Vi har nyligen skrivit flera bloggar om hur olika molnleverantörer hanterar databasfel. Vi jämförde failover-prestanda i Amazon Aurora, Amazon RDS och ClusterControl, testade failover-beteendet i Amazon RDS och även på Google Cloud Platform. Även om dessa tjänster erbjuder fantastiska alternativ när det kommer till failover, kanske de inte är rätt för alla applikationer.
I det här blogginlägget kommer vi att ägna lite tid åt att analysera för- och nackdelarna med att använda DBaaS-lösningarna jämfört med att designa en miljö manuellt eller genom att använda en databashanteringsplattform, som ClusterControl.
Implementera databaser med hög tillgänglighet med hanterade lösningar
Den främsta anledningen till att använda befintliga lösningar är användarvänligheten. Du kan distribuera en högst tillgänglig lösning med automatiserad failover med bara ett par klick. Det finns inget behov av att kombinera olika verktyg, hantera databaserna för hand, distribuera verktyg, skriva skript, designa övervakningen eller andra databashanteringsoperationer. Allt är redan på plats. Detta kan avsevärt minska inlärningskurvan och kräver mindre erfarenhet för att skapa en mycket tillgänglig miljö för databaserna; tillåter i princip alla att distribuera sådana inställningar.
I de flesta fall med dessa lösningar exekveras failover-processen inom rimlig tid. Det kan vara blixtsnabbt som med Amazon Aurora eller något långsammare som med Google Cloud Platform SQL-noder. För de flesta fall är dessa typer av resultat acceptabla.
Slutet. Om du kan acceptera 30 - 60 sekunders driftstopp borde du klara dig med någon av DBaaS-plattformarna.
Nackdelen med att använda en hanterad lösning för HA
Även om DBaaS-lösningar är enkla att använda, har de också några allvarliga nackdelar. Till att börja med finns det alltid en leverantörslåsningskomponent att överväga. När du väl distribuerar ett kluster i Amazon Web Services är det ganska svårt att migrera ut från den leverantören. Det finns inga enkla metoder för att ladda ner hela datasetet genom en fysisk säkerhetskopia. Hos de flesta leverantörer är endast manuellt körda logiska säkerhetskopior tillgängliga. Visst, det finns alltid alternativ för att uppnå detta, men det är vanligtvis en komplex, tidskrävande process, som trots allt ändå kan kräva lite stillestånd.
Att använda en leverantör som Amazon RDS kommer också med begränsningar. Vissa åtgärder är inte lätta att utföra, vilket skulle vara mycket enkelt att utföra i miljöer som distribueras på ett helt användarkontrollerat sätt (t.ex. AWS EC2). Några av dessa begränsningar har redan behandlats i andra bloggar, men för att sammanfatta är att ingen DBaaS-tjänst ger dig samma nivå av flexibilitet som vanlig MySQL GTID-baserad replikering. Du kan marknadsföra vilken slav som helst, du kan återslava varje nod från vilken annan som helst... praktiskt taget alla åtgärder är möjliga. Med verktyg som RDS möter du designinducerade begränsningar som du inte kan kringgå.
Problemet är också med förmågan att förstå prestandadetaljer. När du designar din egen högtillgängliga installation blir du kunnig om potentiella prestandaproblem som kan dyka upp. Å andra sidan är RDS och liknande miljöer i stort sett "svarta lådor". Ja, vi har lärt oss att Amazon RDS använder DRBD för att skapa en skuggkopia av mastern, vi vet att Aurora använder delad, replikerad lagring för att implementera mycket snabba failovers. Det är bara en allmän kunskap. Vi kan inte säga vilka prestandakonsekvenserna av dessa lösningar är, annat än vad vi kan lägga märke till. Vilka är vanliga problem förknippade med dem? Hur stabila är dessa lösningar? Det är bara utvecklarna bakom lösningen som vet säkert.
Vad är alternativet till DBaaS-lösningar?
Du kanske undrar om det finns något alternativ till DBaaS? Det är trots allt så bekvämt att köra den hanterade tjänsten där du kan komma åt de flesta typiska åtgärder via UI. Du kan skapa och återställa säkerhetskopior, failover hanteras automatiskt åt dig. Miljön är lätt att använda vilket kan vara övertygande för företag som inte har engagerad och erfaren personal för att hantera databaser.
ClusterControl erbjuder ett utmärkt alternativ till molnbaserade DBaaS-tjänster. Det ger dig ett grafiskt användargränssnitt som kan användas för att distribuera, hantera och övervaka databaser med öppen källkod.
Med ett par klick kan du enkelt distribuera ett mycket tillgängligt databaskluster, med automatiserad failover (snabbare än de flesta DBaaS-erbjudanden), säkerhetskopieringshantering, avancerad övervakning och andra funktioner som integration med externa verktyg (t.ex. Slack eller PagerDuty) eller uppgraderingshantering. Allt detta samtidigt som man helt undviker leverantörslåsning.
ClusterControl bryr sig inte om var dina databaser finns så länge den kan ansluta till dem med SSH. Du kan ha inställningar i moln, on-prem eller i en blandad miljö av flera molnleverantörer. Så länge anslutningen finns där kommer ClusterControl att kunna hantera miljön. Genom att använda de lösningar du vill ha (och inte de som du inte är bekant eller medveten om) kan du ta full kontroll över miljön när som helst.
Vad du än har installerat med ClusterControl kan du enkelt hantera det på ett mer traditionellt, manuellt eller skriptat sätt. ClusterControl ger dig till och med kommandoradsgränssnitt, som låter dig infoga uppgifter som utförs av ClusterControl i dina skalskript. Du har all kontroll du vill ha - ingenting är en svart låda, varje del av miljön skulle byggas med öppen källkodslösningar kombinerade och distribuerade av ClusterControl.
Låt oss ta en titt på hur enkelt du kan distribuera ett MySQL-replikeringskluster med ClusterControl. Låt oss anta att du har förberett miljön med ClusterControl installerad på en instans och alla andra noder tillgängliga via SSH från ClusterControl-värden.
Vi börjar med att välja “Deploy”-guiden.
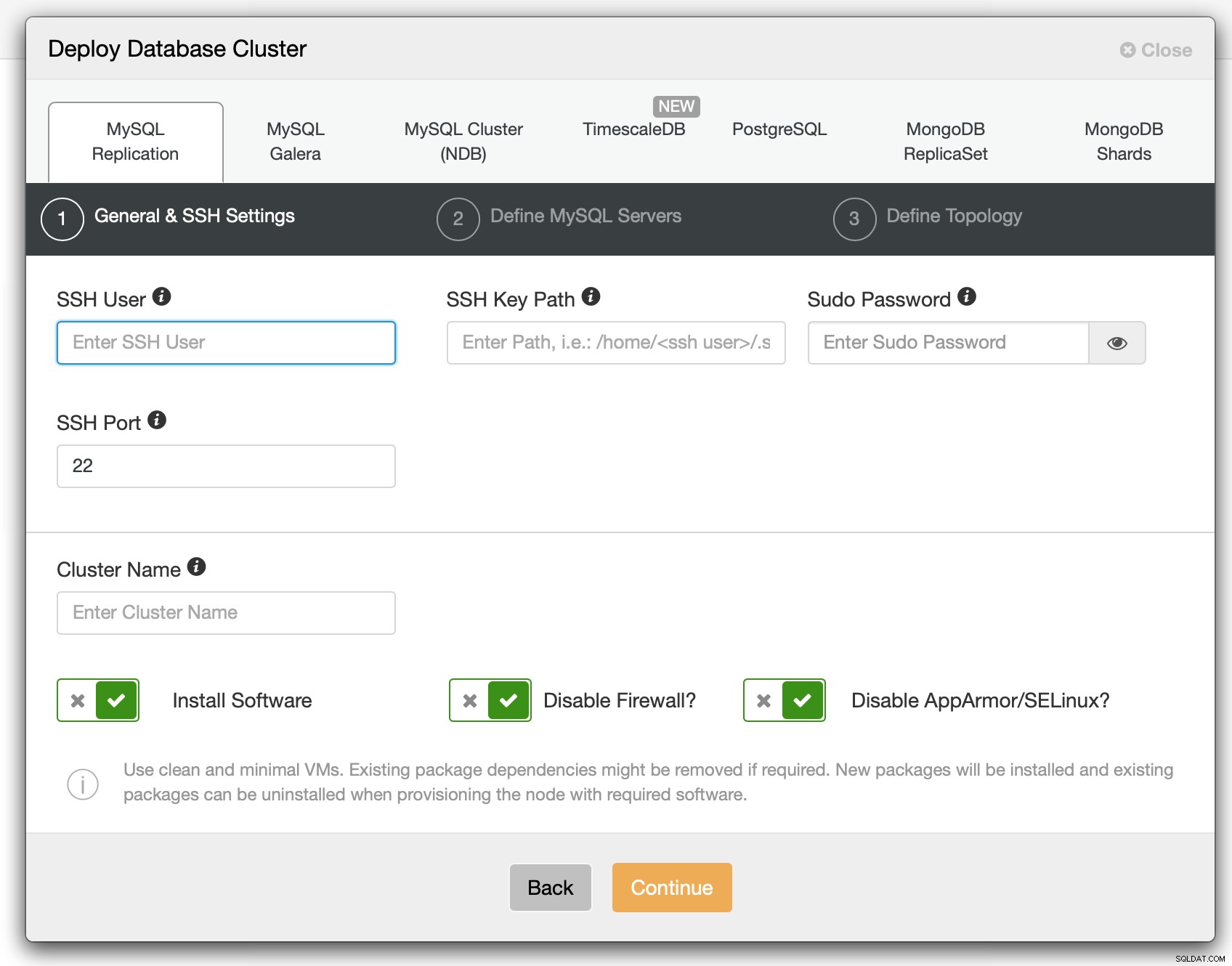
I det första steget måste vi definiera hur ClusterControl ska ansluta till noderna på vilka databaser som ska distribueras. Både root-åtkomst eller sudo (med eller utan lösenord) stöds.
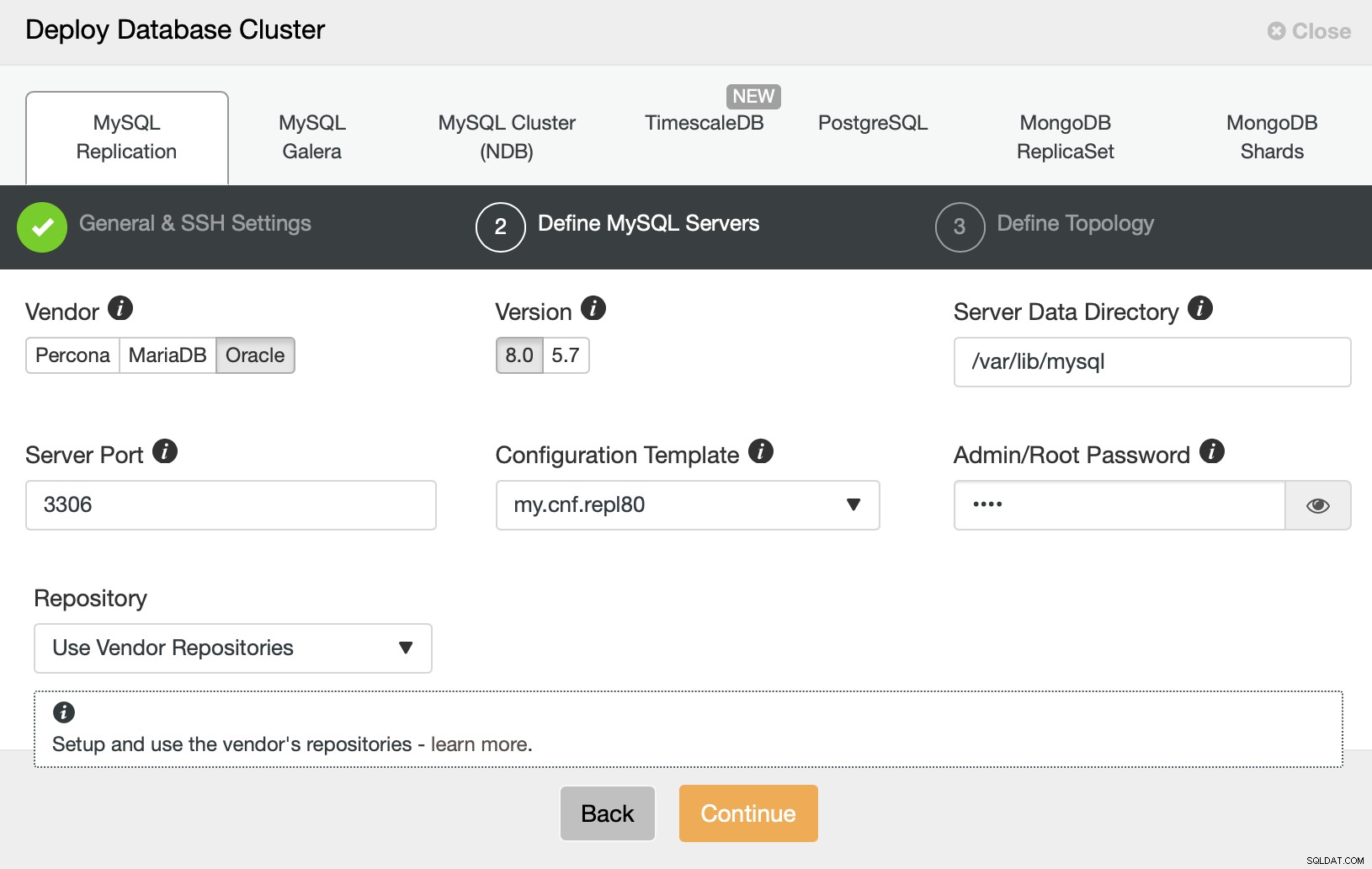
Då vill vi välja en leverantör, version och skicka lösenordet för den administrativa användaren i vår MySQL-databas.
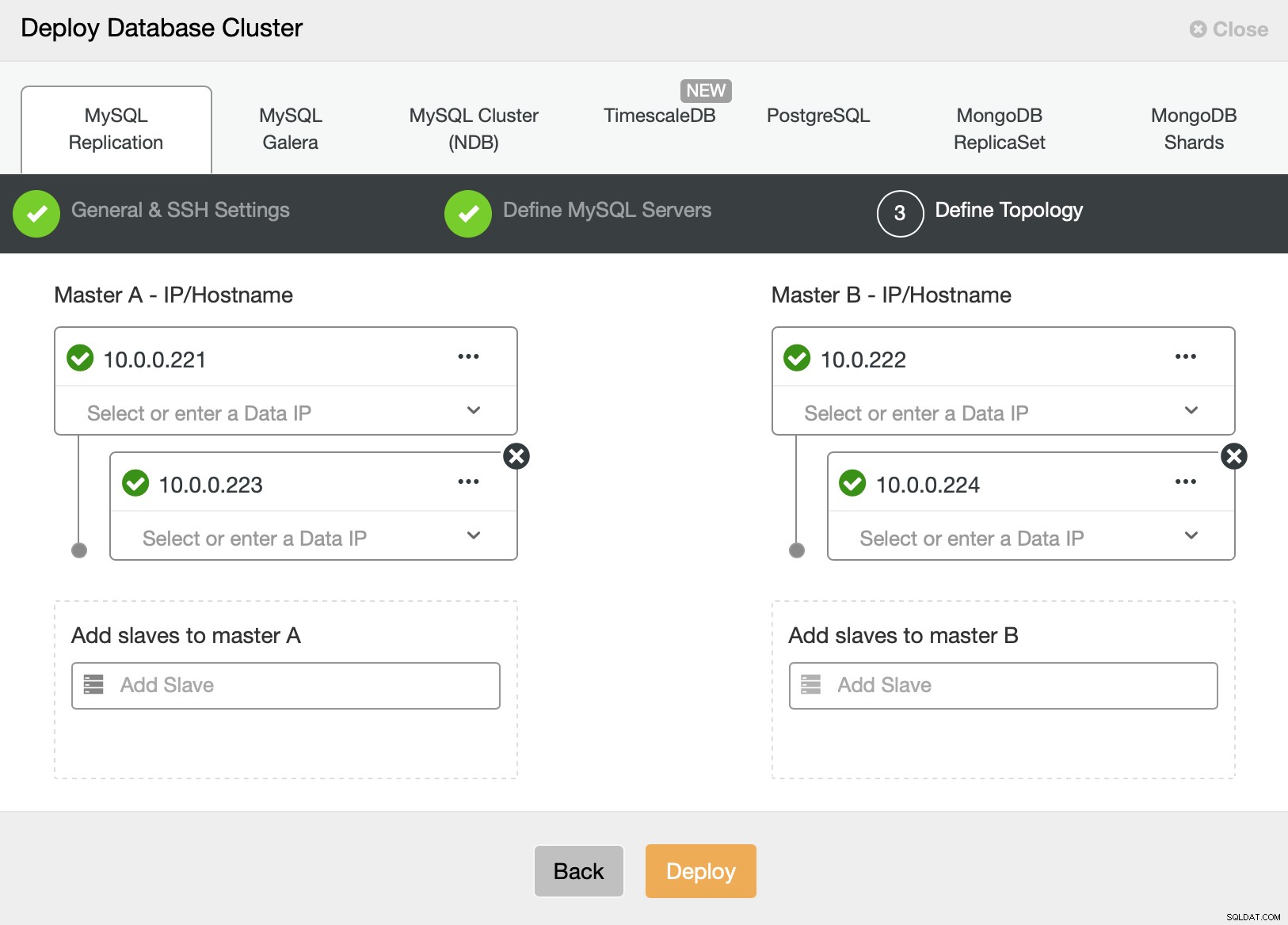
Slutligen vill vi definiera topologin för vårt nya kluster. Som du kan se är detta redan en ganska komplicerad installation, till skillnad från något du kan distribuera med AWS RDS eller GCP SQL-nod.
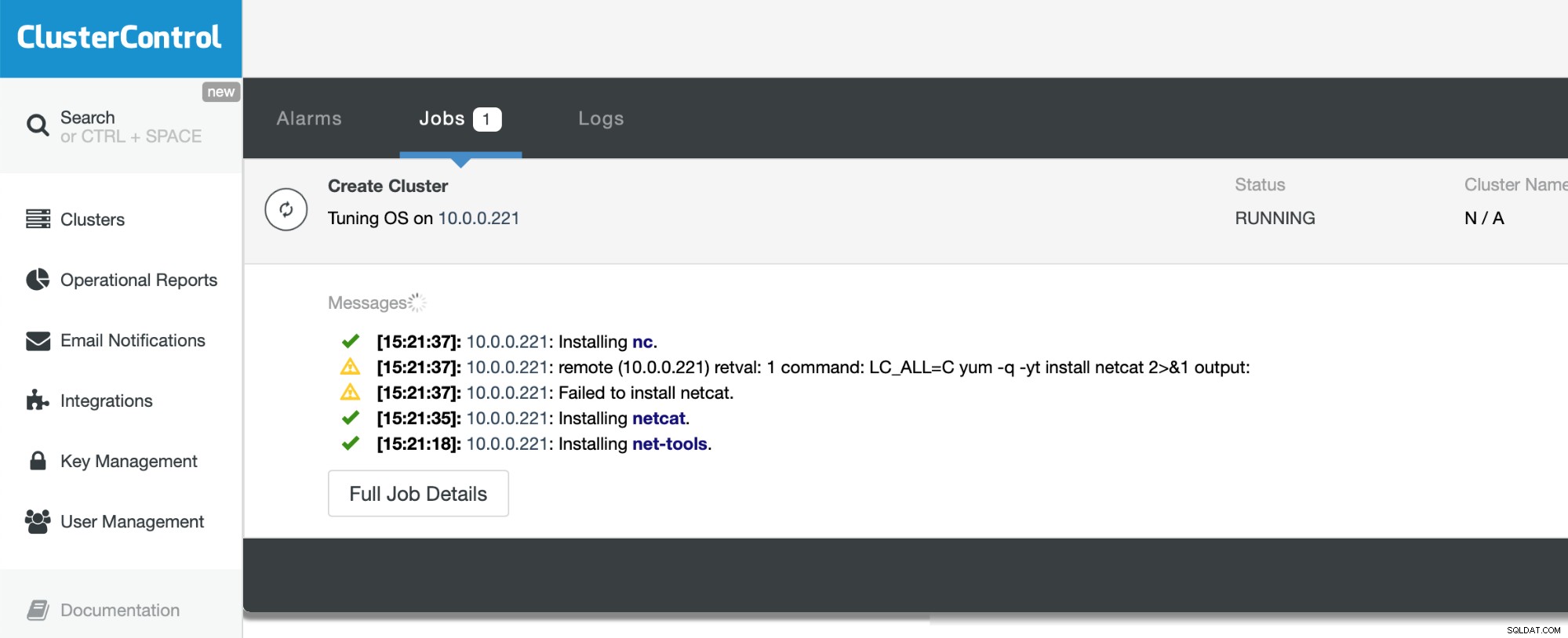
Allt vi behöver göra nu är att vänta på att processen ska slutföras. ClusterControl kommer att göra sitt bästa för att förstå miljön den distribuerar till och installera nödvändig uppsättning paket, inklusive själva databasen.

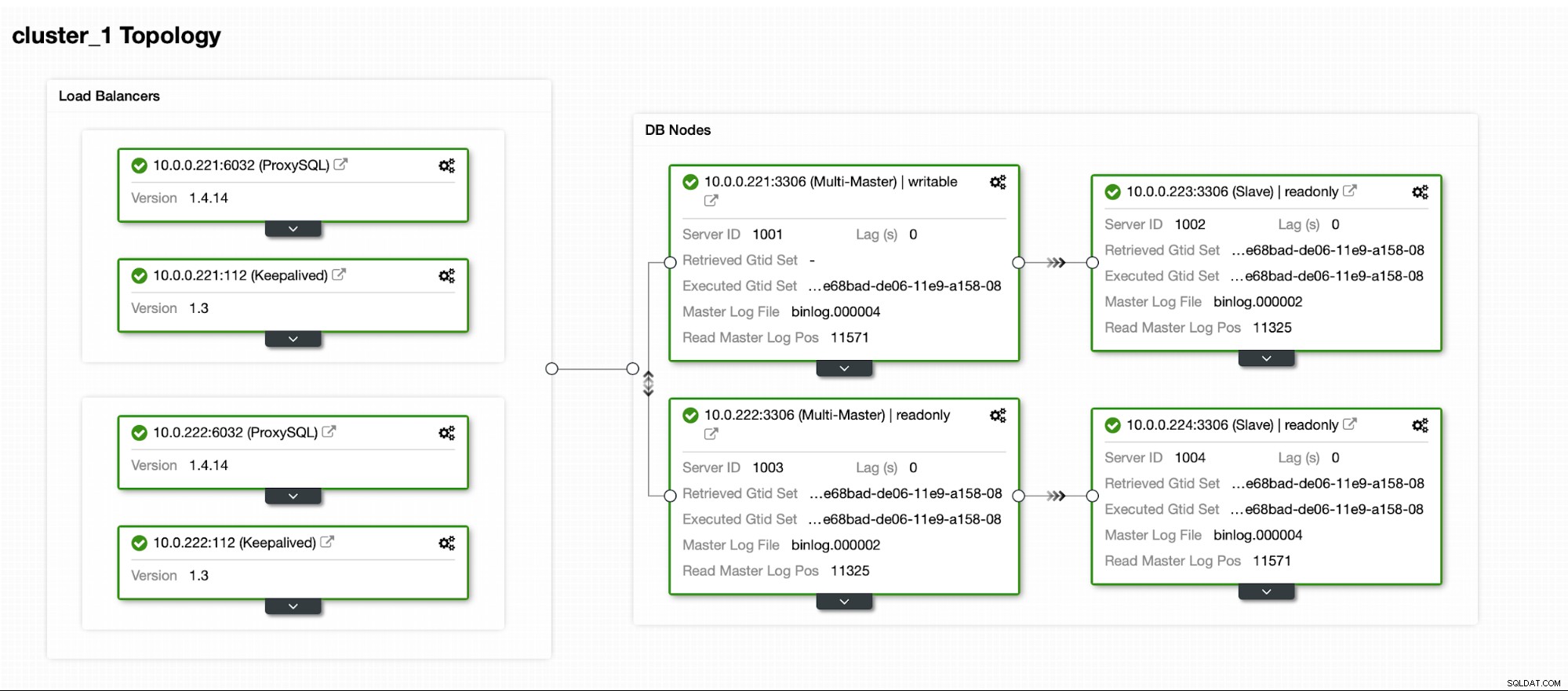
När klustret väl är igång kan du fortsätta med distributionen proxylagret (som ger din applikation en enda ingångspunkt till databaslagret). Det är mer eller mindre vad som händer bakom kulisserna med DBaaS, där man även har endpoints för att koppla till databasklustret. Det är ganska vanligt att använda en enda slutpunkt för att skriva och flera slutpunkter för att nå specifika repliker.
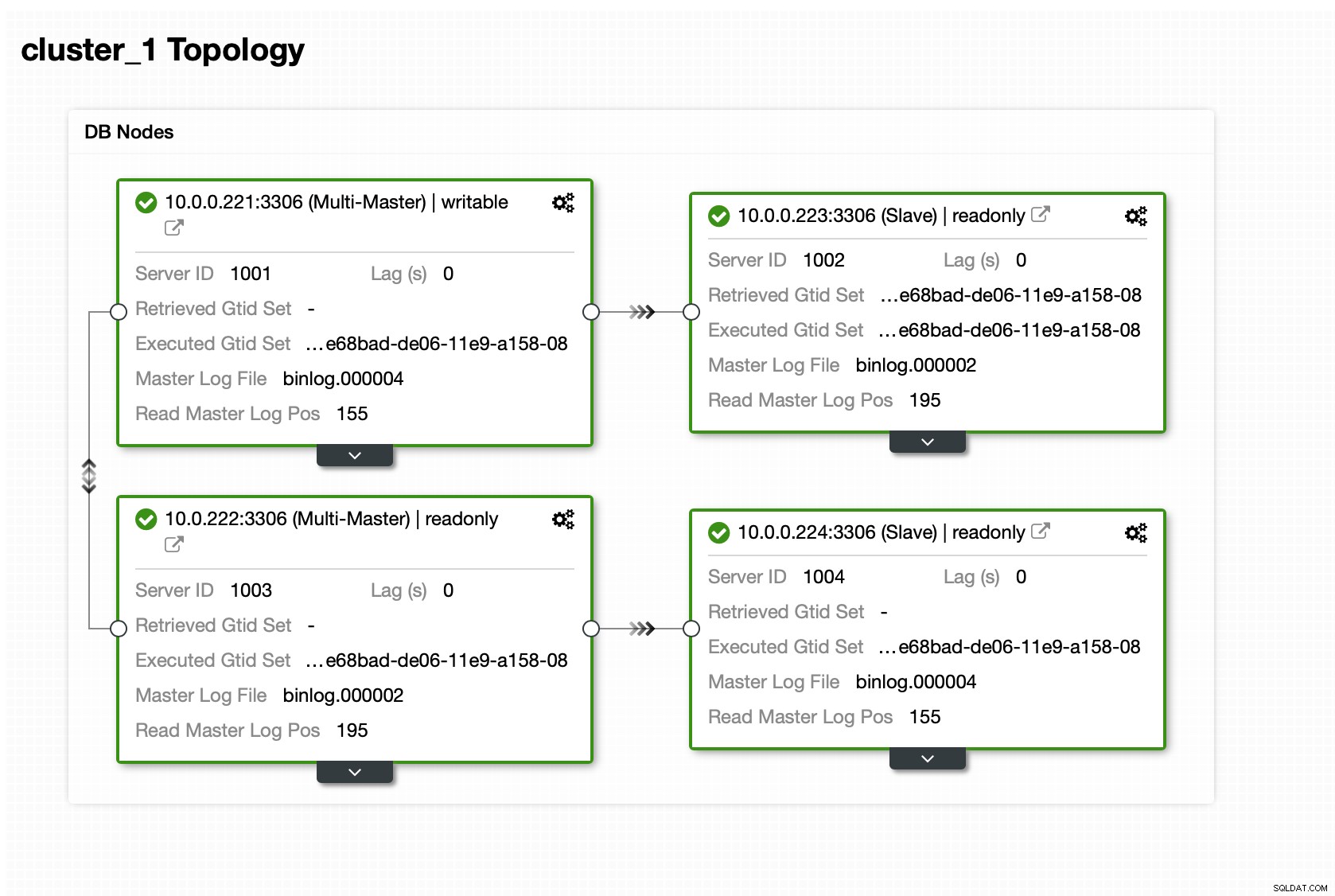
Här kommer vi att använda ProxySQL, som kommer att göra det smutsiga arbetet åt oss - den kommer att förstå topologin, skickar bara skrivningar till mastern och skrivskyddade frågor för lastbalans över alla repliker som vi har.
För att distribuera ProxySQL går vi till Hantera -> Lastbalanserare.
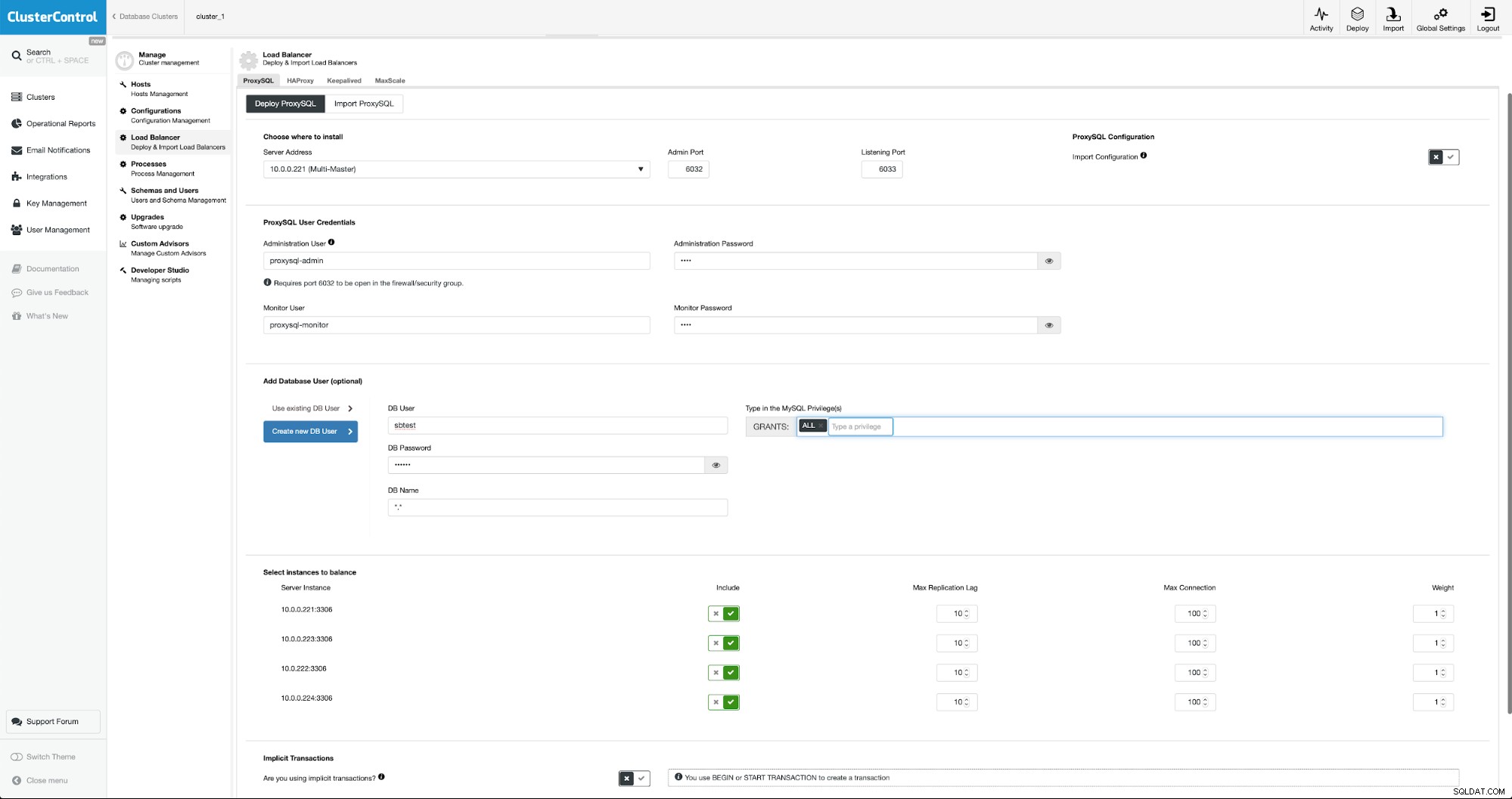
Vi måste fylla i alla obligatoriska fält:värdar att distribuera på, autentiseringsuppgifter för den administrativa och övervakande användaren kan vi importera befintlig användare från MySQL till ProxySQL eller skapa en ny. All information om ProxySQL kan lätt hittas i flera bloggar i vår bloggsektion.
Vi vill att minst två ProxySQL-noder ska distribueras för att säkerställa hög tillgänglighet. Sedan, när de väl har distribuerats, kommer vi att distribuera Keepalved ovanpå ProxySQL. Detta säkerställer att virtuell IP kommer att konfigureras och pekar på en av ProxySQL-instanserna, så länge det finns minst en frisk nod.
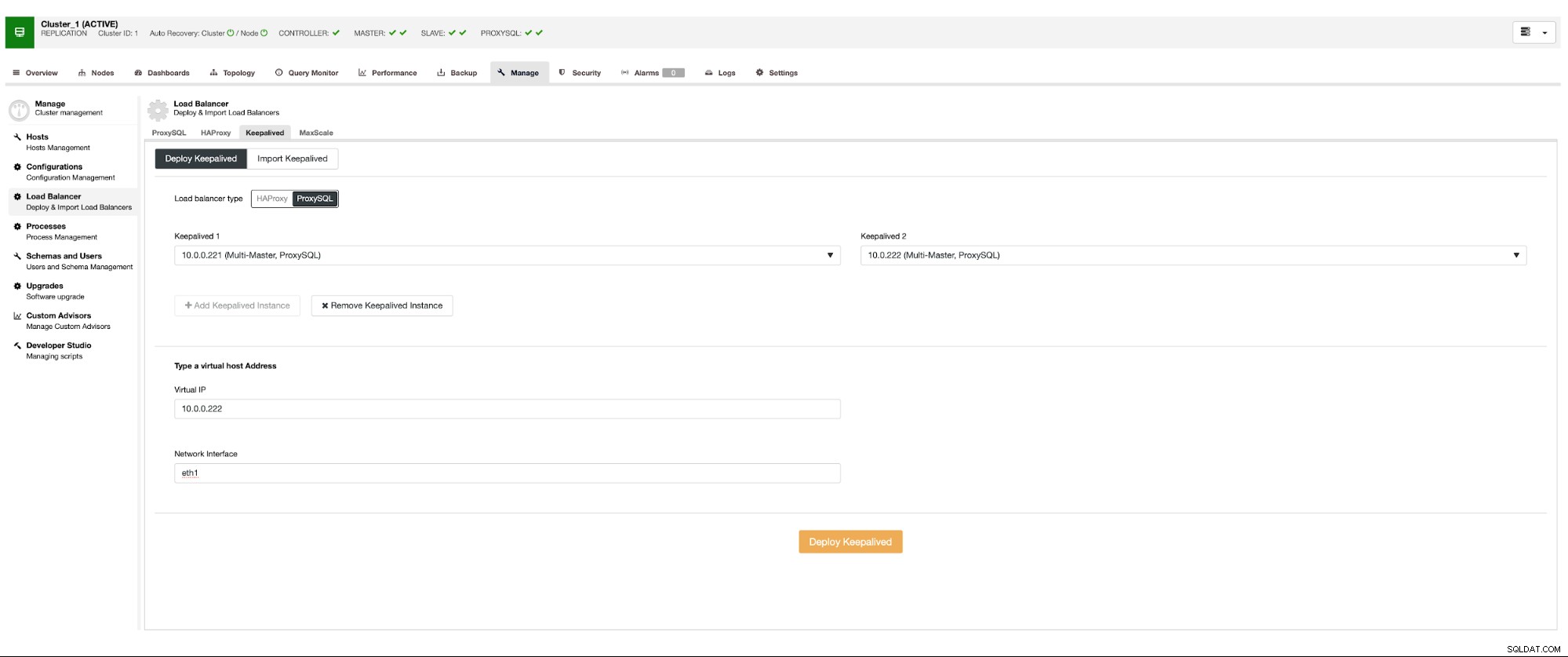
Här är det enda potentiella problemet om du använder molnmiljöer där routing fungerar på ett sätt som du inte enkelt kan få upp ett nätverksgränssnitt. I sådana fall måste du ändra konfigurationen av Keepalived, introducera 'notify_master'-skriptet och använda ett skript, som kommer att göra de nödvändiga IP-ändringarna - i fallet med EC2 skulle det behöva koppla bort Elastic IP från en värd och koppla den till annan värd.
Det finns massor av instruktioner om hur man gör det med brett testad programvara med öppen källkod i inställningar som distribueras av ClusterControl. Du kan enkelt hitta ytterligare information, tips och instruktioner som är relevanta för just din miljö.
Slutsats
Vi hoppas att du tyckte att det här blogginlägget var insiktsfullt. Om du vill testa ClusterControl kommer det med en 30 dagars företagstestperiod där du har alla funktioner tillgängliga. Du kan ladda ner den gratis och testa om den passar i din miljö.