Att köra ett Galera-kluster i ett hybridmoln bör bestå av minst två olika geografiska platser, som förbinder värdar i det lokala eller privata molnet med de i det offentliga molnet. Oavsett om du använder okrossbara privata moln eller offentliga molnplattformar är Disaster Recovery (DR) verkligen en nyckelfråga. Det här handlar inte om att kopiera din data till en säkerhetskopia och att kunna återställa den, det handlar om kontinuitet i verksamheten och hur snabbt du kan återställa tjänster när en katastrof inträffar.
I det här blogginlägget kommer vi att undersöka olika sätt att designa dina Galera-kluster för feltolerans i en hybridmolnmiljö.
Active-Active Setup
Galera Cluster bör köras med ett udda antal noder i ett kluster och börjar vanligtvis med 3 noder. Detta beror på att Galera Cluster använder kvorum för att automatiskt bestämma den primära komponenten, där en majoritet av anslutna noder ska kunna betjäna klustret åt gången, i händelse av klusterpartitionering.
För en aktiv-aktiv installation av hybridmolninstallationer kräver Galera minst 3 olika platser, som bildar ett Galera-kluster över WAN. I allmänhet skulle du behöva en tredje sida för att agera som skiljedomare, rösta för beslutförhet och bevara den "primära komponenten" om någon av webbplatserna inte går att nå. Detta kan ställas in som ett minimum av ett 3-nodskluster på 3 olika platser (1 nod per plats), liknande följande diagram:
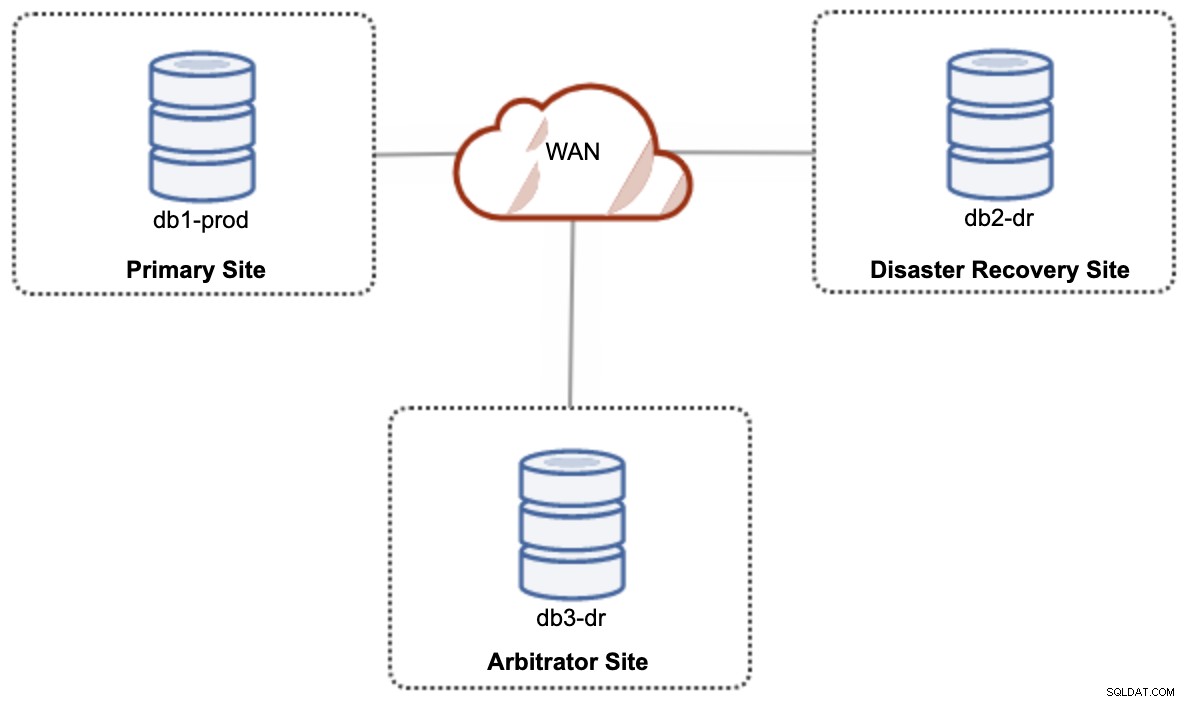
Men för prestanda- och tillförlitlighetsskäl rekommenderas det att ha en 7 -nodkluster, som visas i följande diagram:
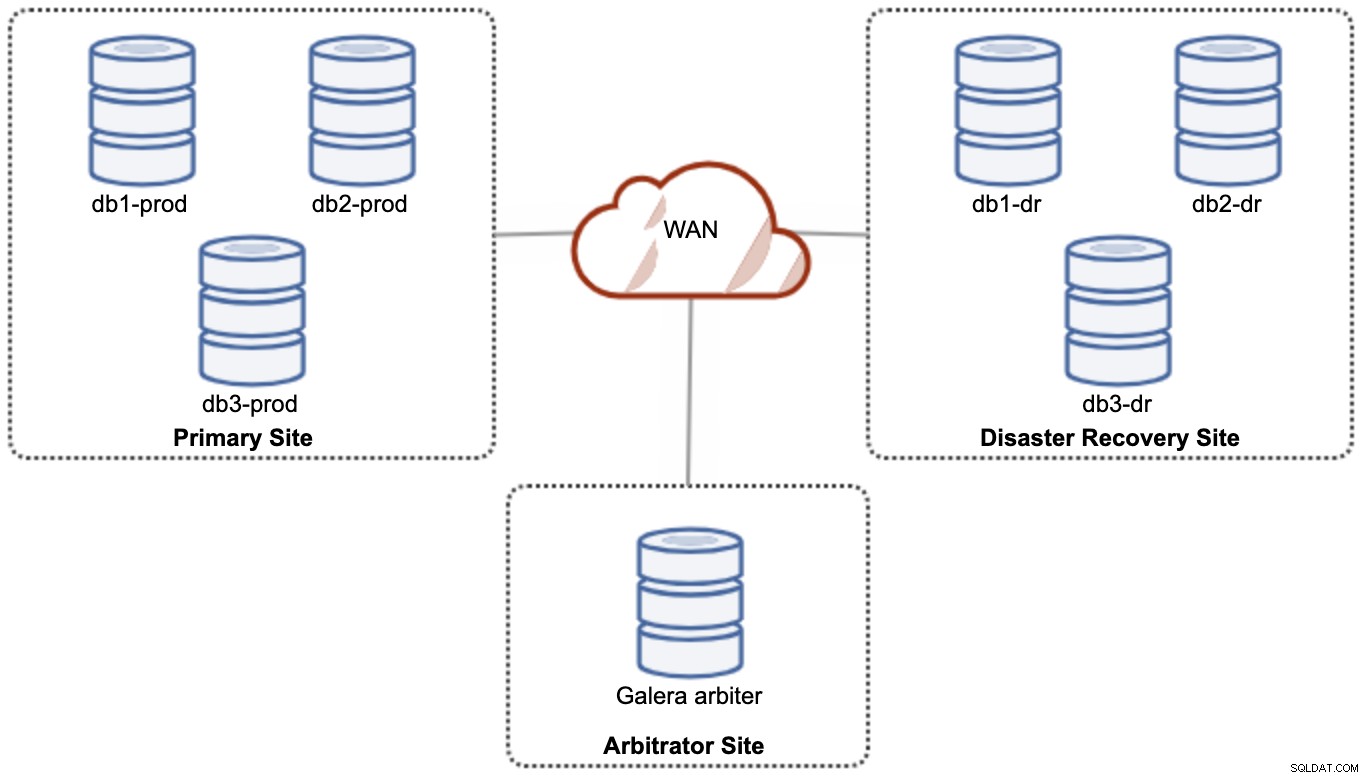
Detta anses vara den bästa topologin för att stödja en aktiv-aktiv installation, där DR-webbplatsen bör vara tillgänglig nästan omedelbart, utan någon inblandning. Båda webbplatserna kan ta emot läsningar/skrivningar när som helst förutsatt att klustret är i kvorumet.
Det är dock mycket kostsamt att ha 3 platser och 7 databasnoder (den 7:e noden kan ersättas med en garbd eftersom det är mycket osannolikt att den kommer att användas för att skicka data till klienterna/applikationerna). Detta är vanligtvis inte en populär implementering i början av projektet på grund av den enorma kostnaden i förväg och hur känslig Galera-gruppens kommunikation och replikering för nätverkslatens.
Active-Passive Setup
I en aktiv-passiv konfiguration krävs minst 2 webbplatser och endast en webbplats är aktiv åt gången, känd som den primära platsen och noderna på den sekundära platsen replikerar endast data som kommer från den primära platsen server/kluster. För Galera Cluster kan vi antingen använda MySQL asynkron replikering (master-slave replikering) eller så kan vi också använda Galeras praktiskt taget synkrona replikering med viss justering för att tona ner dess skrivuppsättningsreplikering för att fungera som asynkron replikering.
Den sekundära platsen måste skyddas mot oavsiktlig skrivning, genom att använda skrivskyddad flagga, programbrandvägg, omvänd proxy eller något annat sätt eftersom dataflödet alltid kommer från den primära till den sekundära platsen om inte en failover har initierat och marknadsfört den sekundära platsen som den primära.
Använda asynkron replikering
En bra sak med asynkron replikering är att replikeringen inte påverkar källservern/klustret, men det är tillåtet att släpa efter mastern. Denna inställning kommer att göra den primära och DR-platsen oberoende av varandra, löst kopplade till asynkron replikering. Detta kan ställas in som ett minimum av ett kluster med fyra noder på två olika platser, liknande följande diagram:
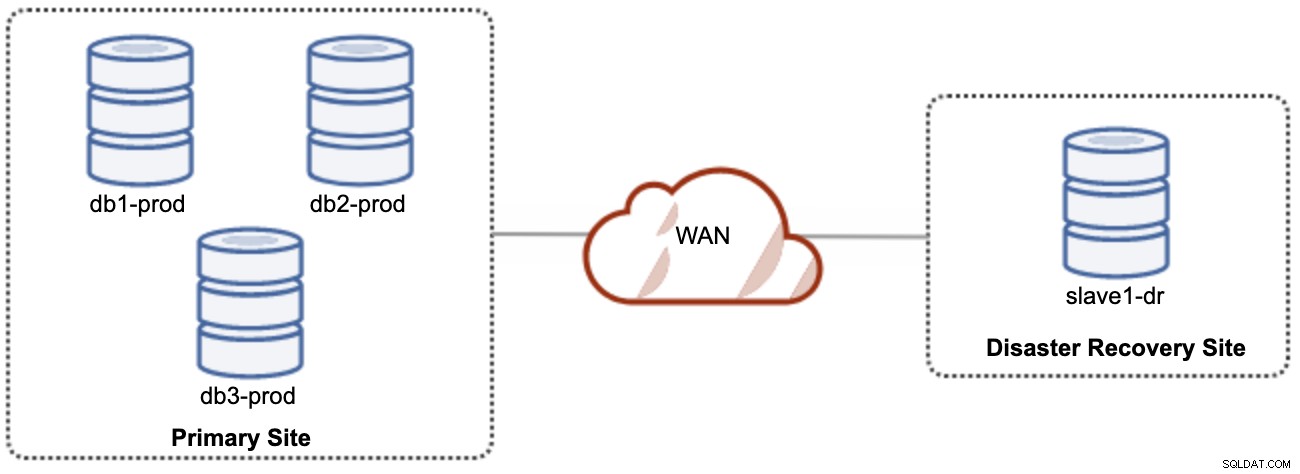
En av Galera-noderna på DR-webbplatsen kommer att vara en slav, som replikerar från en av Galera-noderna (master) på den primära platsen. Båda platserna måste producera binära loggar med GTID och log_slave_updates är aktiverade - uppdateringarna som kommer från den asynkrona replikeringsströmmen kommer att tillämpas på de andra noderna i klustret. För produktionsanvändning rekommenderar vi dock att ha två uppsättningar kluster på båda platserna, som visas i följande diagram:
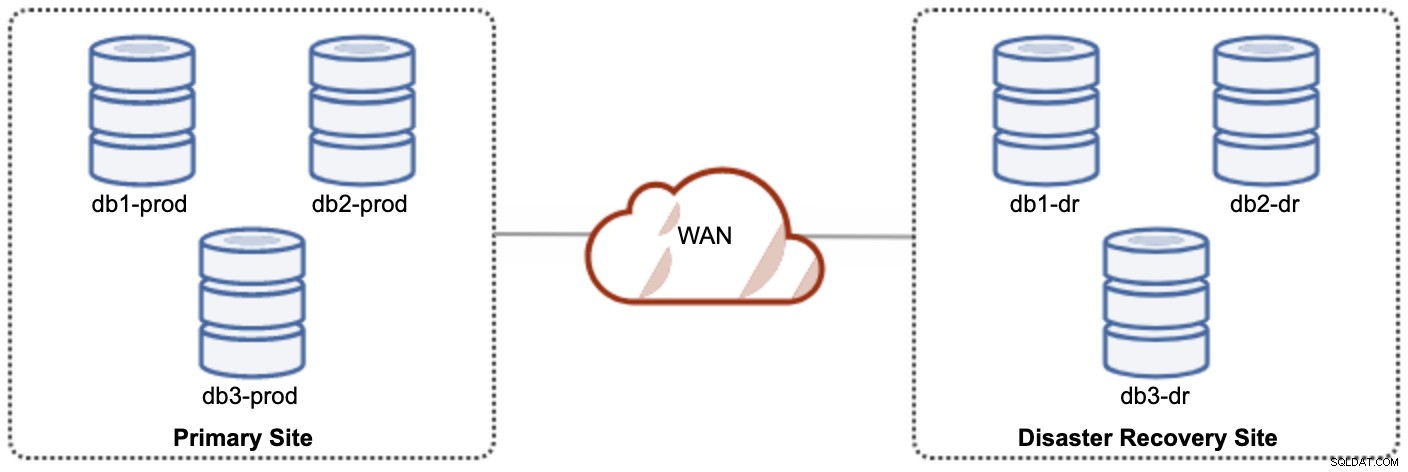
Genom att ha två separata kluster kommer de att vara löst kopplade och inte påverka varandra, t.ex. ett klusterfel på den primära platsen kommer inte att påverka DR-platsen. Prestandamässigt kommer WAN-latens inte att påverka uppdateringar på det aktiva klustret. Dessa skickas asynkront till säkerhetskopieringsplatsen. DR-klustret skulle potentiellt kunna köras på mindre instanser i en offentlig molnmiljö, så länge de kan hålla jämna steg med det primära klustret. Instanserna kan uppgraderas vid behov. Applikationer bör skicka skrivningar till den primära platsen, och den sekundära platsen måste ställas in för att köras i skrivskyddat läge. Katastrofåterställningsplatsen kan användas för andra ändamål som säkerhetskopiering av databas, säkerhetskopiering av binära loggar och rapportering eller bearbetning av analytiska frågor (OLAP).
På nackdelen finns det en risk för dataförlust under failover/fallback om slaven släpar efter. Därför rekommenderas det att aktivera semi-synkron replikering för att minska risken för dataförlust. Observera att användning av semisynkron replikering fortfarande inte ger några starka garantier mot dataförlust, om man jämför med Galeras praktiskt taget synkrona replikering. Läs denna MySQL-manual noggrant, till exempel dessa meningar:
"Med semisynkron replikering, om källan kraschar och en failover till en replik utförs, ska den misslyckade källan inte återanvändas som replikeringskälla och ska kasseras. Den kan ha transaktioner som var inte erkänd av någon replik, som därför inte begicks före failover."
Feilövergångsprocessen är ganska enkel. För att marknadsföra webbplatsen för katastrofåterställning, stäng helt enkelt av skrivskyddad flagga och börja dirigera applikationen till databasnoderna på DR-webbplatsen. Reservstrategin är dock lite knepig och den kräver viss expertis i att iscensätta data på båda platserna, byta master/slav-roll för ett kluster och omdirigera slavreplikeringsflödet till motsatt väg.
Använda Galera Replication
För aktiv-passiv installation kan vi placera majoriteten av noderna på den primära platsen medan minoriteten av noderna finns på katastrofåterställningsplatsen, som visas i följande skärmdump för en 3- nod Galera Cluster:
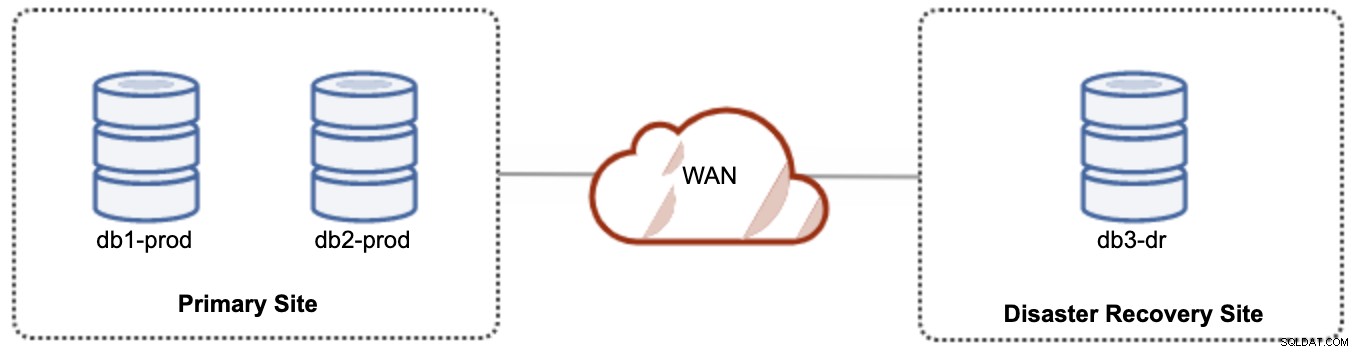
Om den primära webbplatsen är nere kommer klustret att misslyckas eftersom det inte är kvorum. Galera-noden på katastrofåterställningsplatsen (db3-dr) måste bootstrappas manuellt som en primär komponent för en enda nod. När den primära platsen väl kommer upp igen måste båda noderna på den primära platsen (db1-prod och db2-prod) gå med i galera3 igen för att bli synkroniserade. Att ha en ganska stor gcache bör bidra till att minska risken för SST över WAN. Denna arkitektur är lätt att ställa in och administrera och mycket kostnadseffektiv.
Failover är manuell, eftersom administratören måste marknadsföra den enskilda noden som den primära komponenten (bootstrap db3-dr eller använd set pc.bootstrap=1 i parametern wsrep_provider_options. Det skulle bli stillestånd under tiden . Prestanda kan vara ett problem, eftersom DR-webbplatsen kommer att köras med ett mindre antal noder (eftersom DR-platsen alltid är minoriteten) för att köra hela belastningen. Det kan vara möjligt att skala ut med fler noder efter att ha bytt till DR-webbplats men se upp för den extra belastningen.
Observera att Galera Cluster är känsligt för nätverket på grund av dess praktiskt taget synkrona karaktär. Ju längre Galera-noderna befinner sig i ett givet kluster, desto högre latens och dess skrivförmåga för att distribuera och certifiera skrivuppsättningarna. Dessutom, om anslutningen inte är stabil, kan klusterpartitionering lätt inträffa, vilket kan utlösa klustersynkronisering på joinernoderna. I vissa fall kan detta introducera instabilitet i klustret. Detta kräver lite justering av Galera-parametrar, som visas i det här blogginlägget, Deploying a Hybrid Infrastructure Environment for Percona XtraDB Cluster.
Sluta tankar
Galera Cluster är en fantastisk teknik som kan distribueras på olika sätt - ett kluster sträckt sig över flera platser, flera kluster hålls synkroniserade via asynkron replikering, en blandning av synkron och asynkron replikering, och så vidare. Den faktiska lösningen kommer att dikteras av faktorer som WAN-latens, eventuellt mot stark datakonsistens och budget.