Varför välja MySQL-replikering?
Några grunder först om replikeringstekniken. MySQL-replikering är inte komplicerat! Det är lätt att implementera, övervaka och ställa in eftersom det finns olika resurser du kan utnyttja - google är en. MySQL-replikering innehåller inte många konfigurationsvariabler att ställa in. SQL_THREAD och IO_THREADs logiska fel är inte så svåra att förstå och fixa. MySQL-replikering är mycket populär nuförtiden och erbjuder ett enkelt sätt att implementera databasen High Availability. Kraftfulla funktioner som GTID (Global Transaction Identifier) istället för den gammaldags binära loggpositionen eller förlustfri semisynkron replikering gör den mer robust.
Som vi såg i ett tidigare inlägg är nätverkslatens en stor utmaning när man väljer en lösning med hög tillgänglighet. Att använda MySQL-replikering ger fördelen att inte vara lika känslig för latens. Den implementerar ingen certifieringsbaserad replikering, till skillnad från Galera Cluster använder gruppkommunikation och transaktionsbeställningstekniker för att uppnå synkron replikering. Den har alltså inget krav på att alla noder måste certifiera en skrivuppsättning, och inget behov av att vänta innan en commit på den andra slaven eller repliken.
Att välja den traditionella MySQL-replikeringen med asynkront primär-sekundärt tillvägagångssätt ger dig snabbhet när det gäller att hantera transaktioner inifrån din master; den behöver inte vänta på att slavarna ska synkronisera eller utföra transaktioner. Installationen har vanligtvis en primär (master) och en eller flera sekundärer (slavar). Därför är det ett delat-ingenting-system, där alla servrar har en fullständig kopia av data som standard. Naturligtvis finns det nackdelar. Dataintegritet kan vara ett problem om dina slavar inte lyckades replikera på grund av SQL- och I/O-trådsfel eller kraschar. Alternativt, för att lösa problem med dataintegritet, kan du välja att implementera MySQL-replikering som halvsynkron (eller kallad förlustfri semisynkroniserad replikering i MySQL 5.7). Hur detta fungerar är att mastern måste vänta tills en replik bekräftar alla händelser i transaktionen. Detta innebär att den måste avsluta sina skrivningar till en relälogg och spola till disken innan den skickar tillbaka till mastern med ett ACK-svar. Med semi-synkron replikering aktiverad måste trådar eller sessioner i mastern vänta på bekräftelse från en replik. När den väl får ett ACK-svar från repliken kan den utföra transaktionen. Illustrationen nedan visar hur MySQL hanterar semi-synkron replikering.
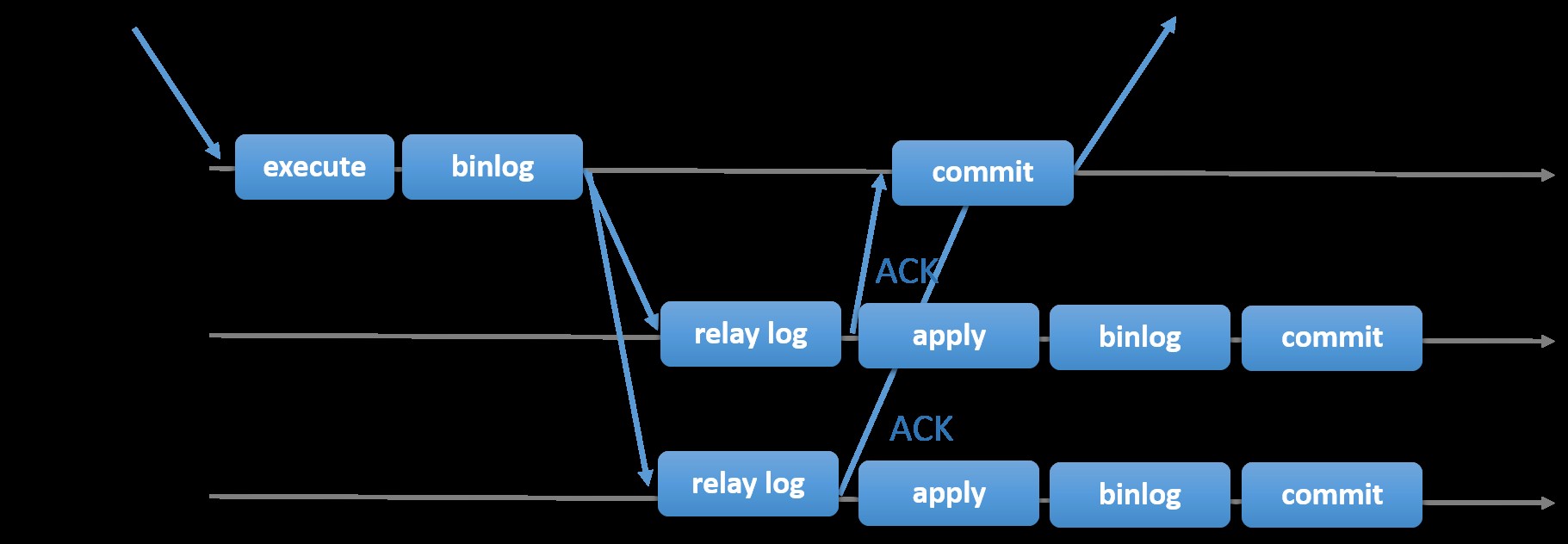 Bild med tillstånd av MySQL-dokumentation
Bild med tillstånd av MySQL-dokumentation Med den här implementeringen replikeras alla genomförda transaktioner redan till minst en slav i händelse av en masterkrasch. Även om semi-synkron inte i sig representerar en hög tillgänglighetslösning, men det är en komponent för din lösning. Det är bäst att du känner till dina behov och justerar din semi-sync-implementering därefter. Därför, om viss dataförlust är acceptabel, kan du istället använda den traditionella asynkrona replikeringen.
GTID-baserad replikering är till hjälp för DBA eftersom det förenklar uppgiften att göra en failover, speciellt när en slav pekas på en annan master eller ny master. Detta betyder att med en enkel MASTER_AUTO_POSITION=1 efter att ha ställt in rätt värd- och replikeringsuppgifter, kommer den att börja replikera från mastern utan att behöva hitta och specificera de korrekta binära logg-x &y-positionerna. Att lägga till stöd för parallell replikering ökar också replikeringstrådarna eftersom det ökar hastigheten för att bearbeta händelserna från reläloggen.
Därför är MySQL-replikering en utmärkt valkomponent framför andra HA-lösningar om den passar dina behov.
Topologier för MySQL-replikering
Att implementera MySQL-replikering i en multimolnmiljö med GCP (Google Cloud Platform) och AWS är fortfarande samma metod om du måste replikera lokalt.
Det finns olika topologier du kan ställa in och implementera.
Master med slavreplikering (enkel replikering)
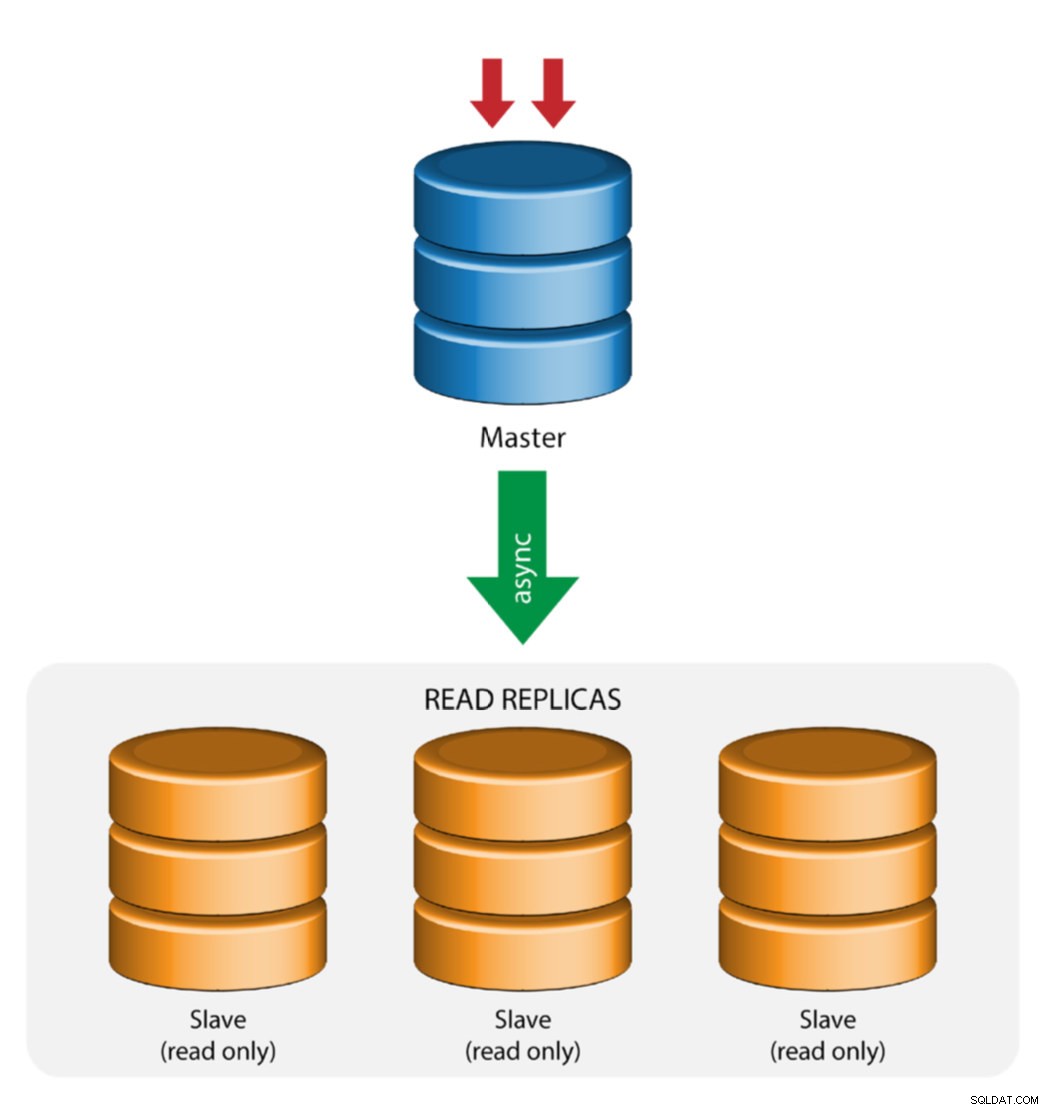
Detta är den mest enkla MySQL-replikeringstopologin. En master tar emot skrivningar, en eller flera slavar replikerar från samma master via asynkron eller semisynkron replikering. Om den utsedda mastern går ner måste den mest uppdaterade slaven befordras till ny master. De återstående slavarna återupptar replikeringen från den nya mastern.
Master med reläslavar (kedjereplikering)
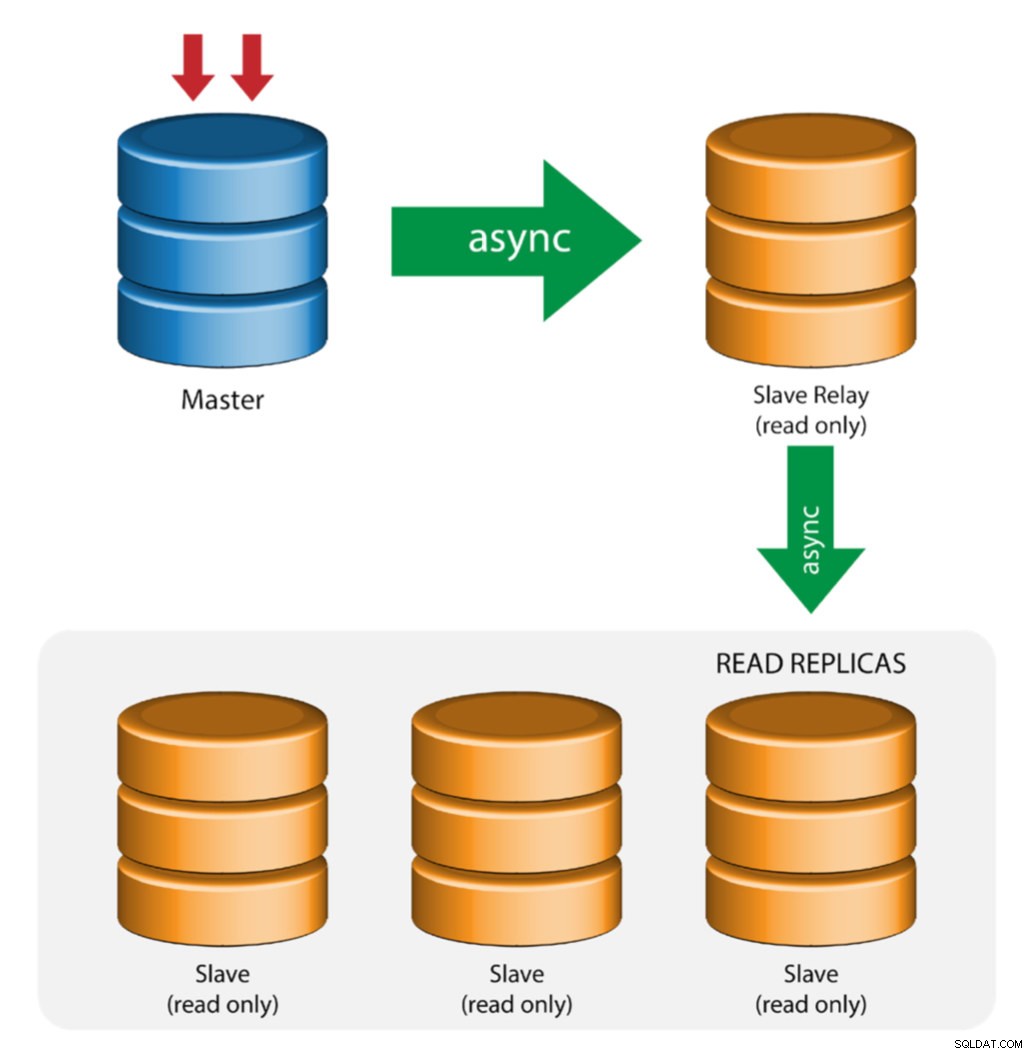
Denna inställning använder en mellanliggande master för att fungera som ett relä till de andra slavarna i replikeringskedjan. När det finns många slavar anslutna till en master kan masterns nätverksgränssnitt bli överbelastat. Denna topologi tillåter läsreplikerna att dra replikeringsströmmen från reläservern för att avlasta masterservern. På slavreläservern måste binär loggning och log_slave_updates vara aktiverade, varvid uppdateringar som tas emot av slavservern från masterservern loggas till slavens egen binära logg.
Att använda slavrelä har sina problem:
- log_slave_updates har en viss prestationsstraff.
- Replikeringsfördröjning på slavreläservern genererar fördröjning på alla dess slavar.
- Ofalska transaktioner på slavreläservern kommer att infektera alla dess slavar.
- Om en slavreläserver misslyckas och du inte använder GTID, slutar alla dess slavar att replikera och de måste initieras på nytt.
Master med Active Master (cirkulär replikering)
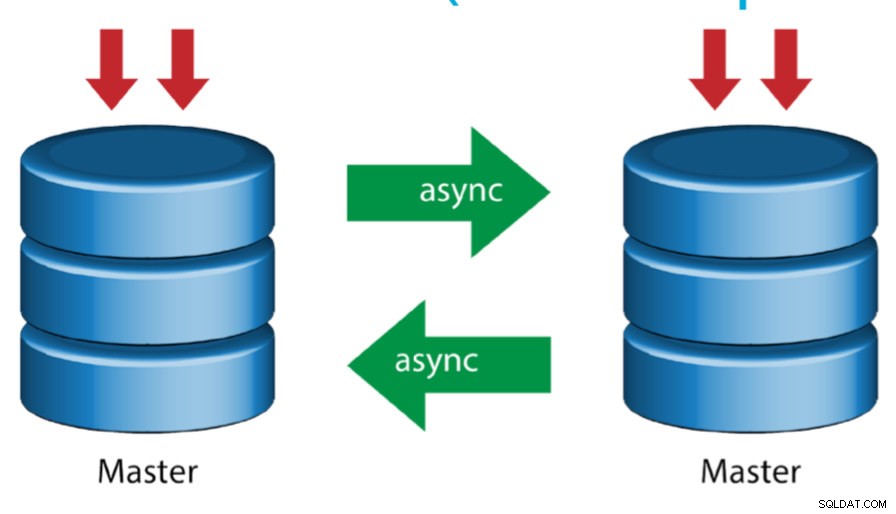
Även känd som ringtopologi, kräver denna inställning två eller flera MySQL-servrar som fungerar som master. Alla masters får skrivningar och genererar binloggar med några varningar:
- Du måste ställa in automatisk ökningsförskjutning på varje server för att undvika kollisioner med primärnyckel.
- Det finns ingen konfliktlösning.
- MySQL-replikering stöder för närvarande inte något låsningsprotokoll mellan master och slav för att garantera atomiciteten hos en distribuerad uppdatering över två olika servrar.
- Vanlig praxis är att bara skriva till en master och den andra mastern fungerar som en hot-standby-nod. Ändå, om du har slavar under den nivån, måste du byta till den nya mastern manuellt om den utsedda mastern misslyckas.
- ClusterControl stöder denna topologi (vi rekommenderar inte flera skribenter i en replikeringsinställning). Se den här tidigare bloggen om hur du distribuerar med ClusterControl.
Master med Backup Master (multipel replikering)
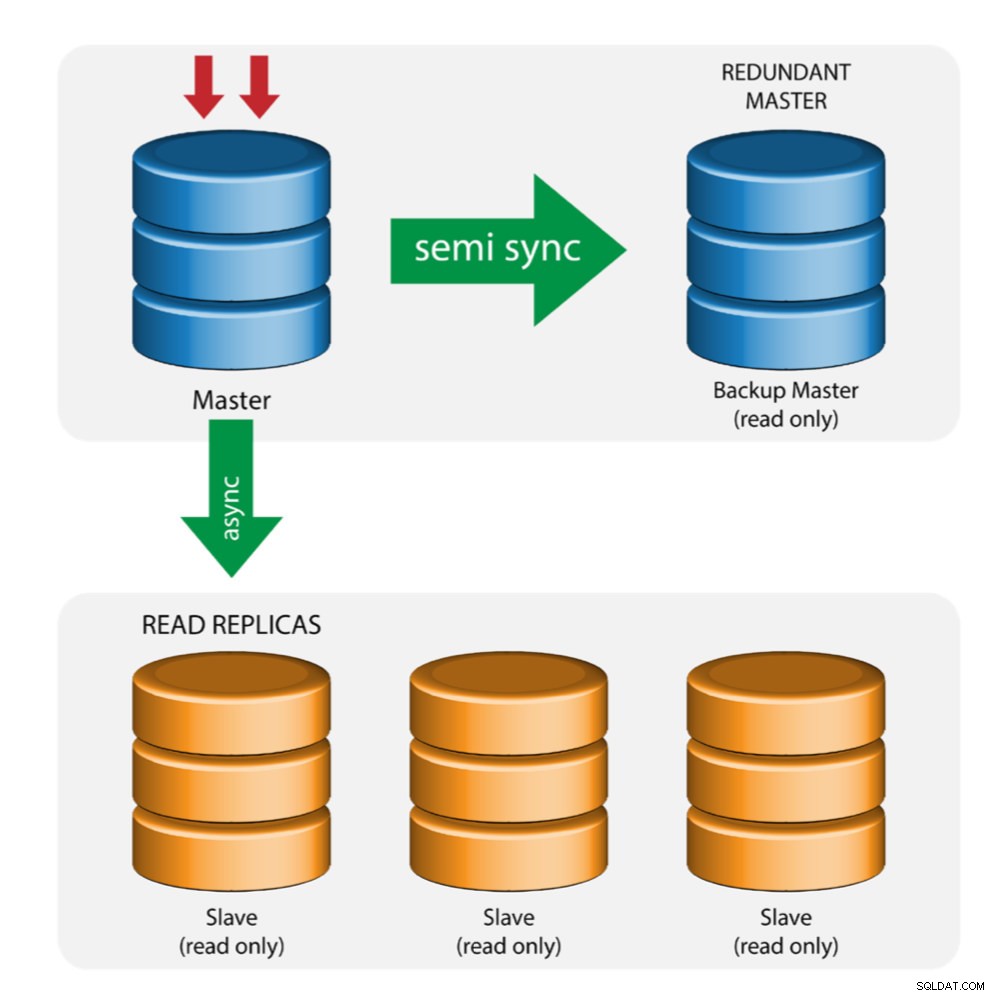
Mastern skickar ändringar till en backup-master och till en eller flera slavar. Semi-synkron replikering används mellan master och backup master. Master skickar uppdatering till backup master och väntar med transaktionsbekräftelse. Backup master får uppdateringar, skriver till sin relälogg och spolar till disk. Backupmaster bekräftar sedan mottagandet av transaktionen till mastern och fortsätter med transaktionsbekräftelse. Semi-synk replikering har en prestandapåverkan, men risken för dataförlust minimeras.
Denna topologi fungerar bra när man utför master-failover i fall mastern går ner. Backupmastern fungerar som en varm-standby-server eftersom den har störst sannolikhet att ha uppdaterad data jämfört med andra slavar.
Multiple Masters to Single Slave (Multi-Source Repplication)
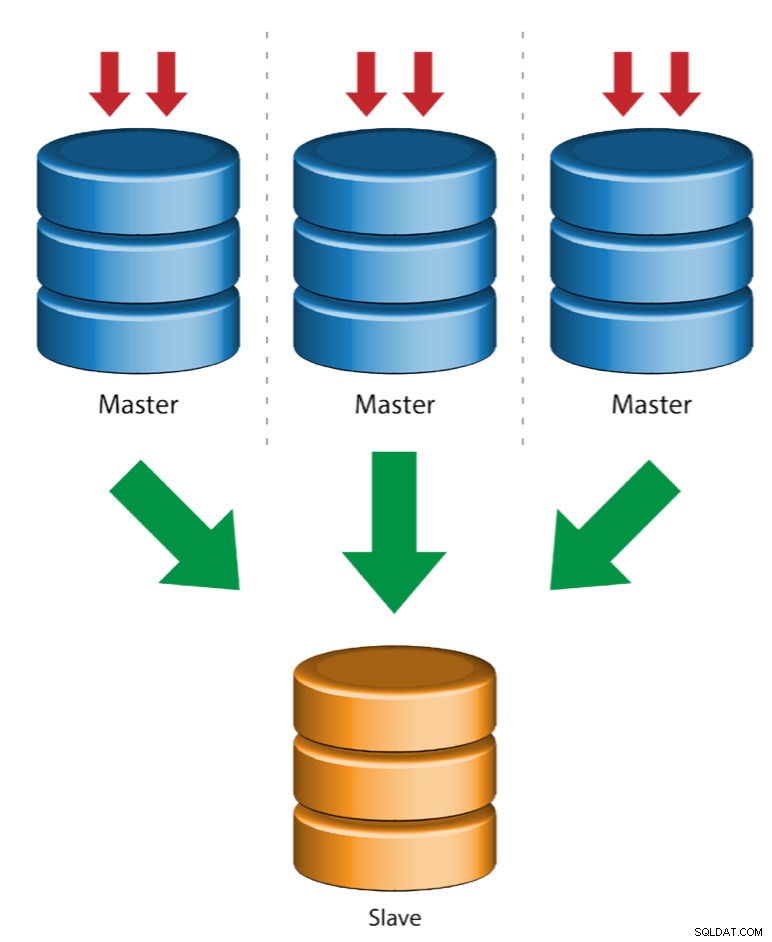
Multi-Source Repplication gör att en replikeringsslav kan ta emot transaktioner från flera källor samtidigt. Replikering med flera källor kan användas för att säkerhetskopiera flera servrar till en enda server, för att slå samman tabellskärvor och konsolidera data från flera servrar till en enda server.
MySQL och MariaDB har olika implementeringar av multi-source replikering, där MariaDB måste ha GTID med gtid-domain-id konfigurerat för att särskilja ursprungstransaktionerna medan MySQL använder en separat replikeringskanal för varje master som slaven replikerar från. I MySQL kan masters i en replikeringstopologi med flera källor konfigureras att använda antingen global transaktionsidentifierare (GTID)-baserad replikering eller binär loggpositionsbaserad replikering.
Mer om MariaDB multi source replikering finns i det här blogginlägget. För MySQL, se MySQL-dokumentationen.
Galera med replikeringsslav (hybridreplikering)
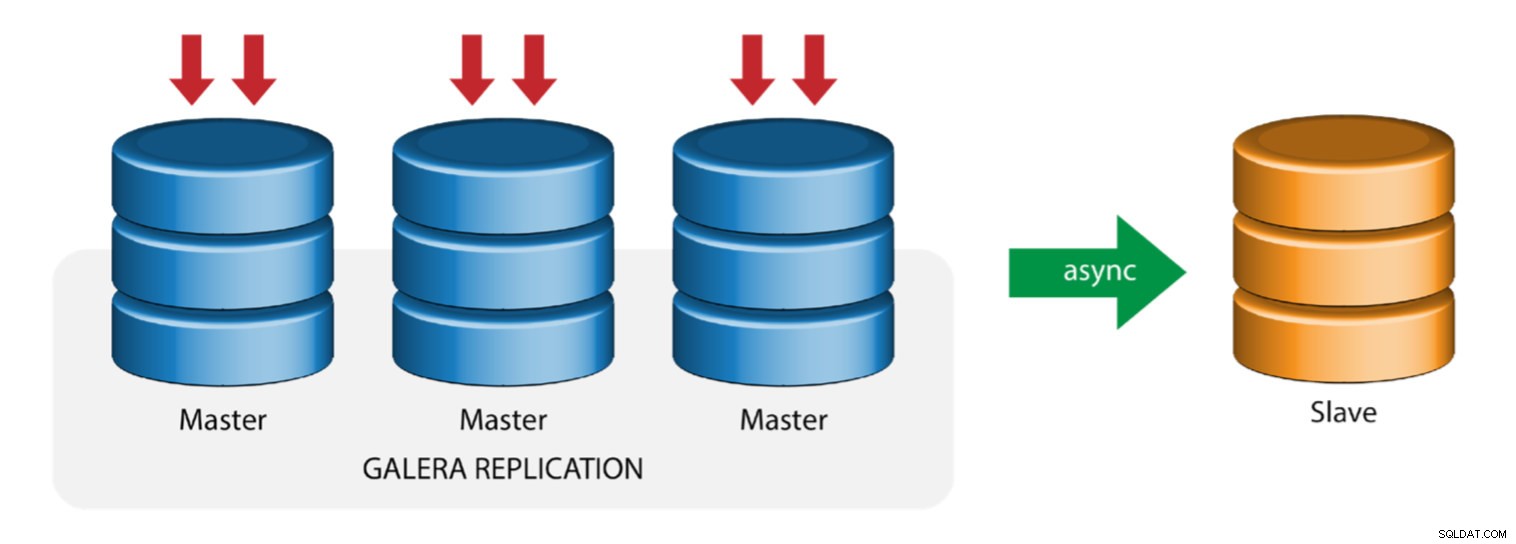
Hybridreplikering är en kombination av MySQL asynkron replikering och praktiskt taget synkron replikering som tillhandahålls av Galera. Implementeringen är nu förenklad med implementeringen av GTID i MySQL-replikering, där att sätta upp och utföra master-failover har blivit en enkel process på slavsidan.
Galera-klusterprestanda är lika snabb som den långsammaste noden. Att ha en asynkron replikeringsslav kan minimera påverkan på klustret om du skickar långa rapporterings-/OLAP-frågor till slaven, eller om du utför tunga jobb som kräver lås som mysqldump. Slaven kan också fungera som en live backup för katastrofåterställning på plats och utanför platsen.
Hybridreplikering stöds av ClusterControl och du kan distribuera den direkt från ClusterControl-gränssnittet. För mer information om hur du gör detta, läs blogginläggen - Hybridreplikering med MySQL 5.6 och Hybridreplikering med MariaDB 10.x.
Förbereder GCP- och AWS-plattformar
Det "verkliga" problemet
I den här bloggen kommer vi att demonstrera och använda "Multiple Replication"-topologin där instanser på två olika offentliga molnplattformar kommer att kommunicera med MySQL-replikering i olika regioner och i olika tillgänglighetszoner. Detta scenario är baserat på ett verkligt problem där en organisation vill bygga sin infrastruktur på flera molnplattformar för skalbarhet, redundans, resiliens/feltolerans. Liknande koncept skulle gälla för MongoDB eller PostgreSQL.
Låt oss överväga en amerikansk organisation, med en utomeuropeisk filial i Sydostasien. Vår trafik är hög inom den asiatiska regionen. Latensen måste vara låg när man tillgodoser skrivningar och läsningar, men samtidigt kan den USA-baserade regionen också hämta poster från den asiatiska trafiken.
The Cloud Architecture Flow
I det här avsnittet kommer jag att diskutera den arkitektoniska gestaltningen. För det första vill vi erbjuda ett mycket säkert lager för vilket våra Google Compute- och AWS EC2-noder kan kommunicera, uppdatera eller installera paket från internet, säkert, högt tillgängligt om en A-Ö (Availability Zone) går ner, kan replikera och kommunicera till en annan molnplattform över ett säkert lager. Se bilden nedan för illustration:

Baserat på illustrationen ovan, under AWS-plattformen, körs alla noder på olika tillgänglighetszoner. Den har ett privat och offentligt subnät där alla beräkningsnoder finns på ett privat subnät. Därför kan den gå utanför internet för att hämta och uppdatera sina systempaket när det behövs. Den har en VPN-gateway för vilken den måste interagera med GCP i den kanalen, kringgå Internet men genom en säker och privat kanal. Samma som GCP, alla beräkningsnoder finns i olika tillgänglighetszoner, använd NAT Gateway för att uppdatera systempaket vid behov och använd VPN-anslutning för att interagera med AWS-noderna som finns på en annan region, d.v.s. Asien och Stillahavsområdet (Singapore). Å andra sidan är den USA-baserade regionen värd under us-east1. För att komma åt noderna fungerar en nod i arkitekturen som bastion-noden för vilken vi kommer att använda den som hoppvärd och installera ClusterControl. Detta kommer att tas upp senare i denna blogg.
Konfigurera GCP- och AWS-miljöer
När du registrerar ditt första GCP-konto tillhandahåller Google ett standard VPC-konto (Virtual Private Cloud). Därför är det bäst att skapa en separat VPC än standard och anpassa den efter dina behov.
Vårt mål här är att placera beräkningsnoderna i privata subnät, annars kommer noderna inte att ställas in med offentlig IPv4. Därför måste båda offentliga molnen kunna prata med varandra. AWS- och GCP-beräkningsnoderna arbetar med olika CIDR som tidigare nämnts. Här är därför följande CIDR:
AWS Compute Nodes: 172.21.0.0/16
GCP Compute Nodes: 10.142.0.0/20
I denna AWS-inställning tilldelade vi tre subnät som inte har någon Internet-gateway utan NAT-gateway; och ett undernät som har en Internet-gateway. Vart och ett av dessa undernät finns individuellt i olika tillgänglighetszoner (AZ).
ap-southeast-1a =172.21.1.0/24
ap-southeast-1b =172.21.8.0/24
ap-southeast-1c =172.21.24.0/24
I GCP används standardundernätet som skapats i en VPC under us-east1 som är 10.142.0.0/20 CIDR. Därför är dessa steg du kan följa för att konfigurera din multi-offentliga molnplattform.
-
För den här övningen skapade jag en VPC i us-east1-regionen med följande subnät 10.142.0.0/20. Se nedan:

-
Reservera en statisk IP. Det här är IP-adressen som vi kommer att konfigurera som en Customer Gateway i AWS
-
Eftersom vi har undernät på plats (tillhandahålls som subnet-us-east1 ), gå till GCP -> VPC-nätverk -> VPC-nätverk och välj den VPC du skapade och gå till Brandväggsreglerna . I det här avsnittet lägger du till reglerna genom att ange din ingång och utgång. I grund och botten är dessa reglerna för inkommande/utgående i AWS eller din brandvägg för inkommande och utgående anslutningar. I den här installationen öppnade jag alla TCP-protokoll från CIDR-intervallet i min AWS och GCP VPC för att göra det enklare för syftet med denna blogg. Detta är därför inte det optimala sättet för säkerhet. Se bilden nedan:
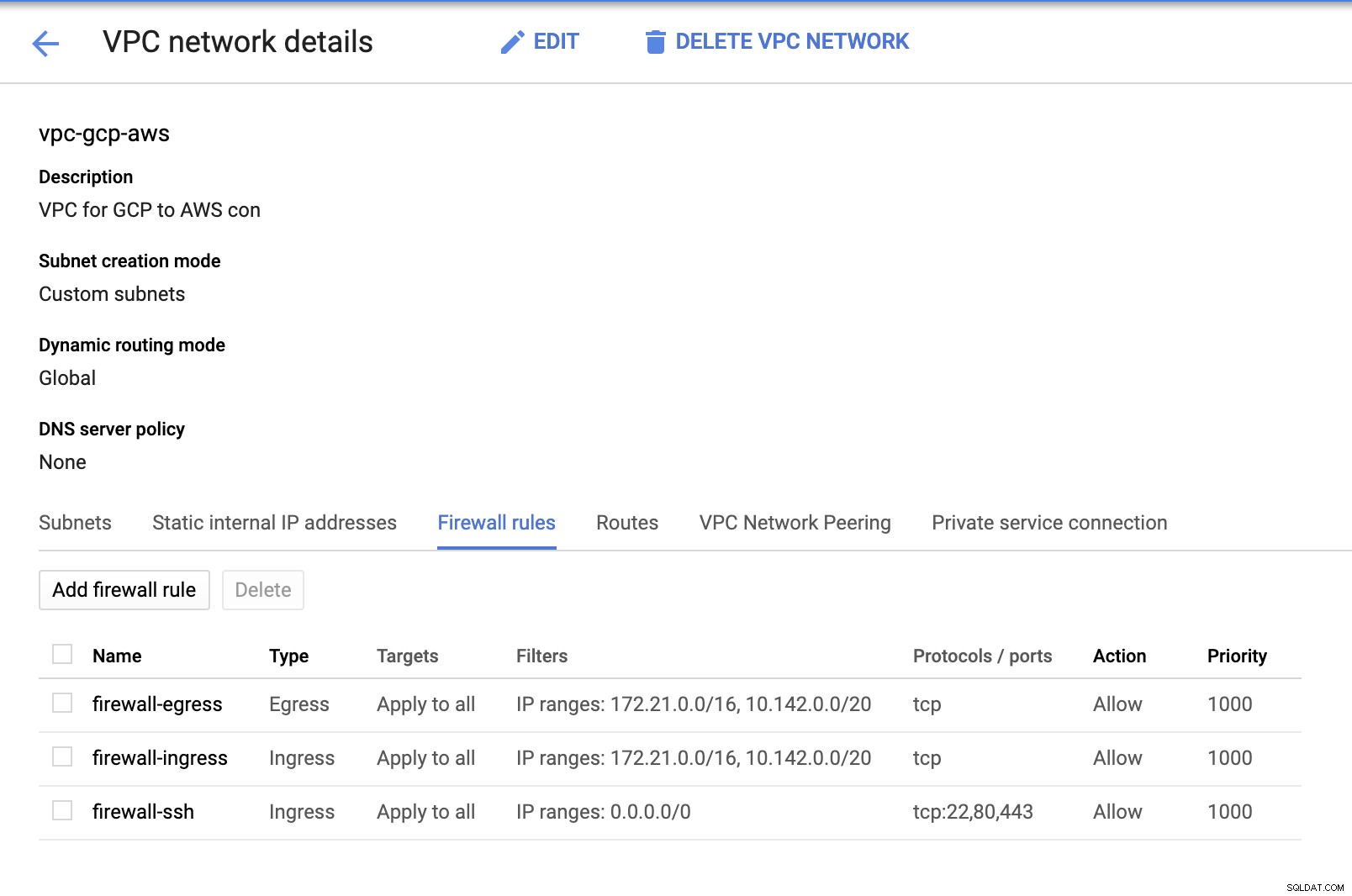
Brandväggen-ssh här kommer att användas för att tillåta ssh, HTTP och HTTPS inkommande anslutningar.
-
Byt nu till AWS och skapa en VPC. För den här bloggen använde jag CIDR (Classless Inter-Domain Routing) 172.21.0.0/16
-
Skapa de undernät som du måste tilldela dem i varje A-Ö (Availability Zone); och åtminstone reservera ett subnät för ett publikt subnät som kommer att hantera NAT Gateway, och resten är för EC2-noder.

-
Skapa sedan din rutttabell och se till att "Destination" och "Targets" är korrekt inställda. För den här bloggen skapade jag 2 rutttabeller. En som kommer att hantera de 3 AZ som mina beräkningsnoder kommer att tilldelas individuellt och kommer att tilldelas utan en Internet Gateway eftersom den inte kommer att ha någon offentlig IP. Sedan kommer den andra att hantera NAT-gatewayen och kommer att ha en Internet-gateway som kommer att finnas i det offentliga undernätet. Se bilden nedan:

och som nämnts visar min exempeldestination för privat rutt som hanterar 3 subnät att ha ett NAT Gateway-mål plus ett Virtual Gateway-mål som jag kommer att nämna senare i de inkommande stegen.

-
Skapa sedan en "Internet Gateway" och tilldela den till den VPC som tidigare skapades i AWS VPC-sektionen. Denna Internet-gateway ska endast ställas in som destination för det offentliga subnätet eftersom det kommer att vara tjänsten som måste ansluta till internet. Uppenbarligen står namnet för som en internetgateway-tjänst.
-
Skapa sedan en "NAT Gateway". När du skapar en "NAT Gateway", se till att du har tilldelat din NAT till ett offentligt undernät. NAT Gateway är din kanal för åtkomst till internet från ditt privata subnät eller EC2-noder som inte har någon offentlig IPv4 tilldelad. Skapa eller tilldela sedan en EIP (Elastic IP) eftersom, i AWS, endast beräkningsnoder som har offentlig IPv4 tilldelad kan ansluta till internet direkt.
-
Nu under VPC -> Säkerhet -> Säkerhetsgrupper (SG) , kommer din skapade VPC att ha en standard SG. För den här installationen skapade jag "Inkommande regler" med källor tilldelade för varje CIDR, dvs. 10.142.0.0/20 i GCP och 172.21.0.0/16 i AWS. Se nedan:

För "Utgående regler" kan du lämna det som det är eftersom att tilldela regler till "Inkommande regler" är bilateralt, vilket innebär att det också öppnas för "Utgående regler". Observera att detta inte är det optimala sättet att ställa in din säkerhetsgrupp; men för att göra det enklare för den här installationen har jag också gjort ett bredare utbud av portomfång och källa. Även att protokollet endast är specifikt för TCP-anslutningar eftersom vi inte kommer att hantera UDP för den här bloggen.
Dessutom kan du lämna dina VPC -> Säkerhet -> Nätverks-ACL orörd så länge den inte NEKAR några tcp-anslutningar från CIDR som anges i din källa. -
Därefter kommer vi att ställa in VPN-konfigurationen som kommer att finnas på AWS-plattformen. Under VPC -> Customer Gateways , skapa gatewayen med den statiska IP-adressen som skapades tidigare i föregående steg. Ta en titt på bilden nedan:
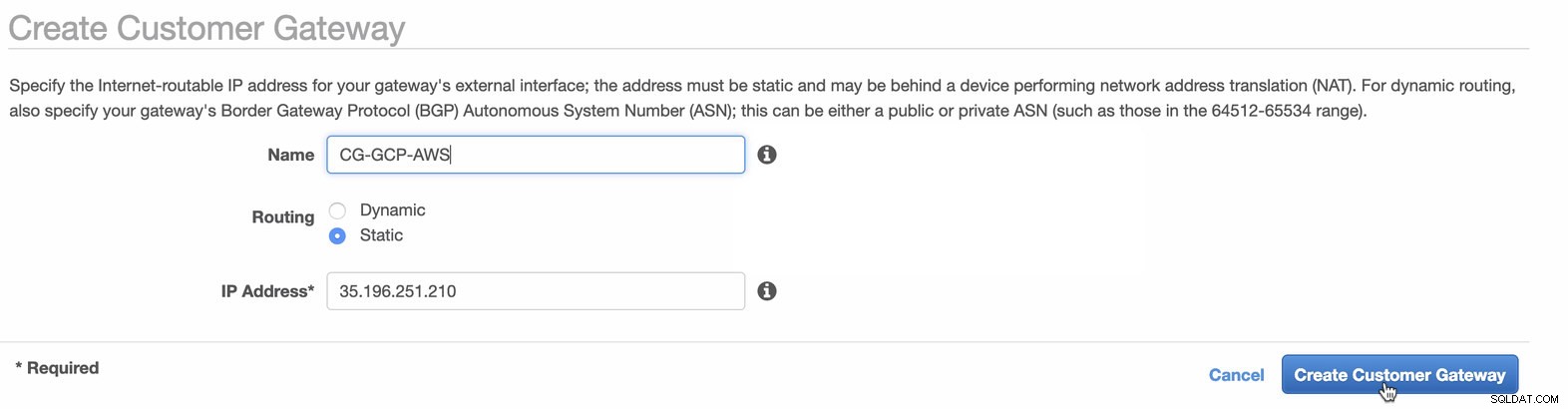
-
Skapa sedan en Virtual Private Gateway och bifoga denna till den aktuella VPC som vi skapade tidigare i föregående steg. Se bilden nedan:

-
Skapa nu en VPN-anslutning som kommer att användas för plats-till-plats-anslutningen mellan AWS och GCP. När du skapar en VPN-anslutning, se till att du har valt rätt Virtual Private Gateway och den Customer Gateway som vi skapade i de föregående stegen. Se bilden nedan:
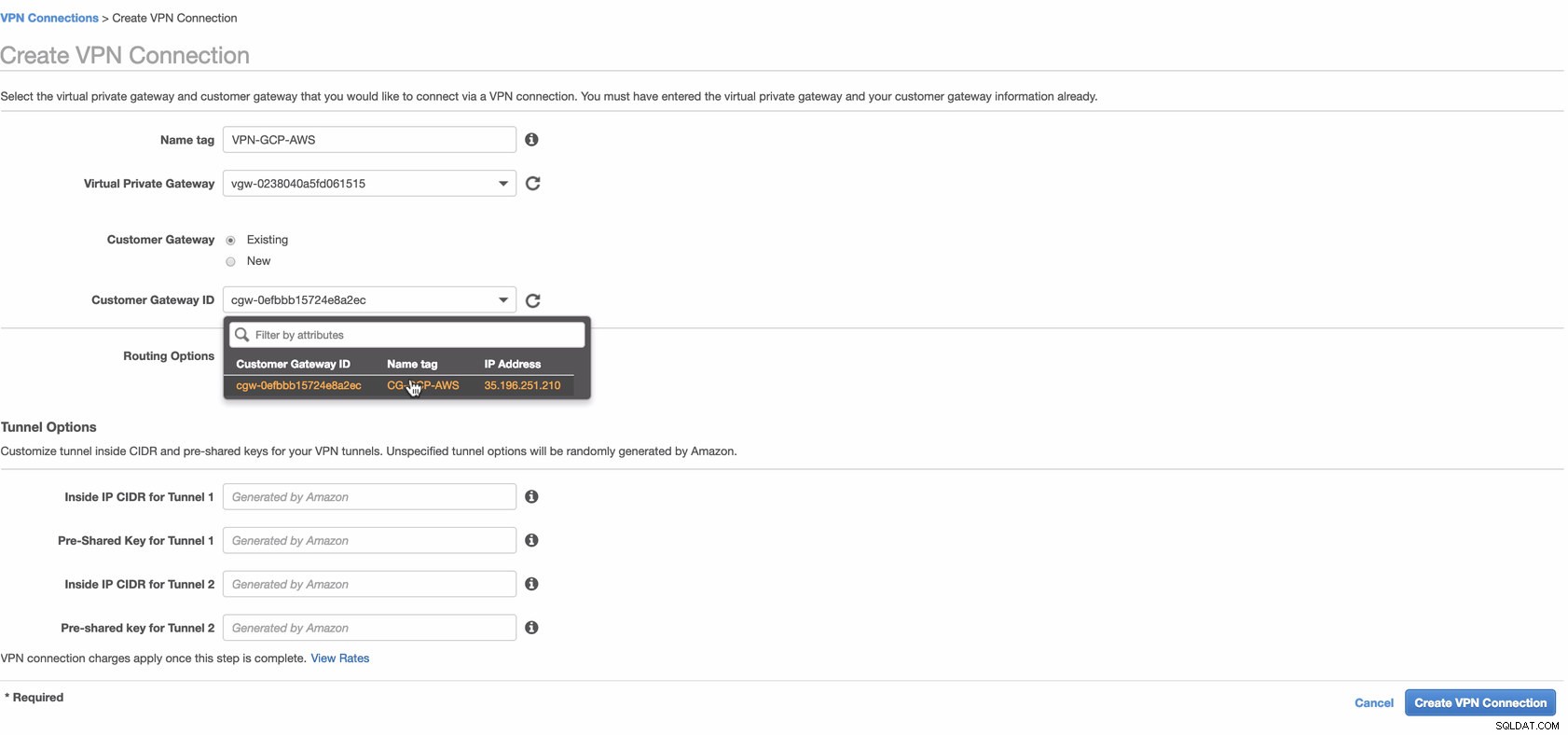
Detta kan ta lite tid medan AWS skapar din VPN-anslutning. När din VPN-anslutning sedan tillhandahålls kan du undra varför under fliken Tunnel (efter att du har valt din VPN-anslutning) kommer den att visa att IP-adressen utanför är nere. Detta är normalt eftersom det inte finns någon anslutning som ännu har upprättats från klienten. Ta en titt på exempelbilden nedan:

När VPN-anslutningen är klar, välj din skapade VPN-anslutning och ladda ner konfigurationen. Den innehåller dina referenser som behövs för följande steg för att skapa en plats-till-plats VPN-anslutning med klienten.
Obs! Om du har ställt in din VPN där IPSEC IS UP men Status är NER precis som bilden nedan

detta beror troligen på felaktiga värden inställda på de specifika parametrarna när du konfigurerade din BGP-session eller molnrouter. Kolla in det här för att felsöka ditt VPN.
-
Eftersom vi har en VPN-anslutning redo värd i AWS, låt oss skapa en VPN-anslutning i GCP. Nu går vi tillbaka till GCP och ställer in klientanslutningen där. I GCP, gå till GCP -> Hybrid Connectivity -> VPN . Se till att du väljer rätt region, som finns på den här bloggen, vi använder us-east1 . Välj sedan den statiska IP-adressen som skapades i de föregående stegen. Se bilden nedan:
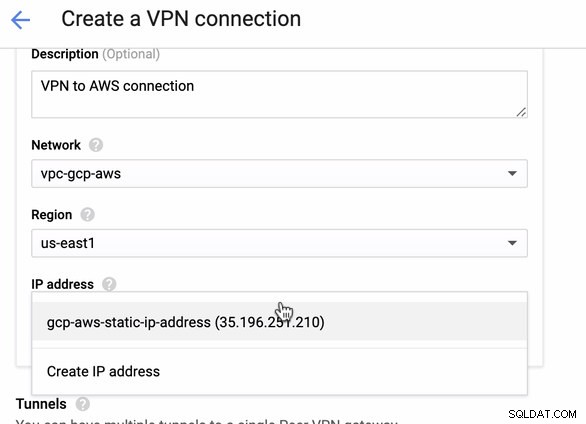
Sedan i tunnlarna avsnitt, det är här du måste ställa in baserat på de nedladdade referenserna från AWS VPN-anslutningen som du skapade tidigare. Jag föreslår att du kollar in den här användbara guiden från Google. Till exempel, en av tunnlarna som ställs in visas i bilden nedan:
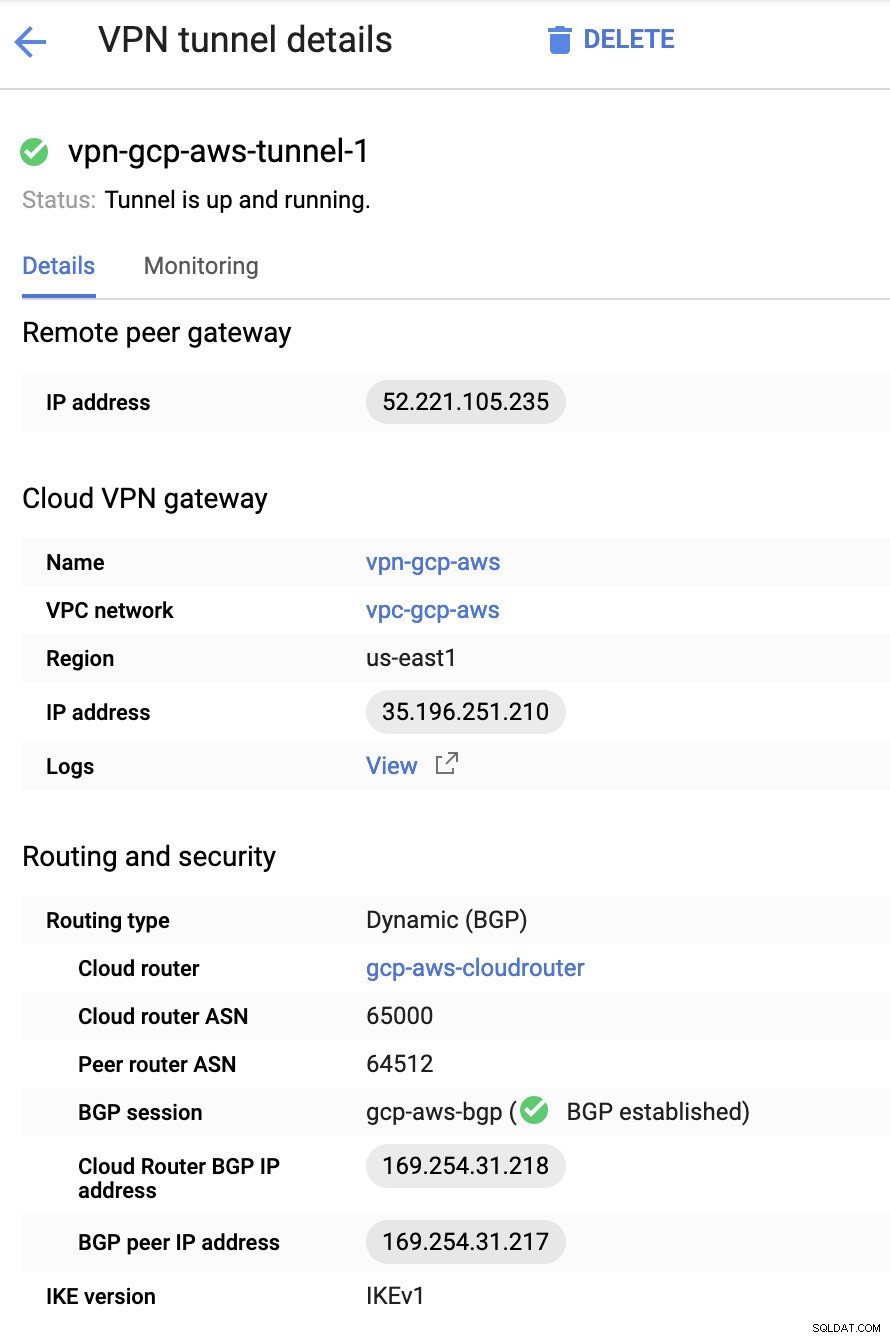
I grund och botten är de viktigaste sakerna här följande:
- Remote Peer Gateway:IP-adress - Detta är IP-adressen för VPN-servern som anges under Tunneldetaljer -> Extern IP-adress . Detta ska inte förväxlas med den statiska IP som vi skapade under GCP. Det är Cloud VPN-gateway -> IP-adress dock.
- Molnrouter ASN - Som standard använder AWS 65000. Men troligtvis får du denna information från den nedladdade konfigurationsfilen.
- Peer-router ASN – Detta är Virtual Private Gateway ASN som finns i den nedladdade konfigurationsfilen.
- Cloud Router BGP IP-adress – Detta är kundgatewayen finns i den nedladdade konfigurationsfilen.
- BGP peer IP-adress – Detta är den Virtual Private Gateway finns i den nedladdade konfigurationsfilen.
-
Ta en titt på exemplet på konfigurationsfilen jag har nedan:
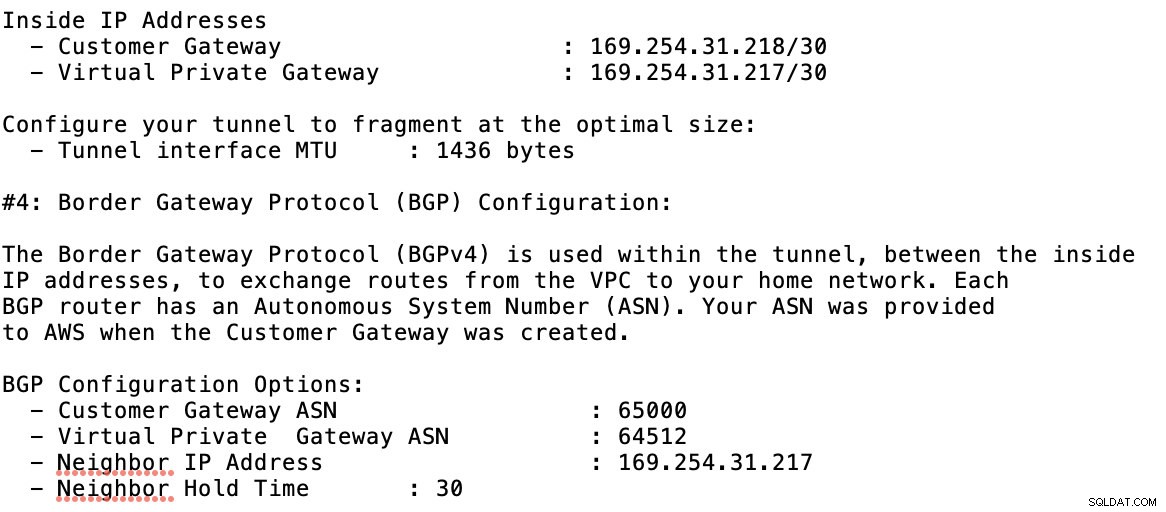
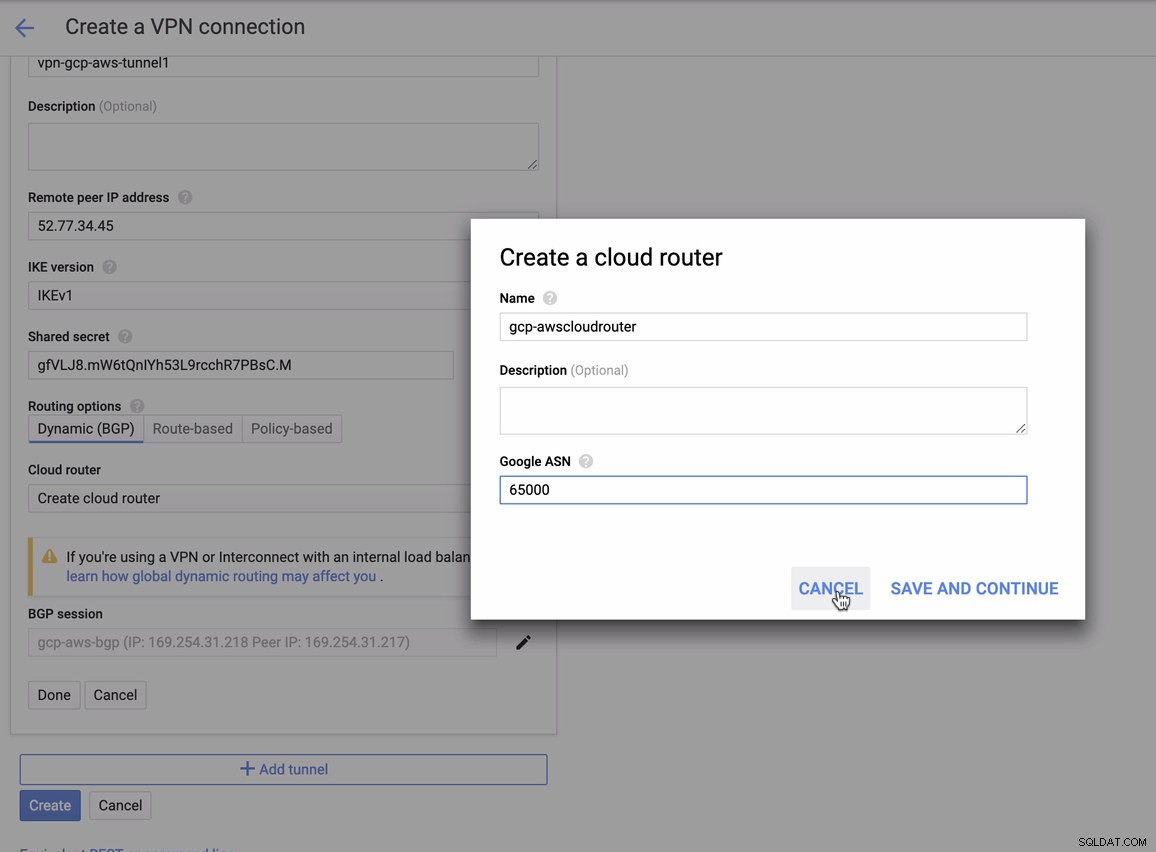
för vilket du måste matcha detta när du lägger till din tunnel under GCP -> Hybrid Connectivity -> VPN anslutningsinställningar. Se bilden nedan för vilken jag skapade en molnrouter och en BGP-session när jag skapade en provtunnel:
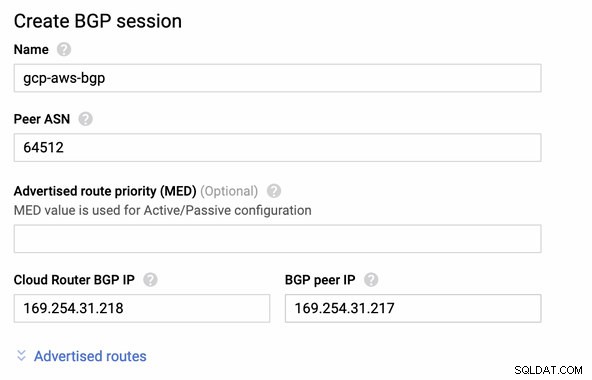
Sedan BGP-session som,

Obs! Den nedladdade konfigurationsfilen innehåller IPSec-konfigurationstunneln för vilken AWS också innehåller två (2) VPN-servrar redo för din anslutning. Du måste ställa in båda så att du har en hög tillgänglig inställning. När den har ställts in för båda tunnlarna korrekt kommer AWS VPN-anslutningen under fliken Tunnels att visa att både Utanvänd IP-adress är upp. Se bilden nedan:

-
Slutligen, eftersom vi har skapat en Internet Gateway och NAT Gateway, fyll i de offentliga och privata undernäten korrekt med korrekt Destination och Mål som noterats i skärmdumpen från tidigare steg. Detta kan ställas in genom att gå till Tjänster -> Nätverk och innehållsleverans -> VPC -> Rutttabeller och välj de skapade rutttabellerna från de föregående stegen. Se bilden nedan:
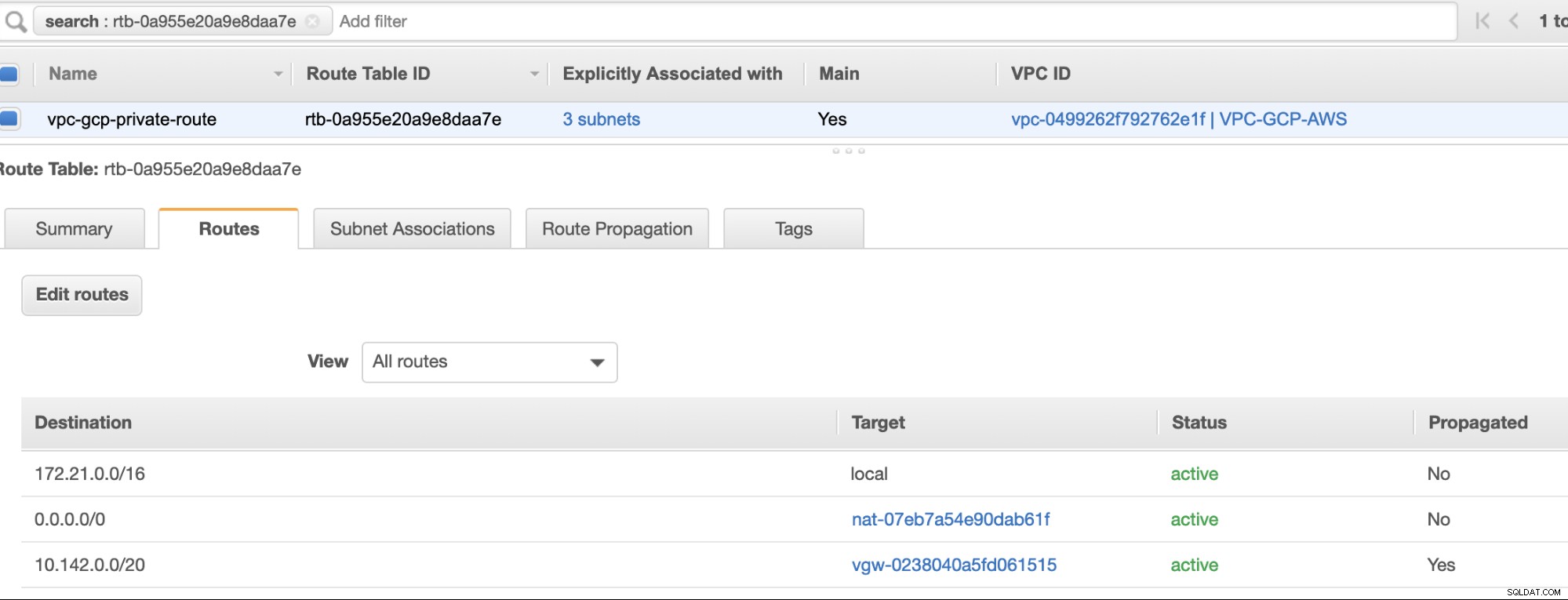
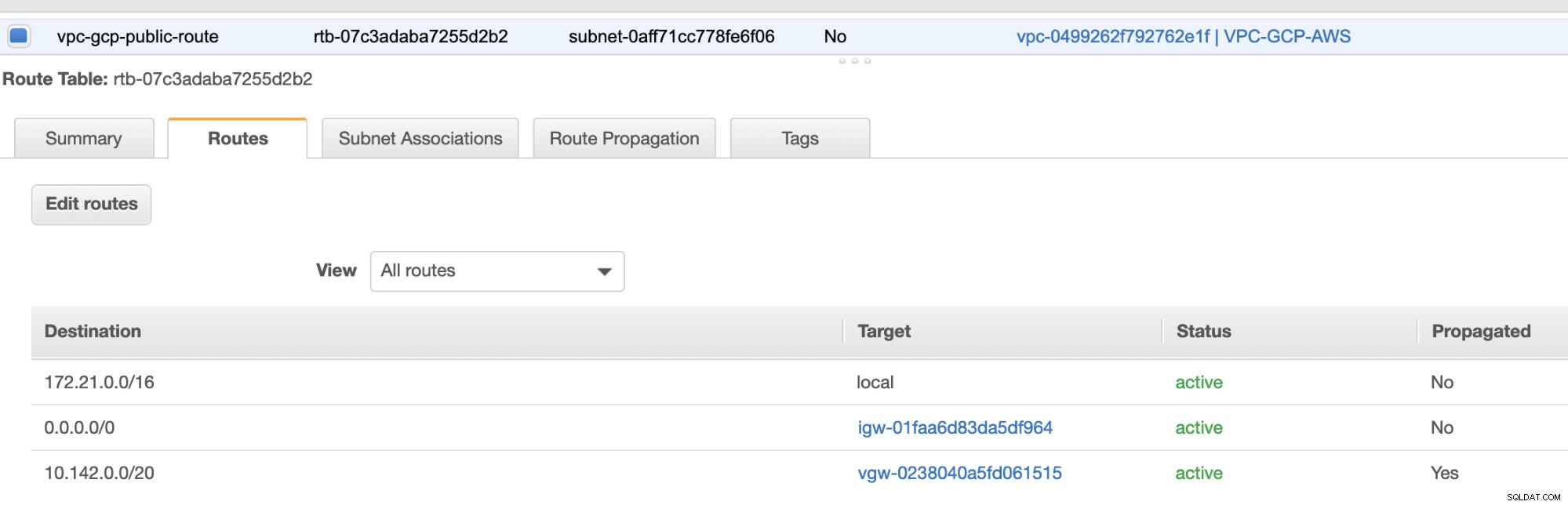
Som du märkte, igw-01faa6d83da5df964 är den Internet-gateway som vi skapade och som används av den allmänna vägen. Medan den privata rutttabellen har destination och mål inställda på nat-07eb7a54e90dab61f och båda dessa har Destination inställd på 0.0.0.0/0 eftersom det tillåter från olika IPv4-anslutningar. Glöm inte heller att ställa in Ruttutbredning korrekt för den virtuella gatewayen som visas på skärmdumpen som har ett mål vgw-0238040a5fd061515 . Klicka bara på Route Propagation och ställ in den på Ja precis som på skärmdumpen nedan:
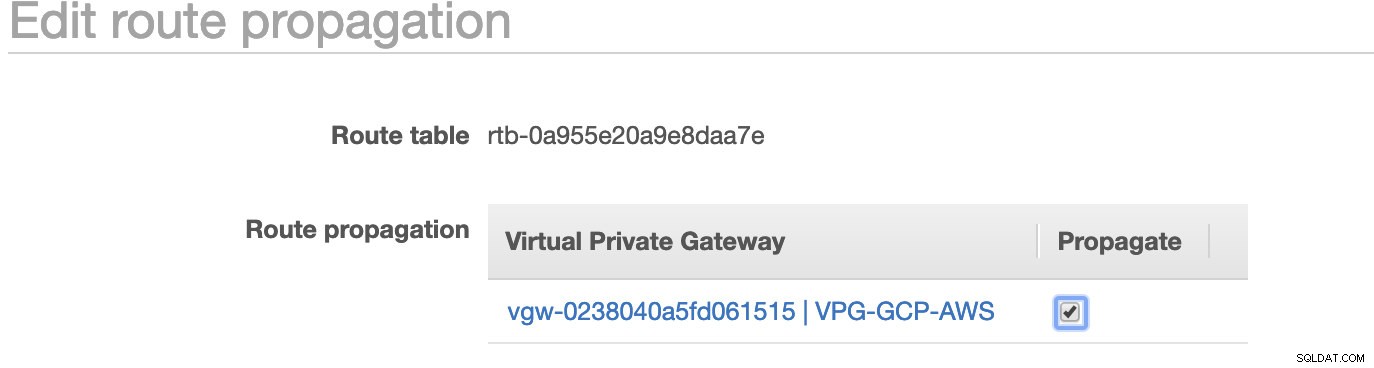
Detta är mycket viktigt för att anslutningen från de externa GCP-anslutningarna ska dirigeras till rutttabellerna i AWS och inget ytterligare manuellt arbete behövs. Annars kan din GCP inte upprätta anslutning till AWS.
Nu när vårt VPN är uppe kommer vi att fortsätta konfigurera våra privata noder inklusive bastionvärden.
Ställa in Compute Engine-noderna
Att ställa in Compute Engine/EC2-noderna kommer att vara snabbt och enkelt eftersom vi har alla inställningar på plats. Jag ska inte gå in på de detaljerna utan kolla in skärmbilderna nedan eftersom de förklarar inställningarna.
AWS EC2-noder :

GCP Compute Nodes :
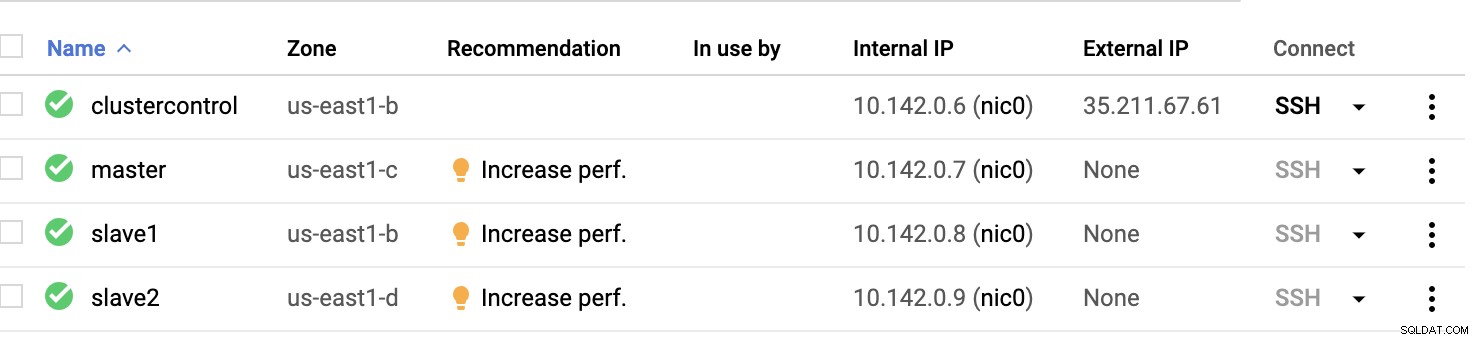
I grund och botten på denna inställning. Värden clustercontrol kommer att vara bastion- eller hoppvärden och för vilken ClusterControl kommer att installeras. Uppenbarligen är alla noder här inte internettillgängliga. De har ingen extern IPv4 tilldelad och noder kommunicerar via en mycket säker kanal med VPN.
Slutligen är alla dessa noder från AWS till GCP konfigurerade med en enhetlig systemanvändare med sudo-åtkomst, vilket behövs i vårt nästa avsnitt. Se hur ClusterControl kan göra ditt liv enklare när du är i multicloud och multi-region.
ClusterControl To The Rescue!!!
Att hantera flera noder och på olika offentliga molnplattformar, plus på en annan "region" kan vara en "verkligen smärtsam och skrämmande" uppgift. Hur övervakar du det på ett effektivt sätt? ClusterControl fungerar inte bara som din schweiziska kniv, utan också som din virtuella DBA. Nu ska vi se hur ClusterControl kan göra ditt liv enklare.
Skapa ett multipelreplikeringskluster med ClusterControl
Låt oss nu försöka skapa ett MariaDB master-slave-replikeringskluster efter "Multiple Replication"-topologin.
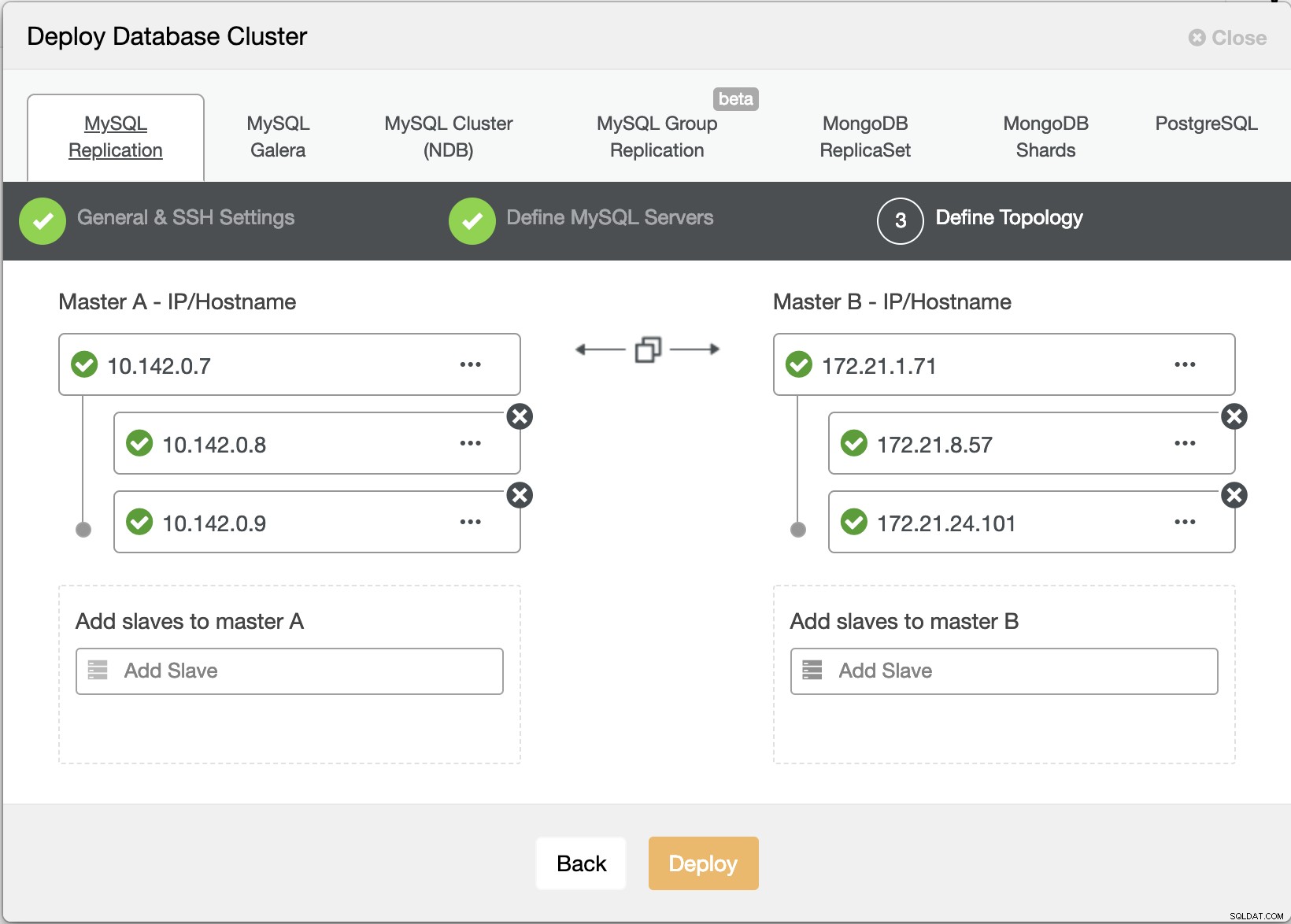 ClusterControl Deploy Wizard
ClusterControl Deploy Wizard Tryck på Deploy knappen installerar paket och ställer in noderna därefter. Därför en logisk bild av hur topologin skulle se ut:
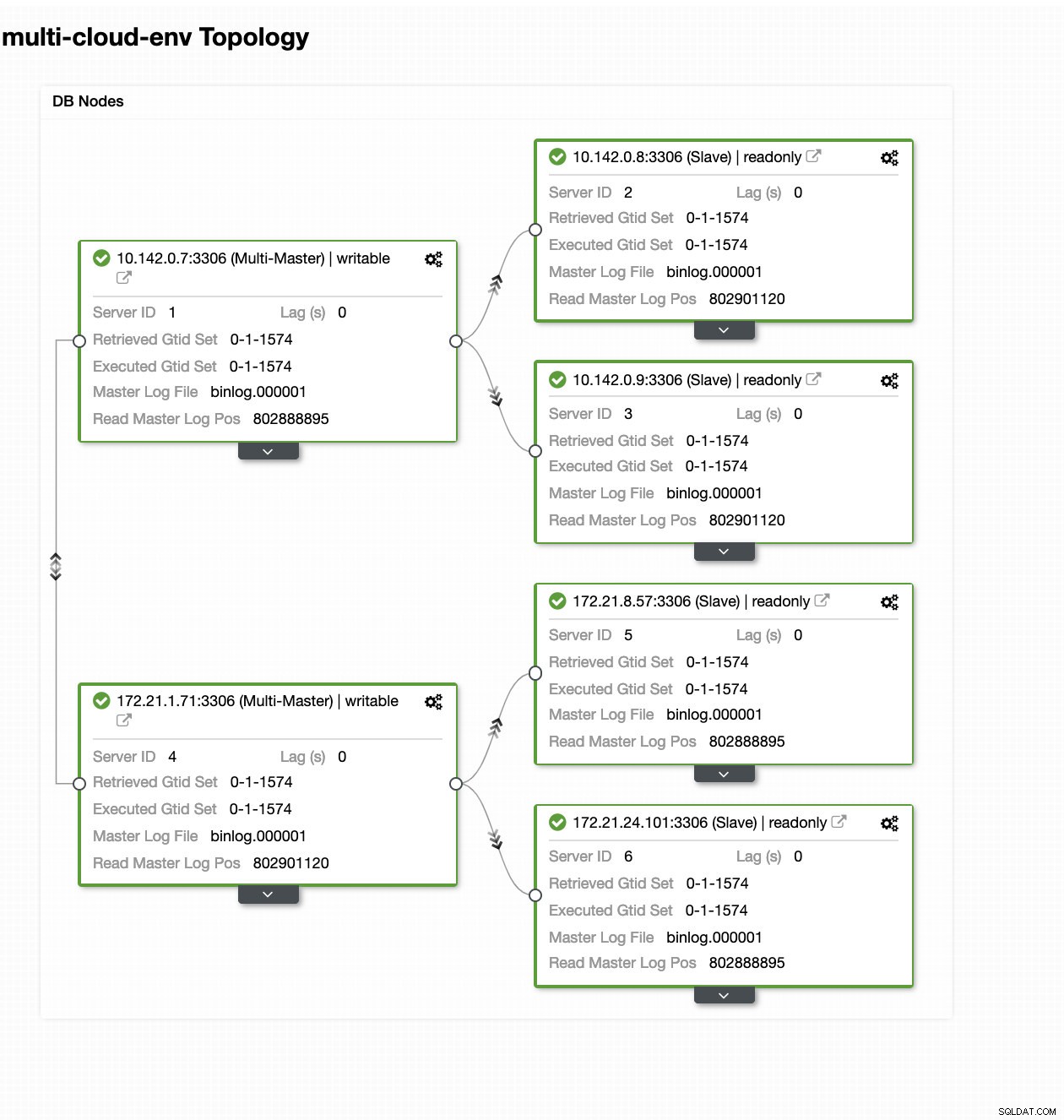 ClusterControl - Topologivy
ClusterControl - Topologivy Noderna 172.21.0.0/16 IP-adresser replikerar från sin master som körs på GCP.
Nu, vad sägs om att vi försöker ladda några skrivningar på mastern? Eventuella problem med anslutning eller latens kan generera slavfördröjning, du kommer att kunna upptäcka detta med ClusterControl. Se skärmdumpen nedan:
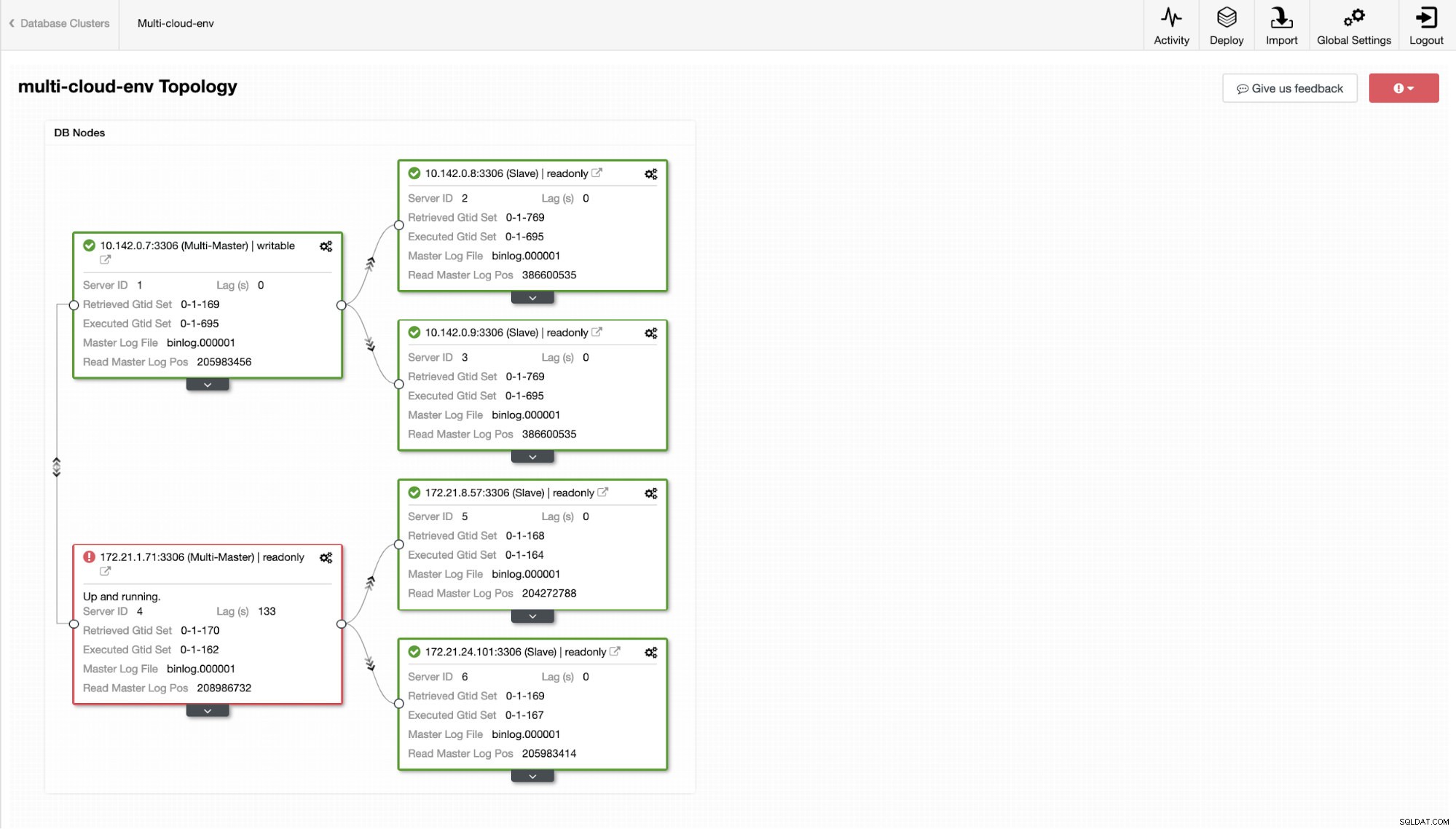
och som du ser i det övre högra hörnet av skärmdumpen blir den röd eftersom det indikerar att problem upptäcktes. Därför skickades ett larm medan detta problem har upptäckts. Se nedan:
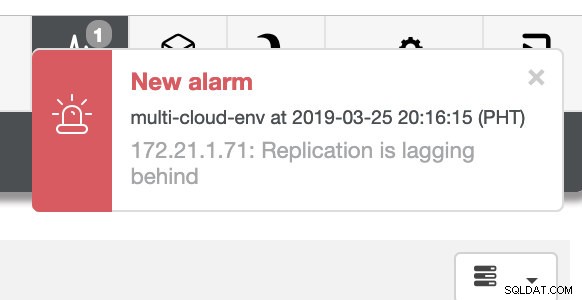
Vi måste gräva i det här. För finkornig övervakning har vi aktiverat agenter på databasinstanserna. Låt oss ta en titt på instrumentpanelen.
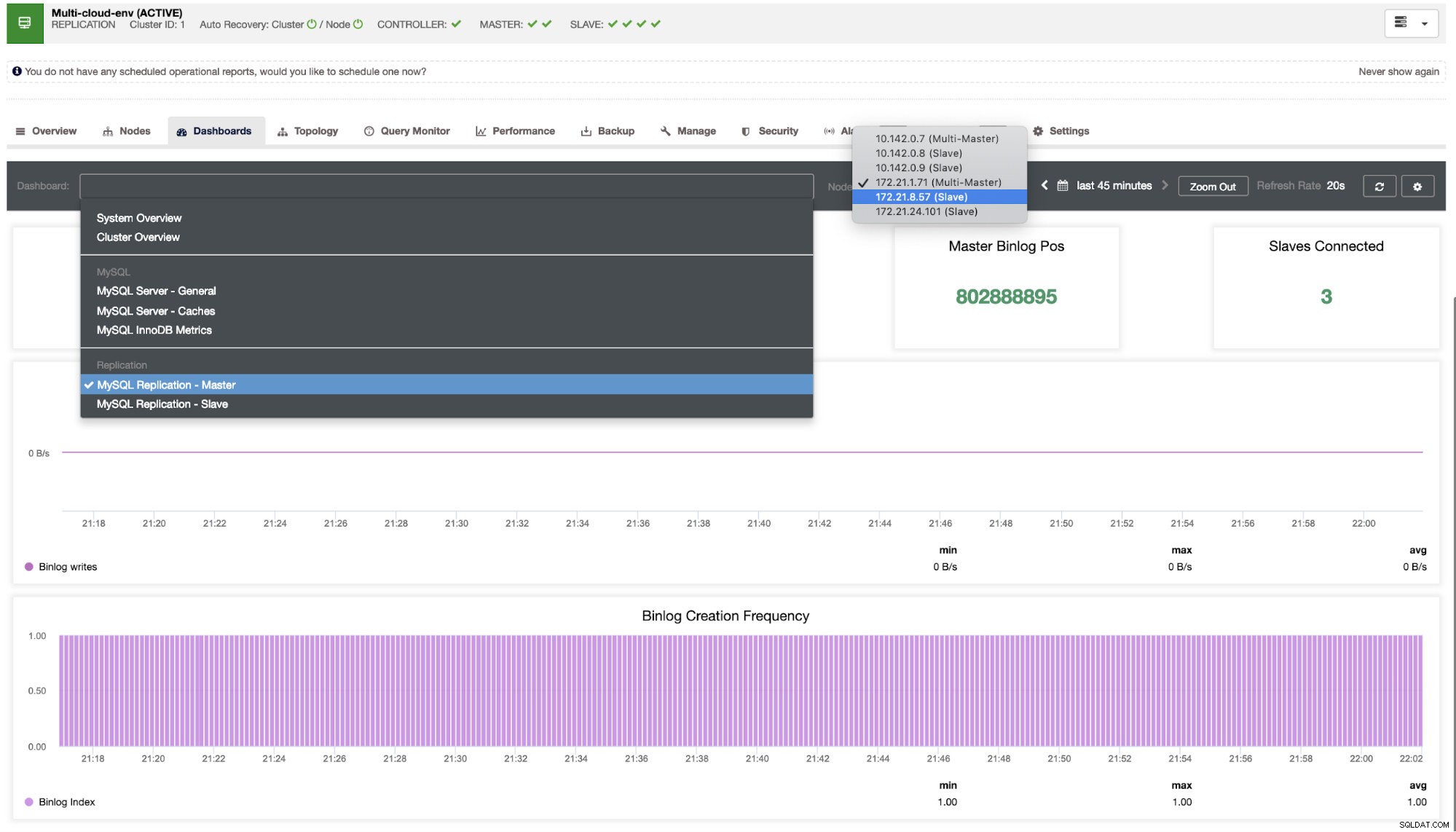
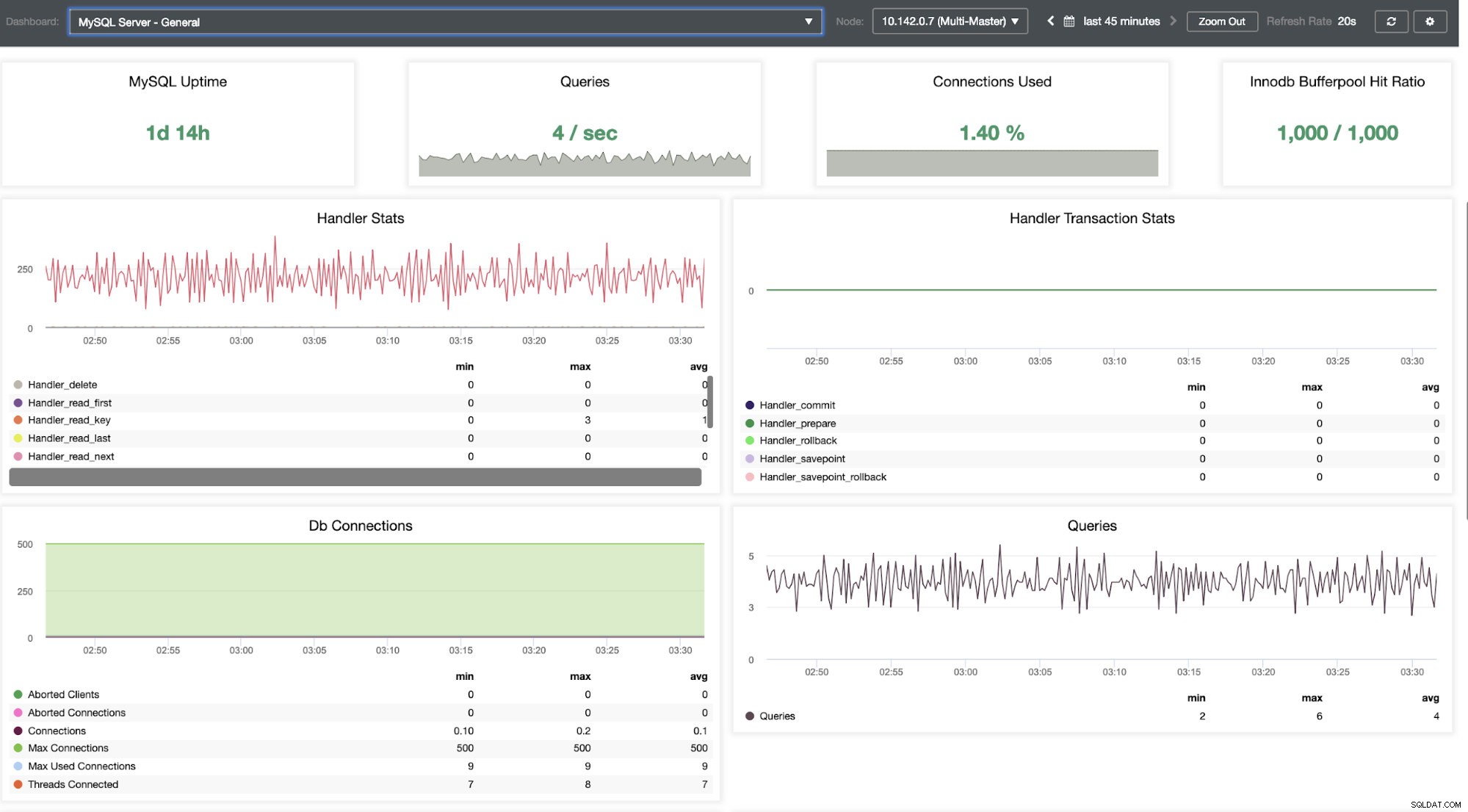
Det erbjuder en supersmidig upplevelse när det gäller att övervaka dina noder.
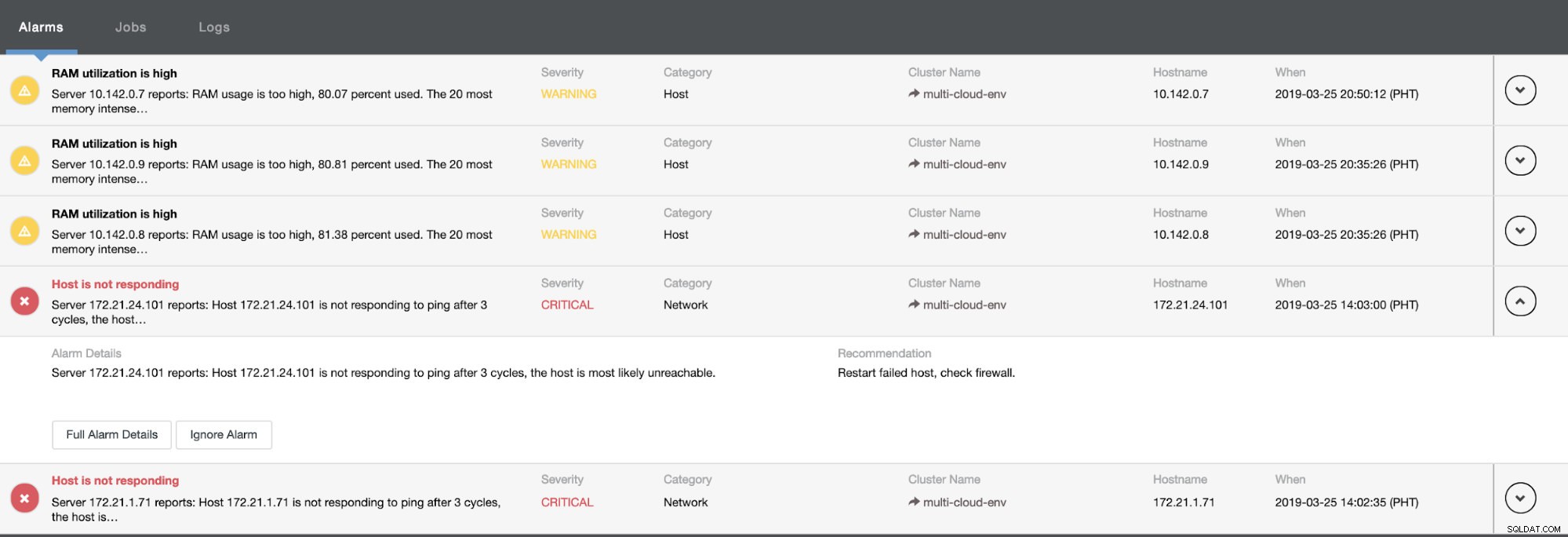
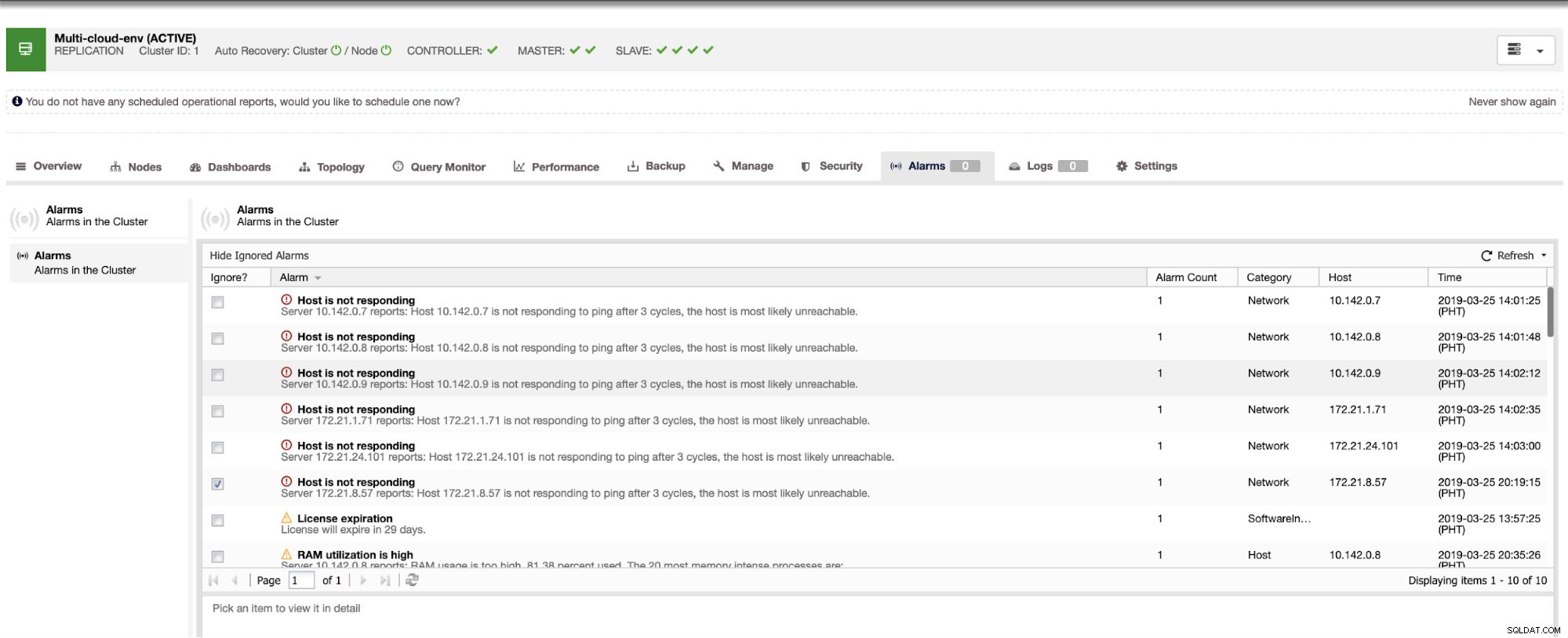
Det talar om för oss att utnyttjandet är högt eller att värden inte svarar. Även om detta bara var en ping svarsfel kan du ignorera varningen för att hindra dig från att bombardera den. Därför kan du "av-ignorera" det om det behövs genom att gå till Cluster -> Larm i Clustercontrol. Se nedan:
Hantera fel och utföra failover
Låt oss säga att us-east1 huvudnoden misslyckades eller kräver en större översyn på grund av system- eller hårdvaruuppgradering. Låt oss säga att detta är topologin just nu (se bilden nedan):
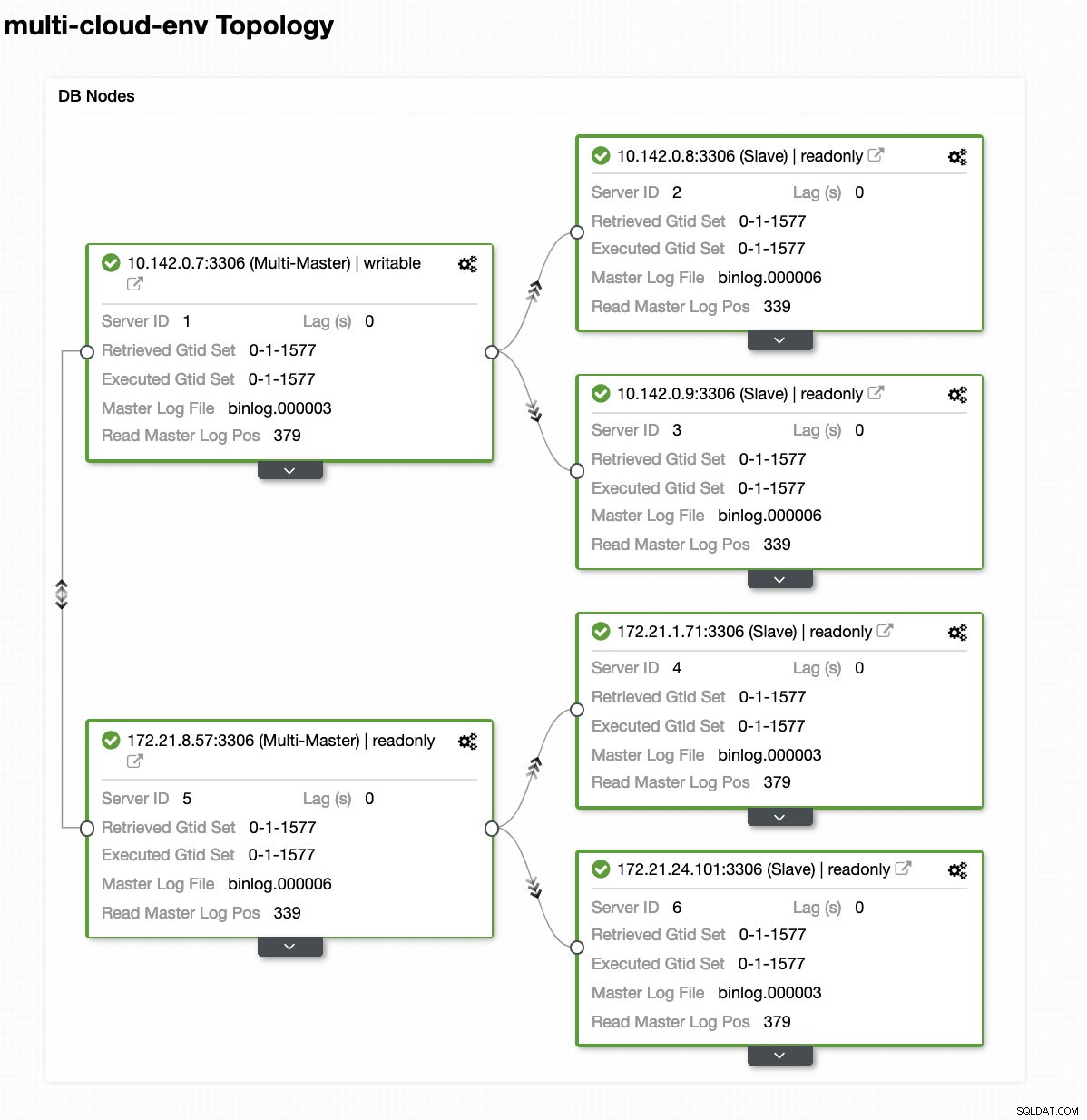
Låt oss försöka stänga av värd 10.142.0.7 som är master under regionen us-east1. Se skärmdumparna nedan hur ClusterControl reagerar på detta:
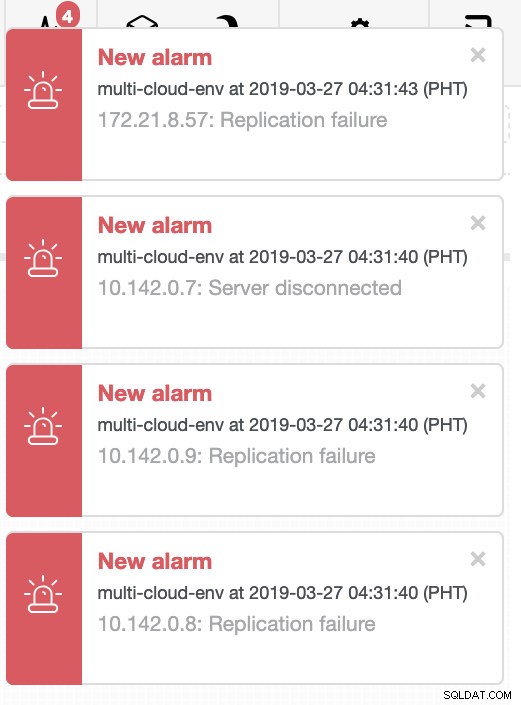
ClusterControl skickar larm när den upptäcker anomalier i klustret. Sedan försöker den göra en failover till en ny master genom att välja rätt kandidat (se bilden nedan):

Sedan avsatte den den misslyckade mastern som redan har tagits ut från klustret (se bilden nedan):
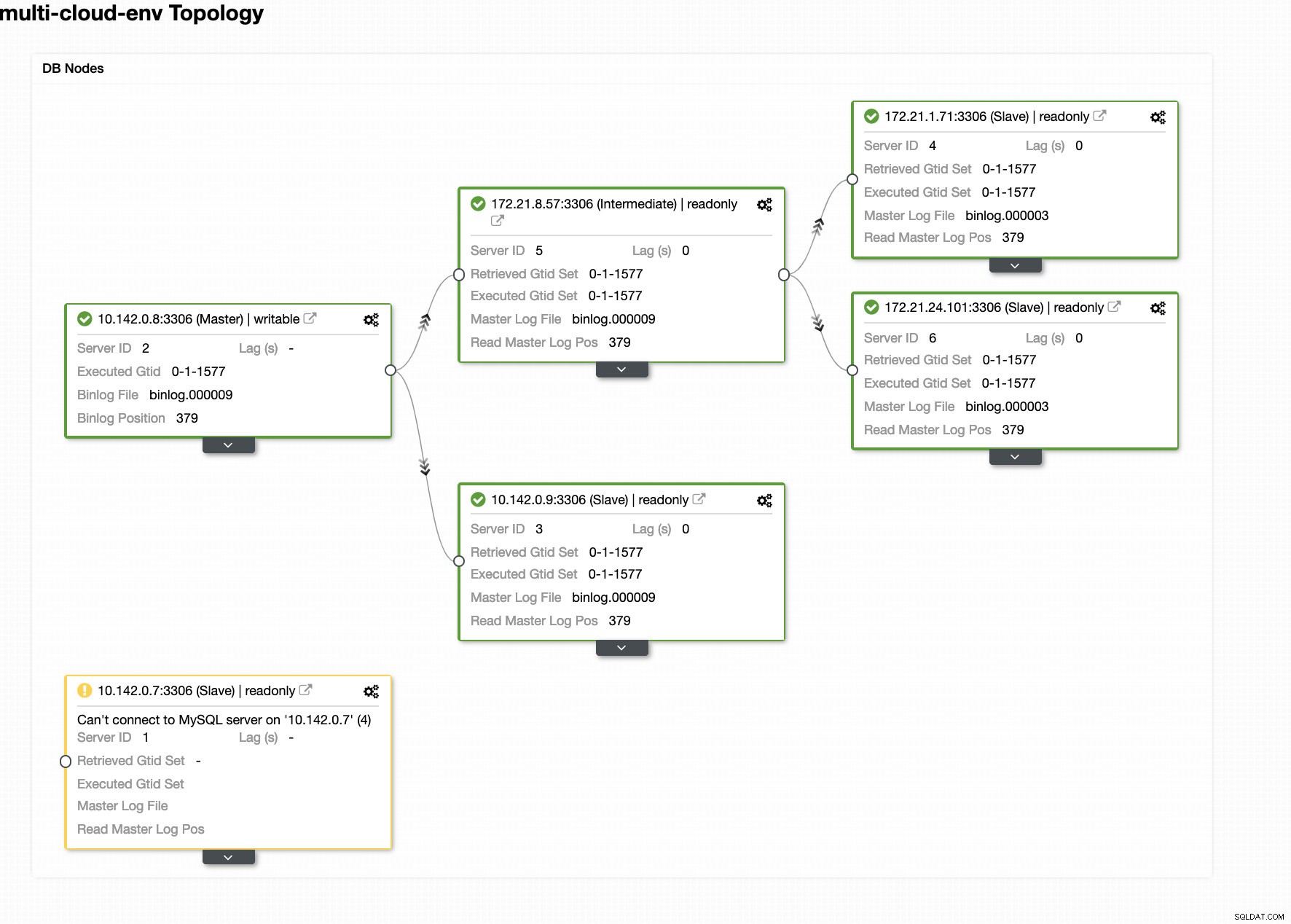
Det här är bara en glimt av vad ClusterControl kan göra, det finns andra fantastiska funktioner som säkerhetskopiering, frågeövervakning, driftsättning/hantering av lastbalanserare och många fler!
Slutsats
Det kan vara svårt att hantera din MySQL-replikeringsinstallation i ett multimoln. Mycket försiktighet måste tas för att säkra vår installation, så förhoppningsvis ger den här bloggen en idé om hur man definierar subnät och skyddar databasnoderna. Efter säkerheten finns det ett antal saker att hantera och det är här ClusterControl kan vara till stor hjälp.
Testa det nu och låt oss veta hur det går. Du kan kontakta oss här när som helst.