MySQL-replikering har varit den vanligaste och mest använda lösningen för hög tillgänglighet av stora organisationer som Github, Twitter och Facebook. Även om det är lätt att installera, finns det utmaningar när du använder den här lösningen från underhåll, inklusive programvaruuppgraderingar, datadrift eller datainkonsekvens över replikanoderna, topologiändringar, failover och återställning. När MySQL släppte version 5.6 medförde det ett antal betydande förbättringar, särskilt för replikering som inkluderar Global Transaction ID (GTID), händelsekontrollsummor, flertrådiga slavar och kraschsäkra slavar/masters. Replikeringen blev ännu bättre med MySQL 5.7 och MySQL 8.0.
Replikering gör att data från en MySQL-server (den primära/mastern) kan replikeras till en eller flera MySQL-servrar (repliken/slavarna). MySQL-replikering är mycket lätt att konfigurera och används för att skala ut läsarbetsbelastningar, ge hög tillgänglighet och geografisk redundans och ladda ner säkerhetskopior och analysjobb.
MySQL-replikering i naturen
Låt oss få en snabb översikt över hur MySQL-replikering fungerar i naturen. MySQL-replikering är brett, och det finns flera sätt att konfigurera det och hur det kan användas. Som standard använder den asynkron replikering, som fungerar när transaktionen slutförs i den lokala miljön. Det finns ingen garanti för att någon händelse någonsin kommer att nå någon slav. Det är ett löst kopplat herre-slav-förhållande, där:
-
Primären väntar inte på en replik.
-
Replika bestämmer hur mycket som ska läsas och från vilken punkt i den binära loggen.
-
Replika kan vara godtyckligt bakom mästaren när det gäller att läsa eller tillämpa ändringar.
Om den primära kraschar kanske transaktioner som den har utfört inte har överförts till någon replik. Följaktligen kan failover från primär till den mest avancerade repliken, i det här fallet, resultera i en failover till den önskade primära som faktiskt saknar transaktioner i förhållande till den tidigare servern.
Asynkron replikering ger lägre skrivlatens eftersom en skrivning bekräftas lokalt av en master innan den skrivs till slavar. Det är utmärkt för lässkalning eftersom att lägga till fler repliker inte påverkar replikeringsfördröjningen. Bra användningsfall för asynkron replikering inkluderar distribution av läsrepliker för lässkalning, live backup-kopia för katastrofåterställning och analys/rapportering.
MySQL semisynkron replikering
MySQL stöder också semi-synkron replikering, där mastern inte bekräftar transaktioner till klienten förrän minst en slav har kopierat ändringen till sin relälogg och spolat den till disken. För att möjliggöra semi-synkron replikering krävs extra steg för plugin-installation och måste aktiveras på de angivna MySQL-master- och slavnoderna.
Halvsynkron verkar vara en bra och praktisk lösning för många fall där hög tillgänglighet och ingen dataförlust är viktigt. Men du bör tänka på att semi-synkron har en prestandapåverkan på grund av den extra rundresan och inte ger starka garantier mot dataförlust. När en commit returneras framgångsrikt är det känt att data finns på minst två ställen (på mastern och minst en slav). Om mastern begår men en krasch inträffar medan mastern väntar på bekräftelse från en slav, är det möjligt att transaktionen kanske inte har nått någon slav. Detta är inte så stort problem eftersom åtagandet inte kommer att återföras till ansökan i detta fall. Det är applikationens uppgift att göra om transaktionen i framtiden. Vad som är viktigt att komma ihåg är att när mastern misslyckas och en slav har befordrats, kan den gamla mastern inte gå med i replikeringskedjan. Under vissa omständigheter kan detta leda till konflikter med data på slavarna, d.v.s. när mastern kraschade efter att slaven tog emot den binära logghändelsen men innan mastern fick bekräftelsen från slaven). Det enda säkra sättet är alltså att kassera data på den gamla mastern och tillhandahålla den från början med hjälp av data från den nyligen marknadsförda mastern.
Använda replikeringsformatet felaktigt
Sedan MySQL 5.7.7 använder standardformatet för binärt loggformat eller variabeln binlog_format ROW, vilket var STATEMENT före 5.7.7. De olika replikeringsformaten motsvarar den metod som används för att registrera källans binära logghändelser. Replikering fungerar eftersom händelser som skrivs till den binära loggen läses från källan och bearbetas sedan på repliken. Händelserna registreras i den binära loggen i olika replikeringsformat beroende på typen av händelse. Att inte veta säkert vad man ska använda kan vara ett problem. MySQL har tre format av replikeringsmetoder:STATEMENT, ROW och MIXED.
-
Det STATEMENT-baserade replikeringsformatet (SBR) är precis vad det är – en replikeringsström av varje programsats som körs på mastern som kommer att spelas om på slavnoden. Som standard utför MySQL traditionell (asynkron) replikering inte de replikerade transaktionerna till slavarna parallellt. Med det betyder det att ordningen på uttalanden i replikeringsströmmen kanske inte är 100 % densamma. Dessutom kan uppspelning av ett uttalande ge olika resultat när det inte körs samtidigt som när det körs från källan. Detta leder till ett inkonsekvent tillstånd mot primären och dess replik(er). Detta var inte ett problem på många år, eftersom inte många körde MySQL med många samtidiga trådar. Men med moderna multi-CPU-arkitekturer har detta faktiskt blivit mycket troligt vid en normal daglig arbetsbelastning.
-
ROW-replikeringsformatet tillhandahåller lösningar som SBR saknar. När du använder loggningsformat för radbaserat replikering (RBR), skriver källan händelser till den binära loggen som indikerar hur enskilda tabellrader ändras. Replikering från källan till repliken fungerar genom att de händelser som representerar ändringarna av tabellraderna kopieras till repliken. Detta innebär att mer data kan genereras, vilket påverkar diskutrymmet i repliken och påverkar nätverkstrafik och disk I/O. Tänk på om en sats ändrar många rader, låt oss säga med en UPDATE-sats, RBR skriver mer data till den binära loggen även för satser som rullas tillbaka. Att köra ögonblicksbilder vid tidpunkten kan också ta längre tid. Samtidighetsproblem kan komma in i bilden med tanke på de låstider som behövs för att skriva stora bitar av data till den binära loggen.
-
Då finns det en metod mellan dessa två; replikering i blandat läge. Den här typen av replikering kommer alltid att replikera satser, förutom när frågan innehåller funktionen UUID(), triggers, lagrade procedurer, UDF:er och några andra undantag. Blandat läge löser inte problemet med dataavdrift och bör undvikas tillsammans med uttalandebaserad replikering.
Planerar du att ha en Multi-Master-installation?
Cirkulär replikering (även känd som ringtopologi) är en känd och vanlig inställning för MySQL-replikering. Den används för att köra en multi-master setup (se bilden nedan) och är ofta nödvändig om du har en multi-datacentermiljö. Eftersom applikationen inte kan vänta på att mastern i det andra datacentret ska bekräfta skrivningarna, är en lokal master att föredra. Normalt används den automatiska inkrementförskjutningen för att förhindra datakrockar mellan masterna. Att låta två master utföra skrivningar till varandra på detta sätt är en allmänt accepterad lösning.
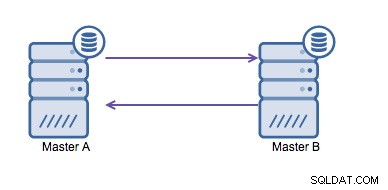
Men om du behöver skriva i flera datacenter till samma databas , slutar du med flera masters som behöver skriva sina data till varandra. Innan MySQL 5.7.6 fanns det ingen metod för att göra en mesh-typ av replikering, så alternativet skulle vara att använda en cirkulär ringreplikering istället.
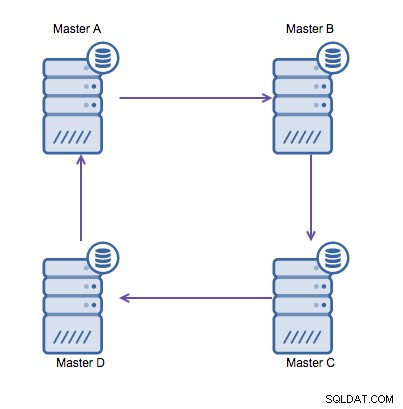
Ringreplikering i MySQL är problematisk av följande skäl:latens, hög tillgänglighet och datadrift. Att skriva lite data till server A skulle ta tre hopp för att hamna på server D (via server B och C). Eftersom (traditionell) MySQL-replikering är entrådig, kan alla långvariga frågor i replikeringen stoppa hela ringen. Dessutom, om någon av servrarna skulle gå ner, skulle ringen brytas, och för närvarande kan ingen failover-mjukvara reparera ringstrukturer. Då kan datadrift uppstå när data skrivs till server A och ändras samtidigt på server C eller D.
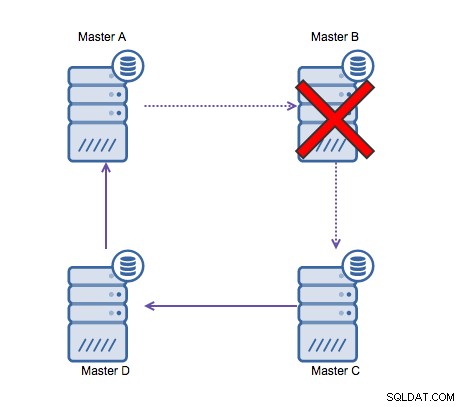
I allmänhet passar cirkulär replikering inte bra med MySQL och bör vara undvikas till varje pris. Eftersom det utformades med det i åtanke, skulle Galera Cluster vara ett bra alternativ för multi-datacenterskrivningar.
Stänga replikeringen med stora uppdateringar
Olika hushållningsbatch-jobb utför ofta olika uppgifter, allt från att rensa upp gamla data till att beräkna medelvärden för "gilla" som hämtats från en annan källa. Detta innebär att ett jobb kommer att skapa mycket databasaktivitet med bestämda intervaller och, med största sannolikhet, skriva mycket data tillbaka till databasen. Naturligtvis innebär detta att aktiviteten inom replikeringsströmmen kommer att öka lika mycket.
Statusbaserad replikering kommer att replikera de exakta frågorna som används i batchjobben, så om frågan tog en halvtimme att bearbeta på mastern, skulle slavtråden stoppas under minst samma mängd tid. Detta betyder att ingen annan data kan replikera, och slavnoderna kommer att börja släpa efter mastern. Om detta överskrider tröskeln för ditt failover-verktyg eller proxy, kan det ta bort dessa slavnoder från de tillgängliga servrarna i klustret. Om du använder satsbaserad replikering kan du förhindra detta genom att krossa data för ditt jobb i mindre omgångar.
Nu kanske du tror att radbaserad replikering inte påverkas av detta, eftersom det kommer att replikera radinformationen istället för frågan. Detta är delvis sant eftersom, för DDL-ändringar, replikeringen återgår till ett uttalandebaserat format. Ett stort antal CRUD-operationer (Create, Read, Update, Delete) kommer också att påverka replikeringsströmmen. I de flesta fall är detta fortfarande en entrådsoperation, och därför kommer varje transaktion att vänta på att den föregående spelas upp via replikering. Detta betyder att om du har hög samtidighet på mastern, kan slaven stanna vid överbelastningen av transaktioner under replikering.
För att komma runt detta erbjuder både MariaDB och MySQL parallell replikering. Implementeringen kan skilja sig åt per leverantör och version. MySQL 5.6 erbjuder parallell replikering så länge frågorna är åtskilda av schemat. MariaDB 10.0 och MySQL 5.7 kan båda hantera parallell replikering över scheman men har andra gränser. Att köra frågor via parallella slavtrådar kan påskynda din replikeringsström om du skriver tungt. Annars vore det bättre att hålla sig till den traditionella entrådsreplikeringen.
Hantera dina schemaändringar eller DDL
Sedan lanseringen av 5.7 har hanteringen av schemaändringen eller DDL-ändringen (Data Definition Language) i MySQL förbättrats mycket. Fram till MySQL 8.0 stöds DDL-ändringsalgoritmerna COPY och INPLACE.
-
KOPIERA:Denna algoritm skapar en ny temporär tabell med det ändrade schemat. När den har migrerat data helt till den nya temporära tabellen byter den och släpper den gamla tabellen.
-
INPLACE:Denna algoritm utför operationer på plats till den ursprungliga tabellen och undviker tabellkopiering och ombyggnad när det är möjligt.
-
INSTANT:Denna algoritm har introducerats sedan MySQL 8.0 men har fortfarande begränsningar.
I MySQL 8.0 introducerades algoritmen INSTANT, som gör omedelbara och på plats tabelländringar för kolumntillägg och tillåter samtidig DML med förbättrad respons och tillgänglighet i hektiska produktionsmiljöer. Detta hjälper till att undvika enorma fördröjningar och stall i repliken som vanligtvis var stora problem i applikationsperspektivet, vilket gjorde att inaktuella data hämtas eftersom läsningarna i slaven ännu inte har uppdaterats på grund av fördröjning.
Även om det är en lovande förbättring finns det fortfarande begränsningar med dem, och ibland är det inte möjligt att tillämpa dessa INSTANT- och INPLACE-algoritmer. Till exempel, för INSTANT- och INPLACE-algoritmer, är att ändra en kolumns datatyp också en vanlig DBA-uppgift, särskilt i applikationsutvecklingsperspektivet på grund av dataändring. Dessa tillfällen är oundvikliga; sålunda kan du inte fortsätta med COPY-algoritmen eftersom detta låser tabellen och orsakar förseningar i slaven. Det påverkar också den primära/masterservern under den här körningen eftersom den samlar upp inkommande transaktioner som också refererar till den påverkade tabellen. Du kan inte utföra en direkt ALTER eller schemaändring på en upptagen server eftersom detta följer med driftstopp eller eventuellt korrumperar din databas om du tappar tålamodet, särskilt om måltabellen är enorm.
Det är sant att det alltid är en utmanande uppgift att utföra schemaändringar på en pågående produktionsinstallation. En ofta använd lösning är att först tillämpa schemaändringen på slavnoderna. Detta fungerar bra för satsbaserad replikering, men detta kan bara fungera upp till en viss grad för radbaserad replikering. Radbaserad replikering tillåter att extra kolumner finns i slutet av tabellen, så så länge den kan skriva de första kolumnerna kommer det att gå bra. Tillämpa först ändringen på alla slavar, sedan failover på en av slavarna och tillämpa sedan ändringen på mastern och anslut den som en slav. Om din ändring innebär att du infogar en kolumn i mitten eller tar bort en kolumn, fungerar detta med radbaserad replikering.
Det finns tillgängliga verktyg som kan utföra onlineschemaändringar mer tillförlitligt. Percona Online Schema Change (så känt som pt-osc) och gh-ost av Schlomi Noach används ofta av DBA:er. Dessa verktyg hanterar schemaändringar effektivt genom att gruppera de berörda raderna i bitar, och dessa bitar kan konfigureras därefter beroende på hur många du vill gruppera.
Om du ska hoppa med pt-osc kommer detta verktyg att skapa en skuggtabell med den nya tabellstrukturen, infoga ny data via triggers och återfyllningsdata i bakgrunden. När det är klart att skapa den nya tabellen, kommer den helt enkelt att byta ut den gamla mot den nya tabellen i en transaktion. Detta fungerar inte i alla fall, särskilt om din befintliga tabell redan har utlösare.
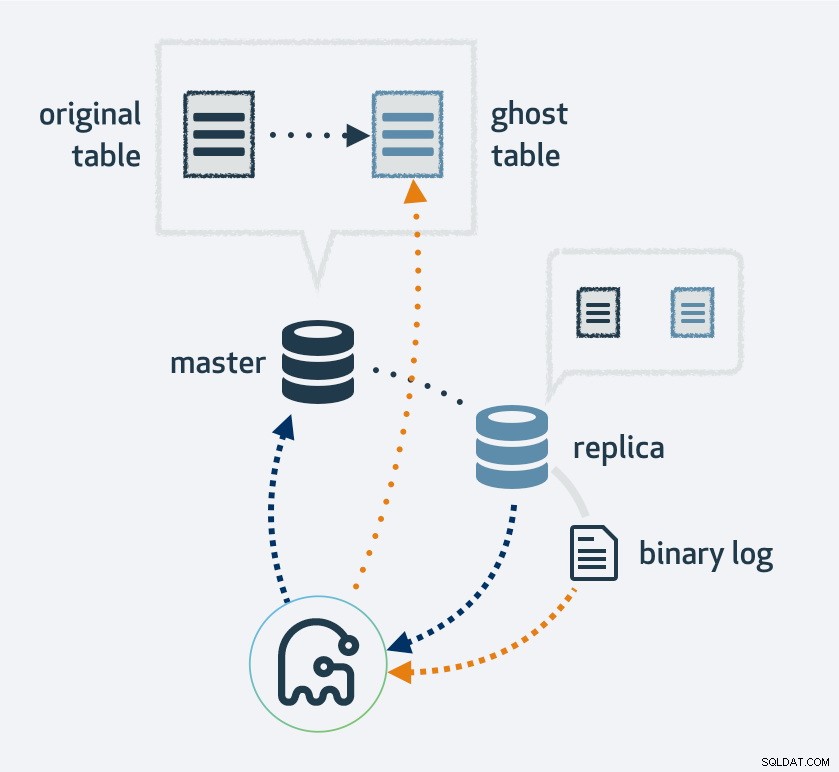
Om du använder gh-ost gör du först en kopia av din befintliga tabelllayout, ändra tabellen till den nya layouten och koppla sedan upp processen som en MySQL-replik. Den kommer att använda replikeringsströmmen för att hitta nya rader som har infogats i den ursprungliga tabellen och samtidigt återfyller tabellen. När återfyllningen är klar kommer de ursprungliga och nya tabellerna att bytas. Naturligtvis kommer alla operationer till den nya tabellen att hamna i replikeringsströmmen; sålunda, på varje replik, sker migreringen samtidigt.
Minnestabeller och replikering
Medan vi är på ämnet DDL, är ett vanligt problem skapandet av minnestabeller. Minnestabeller är icke-beständiga tabeller, deras tabellstruktur finns kvar, men de förlorar sina data efter en omstart av MySQL. När du skapar en ny minnestabell på både en master och en slav kommer de att ha en tom tabell, vilket kommer att fungera utmärkt. När någon av dem har startat om kommer tabellen att tömmas och replikeringsfel kommer att uppstå.
Radbaserad replikering kommer att gå sönder när data i slavnoden returnerar andra resultat, och satsbaserad replikering kommer att gå sönder när den försöker infoga data som redan finns. För minnestabeller är detta en frekvent replikeringsbrytare. Fixningen är enkel:gör en ny kopia av data, ändra motorn till InnoDB, och den bör nu vara replikeringssäker.
Ställa in read_only={True|1}
Detta är naturligtvis ett möjligt fall när du använder en ringtopologi, och vi avråder från att använda ringtopologi om möjligt. Vi beskrev tidigare att inte ha samma data i slavnoderna kan bryta replikering. Ofta orsakas detta av att något (eller någon) ändrar data på slavnoden men inte på masternoden. När masternodens data har ändrats, kommer detta att replikeras till slaven där den inte kan tillämpa ändringen, och detta gör att replikeringen bryts. Detta kan också leda till datakorruption på klusternivå, särskilt om slaven har blivit befordrad eller har misslyckats på grund av en krasch. Det kan bli en katastrof.
Enklast förebyggande för detta är att se till att endast läs_och super_skrivskyddad (endast på> 5.6) är inställda på ON eller 1. Du kanske har förstått hur dessa två variabler skiljer sig och hur det påverkar om du inaktiverar eller aktiverar dem. Med super_read_only (sedan MySQL 5.7.8) inaktiverat kan root-användaren förhindra ändringar i målet eller repliken. Så när båda är inaktiverade kommer detta att förbjuda någon att göra ändringar i data, förutom replikeringen. De flesta failover-hanterare, såsom ClusterControl, ställer in denna flagga automatiskt för att förhindra användare från att skriva till den använda mastern under failover. Vissa av dem behåller till och med detta efter failover.
Aktivera GTID
I MySQL-replikering är det viktigt att starta slaven från rätt position i de binära loggarna. Att erhålla denna position kan göras när du gör en säkerhetskopia (xtrabackup och mysqldump stödjer detta) eller när du har slutat slava på en nod som du gör en kopia av. Att starta replikering med kommandot CHANGE MASTER TO skulle se ut så här:
mysql> CHANGE MASTER TO MASTER_HOST='x.x.x.x',
MASTER_USER='replication_user',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='master-bin.00001',
MASTER_LOG_POS=4;Att starta replikering på fel plats kan få katastrofala konsekvenser:data kan skrivas dubbelt eller inte uppdateras. Detta orsakar datadrift mellan mastern och slavnoden.
Också, att misslyckas över en master till en slav innebär att hitta rätt position och byta master till lämplig värd. MySQL behåller inte binära loggar och positioner från sin master, utan skapar istället sina egna binära loggar och positioner. Detta kan bli ett allvarligt problem för att justera om en slavnod till den nya mastern. Den exakta positionen för mastern vid failover måste hittas på den nya mastern, och sedan kan alla slavar justeras om.
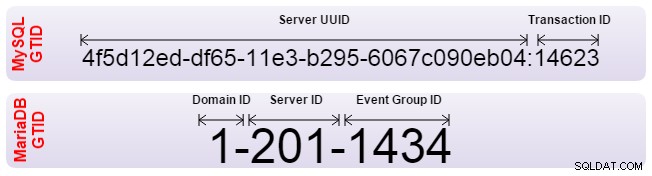
Både Oracle MySQL och MariaDB har implementerat Global Transaction Identifier (GTID) för att lösa detta problem. GTID tillåter automatisk justering av slavar, och servern räknar ut själv vad den korrekta positionen är. Båda har dock implementerat GTID på olika sätt och är därför inkompatibla. Om du behöver ställa in replikering från en till en annan, bör replikeringen ställas in med traditionell binär loggpositionering. Dessutom bör din failover-programvara vara medveten om att den inte använder GTID.
Crash-Safe Slave
Crash säker innebär att även om en slav MySQL/OS kraschar, kan du återställa slaven och fortsätta replikeringen utan att återställa MySQL-databaser till slaven. För att få kraschsäkert slavarbete måste du endast använda InnoDB-lagringsmotorn, och i 5.6 måste du ställa in relay_log_info_repository=TABLE och relay_log_recovery=1.
Slutsats
Övning ger färdighet, men utan ordentlig träning och kunskap om dessa viktiga tekniker kan det vara besvärligt eller leda till en katastrof. Dessa metoder följs vanligtvis av experter inom MySQL och anpassas av stora industrier som en del av deras dagliga rutinarbete när de administrerar MySQL-replikeringen i produktionsdatabasservrarna.
Om du vill läsa mer om MySQL-replikering, kolla in den här handledningen om MySQL-replikering för hög tillgänglighet.
Följ oss på Twitter och LinkedIn och prenumerera på vårt nyhetsbrev för fler uppdateringar om databashanteringslösningar och bästa praxis för dina öppen källkodsbaserade databaser.