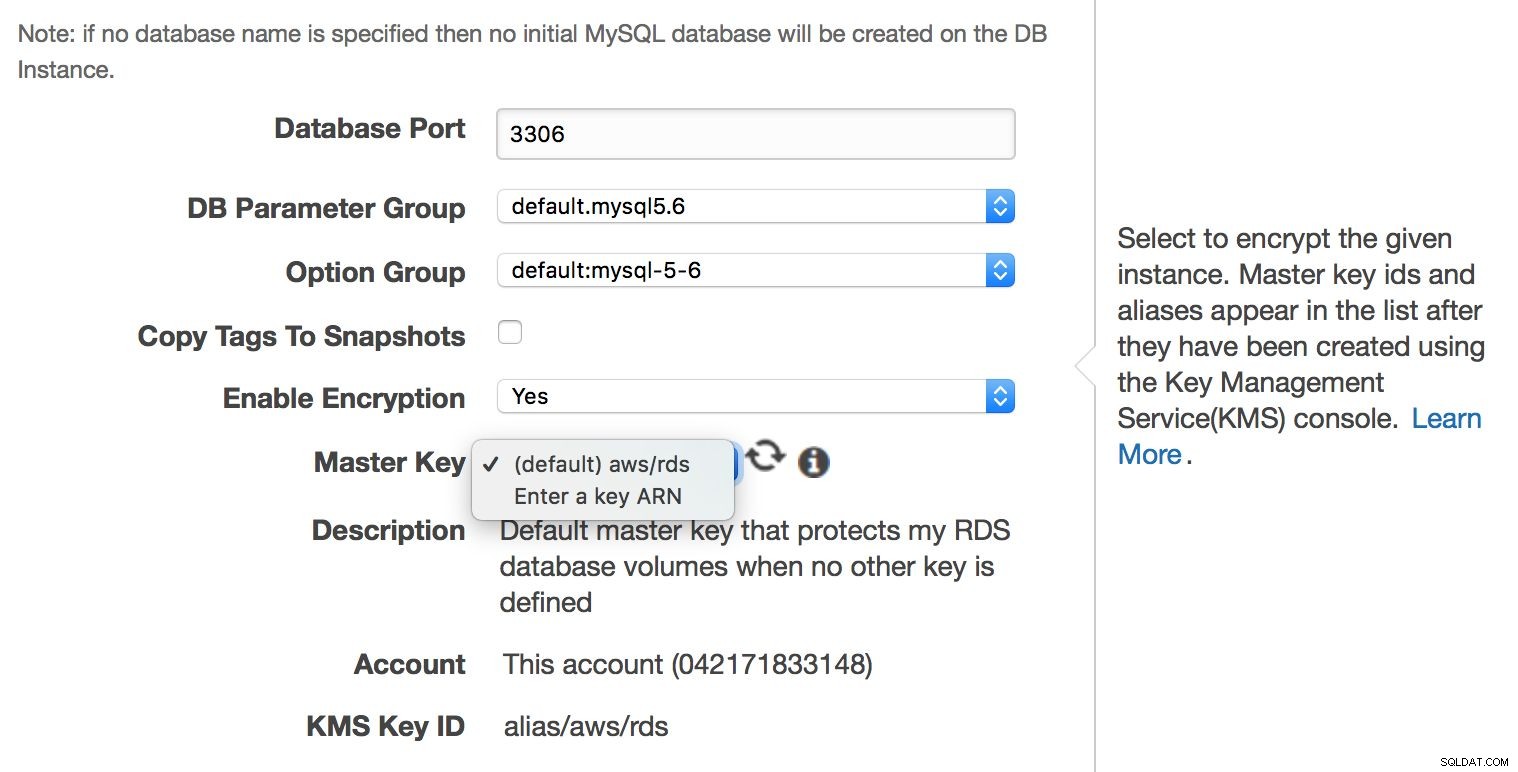
Även om MySQL RDS är en hanterad tjänst, tas inte alla aspekter relaterade till säkerhet om hand av Amazons ingenjörer. Amazon kallar det "Delat ansvarsmodell". Kort sagt tar Amazon hand om säkerheten för nätverket och lagringslagret (så att data överförs på ett säkert sätt), operativsystem (patchar, säkerhetsfixar). Å andra sidan måste användaren ta hand om resten av säkerhetsmodellen. Se till att trafik till och från RDS-instansen är begränsad inom VPC, se till att autentisering på databasnivå görs på rätt sätt (inga lösenordlösa MySQL-användarkonton), verifiera att API-säkerhet är säkerställd (AMI:er är korrekt inställda och med minimala nödvändiga privilegier). Användaren bör också ta hand om brandväggsinställningar (säkerhetsgrupper) för att minimera exponeringen av RDS och den VPC den är i för externa nätverk. Det är också användarens ansvar att implementera data i viloläge - antingen på applikationsnivå eller på databasnivå, genom att skapa en krypterad RDS-instans i första hand.
Kryptering på databasnivå kan endast aktiveras när instansen skapas, du kan inte kryptera en befintlig databas som redan körs.
RDS-begränsningar
Om du planerar att använda RDS eller om du redan använder det, måste du vara medveten om begränsningar som följer med MySQL RDS.
Avsaknad av SUPER-behörighet kan, som vi nämnde, vara väldigt irriterande. Medan lagrade procedurer tar hand om ett antal operationer, är det en inlärningskurva eftersom du behöver lära dig att göra saker på ett annat sätt. Brist på SUPER-privilegier kan också skapa problem med att använda externa övervaknings- och trendverktyg - det finns fortfarande några verktyg som kan kräva denna behörighet för någon del av dess funktionalitet.
Brist på direkt åtkomst till MySQL-datakatalog och loggar gör det svårare att utföra åtgärder som involverar dem. Det händer då och då att en DBA behöver analysera binära loggar eller svansfel, långsam fråga eller allmän logg. Även om det är möjligt att komma åt dessa loggar på RDS, är det mer besvärligt än att göra vad du behöver genom att logga in på skalet på MySQL-värden. Att ladda ner dem lokalt tar också lite tid och lägger till ytterligare latens till vad du än gör.
Brist på kontroll över replikeringstopologi, hög tillgänglighet endast i distributioner med flera A-Ö. Med tanke på att du inte har kontroll över replikeringen kan du inte implementera någon form av hög tillgänglighetsmekanism i ditt databaslager. Det spelar ingen roll att du har flera slavar, du kan inte använda några av dem som masterkandidater för även om du befordrar en slav till en mästare, finns det inget sätt att återslava de återstående slavarna från denna nya mästare. Detta tvingar användare att använda multi-AZ-distributioner och öka kostnaderna (”skugginstansen” är inte gratis, användaren måste betala för den).
Minskad tillgänglighet genom planerad driftstopp. När du distribuerar en RDS-instans tvingas du välja ett veckotidsfönster på 30 minuter under vilket underhållsåtgärder kan utföras på din RDS-instans. Å ena sidan är detta förståeligt eftersom RDS är en Database as a Service så hårdvaru- och mjukvaruuppgraderingar av dina RDS-instanser hanteras av AWS-ingenjörer. Å andra sidan minskar detta din tillgänglighet eftersom du inte kan förhindra att din huvuddatabas går ner under underhållsperioden. Återigen, i det här fallet ökar användningen av multi-AZ-inställning tillgängligheten eftersom ändringar sker först på skugginstansen och sedan failover exekveras. Failover i sig är dock inte transparent så, på ett eller annat sätt, förlorar du drifttiden. Detta tvingar dig att designa din app med oväntade MySQL-masterfel i åtanke. Inte för att det är ett dåligt designmönster - databaser kan krascha när som helst och din applikation bör byggas på ett sätt som tål även de mest svåra scenarier. Det är bara det att med RDS har du begränsade alternativ för hög tillgänglighet.
Reducerade alternativ för implementering med hög tillgänglighet. Med tanke på bristen på flexibilitet i hanteringen av replikeringstopologi är den enda möjliga högtillgänglighetsmetoden multi-AZ-distribution. Denna metod är bra men det finns verktyg för MySQL-replikering som skulle minimera stilleståndstiden ytterligare. Till exempel kan MHA eller ClusterControl när de används i samband med ProxySQL leverera (under vissa förhållanden som avsaknad av långvariga transaktioner) transparent failover-process för applikationen. När du är på RDS kommer du inte att kunna använda den här metoden.
Minskad insikt i din databas prestanda. Även om du kan få mätvärden från MySQL själv, räcker det ibland helt enkelt inte för att få en fullständig 10 000 fots bild av situationen. Vid någon tidpunkt kommer majoriteten av användarna att behöva ta itu med riktigt konstiga problem orsakade av felaktig hårdvara eller felaktig infrastruktur - förlorade nätverkspaket, plötsligt avslutade anslutningar eller oväntat hög CPU-användning. När du har tillgång till din MySQL-värd kan du utnyttja massor av verktyg som hjälper dig att diagnostisera tillståndet för en Linux-server. När du använder RDS är du begränsad till vilka mätvärden som är tillgängliga i Cloudwatch, Amazons övervaknings- och trendverktyg. En mer detaljerad diagnos kräver att du kontaktar supporten och ber dem kontrollera och åtgärda problemet. Detta kan vara snabbt men det kan också vara en mycket lång process med mycket fram och tillbaka e-postkommunikation.
Inlåsning av leverantörer orsakad av en komplex och tidskrävande process för att få ut data från MySQL RDS. RDS ger inte åtkomst till MySQL-datakatalogen så det finns inget sätt att använda industristandardverktyg som xtrabackup för att flytta data på ett binärt sätt. Å andra sidan är RDS under huven en MySQL som underhålls av Amazon, det är svårt att säga om den är 100% kompatibel med upstream eller inte. RDS är bara tillgängligt på AWS, så du skulle inte kunna göra en hybridinstallation.
Sammanfattning
MySQL RDS har både styrkor och svagheter. Detta är ett mycket bra verktyg för dem som vill fokusera på applikationen utan att behöva oroa sig för att använda databasen. Du distribuerar en databas och börjar skicka frågor. Inget behov av att bygga säkerhetskopieringsskript eller konfigurera övervakningslösning eftersom det redan är gjort av AWS-ingenjörer - allt du behöver göra är att använda det.
Det finns också en mörk sida av MySQL RDS. Brist på alternativ för att bygga mer komplexa inställningar och skala utanför att bara lägga till fler slavar. Brist på stöd för bättre hög tillgänglighet än vad som föreslås under multi-AZ-distributioner. Besvärlig tillgång till MySQL-loggar. Brist på direkt åtkomst till MySQL-datakatalog och brist på stöd för fysiska säkerhetskopior, vilket gör det svårt att flytta ut data från RDS-instansen.
För att sammanfatta det kan RDS fungera bra för dig om du värdesätter användarvänlighet framför detaljerad kontroll av databasen. Du måste komma ihåg att du någon gång i framtiden kan växa ur MySQL RDS. Vi pratar inte nödvändigtvis bara om prestanda här. Det handlar mer om din organisations behov av mer komplex replikeringstopologi eller ett behov av att ha bättre insikt i databasoperationer för att snabbt kunna hantera olika problem som dyker upp då och då. I så fall, om din datauppsättning redan har vuxit i storlek, kan du tycka att det är svårt att flytta ut från RDS. Innan de fattar något beslut om att flytta din data till RDS måste informationshanterare överväga sin organisations krav och begränsningar inom specifika områden.
I nästa par blogginlägg kommer vi att visa dig hur du tar dina data från RDS till en separat plats. Vi kommer att diskutera både migration till EC2 och till lokal infrastruktur.