Med hänvisning till din kommentar:
@MarcB databasen är normaliserad, CSV-strängen kommer från användargränssnittet."Hämta data för följande personer:101,202,303"
Det här svaret har ett snävt fokus på just de siffror som separeras med kommatecken. För, som det visar sig, pratade du inte ens om FIND_IN_SET trots allt.
Ja, du kan uppnå vad du vill. Du skapar ett förberett uttalande som accepterar en sträng som en parameter som i detta Senaste svaret
min. I det svaret, titta på det andra blocket som visar CREATE PROCEDURE och dess andra parameter som accepterar en sträng som (1,2,3) . Jag återkommer till denna punkt om ett ögonblick.
Inte för att du behöver se det @spraff men andra kanske. Uppdraget är att få typen !=ALLA och möjliga_nycklar och nycklar av Förklara att inte visa null, som du visade i ditt andra block. För en allmän läsning om ämnet, se artikeln Understanding EXPLAINs utdata
och MySQL-manualsidan med titeln EXPLAIN Extra information
.
Tillbaka till (1,2,3) referens ovan. Vi vet från din kommentar och din andra Förklara utdata i din fråga att den uppfyller följande önskade villkor:
- typ =intervall (och i synnerhet inte ALLA) . Se dokumenten ovan om detta.
- nyckeln är inte null
Det här är exakt de villkor du har i din andra Explain-utdata, och utdata som kan ses med följande fråga:
explain
select * from ratings where id in (2331425, 430364, 4557546, 2696638, 4510549, 362832, 2382514, 1424071, 4672814, 291859, 1540849, 2128670, 1320803, 218006, 1827619, 3784075, 4037520, 4135373, ... use your imagination ..., ..., 4369522, 3312835);
där jag har 999 värden i den in klausullista. Det är ett exempel från det här svaret
av mina i Appendix D genererar en sådan slumpmässig sträng av csv, omgiven av öppna och stängda parenteser.
Och notera följande Förklara utdata för det 999-elementet i klausulen nedan:

Målet uppnått. Du uppnår detta med en lagrad proc som liknar den jag nämnde tidigare i denna länk
med ett FÖRBÄTTAT UTTALANDE
(och dessa saker använder concat() följt av en EXECUTE ).
Indexet används, en Tablescan (vilket betyder dåligt) upplevs inte. Ytterligare avläsningar är The range Join Type
, alla referenser du kan hitta på MySQL:s kostnadsbaserade optimerare (CBO), detta svar
från vladr dock daterad, med ett öga på ANALYSE TABELL
del, särskilt efter betydande dataförändringar. Observera att ANALYSE kan ta en betydande tid att köra på extremt stora datamängder. Ibland många många timmar.
Sql Injection Attacks:
Användning av strängar som skickas till lagrade procedurer är en attackvektor för SQL Injection-attacker. Försiktighetsåtgärder måste vidtas för att förhindra dem när du använder data från användaren. Om din rutin tillämpas mot dina egna id:n som genereras av ditt system, då är du säker. Notera dock att SQL Injection-attacker på andra nivån inträffar när data infördes av rutiner som inte sanerade dessa data i en tidigare infogning eller uppdatering. Attacker som genomfördes tidigare via data och användes senare (en sorts tidsinställd bomb).
Så det här svaret är Färdigt för det mesta.
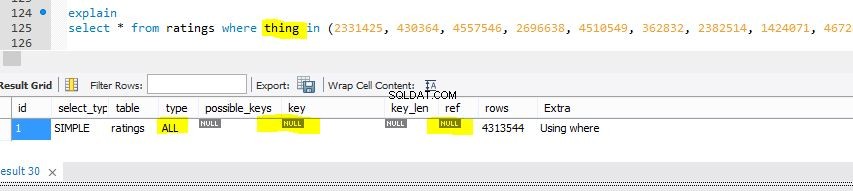
Nedan är en vy av samma tabell med en mindre modifiering av den för att visa vilken fruktad Tablescan skulle se ut som i den föregående frågan (men mot en icke-indexerad kolumn som heter thing ).
Ta en titt på vår nuvarande tabelldefinition:
CREATE TABLE `ratings` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`thing` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5046214 DEFAULT CHARSET=utf8;
select min(id), max(id),count(*) as theCount from ratings;
+---------+---------+----------+
| min(id) | max(id) | theCount |
+---------+---------+----------+
| 1 | 5046213 | 4718592 |
+---------+---------+----------+
Observera att kolumnen thing var en nullbar int-kolumn tidigare.
update ratings set thing=id where id<1000000;
update ratings set thing=id where id>=1000000 and id<2000000;
update ratings set thing=id where id>=2000000 and id<3000000;
update ratings set thing=id where id>=3000000 and id<4000000;
update ratings set thing=id where id>=4000000 and id<5100000;
select count(*) from ratings where thing!=id;
-- 0 rows
ALTER TABLE ratings MODIFY COLUMN thing int not null;
-- current table definition (after above ALTER):
CREATE TABLE `ratings` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`thing` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5046214 DEFAULT CHARSET=utf8;
Och sedan Explain that is a Tablescan (mot kolumn thing ):