A single point of failure (SPOF) är en vanlig orsak till att organisationer arbetar för att sprida närvaron av sina databasmiljöer till en annan plats geografiskt. Det är en del av de strategiska planerna för katastrofåterställning och affärskontinuitet.
Disaster Recovery (DR)-planering innefattar tekniska procedurer som täcker förberedelserna för oförutsedda problem som naturkatastrofer, olyckor (som mänskliga misstag) eller incidenter (som kriminella handlingar).
Under det senaste decenniet har distribution av din databasmiljö över flera geografiska platser varit en ganska vanlig installation, eftersom offentliga moln erbjuder många sätt att hantera detta. Utmaningen ligger i att sätta upp databasmiljöer. Det skapar utmaningar när du försöker hantera databasen/databaserna, flytta dina data till en annan geo-plats eller tillämpa säkerhet med en hög nivå av observerbarhet.
I den här bloggen visar vi hur du kan göra detta med MySQL-replikering. Vi kommer att täcka hur du kan kopiera dina data till en annan databasnod som ligger i ett annat land långt från MySQL-klustrets nuvarande geografi. För det här exemplet är vår målregion baserad på us-east, medan min on-prem är i Asien i Filippinerna.
Varför behöver jag ett databaskluster för geografisk plats?
Till och med Amazon AWS, den främsta offentliga molnleverantören, hävdar att de lider av driftstopp eller oavsiktliga avbrott (som det som hände 2017). Låt oss säga att du använder AWS som ditt sekundära datacenter förutom ditt lokala. Du kan inte ha någon intern åtkomst till dess underliggande hårdvara eller till de interna nätverk som hanterar dina beräkningsnoder. Dessa är helt hanterade tjänster som du har betalat för, men du kan inte undvika det faktum att det kan drabbas av ett avbrott när som helst. Om en sådan geografisk plats drabbas av ett avbrott kan du ha långa driftstopp.
Den här typen av problem måste förutses under din affärskontinuitetsplanering. Den ska ha analyserats och implementerats utifrån vad som har definierats. Affärskontinuitet för dina MySQL-databaser bör inkludera hög drifttid. Vissa miljöer gör riktmärken och sätter höga krav på rigorösa tester inklusive den svaga sidan för att avslöja eventuell sårbarhet, hur motståndskraftig den kan vara och hur skalbar din teknologiarkitektur inklusive din databasinfrastruktur. För företag, särskilt de som hanterar höga transaktioner, är det absolut nödvändigt att se till att produktionsdatabaser är tillgängliga för applikationerna hela tiden även när en katastrof inträffar. Annars kan driftstopp upplevas och det kan kosta dig en stor summa pengar.
Med dessa identifierade scenarier börjar organisationer utöka sin infrastruktur till olika molnleverantörer och placera noder till olika geografiska platser för att få högre drifttid (om möjligt på 99.99999999999), lägre RPO och har ingen SPOF.
För att säkerställa att produktionsdatabaser överlever en katastrof måste en webbplats för återställning av katastrofer (DR) konfigureras. Produktions- och DR-sajter måste vara en del av två geografiskt avlägsna datacenter. Detta innebär att en reservdatabas måste konfigureras på DR-platsen för varje produktionsdatabas så att dataändringarna som sker i produktionsdatabasen omedelbart synkroniseras till standbydatabasen via transaktionsloggar. Vissa inställningar använder också sina DR-noder för att hantera läsningar för att ge lastbalansering mellan applikationen och datalagret.
Den önskade arkitektoniska inställningen
I den här bloggen är den önskade installationen enkel och ändå mycket vanlig implementering nuförtiden. Se nedan om den önskade arkitektoniska inställningen för denna blogg:
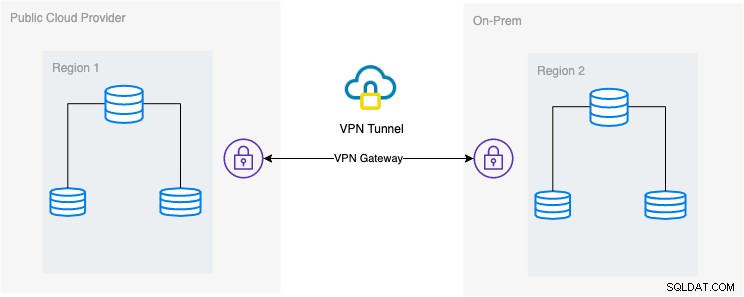
I den här bloggen väljer jag Google Cloud Platform (GCP) som offentlig molnleverantör och använder mitt lokala nätverk som min lokala databasmiljö.
Det är ett måste att när du använder denna typ av design behöver du alltid både miljö eller plattform för att kommunicera på ett mycket säkert sätt. Använda VPN eller använda alternativ som AWS Direct Connect. Även om dessa offentliga moln nuförtiden erbjuder hanterade VPN-tjänster som du kan använda. Men för den här installationen kommer vi att använda OpenVPN eftersom jag inte behöver sofistikerad hårdvara eller tjänst för den här bloggen.
Bästa och mest effektiva sättet
För MySQL/Percona/MariaDB-databasmiljöer är det bästa och effektivaste sättet att ta en säkerhetskopia av din databas, skicka till målnoden som ska distribueras eller instansieras. Det finns olika sätt att använda detta tillvägagångssätt, antingen kan du använda mysqldump, mydumper, rsync eller använda Percona XtraBackup/Mariabackup och strömma data som går till din målnod.
Använda mysqldump
mysqldump skapar en logisk säkerhetskopia av hela din databas eller så kan du selektivt välja en lista med databaser, tabeller eller till och med specifika poster som du ville dumpa.
Ett enkelt kommando som du kan använda för att ta en fullständig säkerhetskopia kan vara,
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | mysql -h <target-host-db-node -u<user> -p<password> -vvv --show-warningsMed detta enkla kommando kör den MySQL-satserna direkt till måldatabasnoden, till exempel din måldatabasnod på en Google Compute Engine. Detta kan vara effektivt när data är mindre eller du har en snabb bandbredd. Annars kan du välja att packa din databas till en fil och sedan skicka den till målnoden.
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | gzip > mydata.db
$ scp mydata.db <target-host>:/some/pathKör sedan mysqldump till måldatabasnoden som sådan,
zcat mydata.db | mysqlNackdelen med att använda logisk säkerhetskopiering med mysqldump är att den är långsammare och konsumerar diskutrymme. Den använder också en enda tråd så du kan inte köra detta parallellt. Alternativt kan du använda mydumper, särskilt när din data är för stor. mydumper kan köras parallellt men det är inte lika flexibelt jämfört med mysqldump.
Använda xtrabackup
xtrabackup är en fysisk backup där du kan skicka strömmar eller binär till målnoden. Detta är mycket effektivt och används mest när du streamar en säkerhetskopia över nätverket, särskilt när målnoden är av annan geografi eller annan region. ClusterControl använder xtrabackup när en ny slav tillhandahålls eller instansieras, oavsett var den befinner sig, så länge som åtkomst och behörighet har ställts in före åtgärden.
Om du använder xtrabackup för att köra det manuellt, kan du köra kommandot som sådant,
## Målnod
$ socat -u tcp-listen:9999,reuseaddr stdout 2>/tmp/netcat.log | xbstream -x -C /var/lib/mysql## Källnod
$ innobackupex --defaults-file=/etc/my.cnf --stream=xbstream --socket=/var/lib/mysql/mysql.sock --host=localhost --tmpdir=/tmp /tmp | socat -u stdio TCP:192.168.10.70:9999För att utveckla dessa två kommandon måste det första kommandot utföras eller köras först på målnoden. Kommandot för målnod lyssnar på port 9999 och kommer att skriva alla strömmar som tas emot från port 9999 i målnoden. Det är beroende av kommandona socat och xbstream vilket innebär att du måste se till att du har dessa paket installerade.
På källnoden kör den innobackupex perl-skriptet som anropar xtrabackup i bakgrunden och använder xbstream för att strömma data som kommer att skickas över nätverket. Socat-kommandot öppnar porten 9999 och skickar dess data till den önskade värden, som är 192.168.10.70 i detta exempel. Se ändå till att du har socat och xbstream installerade när du använder det här kommandot. Ett alternativt sätt att använda socat är nc men socat erbjuder mer avancerade funktioner jämfört med nc som serialisering som att flera klienter kan lyssna på en port.
ClusterControl använder detta kommando när man bygger om en slav eller bygger en ny slav. Det är snabbt och garanterar att den exakta kopian av dina källdata kommer att kopieras till din målnod. När du tillhandahåller en ny databas till en separat geo-plats, erbjuder detta tillvägagångssätt mer effektivitet och ger dig snabbare att slutföra jobbet. Även om det kan finnas för- och nackdelar när du använder logisk eller binär backup när den strömmas genom tråden. Att använda den här metoden är ett mycket vanligt tillvägagångssätt när man skapar ett nytt databaskluster för geolokalisering till en annan region och skapar en exakt kopia av din databasmiljö.
Effektivitet, observerbarhet och hastighet
Frågor som lämnas av de flesta människor som inte är bekanta med detta tillvägagångssätt täcker alltid "HUR, VAD, VAR"-problem. I det här avsnittet kommer vi att täcka hur du effektivt kan ställa in din geografiska platsdatabas med mindre arbete att hantera och med observerbarhet varför den misslyckas. Att använda ClusterControl är mycket effektivt. I denna nuvarande installation har jag följande miljö som initialt implementerad:
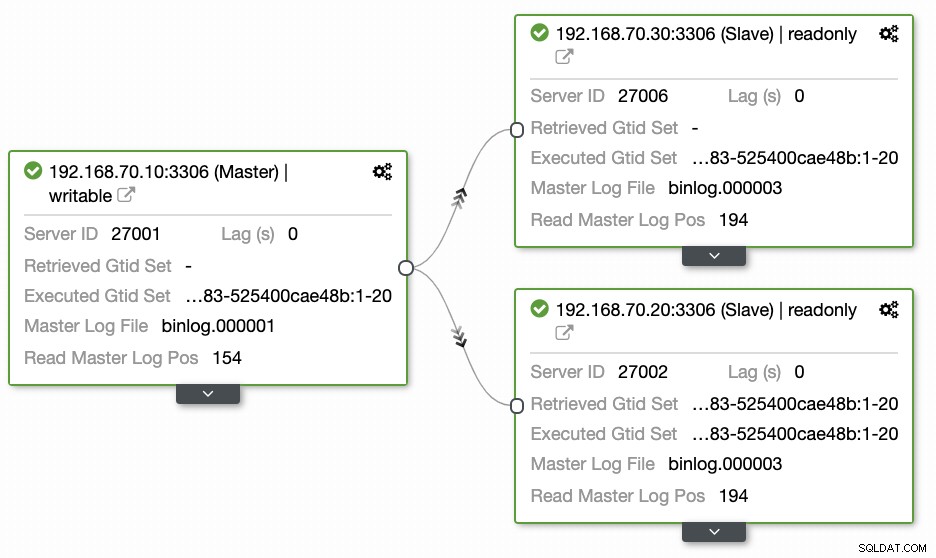
Utökar noden till GCP
När du börjar ställa in ditt geo-platsdatabaskluster, för att utöka ditt kluster och skapa en ögonblicksbildkopia av ditt kluster, kan du lägga till en ny slav. Som nämnts tidigare kommer ClusterControl att använda xtrabackup (mariabackup för MariaDB 10.2 och framåt) och distribuera en ny nod inom ditt kluster. Innan du kan registrera dina GCP-beräkningsnoder som dina målnoder måste du först ställa in lämplig systemanvändare på samma sätt som systemanvändaren du registrerade i ClusterControl. Du kan verifiera detta i din /etc/cmon.d/cmon_X.cnf, där X är cluster_id. Se till exempel nedan:
# grep 'ssh_user' /etc/cmon.d/cmon_27.cnf
ssh_user=maximusmaximus (i det här exemplet) måste finnas i dina GCP-beräkningsnoder. Användaren i dina GCP-noder måste ha sudo- eller superadmin-behörigheter. Det måste också ställas in med en lösenordsfri SSH-åtkomst. Läs vår dokumentation mer om systemanvändaren och dess nödvändiga rättigheter.
Låt oss ha en exempellista på servrar nedan (från GCP-konsolen:Compute Engine-instrumentpanelen):
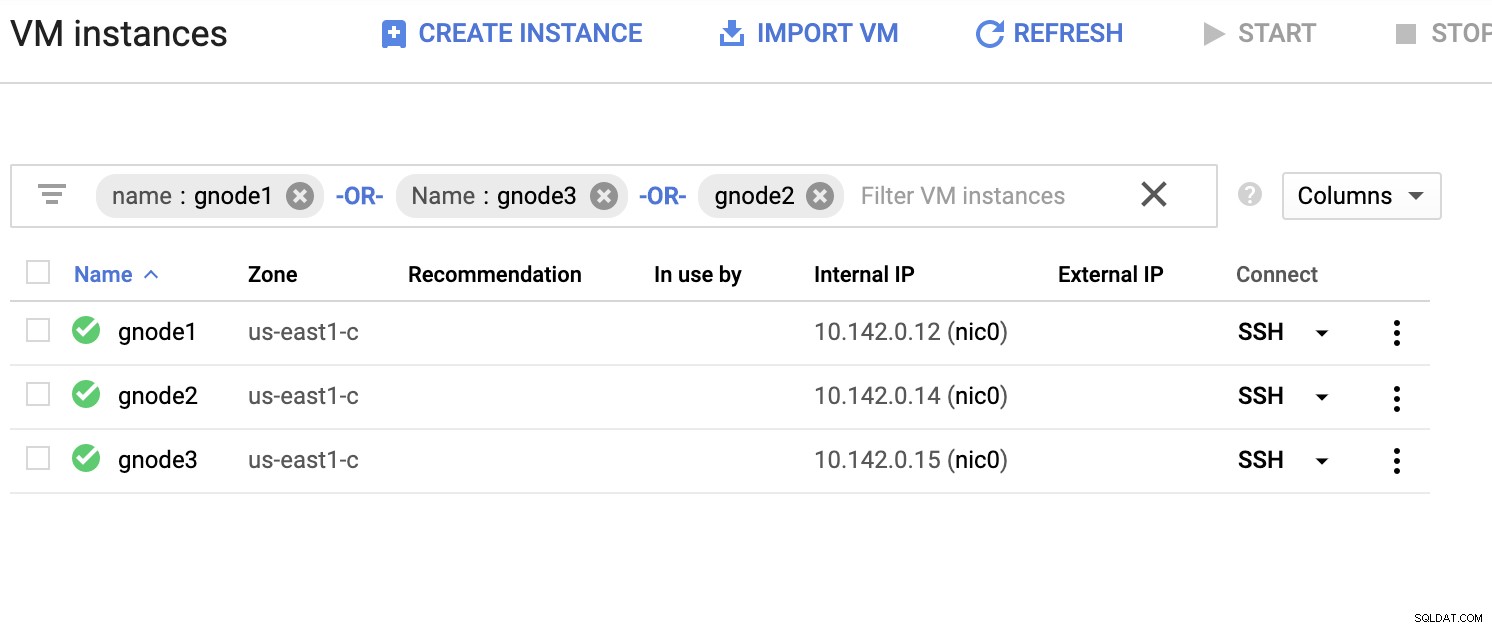
I skärmdumpen ovan är vår målregion baserad på USA-öst område. Som nämnts tidigare är mitt lokala nätverk konfigurerat över ett säkert lager som går genom GCP (vice versa) med OpenVPN. Så kommunikation från GCP som går till mitt lokala nätverk är också inkapslad över VPN-tunneln.
Lägg till en slavnod till GCP
Skärmdumpen nedan visar hur du kan göra detta. Se bilderna nedan:
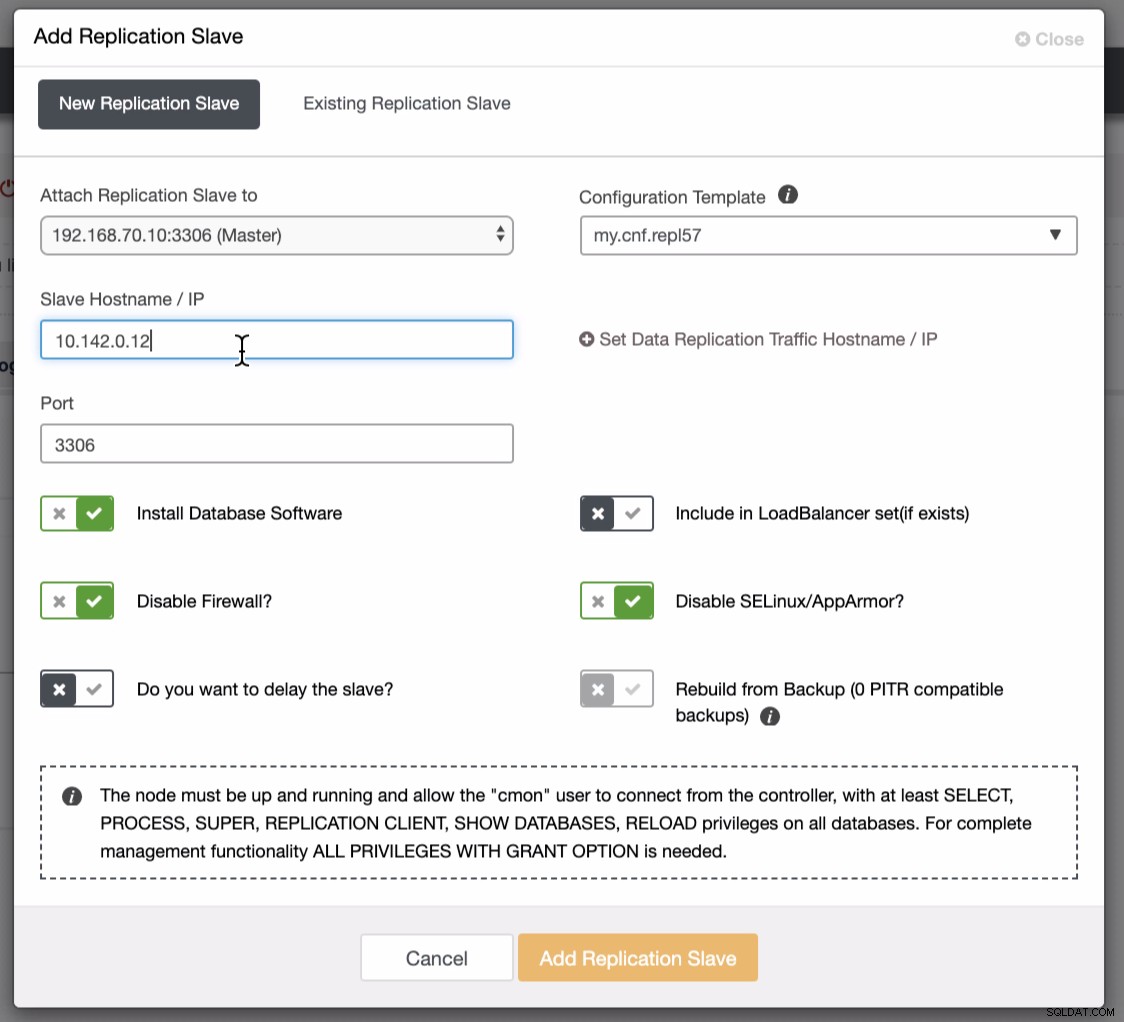
Som framgår av den andra skärmdumpen riktar vi oss mot nod 10.142.0.12 och dess källmästare är 192.168.70.10. ClusterControl är smart nog att avgöra brandväggar, säkerhetsmoduler, paket, konfiguration och inställningar som behöver göras. Se nedan ett exempel på jobbaktivitetslogg:
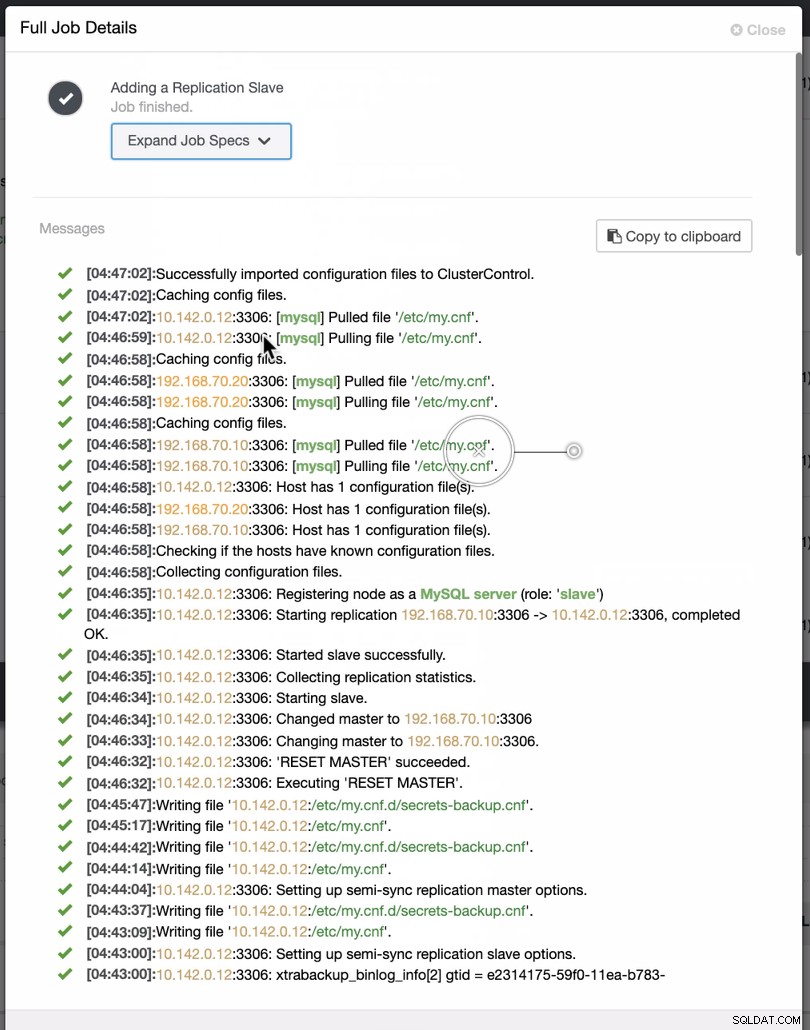
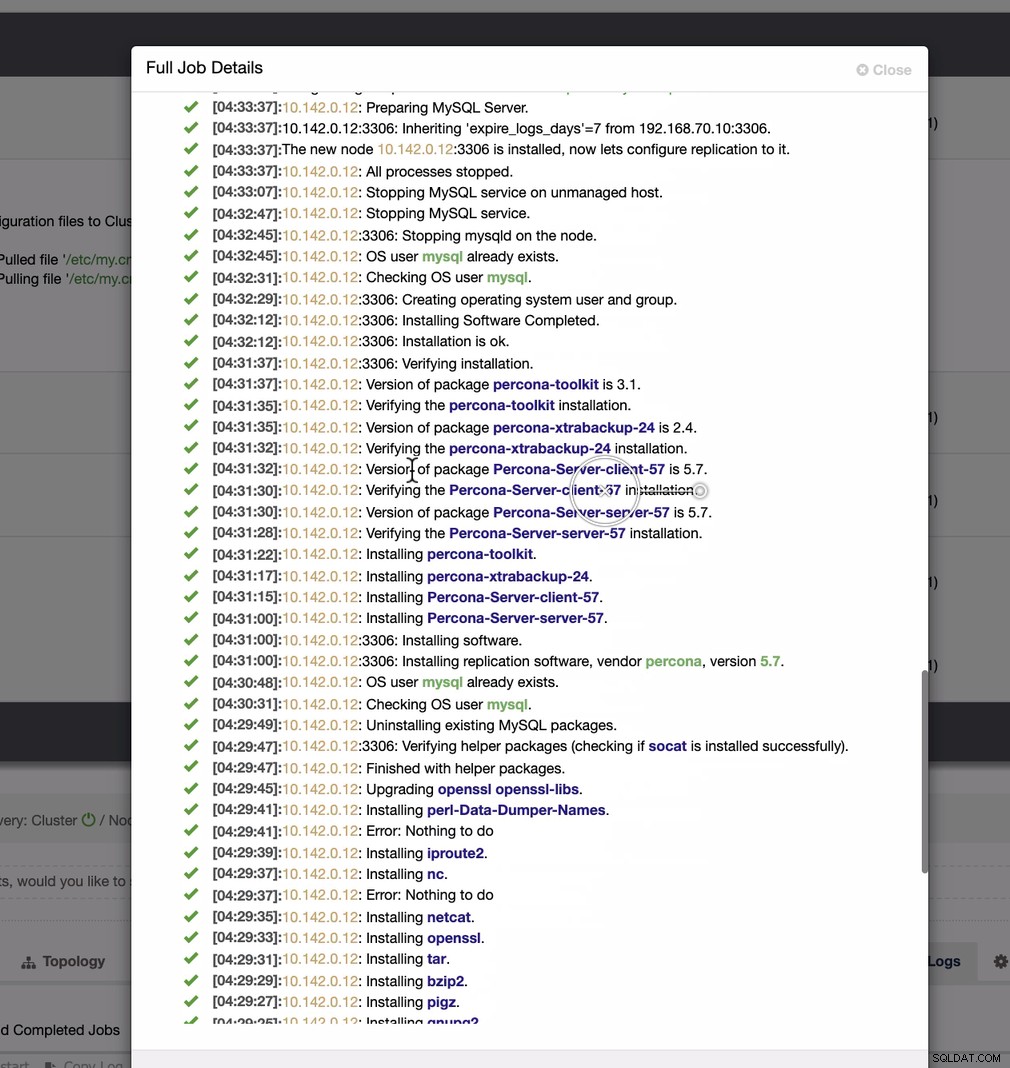
Ganska enkel uppgift, eller hur?
Slutför GCP MySQL-klustret
Vi måste lägga till ytterligare två noder till GCP-klustret för att ha en balanstopologi som vi hade i det lokala nätverket. För den andra och tredje noden, se till att mastern måste peka på din GCP-nod. I det här exemplet är mastern 10.142.0.12. Se nedan hur du gör detta,
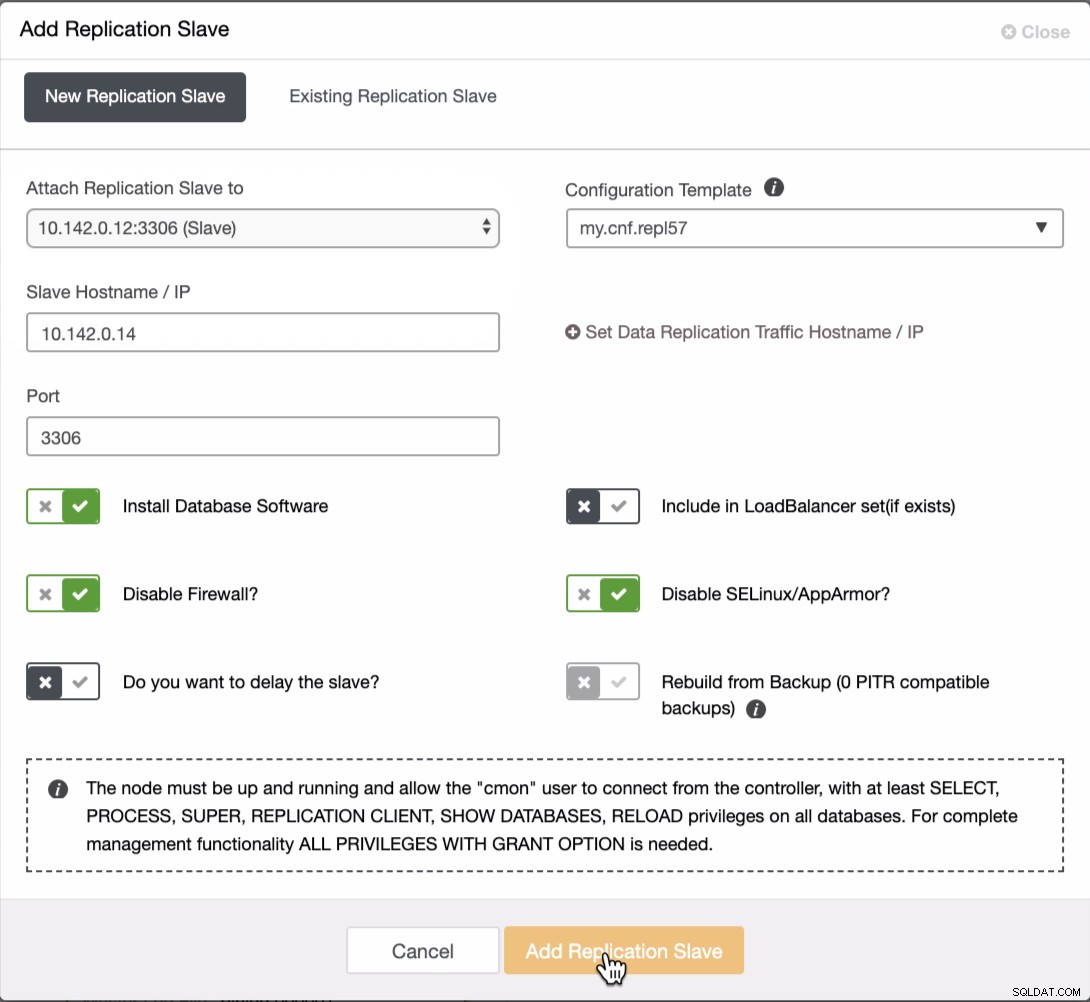
Som framgår av skärmdumpen ovan valde jag 10.142.0.12 (slav) ) vilket är den första noden vi har lagt till i klustret. Det fullständiga resultatet ser ut som följer,
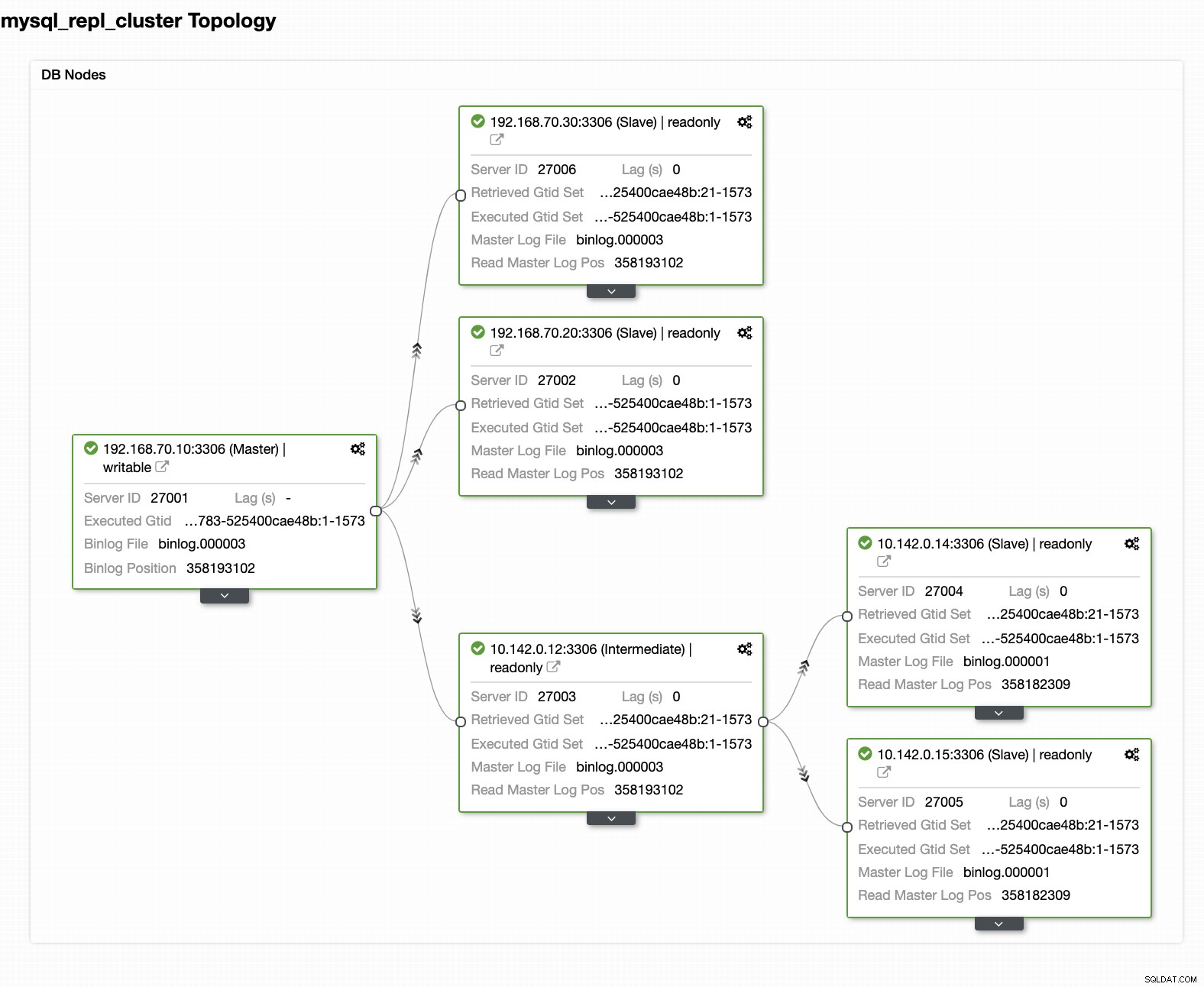
Din slutliga installation av Geo-Location Database Cluster
Från den senaste skärmdumpen kanske den här typen av topologi inte är din idealiska inställning. För det mesta måste det vara en multi-master-inställning, där ditt DR-kluster fungerar som standby-kluster, medan ditt on-prem fungerar som det primära aktiva klustret. För att göra detta är det ganska enkelt i ClusterControl. Se följande skärmdumpar för att uppnå detta mål.
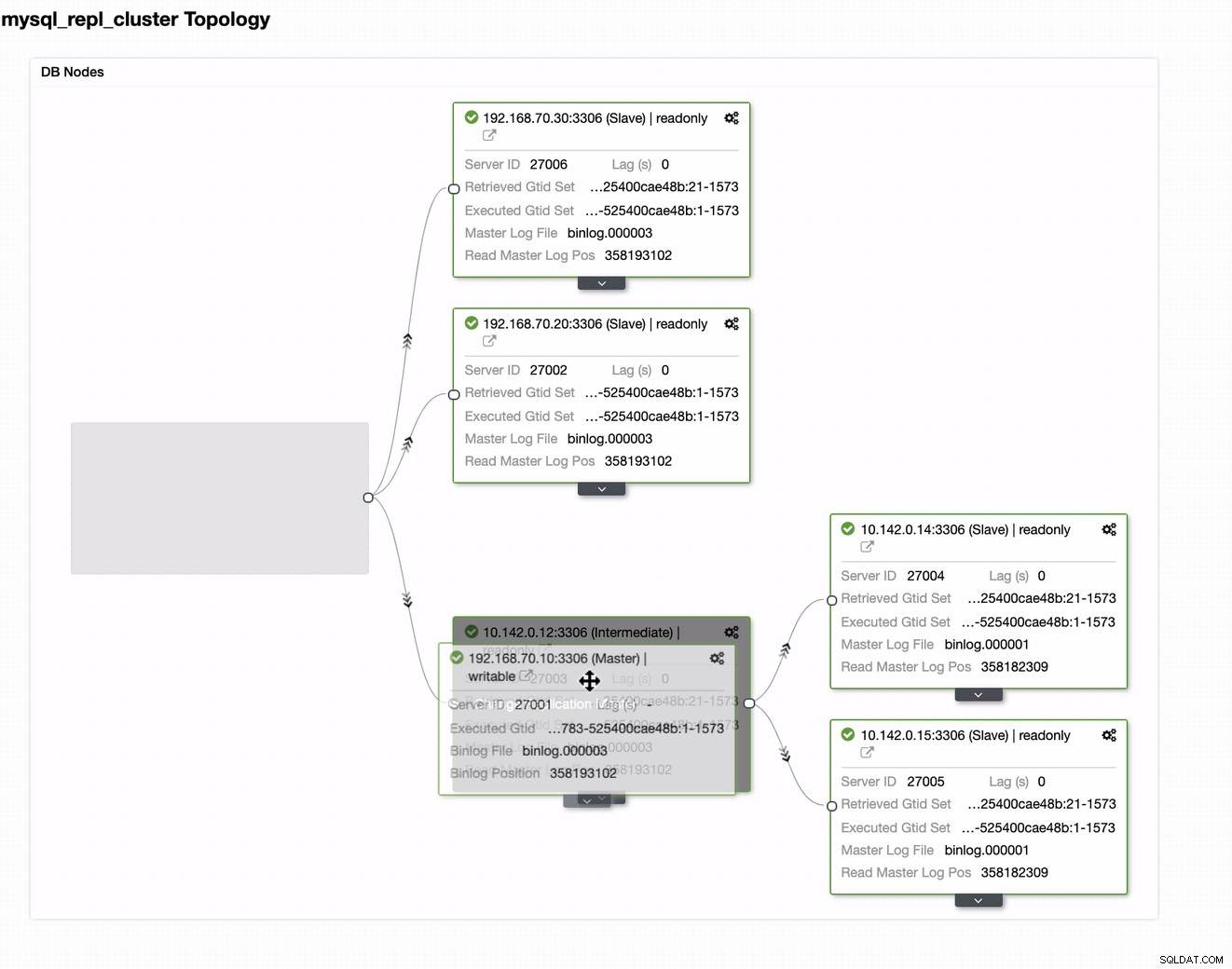
Du kan bara dra din nuvarande master till målmastern som måste vara ställ in som en primär standby-skribent utifall att din på plats skulle komma till skada. I det här exemplet drar vi inriktningsvärd 10.142.0.12 (GCP-beräkningsnod). Slutresultatet visas nedan:
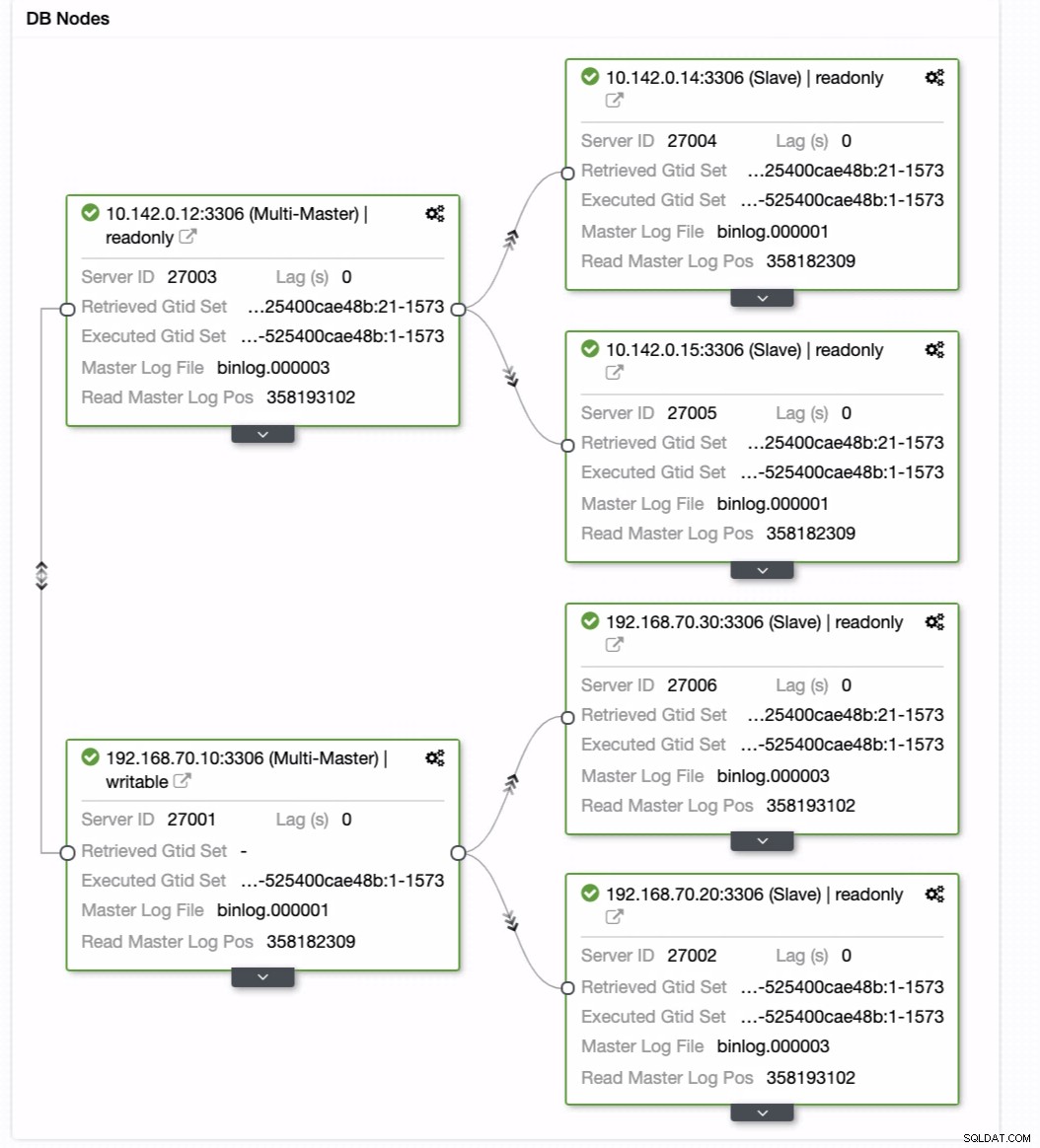
Då uppnår den önskat resultat. Enkelt och mycket snabbt att skapa ditt Geo-Location Database-kluster med MySQL-replikering.
Slutsats
Att ha ett Geo-Location Database Cluster är inte nytt. Det har varit ett önskat upplägg för företag och organisationer som undviker SPOF som vill ha motståndskraft och lägre RPO.
De viktigaste fördelarna med den här installationen är säkerhet, redundans och motståndskraft. Den täcker också hur genomförbart och effektivt du kan distribuera ditt nya kluster till en annan geografisk region. Även om ClusterControl kan erbjuda detta, förvänta dig att vi kan få fler förbättringar av detta tidigare där du kan skapa effektivt från en säkerhetskopia och skapa ditt nya annorlunda kluster i ClusterControl, så håll utkik.