Introduktion
Att ta reda på vilken typ av databasinfrastruktur du behöver för att matcha dina applikationers prestanda, tillförlitlighet och skalningskrav kan vara en svår uppgift. De val du gör för din databastopologi kan påverka hur hela din applikationsstack reagerar på olika typer av användning och vilka felscenarier den kan förklara. På grund av detta är det viktigt att förstå dina alternativ och fatta ett välgrundat beslut som ligger i linje med dina mål.
Det finns många olika sätt att gå från en enda databas som hanterar alla dina infrastrukturbehov till mer komplexa system. Tillsammans med detta finns det många avvägningar att överväga.
I den här guiden kommer vi att introducera några av de vanligaste mönstren för relationsdatabasinfrastruktur och hur de överensstämmer med olika användningsmönster. Vi går igenom vilka fördelar varje konfiguration erbjuder samt några av de brister som du måste ta hänsyn till. Vi kommer också att prata om effekterna av olika beslut på din övergripande verksamhetskomplexitet. När du är klar bör du kunna fatta ett bättre beslut om vilken design som är bäst lämpad för dina nuvarande behov och vilka alternativ du kanske vill experimentera med när dina behov förändras.
Skala vertikalt
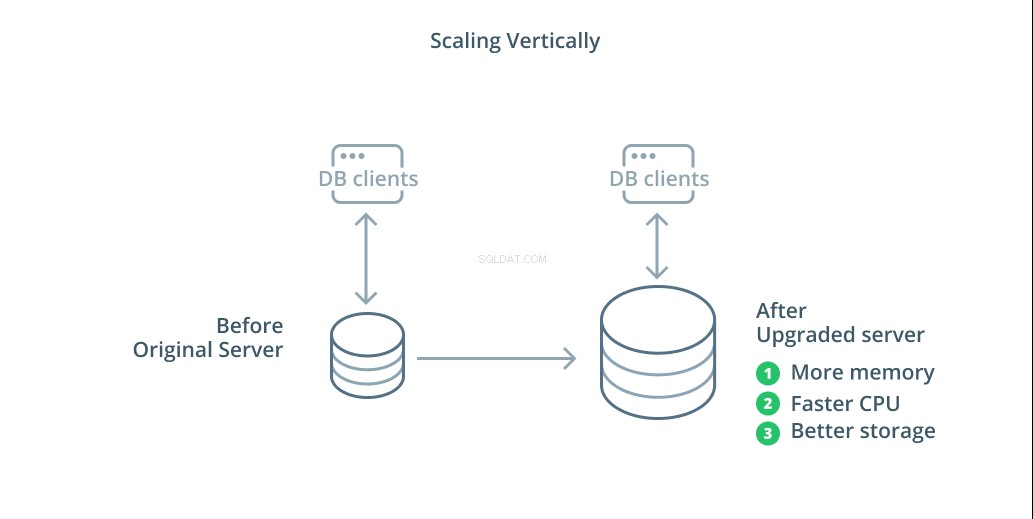
Det enklaste sättet att skala ett databassystem är vertikal skalning. Skala vertikalt , även kallad skala upp , innebär att lägga till kapacitet till servern som hanterar din databas. Genom att öka processorkraften, minnesallokeringen eller lagringskapaciteten kan du öka prestanda och volym som ett databassystem kan hantera utan att öka komplexiteten i systemet som helhet.
Som en allmän regel är att skala upp din databas ett bra första steg eftersom det ökar din databas kapacitet utan att påverka din infrastrukturtopologi. Uppskalning är vanligtvis ganska enkelt också, eftersom en maskin med större kapacitet kan konfigureras som en replikeringsföljare tills den är synkroniserad och sedan kan en failover utlösas för att göra den till den nya primära servern.
Uppskalning har dock sina begränsningar eftersom mängden resurser som rimligen kan allokeras till en maskin är begränsad. Det representerar också en enda felpunkt om inga replikeringsföljare är konfigurerade att ta över när problem uppstår. Dessa problem åtgärdas av några av de andra skalningsalternativen.
Command-query Responsibility Segregation (CQRS) och skrivskyddade repliker
Det andra primära sättet att skala din databasinfrastruktur är att skala ut. Skalar ut innebär att istället för att öka kapaciteten på en enskild server ökar du antalet servrar som är dedikerade till att betjäna ett specifikt behov. Så du lägger till kapacitet genom att lägga till ytterligare maskiner till din infrastruktur.
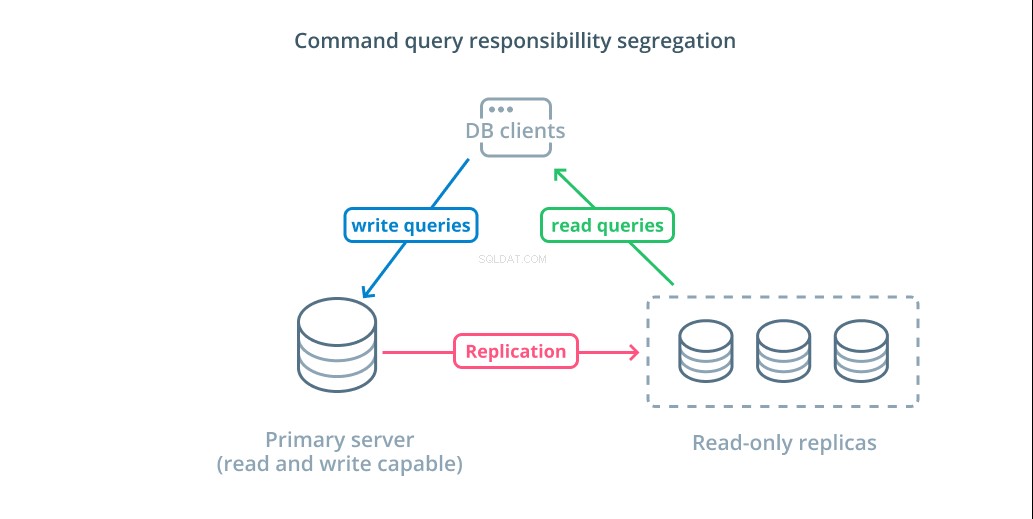
Segregering av kommandoförfrågningar (CQRS) är en term som används för att beskriva att lägga till logik för att skilja ut frågor som muterar data (skriva frågor) från de som inte gör det (läs frågor). Detta gör att du kan dirigera dessa olika kategorier av förfrågningar till olika värdar för att hjälpa till att fördela belastningen.
Den mest grundläggande infrastrukturen för att dra fördel av denna design är en primär server som kan acceptera läs- och skrivfrågor kombinerat med en eller flera replikservrar som följer den primära servern som kan acceptera läsfrågor. Denna design är lämplig för applikationsanvändningsmönster som är lästunga, eftersom läsoperationer kan hanteras av vilken som helst av databasservrarna.
Dessutom ger detta system viss redundans till din arkitektur eftersom systemet fortfarande fungerar om någon av servrarna går ner. Om en följare går ner kan läsbegäranden dirigeras till de andra servrarna. Om den primära servern går ner kan en av replikanhängarna befordras att acceptera skrivfrågor.
Multiprimär replikering
Även om användning av CQRS med skrivskyddade repliker hjälper dig att hantera ett högre antal läsbegäranden, påverkar det inte skrivprestandan i din infrastruktur nämnvärt. För att öka antalet skrivningar som din arkitektur kan hantera måste du överväga om du kan använda en multiprimär replikeringsdesign.
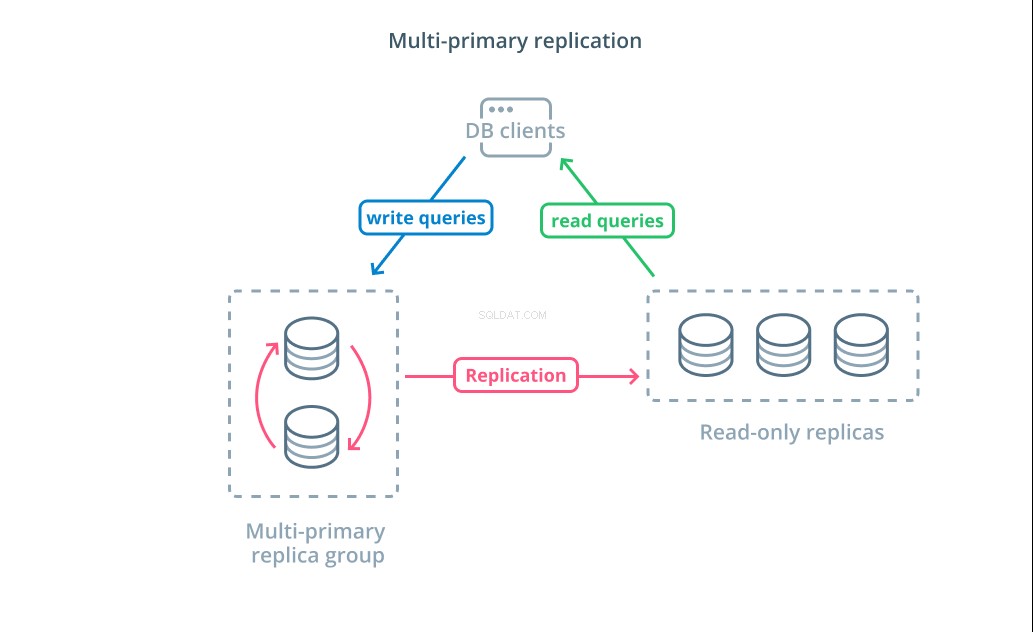
Multiprimär replikering är en form av replikering där flera servrar kan acceptera skrivförfrågningar. Vissa system är konfigurerade så att vilken server som helst kan behandla skrivförfrågningar, medan andra är designade så att en kärngrupp av primära servrar hanterar skrivningar med ett större antal skrivskyddade följare. Oavsett implementering ökar multiprimär replikering antalet servrar som är ansvariga för skrivfrågor.
Även om den här designen från början låter perfekt, finns det några stora utmaningar som hindrar detta från att bli ett allmänt antaget mönster. Även om flera servrar kan hantera skrivförfrågningar måste de fortfarande samordna sig för att replikera ändringar mellan sina servrar och för att lösa konflikter i dataändringar. Detta kan antingen leda till långa svarstider när konflikter förhandlas eller till inkonsekventa data.
Varje system väljer sitt eget sätt att hantera dessa utmaningar. Detta är en demonstration av CAP Theorem — ett uttalande som beskriver samspelet mellan konsekvens, tillgänglighet och partitionstolerans i distribuerade system — i aktion. Vissa system erbjuder svagare konsistensgarantier för att upprätthålla tillgänglighet, medan andra databaser vägrar att acceptera ändringar om deras kamrater inte kan koordinera transaktionen vid tidpunkten för skrivningen. Att välja det tillvägagångssätt som bäst passar dina behov är en viktig faktor när du ska välja mellan olika implementeringar.
Läs frågecache
Även om användning av skrivskyddade repliker är ett sätt att öka antalet tillgängliga databaser som kan svara på läsbegäranden, förbättrar det inte den grundläggande frågeprestandan för komplexa läsoperationer. En av servrarna förväntas fortfarande utföra läsoperationen varje gång en begäran görs, även om resultaten är identiska med den tidigare uppslagningen.
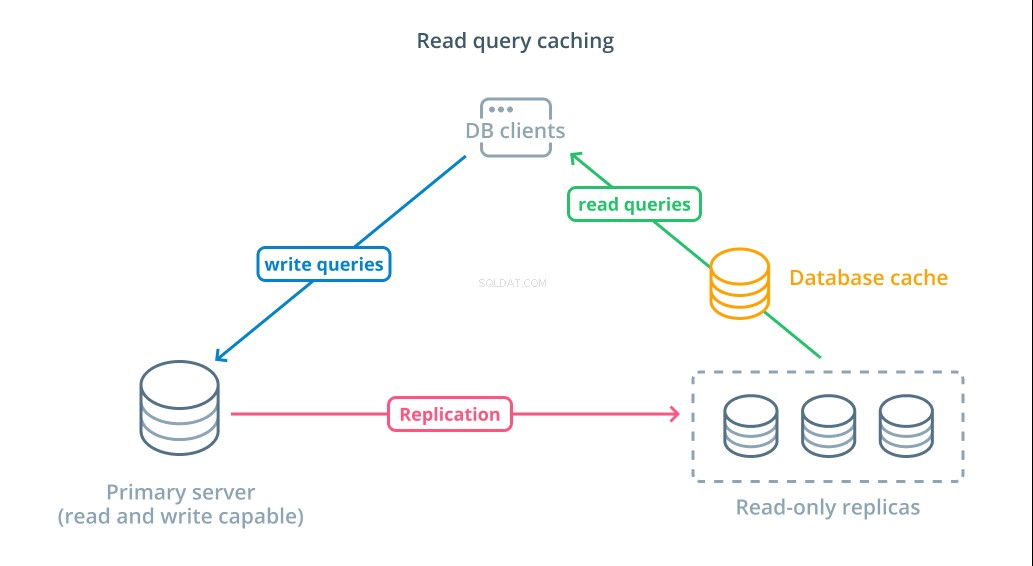
För att minska svarstider, en läs fråga cachning lager kan införas. Att lägga till en cache mellan dina databasklienter och själva databaserna kan minska frågetiden för vanliga förfrågningar avsevärt. Applikationen kan begära läsresultat från cachen och ta emot dem nästan omedelbart om de är tillgängliga. I de fall resultaten inte hittas i cachen, hämtas de från själva databasen och läggs till i cachen till nästa gång.
Att konfigurera cachelagring på detta sätt är otroligt effektivt för scenarier där data sannolikt inte kommer att ändras varje gång begäran görs. Det är särskilt användbart för dyra läsfrågor som konsulterar flera tabeller och inkluderar komplexa kopplingsoperationer. Dessa resultat kan köras en gång och sedan sparas för framtida frågor.
I fall där data ändras snabbare, kanske en läscache inte hjälper till så mycket. Beroende på det konfigurerade beteendet riskerar cacher att returnera inaktuella data i dessa situationer och genomtänkta cache-ogiltigförklaringsstrategier bör implementeras för att avhysa inaktuella data från cachen när de ändras.
Datafördelning
Hittills har designerna vi diskuterat segmenterade databaskomponenter baserat på om de svarar på skrivförfrågningar eller inte. Ett annat sätt att dela upp ansvaret är dock att dela upp den faktiska datamängden i flera delar.
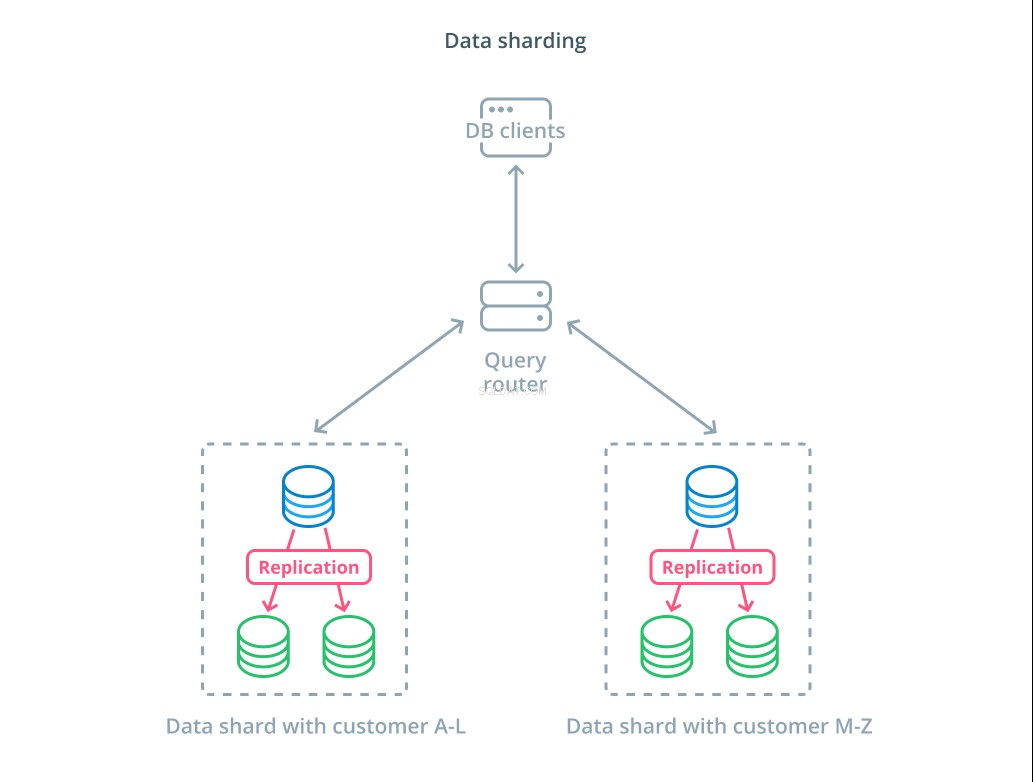
Skärning är processen att dela upp en logisk datamängd i mindre delmängder för att distribuera deras hantering till olika maskiner. Varje databasserver hanterar bara en del av datan och en routingmekaniker introduceras som förstår vilka maskiner som är ansvariga för vilka databitar.
Vanligtvis utförs skärning i scenarier där det är onödigt eller ovanligt att arbeta med hela datasetet samtidigt. Datauppsättningen segmenteras baserat på varje posts värde för en specifik nyckel, känd som sharding-nyckeln . Till exempel kan du manuellt klippa data baserat på var kunderna befinner sig. Du kan också skärpa automatiskt med hjälp av en hashalgoritm för att bestämma vilka noder som ska hantera vilka nycklar. Detta kan hjälpa ditt system att undvika obalanserad distribution i fall där shard-tangenten är ojämnt fördelad.
Sharding introducerar en hel del komplexitet i datasystem och är inte lämpligt för alla scenarier. Operationer som interagerar med flera shards kommer att drabbas av betydande prestationsstraff när de hämtar resultat från varje medlem. Detta kan hända för aggregerade frågor eller om den specifika shardnyckeln inte är känd i förväg. Dessutom kan ojämn allokering av skärvor också orsaka ineffektivitet och flaskhalsar som måste åtgärdas genom att ombalansera fördelningen av hela datamängden.
Decentraliserad funktionell datahantering
Istället för att dela upp värdena för en datauppsättning i flera segment är det i många fall mer meningsfullt att använda olika databaser för olika funktionella ändamål. Om du till exempel har en kontotjänst och en produkttjänst, kan dedikerade databaser som sammanfaller med varje problem hjälpa dig att skala olika komponenter oberoende av varandra.
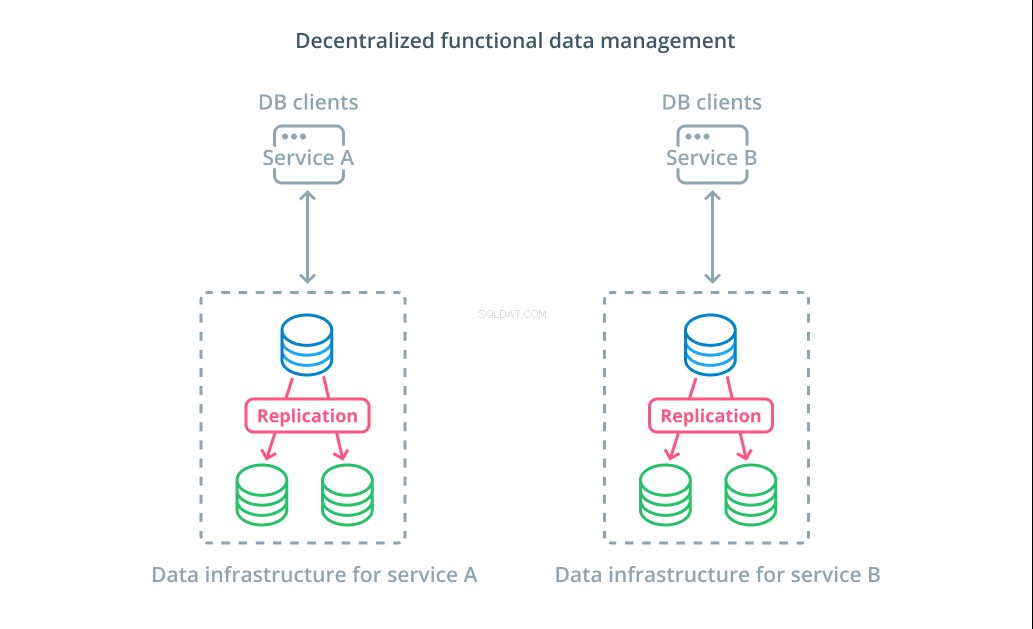
Funktionell datahantering låter dig bryta upp din databasinfrastruktur och hantera varje del enligt kundens behov. Varje funktionell del kan skalas med den strategi som är mest meningsfull. Det låter dig designa databasschemat och distribuera det till en plats som bäst matchar mönstren för ett specifikt användningsfall istället för att kräva att det ska tjäna hela organisationen.
För många organisationer har denna strategi viktiga fördelar som går utöver egenskaperna hos de faktiska systemen. Decentraliserad datahantering kan tillåta mindre team att äga sin egen data utan att koordinera förändringar med andra parter. Det överensstämmer väl med den fokuserade separationen av problem som främjas av mikrotjänstorienterade applikationsarkitekturer.
Serverlösa databaser
De olika avvägningar som du måste utvärdera och mängden infrastruktur du kan förväntas hantera för korrekt skalning kan vara överväldigande för många människor. Ett alternativ för att avlasta denna komplexitet är att dra fördel av databastjänster som hanterar infrastruktur och skala åt dig.
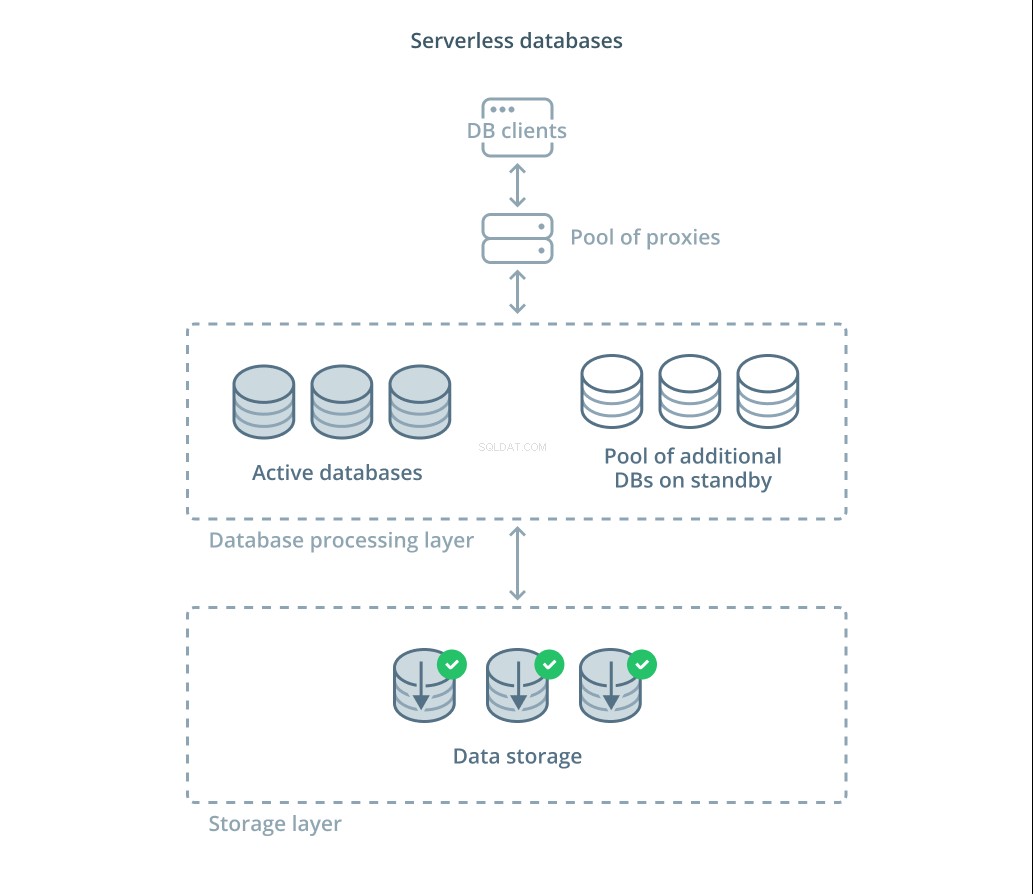
Serverlösa databaser är en kategori av tjänster som frikopplar datalagring från databehandling för att enkelt skala resurser som svar på förändringar i efterfrågan.
Ett datalagringslager ansvarar för att underhålla den faktiska data som hanteras av systemet. Framför det här lagret distribueras en nivå av skalbara databasbehandlingsenheter för att hantera den faktiska frågebehandlingen mot datamängderna. Antalet aktiva enheter vid varje given tidpunkt är direkt kopplat till den aktuella användningen, så mer resurser allokeras när efterfrågan toppar och bearbetningsenheterna återgår till standby om det tystnar.
Förfrågningar vidarebefordras till databasprocessorerna via en routingproxy som vet hur man vidarebefordrar förfrågningar till de aktiva noderna och när man ska begära ytterligare resurser.
Serverlösa databaser har många av samma egenskaper som traditionella databastjänster som implementerar funktioner för automatisk skalning. Båda kan tilldela kapacitet baserat på efterfrågan. Serverlösa databaser låter dig dock skilja lagringskostnader från bearbetningskostnader och kan skala ner bearbetningen till noll när den inte behövs. Serverlösa lösningar tenderar dessutom att kunna skalas upp mycket snabbare för att möta efterfrågan jämfört med den automatiska skalningen som traditionella erbjudanden erbjuder.
Även om serverlösa databaser kan passa bra för vissa, är de inte en silverkula. I fall där databasbehandlare var skalas ner till noll kan det bli förseningar i bearbetningen igen på grund av kallstarter. Dessutom kan churn genom anslutningar mellan de olika komponenterna i en serverlös databasstack leda till ytterligare latens.
Serverlösa databasplattformar kan också vara svåra ur driftssynpunkt. Driftsättningar och databasändringar kan vara svårare att resonera kring och övervaka. Den lokala utvecklingsmiljön kan också skilja sig väsentligt från produktionsmiljön på grund av databassystemets dynamiska tillstånd. Och slutligen, som med alla andra molntjänster, kan användning av serverlösa databaser potentiellt utsätta dig för risk för leverantörslåsning. Det är viktigt att komma ihåg dessa avvägningar när du designar runt en serverlös plattform.
Slutsats
Det finns många sätt att designa, distribuera och hantera din databasinfrastruktur när dina applikationskrav blir mer seriösa. Varje lösning har sina styrkor och begränsningar som är viktiga att förstå när man försöker hitta en passform för din miljö.
Genom att lära dig om hur databasinfrastruktur påverkar tillgängligheten, prestandan och integriteten för dina data kan du undvika kostsamma misstag och implementeringar som inte ger de garantier du behöver. Om en av designerna ovan inte täcker dina krav, kanske du kan kombinera några av elementen i olika tillvägagångssätt för att få ytterligare fördelar.
Om du vill lära dig mer om de allmänna mönstren som täcks ovan, här är några ytterligare resurser som du kanske vill kolla in:
- Uppskalning kontra utskalning
- Segregering av kommandoförfrågningsansvar
- Multiprimär replikering
- Cachar läsfrågor
- Datadelning
- Decentraliserad datahantering
- Serverlösa databaser