Prestanda är extremt viktigt i många konsumentprodukter som e-handel, betalningssystem, spel, transportappar och så vidare. Även om databaser är internt optimerade genom flera mekanismer för att möta deras prestandakrav i den moderna världen, beror mycket på applikationsutvecklaren också - trots allt är det bara en utvecklare som vet vilka frågor applikationen måste utföra.
Utvecklare som sysslar med relationsdatabaser har använt eller åtminstone hört talas om indexering, och det är ett mycket vanligt begrepp i databasvärlden. Den viktigaste delen är dock att förstå vad som ska indexeras och hur indexeringen kommer att öka frågans svarstid. För att göra det måste du förstå hur du ska fråga dina databastabeller. Ett korrekt index kan bara skapas när du vet exakt hur dina sök- och dataåtkomstmönster ser ut.
I enkel terminologi mappar ett index söknycklar till motsvarande data på disken genom att använda olika datastrukturer i minnet och på disken. Index används för att påskynda sökningen genom att minska antalet poster att söka efter.
Oftast skapas ett index på kolumnerna som anges i WHERE klausul i en fråga när databasen hämtar och filtrerar data från tabellerna baserat på dessa kolumner. Om du inte skapar ett index skannar databasen alla rader, filtrerar bort de matchande raderna och returnerar resultatet. Med miljontals poster kan denna skanningsoperation ta många sekunder och den här höga svarstiden gör API:er och applikationer långsammare och oanvändbara. Låt oss se ett exempel -
Vi kommer att använda MySQL med en standard InnoDB-databasmotor, även om koncepten som förklaras i den här artikeln är mer eller mindre desamma i andra databasservrar liksom Oracle, MSSQL etc.
Skapa en tabell som heter index_demo med följande schema:
CREATE TABLE index_demo (
name VARCHAR(20) NOT NULL,
age INT,
pan_no VARCHAR(20),
phone_no VARCHAR(20)
);Hur verifierar vi att vi använder InnoDB-motorn?
Kör kommandot nedan:
SHOW TABLE STATUS WHERE name = 'index_demo' \G;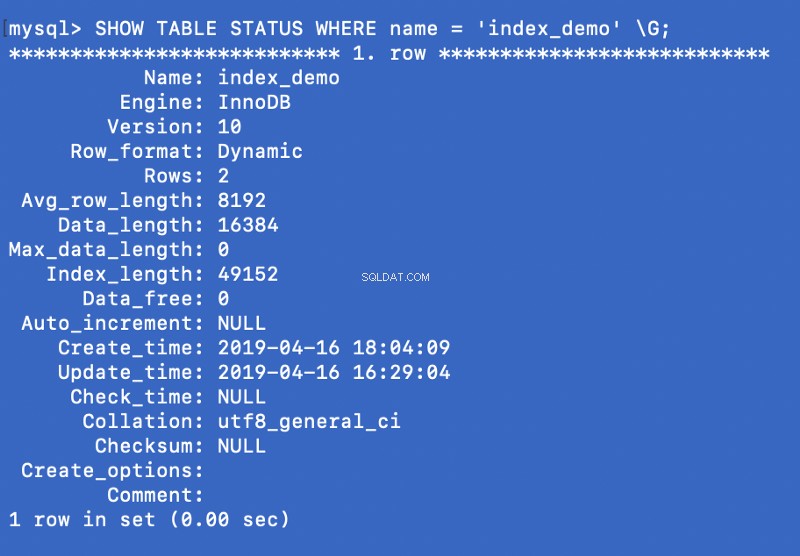
Engine kolumnen i skärmdumpen ovan representerar motorn som används för att skapa tabellen. Här InnoDB används.
Infoga nu några slumpmässiga data i tabellen, min tabell med 5 rader ser ut som följande:
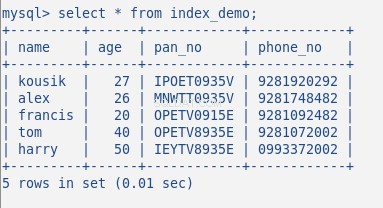
Jag har inte skapat något index för denna tabell förrän nu. Låt oss verifiera detta med kommandot:SHOW INDEX . Det ger 0 resultat.

För närvarande, om vi kör en enkel SELECT fråga, eftersom det inte finns något användardefinierat index, kommer frågan att skanna hela tabellen för att ta reda på resultatet:
EXPLAIN SELECT * FROM index_demo WHERE name = 'alex';
EXPLAIN visar hur frågemotorn planerar att köra frågan. I skärmdumpen ovan kan du se att rows kolumnen returnerar 5 &possible_keys returnerar null . possible_keys representerar alla tillgängliga index som kan användas i den här frågan. key kolumnen representerar vilket index som faktiskt kommer att användas av alla möjliga index i den här frågan.
Primär nyckel:
Ovanstående fråga är mycket ineffektiv. Låt oss optimera den här frågan. Vi gör phone_no kolumn a PRIMARY KEY förutsatt att det inte finns två användare i vårt system med samma telefonnummer. Tänk på följande när du skapar en primärnyckel:
- En primärnyckel bör vara en del av många viktiga frågor i din ansökan.
- Primärnyckel är en begränsning som unikt identifierar varje rad i en tabell. Om flera kolumner är en del av primärnyckeln bör den kombinationen vara unik för varje rad.
- Primärnyckel ska vara icke-null. Gör aldrig null-aktiverade fält till din primära nyckel. Enligt ANSI SQL-standarder bör primärnycklar vara jämförbara med varandra, och du bör definitivt kunna se om kolumnvärdet för primärnyckeln för en viss rad är större, mindre eller lika med densamma från den andra raden. Sedan
NULLbetyder ett odefinierat värde i SQL-standarder, du kan inte deterministiskt jämföraNULLmed något annat värde, så logisktNULLär inte tillåtet. - Den idealiska primärnyckeltypen bör vara ett tal som
INTellerBIGINTeftersom heltalsjämförelser är snabbare, så att gå igenom indexet kommer att gå mycket snabbt.
Ofta definierar vi ett id fält som AUTO INCREMENT i tabeller och använd det som en primärnyckel, men valet av en primärnyckel beror på utvecklarna.
Vad händer om du inte skapar någon primärnyckel själv?
Det är inte obligatoriskt att skapa en primärnyckel själv. Om du inte har definierat någon primärnyckel, skapar InnoDB implicit en åt dig eftersom InnoDB av design måste ha en primärnyckel i varje tabell. Så när du skapar en primärnyckel senare för den tabellen, tar InnoDB bort den tidigare automatiskt definierade primärnyckeln.
Eftersom vi inte har någon primärnyckel definierad just nu, låt oss se vad InnoDB som standard skapade för oss:
SHOW EXTENDED INDEX FROM index_demo;
EXTENDED visar alla index som inte är användbara av användaren men som hanteras helt av MySQL.
Här ser vi att MySQL har definierat ett sammansatt index (vi kommer att diskutera sammansatta index senare) på DB_ROW_ID , DB_TRX_ID , DB_ROLL_PTR , &alla kolumner definierade i tabellen. I avsaknad av en användardefinierad primärnyckel används detta index för att hitta poster unikt.
Vad är skillnaden mellan nyckel och index?
Även om termerna key &index används omväxlande, key betyder en begränsning som läggs på kolonnens beteende. I det här fallet är begränsningen att primärnyckeln är ett fält som inte kan null, vilket unikt identifierar varje rad. Å andra sidan, index är en speciell datastruktur som underlättar datasökning över hela tabellen.
Låt oss nu skapa det primära indexet på phone_no &granska det skapade indexet:
ALTER TABLE index_demo ADD PRIMARY KEY (phone_no);
SHOW INDEXES FROM index_demo;
Observera att CREATE INDEX kan inte användas för att skapa ett primärt index, men ALTER TABLE används.

I skärmdumpen ovan ser vi att ett primärt index skapas i kolumnen phone_no . Kolumnerna i följande bilder beskrivs enligt följande:
Table :Tabellen där indexet skapas.
Non_unique :Om värdet är 1 är indexet inte unikt, om värdet är 0 är indexet unikt.
Key_name :Namnet på det skapade indexet. Namnet på det primära indexet är alltid PRIMARY i MySQL, oavsett om du har angett något indexnamn eller inte när du skapade indexet.
Seq_in_index :Löpnumret för kolumnen i indexet. Om flera kolumner ingår i indexet kommer sekvensnumret att tilldelas baserat på hur kolumnerna ordnades under tiden för att skapa index. Sekvensnummer börjar från 1.
Collation :hur kolumnen sorteras i indexet. A betyder stigande, D betyder fallande, NULL betyder inte sorterad.
Cardinality :Det uppskattade antalet unika värden i indexet. Mer kardinalitet betyder större chanser att frågeoptimeraren väljer index för frågor.
Sub_part :Indexprefixet. Det är NULL om hela kolumnen är indexerad. Annars visar den antalet indexerade byte om kolumnen är delvis indexerad. Vi kommer att definiera partiellt index senare.
Packed :Indikerar hur nyckeln är packad; NULL om det inte är det.
Null :YES om kolumnen kan innehålla NULL värden och blank om den inte gör det.
Index_type :Indikerar vilken indexeringsdatastruktur som används för detta index. Några möjliga kandidater är — BTREE , HASH , RTREE , eller FULLTEXT .
Comment :Informationen om indexet som inte beskrivs i dess egen kolumn.
Index_comment :Kommentaren för indexet som angavs när du skapade indexet med COMMENT attribut.
Låt oss nu se om detta index minskar antalet rader som kommer att sökas efter för ett givet phone_no i WHERE klausul i en fråga.
EXPLAIN SELECT * FROM index_demo WHERE phone_no = '9281072002';
I den här ögonblicksbilden, lägg märke till att rows kolumnen har returnerat 1 endast possible_keys &key båda returnerar PRIMARY . Så det betyder i huvudsak att använda det primära indexet som heter PRIMARY (namnet tilldelas automatiskt när du skapar primärnyckeln), frågeoptimeraren går bara direkt till posten och hämtar den. Det är väldigt effektivt. Det är precis vad ett index är till för – för att minimera sökomfånget till priset av extra utrymme.
Clustered Index:
Ett clustered index är samlokaliserad med data i samma tabellutrymme eller samma diskfil. Du kan anse att ett klustrat index är ett B-Tree index vars bladnoder är de faktiska datablocken på disken, eftersom index och data finns tillsammans. Denna typ av index organiserar fysiskt data på disken enligt den logiska ordningen för indexnyckeln.
Vad betyder fysisk dataorganisation?
Fysiskt är data organiserade på disk över tusentals eller miljoner diskar/datablock. För ett klustrat index är det inte obligatoriskt att alla diskblock lagras smittsamt. Fysiska datablock flyttas hela tiden hit och dit av operativsystemet närhelst det är nödvändigt. Ett databassystem har ingen absolut kontroll över hur fysiskt datautrymme hanteras, men inuti ett datablock kan poster lagras eller hanteras i indexnyckelns logiska ordning. Följande förenklade diagram förklarar det:
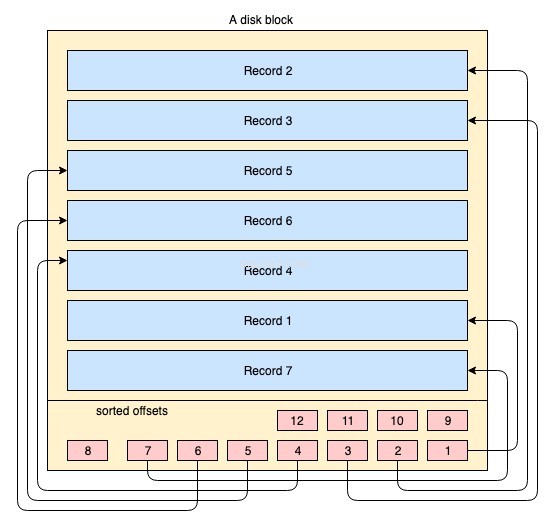
- Den gulfärgade stora rektangeln representerar ett diskblock/datablock
- de blåfärgade rektanglarna representerar data lagrade som rader inuti blocket
- sidfotsområdet representerar indexet för blocket där rödfärgade små rektanglar finns i sorterad ordning efter en viss nyckel. Dessa små block är inget annat än en sorts pekare som pekar på förskjutningar av posterna.
Posterna lagras på diskblocket i valfri ordning. När nya poster läggs till läggs de till i nästa tillgängliga utrymme. Närhelst en befintlig post uppdateras bestämmer operativsystemet om posten fortfarande kan passa in i samma position eller om en ny position måste tilldelas för den posten.
Så posternas position hanteras helt av OS och det finns inget bestämt samband mellan ordningen på två poster. För att hämta posterna i den logiska nyckelordningen, innehåller disksidor en indexsektion i sidfoten, indexet innehåller en lista med offsetpekare i nyckelordningen. Varje gång en post ändras eller skapas, justeras indexet.
På så sätt behöver du verkligen inte bry dig om att faktiskt organisera den fysiska posten i en viss ordning, snarare upprätthålls en liten indexsektion i den ordningen och det blir mycket enkelt att hämta eller underhålla poster.
Fördel med Clustered Index:
Denna ordning eller samlokalisering av relaterad data gör faktiskt ett klustrat index snabbare. När data hämtas från disk läses hela blocket som innehåller data av systemet eftersom vårt disk IO-system skriver och läser data i block. Så vid intervallfrågor är det mycket möjligt att den samlokaliserade datan buffras i minnet. Säg att du aktiverar följande fråga:
SELECT * FROM index_demo WHERE phone_no > '9010000000' AND phone_no < '9020000000'
Ett datablock hämtas i minnet när frågan exekveras. Säg att datablocket innehåller phone_no i intervallet från 9010000000 till 9030000000 . Så vilket intervall du än begärde i frågan är bara en delmängd av data som finns i blocket. Om du nu aktiverar nästa fråga för att få alla telefonnummer i intervallet, säg från 9015000000 till 9019000000 , du behöver inte hämta några fler block från disken. Den fullständiga informationen kan hittas i det aktuella datablocket, alltså clustered_index minskar antalet disk-IO genom att samlokalisera relaterade data så mycket som möjligt i samma datablock. Denna reducerade disk-IO ger förbättringar i prestanda.
Så om du har en väl genomtänkt primärnyckel och dina frågor är baserade på primärnyckeln, kommer prestandan att vara supersnabb.
Begränsningar för Clustered Index:
Eftersom ett klustrat index påverkar den fysiska organisationen av data kan det bara finnas ett klustrat index per tabell.
Relation mellan primärnyckel och klusterindex:
Du kan inte skapa ett klustrat index manuellt med InnoDB i MySQL. MySQL väljer det åt dig. Men hur väljer den? Följande utdrag är från MySQL-dokumentationen:
När du definierar enPRIMARY KEYpå ditt bord,InnoDBanvänder det som det klustrade indexet. Definiera en primärnyckel för varje tabell som du skapar. Om det inte finns någon logisk unik och icke-null kolumn eller uppsättning kolumner, lägg till en ny kolumn för automatisk ökning, vars värden fylls i automatiskt.
Om du inte definierar enPRIMARY KEYför ditt bord, MySQL hittar den förstaUNIQUEindex där alla nyckelkolumner ärNOT NULLochInnoDBanvänder det som det klustrade indexet.
Om tabellen inte har någonPRIMARY KEYeller lämpligUNIQUEindex,InnoDBgenererar internt ett dolt klustrat index med namnetGEN_CLUST_INDEXpå en syntetisk kolumn som innehåller rad-ID-värden. Raderna är ordnade efter ID:t somInnoDBtilldelar raderna i en sådan tabell. Rad-ID är ett 6-byte-fält som ökar monotont när nya rader infogas. Således är raderna ordnade av rad-ID:t fysiskt i infogningsordning.
Kort sagt, MySQL InnoDB-motorn hanterar faktiskt det primära indexet som ett klustrat index för att förbättra prestanda, så primärnyckeln och den faktiska posten på disken klustras tillsammans.
Struktur av primär nyckel (klustrad) Index:
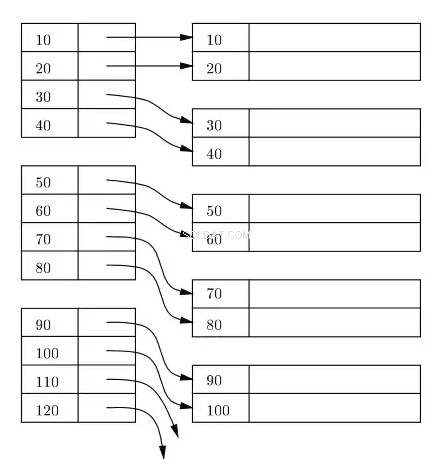
Ett index upprätthålls vanligtvis som ett B+-träd på disk och i minnet, och alla index lagras i block på disken. Dessa block kallas indexblock. Posterna i indexblocket sorteras alltid på index-/söknyckeln. Lövindexblocket i indexet innehåller en radlokaliserare. För det primära indexet hänvisar radlokaliseringen till den virtuella adressen för motsvarande fysiska plats för datablocken på disken där raderna finns sorterade enligt indexnyckeln.
I följande diagram representerar de vänstra rektanglarna bladnivåindexblock, och de högra rektanglarna representerar datablocken. Logiskt sett ser datablocken ut att vara inriktade i en sorterad ordning, men som redan beskrivits tidigare kan de faktiska fysiska platserna vara utspridda här &där.
Är det möjligt att skapa ett primärt index på en icke-primär nyckel?
I MySQL skapas automatiskt ett primärt index och vi har redan beskrivit ovan hur MySQL väljer det primära indexet. Men i databasvärlden är det faktiskt inte nödvändigt att skapa ett index på primärnyckelkolumnen - det primära indexet kan också skapas på vilken icke-primärnyckelkolumn som helst. Men när de skapas på primärnyckeln är alla nyckelposter unika i indexet, medan i det andra fallet kan det primära indexet också ha en duplicerad nyckel.
Är det möjligt att ta bort en primärnyckel?
Det är möjligt att ta bort en primärnyckel. När du tar bort en primärnyckel försvinner det relaterade klustrade indexet såväl som unikhetsegenskapen för den kolumnen.
ALTER TABLE `index_demo` DROP PRIMARY KEY;
- If the primary key does not exist, you get the following error:
"ERROR 1091 (42000): Can't DROP 'PRIMARY'; check that column/key exists"Fördelar med Primary Index:
- Primära indexbaserade intervallfrågor är mycket effektiva. Det kan finnas en möjlighet att diskblocket som databasen har läst från disken innehåller all data som hör till frågan, eftersom det primära indexet är klustrade och poster ordnas fysiskt. Så lokaliseringen av data kan tillhandahållas av det primära indexet.
- Alla frågor som drar fördel av primärnyckeln är mycket snabba.
Nackdelar med primärt index:
- Eftersom det primära indexet innehåller en direkt referens till datablockadressen genom det virtuella adressutrymmet och diskblocken är fysiskt organiserade i indexnyckelns ordning, varje gång operativsystemet delar upp en skiva på grund av
DMLoperationer somINSERT/UPDATE/DELETE, det primära indexet måste också uppdateras. AlltsåDMLoperationer sätter viss press på det primära indexets prestanda.
Sekundärt index:
Alla andra index än ett klustrade index kallas ett sekundärt index. Sekundära index påverkar inte fysiska lagringsplatser till skillnad från primära index.
När behöver du ett sekundärt index?
Du kan ha flera användningsfall i din applikation där du inte frågar databasen med en primärnyckel. I vårt exempel phone_no är den primära nyckeln men vi kan behöva fråga databasen med pan_no eller name . I sådana fall behöver du sekundära index på dessa kolumner om frekvensen av sådana frågor är mycket hög.
Hur skapar man ett sekundärt index i MySQL?
Följande kommando skapar ett sekundärt index i name kolumnen i index_demo bord.
CREATE INDEX secondary_idx_1 ON index_demo (name);
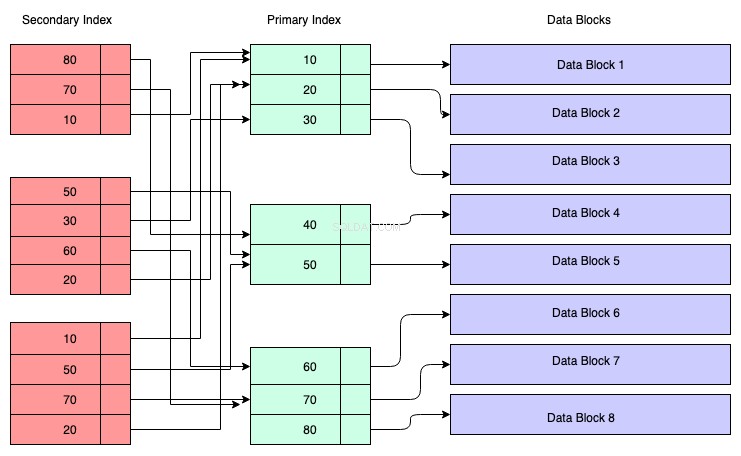
Struktur av sekundärt index:
I diagrammet nedan representerar de rödfärgade rektanglarna sekundära indexblock. Sekundärt index upprätthålls också i B+-trädet och det sorteras enligt nyckeln som indexet skapades på. Bladnoderna innehåller en kopia av nyckeln till motsvarande data i det primära indexet.
Så för att förstå kan du anta att det sekundära indexet har referens till primärnyckelns adress, även om det inte är fallet. Att hämta data genom det sekundära indexet innebär att du måste gå igenom två B+-träd — det ena är det sekundära index B+-trädet i sig och det andra är det primära index B+-trädet.
Fördelar med ett sekundärt index:
Logiskt sett kan du skapa så många sekundära index du vill. Men i verkligheten krävs en seriös tankeprocess för hur många index som faktiskt krävs eftersom varje index har sitt eget straff.
Nackdelar med ett sekundärt index:
Med DML operationer som DELETE / INSERT , måste det sekundära indexet också uppdateras så att kopian av primärnyckelkolumnen kan tas bort/infogas. I sådana fall kan förekomsten av många sekundära index skapa problem.
Dessutom, om en primärnyckel är mycket stor som en URL , eftersom sekundära index innehåller en kopia av värdet för primärnyckelkolumnen, kan det vara ineffektivt när det gäller lagring. Fler sekundära nycklar innebär ett större antal dubbletter av kolumnvärdet för primärnyckeln, så mer lagringsutrymme vid en stor primärnyckel. Även den primära nyckeln själv lagrar nycklarna, så den kombinerade effekten på lagringen blir mycket hög.
Övervägande innan du tar bort ett primärt index:
I MySQL kan du ta bort ett primärt index genom att släppa den primära nyckeln. Vi har redan sett att ett sekundärt index beror på ett primärt index. Så om du tar bort ett primärt index måste alla sekundära index uppdateras för att innehålla en kopia av den nya primära indexnyckeln som MySQL automatiskt justerar.
Denna process är dyr när det finns flera sekundära index. Även andra tabeller kan ha en främmande nyckelreferens till primärnyckeln, så du måste ta bort dessa främmande nyckelreferenser innan du tar bort primärnyckeln.
När en primärnyckel raderas skapar MySQL automatiskt en annan primärnyckel internt, och det är en kostsam operation.
UNIKT nyckelindex:
Precis som primärnycklar kan unika nycklar också identifiera poster unikt med en skillnad – den unika nyckelkolumnen kan innehålla null värden.
Till skillnad från andra databasservrar kan en unik nyckelkolumn i MySQL ha så många null värden som möjligt. I SQL-standard, null betyder ett odefinierat värde. Så om MySQL bara måste innehålla en null värde i en unik nyckelkolumn, måste den anta att alla nollvärden är desamma.
Men logiskt sett är detta inte korrekt eftersom null betyder odefinierat – och odefinierade värden kan inte jämföras med varandra, det är naturen hos null . Eftersom MySQL inte kan hävda om alla null s betyder detsamma, det tillåter flera null värden i kolumnen.
Följande kommando visar hur man skapar ett unikt nyckelindex i MySQL:
CREATE UNIQUE INDEX unique_idx_1 ON index_demo (pan_no);
Kompositindex:
MySQL låter dig definiera index på flera kolumner, upp till 16 kolumner. Detta index kallas ett index för flera kolumner/sammansatta/sammansatta.
Låt oss säga att vi har ett index definierat på 4 kolumner - col1 , col2 , col3 , col4 . Med ett sammansatt index har vi sökmöjligheter på col1 , (col1, col2) , (col1, col2, col3) , (col1, col2, col3, col4) . Så vi kan använda valfritt vänsterprefix i de indexerade kolumnerna, men vi kan inte utelämna en kolumn från mitten och använda det som — (col1, col3) eller (col1, col2, col4) eller col3 eller col4 etc. Dessa är ogiltiga kombinationer.
Följande kommandon skapar 2 sammansatta index i vår tabell:
CREATE INDEX composite_index_1 ON index_demo (phone_no, name, age);
CREATE INDEX composite_index_2 ON index_demo (pan_no, name, age);
Om du har frågor som innehåller en WHERE sats på flera kolumner, skriv satsen i ordningen för kolumnerna i det sammansatta indexet. Indexet kommer att gynna den frågan. I själva verket, medan du bestämmer kolumnerna för ett sammansatt index, kan du analysera olika användningsfall av ditt system och försöka komma fram till den ordning på kolumner som kommer att gynna de flesta av dina användningsfall.
Sammansatta index kan hjälpa dig att JOIN &SELECT frågor också. Exempel:i följande SELECT * fråga, composite_index_2 används.

När flera index är definierade väljer MySQL-frågeoptimeraren det index som eliminerar det största antalet rader eller skannar så få rader som möjligt för bättre effektivitet.
Varför använder vi sammansatta index ? Varför inte definiera flera sekundära index på de kolumner vi är intresserade av?
MySQL använder endast ett index per tabell per fråga förutom UNION. (I en UNION körs varje logisk fråga separat och resultaten slås samman.) Så att definiera flera index på flera kolumner garanterar inte att dessa index kommer att användas även om de är en del av frågan.
MySQL upprätthåller något som kallas indexstatistik som hjälper MySQL att sluta sig till hur data ser ut i systemet. Indexstatistik är dock en generilisering, men baserat på denna metadata bestämmer MySQL vilket index som är lämpligt för den aktuella frågan.
Hur fungerar sammansatt index?
Kolumnerna som används i sammansatta index är sammanlänkade, och dessa sammanlänkade nycklar lagras i sorterad ordning med hjälp av ett B+-träd. När du utför en sökning matchas sammansättningen av dina söknycklar mot de i det sammansatta indexet. Om det sedan finns någon oöverensstämmelse mellan ordningen av dina söknycklar och ordningen av de sammansatta indexkolumnerna, kan indexet inte användas.
I vårt exempel, för följande post, bildas en sammansatt indexnyckel genom att sammanfoga pan_no , name , age — HJKXS9086Wkousik28 .
+--------+------+------------+------------+
name
age
pan_no
phone_no
+--------+------+------------+------------+
kousik
28
HJKXS9086W
9090909090Så här identifierar du om du behöver ett sammansatt index:
- Analysera dina frågor först utifrån dina användningsfall. Om du ser att vissa fält visas tillsammans i många frågor kan du överväga att skapa ett sammansatt index.
- Om du skapar ett index i
col1&ett sammansatt index i (col1,col2), då borde bara det sammansatta indexet vara bra.col1enbart kan betjänas av det sammansatta indexet eftersom det är ett vänsterprefix av indexet. - Tänk på kardinalitet. Om kolumner som används i det sammansatta indexet har hög kardinalitet tillsammans, är de goda kandidater för det sammansatta indexet.
Täckningsindex:
Ett täckande index är en speciell sorts sammansatt index där alla kolumner som anges i frågan någonstans finns i indexet. Så frågeoptimeraren behöver inte träffa databasen för att få data – snarare får den resultatet från själva indexet. Exempel:vi har redan definierat ett sammansatt index på (pan_no, name, age) , så överväg nu följande fråga:
SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = 'kousik'
Kolumnerna som nämns i SELECT &WHERE klausuler är en del av det sammansatta indexet. Så i det här fallet kan vi faktiskt få värdet av age kolumn från själva det sammansatta indexet. Låt oss se vad EXPLAIN kommandot visar för denna fråga:
EXPLAIN FORMAT=JSON SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = '111kousik1';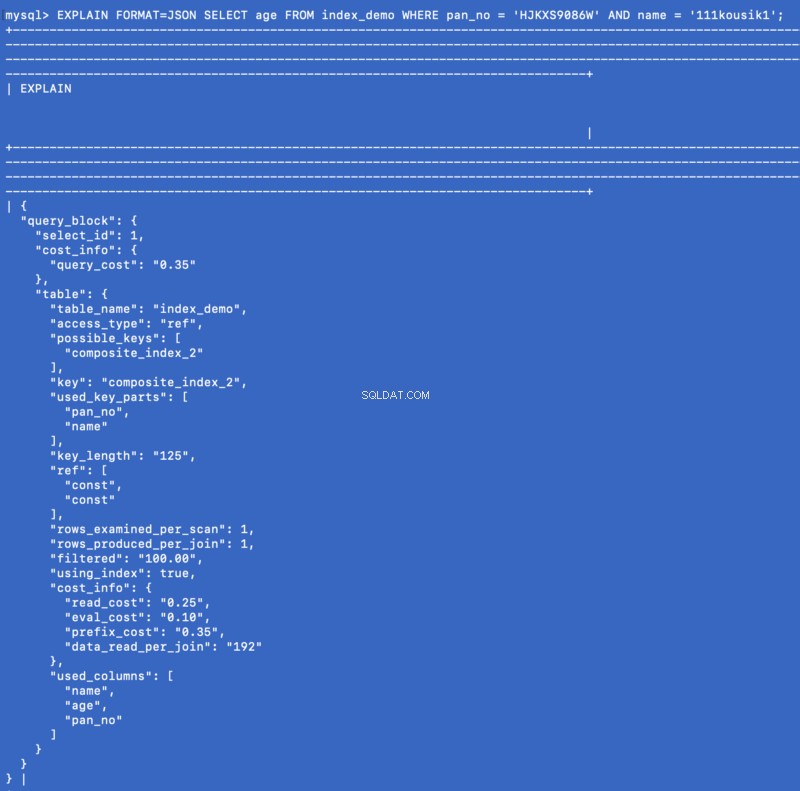
I svaret ovan, notera att det finns en nyckel — using_index som är inställd på true vilket betyder att det täckande indexet har använts för att svara på frågan.
Jag vet inte hur mycket täckande index uppskattas i produktionsmiljöer, men uppenbarligen verkar det vara en bra optimering ifall frågan passar.
Delvis index:
Vi vet redan att index påskyndar våra frågor på bekostnad av utrymme. Ju fler index du har, desto mer lagringsbehov. Vi har redan skapat ett index som heter secondary_idx_1 i kolumnen name . Kolumnen name kan innehålla stora värden oavsett längd. Också i indexet har radlokaliseringarnas eller radpekarnas metadata sin egen storlek. Så totalt sett kan ett index ha hög lagrings- och minnesbelastning.
I MySQL är det möjligt att skapa ett index på de första byten med data också. Exempel:följande kommando skapar ett index på de första 4 byten av namn. Även om den här metoden minskar minneskostnader med en viss mängd, kan indexet inte eliminera många rader, eftersom i det här exemplet kan de första 4 byten vara gemensamma för många namn. Vanligtvis stöds denna typ av prefixindexering på CHAR ,VARCHAR , BINARY , VARBINARY typ av kolumner.
CREATE INDEX secondary_index_1 ON index_demo (name(4));Vad händer under huven när vi definierar ett index?
Låt oss köra SHOW EXTENDED kommandot igen:
SHOW EXTENDED INDEXES FROM index_demo;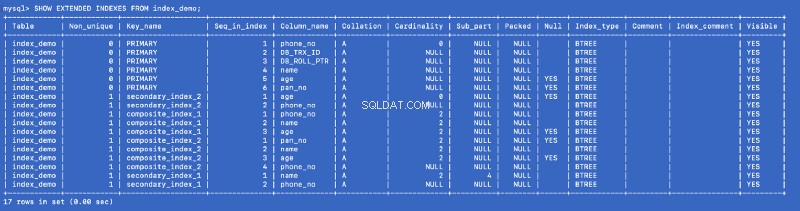
Vi definierade secondary_index_1 på name , men MySQL har skapat ett sammansatt index på (name , phone_no ) där phone_no är den primära nyckelkolumnen. Vi skapade secondary_index_2 på age &MySQL skapade ett sammansatt index på (age , phone_no ). Vi skapade composite_index_2 på (pan_no , name , age ) &MySQL har skapat ett sammansatt index på (pan_no , name , age , phone_no ). Det sammansatta indexet composite_index_1 har redan phone_no som en del av det.
Så vilket index vi än skapar skapar MySQL i bakgrunden ett sammansatt stödindex som i sin tur pekar på primärnyckeln. Detta betyder att den primära nyckeln är en förstklassig medborgare i MySQL-indexeringsvärlden. It also proves that all the indexes are backed by a copy of the primary index —but I am not sure whether a single copy of the primary index is shared or different copies are used for different indexes.
There are many other indices as well like Spatial index and Full Text Search index offered by MySQL. I have not yet experimented with those indices, so I’m not discussing them in this post.
General Indexing guidelines:
- Since indices consume extra memory, carefully decide how many &what type of index will suffice your need.
- With
DMLoperations, indices are updated, so write operations are quite costly with indexes. The more indices you have, the greater the cost. Indexes are used to make read operations faster. So if you have a system that is write heavy but not read heavy, think hard about whether you need an index or not. - Cardinality is important — cardinality means the number of distinct values in a column. If you create an index in a column that has low cardinality, that’s not going to be beneficial since the index should reduce search space. Low cardinality does not significantly reduce search space.
Example:if you create an index on a boolean (int1or0only ) type column, the index will be very skewed since cardinality is less (cardinality is 2 here). But if this boolean field can be combined with other columns to produce high cardinality, go for that index when necessary. - Indices might need some maintenance as well if old data still remains in the index. They need to be deleted otherwise memory will be hogged, so try to have a monitoring plan for your indices.
In the end, it’s extremely important to understand the different aspects of database indexing. It will help while doing low level system designing. Many real-life optimizations of our applications depend on knowledge of such intricate details. A carefully chosen index will surely help you boost up your application’s performance.
Please do clap &share with your friends &on social media if you like this article. :)
References:
- https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
- https://www.quora.com/What-is-difference-between-primary-index-and-secondary-index-exactly-And-whats-advantage-of-one-over-another
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html
- https://www.oreilly.com/library/view/high-performance-mysql/0596003064/ch04.html
- https://www.unofficialmysqlguide.com/covering-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/multiple-column-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/show-index.html
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html