En av mina största glädjeämnen som utvecklare är att lära mig hur olika teknologier korsas.
Under åren har jag haft möjlighet att arbeta med olika typer av mjukvara och verktyg. Av de många verktyg jag har använt är Python och Structured Query Language (SQL) två av mina favoriter.
I den här artikeln ska jag dela med dig av hur Python och de olika SQL-databaserna interagerar.
Jag ska prata om de mest populära databaserna, SQLite, MySQL och PostgreSQL. Jag kommer att förklara de viktigaste skillnaderna för varje databas och motsvarande användningsfall. Och jag avslutar artikeln med lite Python-kod.
Koden visar dig hur du skriver en SQL-fråga för att hämta data från en PostgreSQL-databas och lagra data i en pandas-dataram.
Om du inte är bekant med relationsdatabaser (RDBMS), föreslår jag att du kollar in Sameers artikel om grundläggande RDBMS-terminologi här. Resten av artikeln kommer att använda termer som refereras till i Sameers artikel.
Populära SQL-databaser
SQLite
SQLite är mest känt för att vara en integrerad databas. Det betyder att du inte behöver installera en extra applikation eller använda en separat server för att köra databasen.
Om du skapar en MVP eller inte behöver massor av datalagringsutrymme, vill du gå med en SQLite-databas.
Fördelen är att du kan röra dig snabbare med en SQLite-databas i förhållande till MySQL och PostgreSQL. Som sagt, du kommer att sitta fast med begränsad funktionalitet. Du kommer inte att kunna anpassa funktioner eller lägga till massor av fleranvändarfunktioner.
MySQL/PostgreSQL
Det finns tydliga skillnader mellan MySQL och PostgreSQL. Som sagt, med tanke på artikelns sammanhang, passar de in i en liknande kategori.
Båda databastyperna är bra för företagslösningar. Om du behöver skala snabbt är MySQL och PostgreSQL det bästa alternativet. De kommer att tillhandahålla långsiktig infrastruktur och stärka din säkerhet.
En annan anledning till att de är bra för företag är att de kan hantera högpresterande aktiviteter. Längre infoga, uppdatera och välja uttalanden kräver mycket datorkraft. Du kommer att kunna skriva dessa uttalanden med mindre latens än vad en SQLite-databas skulle ge dig.
Varför ansluta Python och en SQL-databas?
Du kanske undrar, "varför ska jag bry mig om att ansluta Python och en SQL-databas?"
Det finns många användningsfall för när någon skulle vilja ansluta Python till en SQL-databas. Som jag nämnde tidigare kanske du arbetar med en webbapplikation. I det här fallet måste du ansluta en SQL-databas så att du kan lagra data som kommer från webbapplikationen.
Kanske arbetar du inom datateknik och behöver bygga en automatiserad ETL-pipeline. Genom att ansluta Python till en SQL-databas kan du använda Python för dess automationsfunktioner. Du kommer också att kunna kommunicera mellan olika datakällor. Du behöver inte växla mellan olika programmeringsspråk.
Att ansluta Python och en SQL-databas kommer också att göra ditt datavetenskapsarbete mer bekvämt. Du kommer att kunna använda dina Python-färdigheter för att manipulera data från en SQL-databas. Du behöver ingen CSV-fil.
Hur Python- och SQL-databaser ansluter

Python- och SQL-databaser ansluts via anpassade Python-bibliotek. Du kan importera dessa bibliotek till ditt Python-skript.
Databasspecifika Python-bibliotek fungerar som kompletterande instruktioner. Dessa instruktioner vägleder din dator om hur den kan interagera med din SQL-databas. Annars kommer din Python-kod att vara ett främmande språk för databasen du försöker ansluta till.
Hur man ställer in projektet
Låt oss ta en PostgreSQL-databas, AWS Redshift, till exempel. Först vill du importera psycopg-biblioteket. Det är ett universellt Python-bibliotek för PostgreSQL-databaser.
#Library for connecting to AWS Redshift
import psycopg
#Library for reading the config file, which is in JSON
import json
#Data manipulation library
import pandas as pdDu kommer att märka att vi också importerade JSON- och pandasbiblioteken. Vi importerade JSON eftersom att skapa en JSON-konfigurationsfil är ett säkert sätt att lagra dina databasuppgifter. Vi vill inte att någon annan ska se dem!
Pandabiblioteket gör det möjligt för dig att använda alla pandas statistiska funktioner för ditt Python-skript. I det här fallet kommer biblioteket att göra det möjligt för Python att lagra data som din SQL-fråga returnerar i en dataram.
Därefter vill du komma åt din konfigurationsfil. json.load() funktionen läser JSON-filen så att du kan komma åt dina databasuppgifter i nästa steg.
config_file = open(r"C:\Users\yourname\config.json")
config = json.load(config_file)
Nu när ditt Python-skript kan komma åt din JSON-konfigurationsfil, vill du skapa en databasanslutning. Du måste läsa och använda inloggningsuppgifterna från din konfigurationsfil:
con = psycopg2.connect(dbname= "db_name", host=config[hostname], port = config["port"],user=config["user_id"], password=config["password_key"])
cur = con.cursor()Du skapade precis en databasanslutning! När du importerade psycopg-biblioteket översatte du Python-koden du skrev ovan för att tala till PostgreSQL-databasen (AWS Redshift).
I sig själv skulle AWS Redshift inte förstå ovanstående kod. Men eftersom du importerade psycopg-biblioteket talar du nu ett språk som AWS Redshift kan förstå.
Det fina med Python är att det har bibliotek för SQLite, MySQL och PostgreSQL. Du kommer att kunna integrera teknikerna med lätthet.
Hur man skriver en SQL-fråga
Hämta gärna European Soccer Data till din PostgreSQL-databas. Jag kommer att använda dess data för det här exemplet.
Databasanslutningen du skapade i det sista steget låter dig skriva SQL för att sedan lagra data i en Python-vänlig datastruktur. Nu när du har upprättat en databasanslutning kan du skriva en SQL-fråga för att börja hämta data:
query = "SELECT *
FROM League
JOIN Country ON Country.id = League.country_id;"Arbetet är dock inte klart än. Du måste skriva lite extra Python-kod som exekverar SQL-frågan:
#Runs your SQL query
execute1 = cur.execute(query)
result = cur.fetchall()Sedan måste du lagra den returnerade datan i en pandas dataram:
#Create initial dataframe from SQL data
raw_initial_df = pd.read_sql_query(query, con)
print(raw_initial_df)Du bör skaffa en pandas dataram (raw_initial_df) som ser ut ungefär så här:
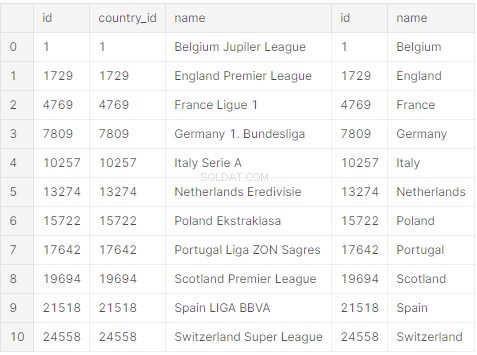
Det finns en databas för alla

SQLite, MySQL och PostgreSQL har alla sina för- och nackdelar. Vilken du väljer bör bero på ditt projekt eller företags behov. Du bör också överväga vad du behöver nu jämfört med flera år på vägen.
Det viktiga att komma ihåg är att Python kan integreras med varje databastyp.
Den här artikeln skrapar på ytan för vad som är möjligt med att ansluta Python till en SQL-databas. Jag älskar att se hur programvara korsas och kombineras för att tillföra ett otroligt värde.
Vill du ha mer av den här typen av innehåll hittar du mig på Course to Hire! Jag vill hjälpa fler människor att lära sig koda och få ett jobb inom tekniken. Hör av dig om du har frågor eller bara vill säga hej :)