Någon raderade av misstag en del av databasen. Någon glömde att inkludera en WHERE-sats i en DELETE-fråga, eller så tappade de fel tabell. Sådana saker kan och kommer att hända, det är oundvikligt och mänskligt. Men konsekvenserna kan bli katastrofala. Vad kan du göra för att skydda dig mot sådana situationer, och hur kan du återställa dina data? I det här blogginlägget kommer vi att täcka några av de mest typiska fallen av dataförlust och hur du kan förbereda dig så att du kan återhämta dig från dem.
Förberedelser
Det finns saker du bör göra för att säkerställa en smidig återhämtning. Låt oss gå igenom dem. Tänk på att det inte är en "välj en"-situation - helst kommer du att implementera alla åtgärder som vi kommer att diskutera nedan.
Säkerhetskopiering
Du måste ha en backup, det går inte att komma ifrån det. Du bör testa dina säkerhetskopior - om du inte testar dina säkerhetskopior kan du inte vara säker på om de är bra och om du någonsin kommer att kunna återställa dem. För katastrofåterställning bör du förvara en kopia av din säkerhetskopia någonstans utanför ditt datacenter - ifall hela datacentret skulle bli otillgängligt. För att påskynda återställningen är det mycket användbart att behålla en kopia av säkerhetskopian även på databasnoderna. Om din datauppsättning är stor, kan kopiering av den över nätverket från en backupserver till databasnoden som du vill återställa ta betydande tid. Att behålla den senaste säkerhetskopian lokalt kan avsevärt förbättra återställningstiderna.
Logisk säkerhetskopiering
Din första säkerhetskopia kommer troligen att vara en fysisk säkerhetskopia. För MySQL eller MariaDB blir det antingen något som xtrabackup eller någon slags ögonblicksbild av filsystemet. Sådana säkerhetskopior är utmärkta för att återställa en hel datauppsättning eller för att tillhandahålla nya noder. Men vid radering av en delmängd av data lider de av betydande omkostnader. Först och främst kan du inte återställa all data, annars kommer du att skriva över alla ändringar som hände efter att säkerhetskopian skapades. Det du letar efter är möjligheten att återställa bara en delmängd av data, bara de rader som av misstag togs bort. För att göra det med en fysisk säkerhetskopia måste du återställa den på en separat värd, hitta borttagna rader, dumpa dem och sedan återställa dem i produktionsklustret. Att kopiera och återställa hundratals gigabyte med data bara för att återställa en handfull rader är något vi definitivt skulle kalla en betydande overhead. För att undvika det kan du använda logiska säkerhetskopior - istället för att lagra fysisk data lagrar sådana säkerhetskopior data i ett textformat. Detta gör det enklare att hitta exakt den data som togs bort, som sedan kan återställas direkt på produktionsklustret. För att göra det ännu enklare kan du också dela upp sådan logisk säkerhetskopia i delar och säkerhetskopiera varje tabell till en separat fil. Om din datauppsättning är stor är det vettigt att dela upp en stor textfil så mycket som möjligt. Detta kommer att göra säkerhetskopieringen inkonsekvent men för de flesta fallen är detta inget problem - om du behöver återställa hela datasetet till ett konsekvent tillstånd kommer du att använda fysisk säkerhetskopiering, vilket är mycket snabbare i detta avseende. Om du bara behöver återställa en delmängd av data är kraven på konsistens mindre stränga.
Återställning vid tidpunkt
Säkerhetskopiering är bara en början - du kommer att kunna återställa dina data till den punkt där säkerhetskopieringen togs, men troligen togs data bort efter den tiden. Bara genom att återställa saknade data från den senaste säkerhetskopian kan du förlora all data som ändrades efter säkerhetskopieringen. För att undvika det bör du implementera Point-In-Time Recovery. För MySQL betyder det i princip att du måste använda binära loggar för att spela upp alla ändringar som hände mellan ögonblicket för säkerhetskopieringen och dataförlusthändelsen. Skärmbilden nedan visar hur ClusterControl kan hjälpa till med det.
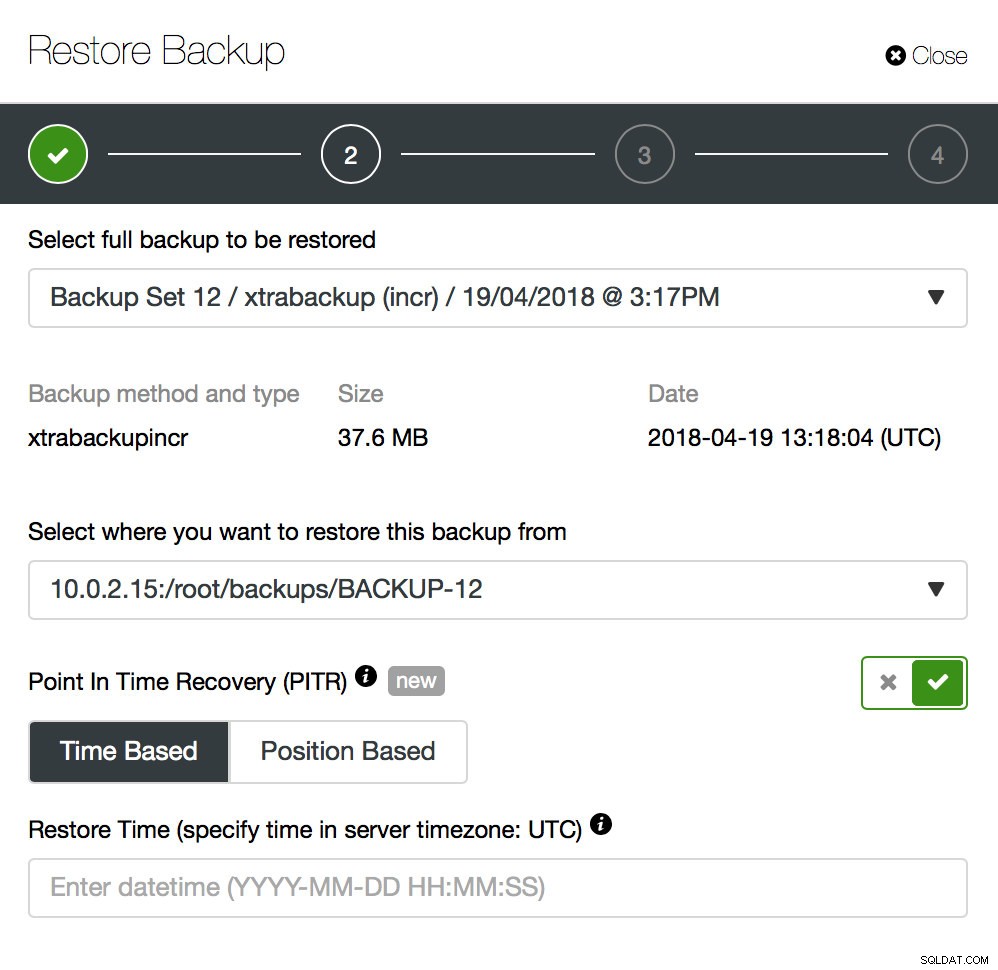
Vad du måste göra är att återställa denna säkerhetskopia fram till ögonblicket precis innan dataförlusten. Du måste återställa den på en separat värd för att inte göra ändringar i produktionsklustret. När du har återställt säkerhetskopian kan du logga in på den värden, hitta den saknade data, dumpa den och återställa i produktionsklustret.
Fördröjd slav
Alla metoder som vi diskuterade ovan har en gemensam smärtpunkt - det tar tid att återställa data. Det kan ta längre tid när du återställer all data och sedan försöker dumpa bara den intressanta delen. Det kan ta kortare tid om du har logisk säkerhetskopiering och du snabbt kan borra ner till de data du vill återställa, men det är inte på något sätt en snabb uppgift. Du måste fortfarande hitta ett par rader i en stor textfil. Ju större den är, desto mer komplicerad blir uppgiften - ibland saktar själva storleken av filen ner alla åtgärder. En metod för att undvika dessa problem är att ha en fördröjd slav. Slavar försöker vanligtvis hålla sig uppdaterade med mastern men det är också möjligt att konfigurera dem så att de håller avstånd från sin master. I skärmdumpen nedan kan du se hur du använder ClusterControl för att distribuera en sådan slav:
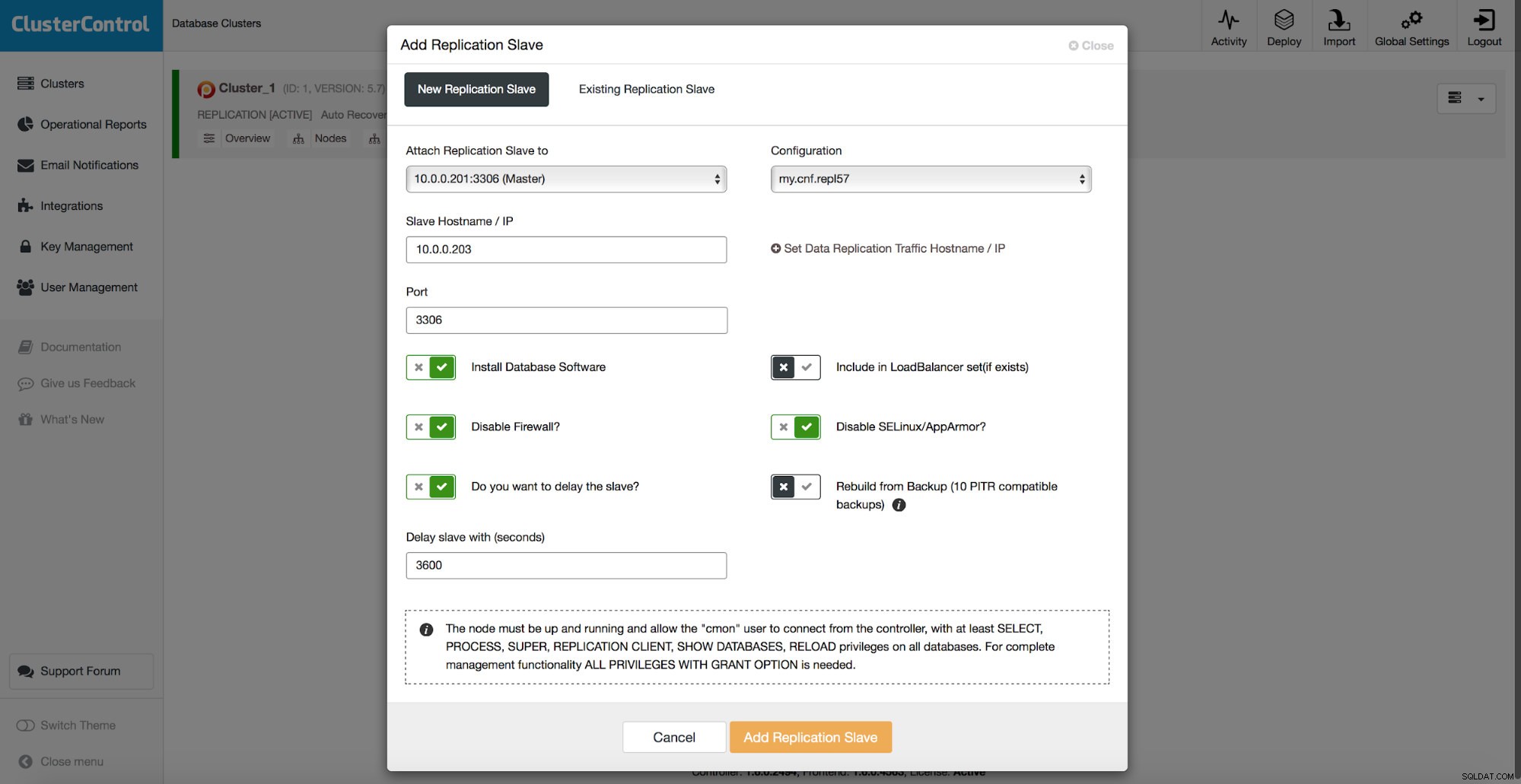
Kort sagt, vi har här ett alternativ att lägga till en replikeringsslav till databasinställningen och konfigurera den för att försenas. I skärmdumpen ovan kommer slaven att vara försenad med 3600 sekunder, vilket är en timme. Detta låter dig använda den slaven för att återställa borttagna data upp till en timme från raderingen av data. Du behöver inte återställa en säkerhetskopia, det räcker med att köra mysqldump eller SELECT ... INTO OUTFILE för de saknade data och du kommer att få data att återställa på ditt produktionskluster.
Återställer data
I det här avsnittet kommer vi att gå igenom ett par exempel på oavsiktlig radering av data och hur du kan återställa från dem. Vi kommer att gå igenom återställningen från en fullständig dataförlust, vi kommer också att visa hur man återställer från en partiell dataförlust när du använder fysiska och logiska säkerhetskopior. Vi kommer äntligen att visa dig hur du återställer rader som raderats av misstag om du har en fördröjd slav i din inställning.
Fullständig dataförlust
Oavsiktlig "rm -rf" eller "DROP SCHEMA myonlyschema;" har körts och du slutade utan data alls. Om du råkade ta bort andra filer än från MySQL-datakatalogen kan du behöva omprovisionera värden. För att göra saker enklare kommer vi att anta att endast MySQL har påverkats. Låt oss överväga två fall, med en fördröjd slav och utan en.
Ingen fördröjd slav
I det här fallet är det enda vi kan göra att återställa den senaste fysiska säkerhetskopian. Eftersom all vår data har tagits bort behöver vi inte vara oroliga för aktivitet som hände efter dataförlusten eftersom det inte finns någon aktivitet utan data. Vi borde vara oroliga för aktiviteten som hände efter att säkerhetskopieringen ägde rum. Det betyder att vi måste göra en punkt-i-tid-återställning. Naturligtvis kommer det att ta längre tid än att bara återställa data från säkerhetskopian. Om det är viktigare att få upp din databas snabbt än att få all data återställd, kan du också bara återställa en säkerhetskopia och klara det.
Först och främst, om du fortfarande har tillgång till binära loggar på servern du vill återställa, kan du använda dem för PITR. Först vill vi konvertera den relevanta delen av de binära loggarna till en textfil för vidare undersökning. Vi vet att dataförlust inträffade efter 13:00:00. Låt oss först kontrollera vilken binlogfil vi bör undersöka:
example@sqldat.com:~# ls -alh /var/lib/mysql/binlog.*
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:32 /var/lib/mysql/binlog.000001
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:33 /var/lib/mysql/binlog.000002
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:35 /var/lib/mysql/binlog.000003
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:38 /var/lib/mysql/binlog.000004
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:39 /var/lib/mysql/binlog.000005
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:41 /var/lib/mysql/binlog.000006
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:43 /var/lib/mysql/binlog.000007
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:45 /var/lib/mysql/binlog.000008
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:47 /var/lib/mysql/binlog.000009
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:49 /var/lib/mysql/binlog.000010
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:51 /var/lib/mysql/binlog.000011
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:53 /var/lib/mysql/binlog.000012
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:55 /var/lib/mysql/binlog.000013
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:57 /var/lib/mysql/binlog.000014
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:59 /var/lib/mysql/binlog.000015
-rw-r----- 1 mysql mysql 306M Apr 23 13:18 /var/lib/mysql/binlog.000016Som kan ses är vi intresserade av den sista binlogfilen.
example@sqldat.com:~# mysqlbinlog --start-datetime='2018-04-23 13:00:00' --verbose /var/lib/mysql/binlog.000016 > sql.outNär det är klart, låt oss ta en titt på innehållet i den här filen. Vi kommer att söka efter "drop schema" i vim. Här är en relevant del av filen:
# at 320358785
#180423 13:18:58 server id 1 end_log_pos 320358850 CRC32 0x0893ac86 GTID last_committed=307804 sequence_number=307805 rbr_only=no
SET @@SESSION.GTID_NEXT= '52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415'/*!*/;
# at 320358850
#180423 13:18:58 server id 1 end_log_pos 320358946 CRC32 0x487ab38e Query thread_id=55 exec_time=1 error_code=0
SET TIMESTAMP=1524489538/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
drop schema sbtest
/*!*/;Som vi kan se vill vi återställa upp till position 320358785. Vi kan skicka dessa data till ClusterControl UI:
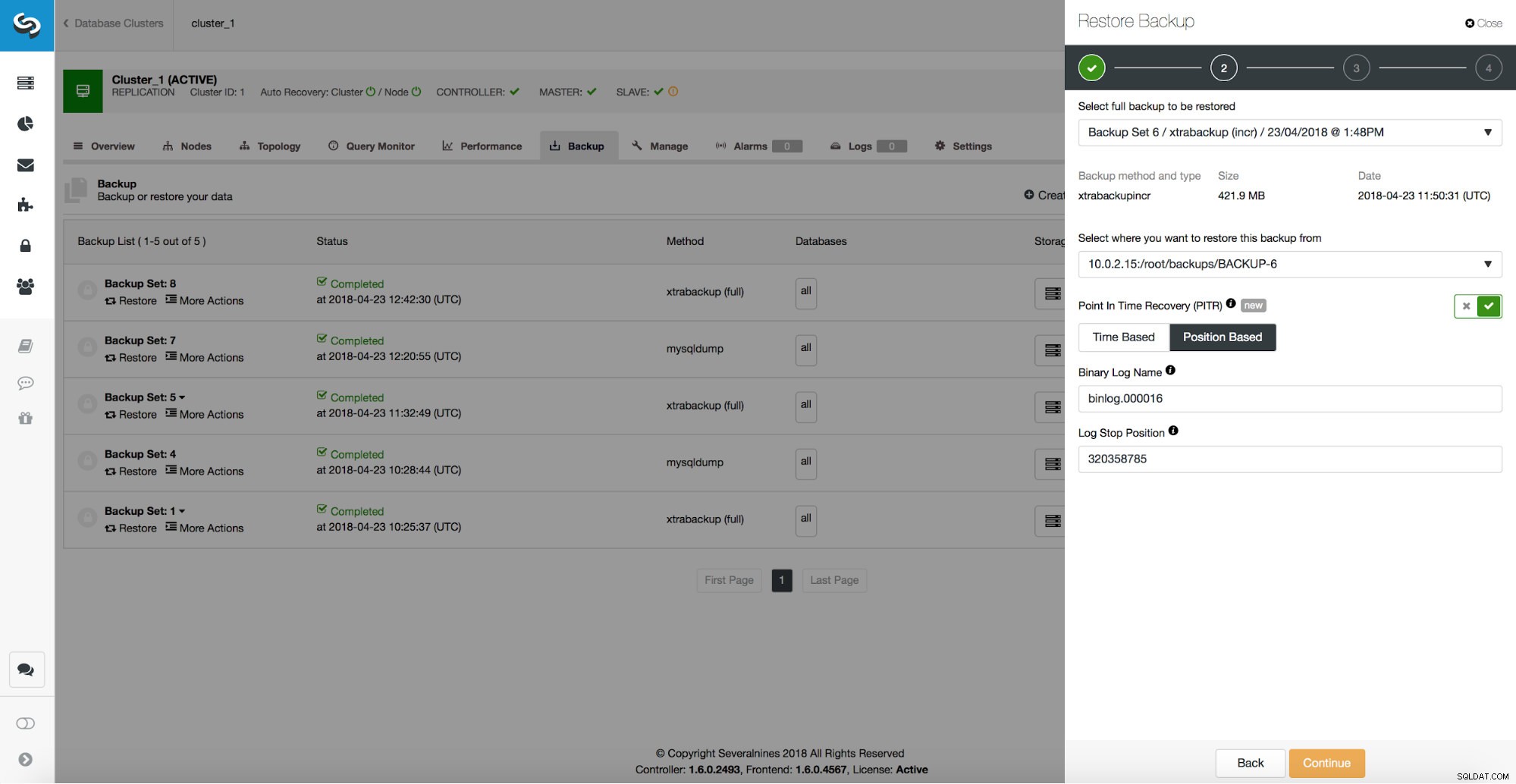
Fördröjd slav
Om vi har en fördröjd slav och den värden räcker för att hantera all trafik, kan vi använda den och marknadsföra den för att bemästra. Först måste vi dock se till att den kom ikapp den gamla mastern fram till dataförlusten. Vi kommer att använda lite CLI här för att få det att hända. Först måste vi ta reda på vilken position dataförlusten inträffade. Sedan kommer vi att stoppa slaven och låta den köra fram till dataförlusthändelsen. Vi visade hur man får rätt position i föregående avsnitt - genom att undersöka binära loggar. Vi kan antingen använda den positionen (binlog.000016, position 320358785) eller, om vi använder en flertrådad slav, ska vi använda GTID för dataförlusthändelsen (52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415) för att spela upp 443415-frågor. det GTID.
Låt oss först stoppa slaven och inaktivera fördröjningen:
mysql> STOP SLAVE;
Query OK, 0 rows affected (0.01 sec)
mysql> CHANGE MASTER TO MASTER_DELAY = 0;
Query OK, 0 rows affected (0.02 sec)Sedan kan vi starta den till en given binär loggposition.
mysql> START SLAVE UNTIL MASTER_LOG_FILE='binlog.000016', MASTER_LOG_POS=320358785;
Query OK, 0 rows affected (0.01 sec)Om vi vill använda GTID kommer kommandot att se annorlunda ut:
mysql> START SLAVE UNTIL SQL_BEFORE_GTIDS = ‘52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415’;
Query OK, 0 rows affected (0.01 sec)När replikeringen avbröts (vilket betyder att alla händelser vi bad om har utförts), bör vi verifiera att värden innehåller de saknade data. Om så är fallet kan du marknadsföra den till master och sedan bygga om andra värdar med en ny master som datakälla.
Detta är inte alltid det bästa alternativet. Allt beror på hur försenad din slav är - om den är försenad med ett par timmar kanske det inte är meningsfullt att vänta på att den ska komma ikapp, speciellt om skrivtrafiken är stor i din miljö. I sådana fall är det troligtvis snabbare att bygga om värdar med hjälp av fysisk säkerhetskopiering. Å andra sidan, om du har en ganska liten trafikvolym kan detta vara ett bra sätt att faktiskt snabbt åtgärda problemet, marknadsföra en ny master och komma vidare med att betjäna trafik, medan resten av noderna byggs om i bakgrunden .
Delvis dataförlust – fysisk säkerhetskopiering
I händelse av partiell dataförlust kan fysiska säkerhetskopior vara ineffektiva, men eftersom det är den vanligaste typen av säkerhetskopia är det mycket viktigt att veta hur man använder dem för partiell återställning. Det första steget kommer alltid att vara att återställa en säkerhetskopia upp till en tidpunkt före dataförlusthändelsen. Det är också mycket viktigt att återställa det på en separat värd. ClusterControl använder xtrabackup för fysiska säkerhetskopior så vi kommer att visa hur man använder det. Låt oss anta att vi körde följande felaktiga fråga:
DELETE FROM sbtest1 WHERE id < 23146;
Vi ville bara ta bort en enda rad ('=' i WHERE-satsen), istället tog vi bort ett gäng av dem ( mysqlbinlog --verbose /var/lib/mysql/binlog.000003 > bin.out
Låt oss nu titta på utdatafilen och se vad vi kan hitta där. Vi använder radbaserad replikering och därför kommer vi inte att se den exakta SQL som kördes. Istället (så länge vi använder --verbose flagga till mysqlbinlog) kommer vi att se händelser som nedan:
### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=999296
### @2=1009782
### @3='96260841950-70557543083-97211136584-70982238821-52320653831-03705501677-77169427072-31113899105-45148058587-70555151875'
### @4='84527471555-75554439500-82168020167-12926542460-82869925404'Som kan ses identifierar MySQL rader att radera med ett mycket exakt WHERE-villkor. Mystiska tecken i den läsbara kommentaren "@1", "@2", betyder "första kolumnen", "andra kolumnen". Vi vet att den första kolumnen är 'id', vilket är något vi är intresserade av. Vi måste hitta en stor DELETE-händelse på en 'sbtest1'-tabell. Kommentarer som följer bör nämna id för 1, sedan id för '2', sedan '3' och så vidare - allt upp till id för '23145'. Alla ska exekveras i en enda transaktion (enskild händelse i en binär logg). Efter att ha analyserat utdata med "mindre" hittade vi:
### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=1
### @2=1006036
### @3='123'
### @4='43683718329-48150560094-43449649167-51455516141-06448225399'
### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=2
### @2=1008980
### @3='123'
### @4='05603373460-16140454933-50476449060-04937808333-32421752305'Evenemanget som dessa kommentarer är bifogade startade på:
#180427 8:09:21 server id 1 end_log_pos 29600687 CRC32 0x8cfdd6ae Xid = 307686
COMMIT/*!*/;
# at 29600687
#180427 8:09:21 server id 1 end_log_pos 29600752 CRC32 0xb5aa18ba GTID last_committed=42844 sequence_number=42845 rbr_only=yes
/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;
SET @@SESSION.GTID_NEXT= '0c695e13-4931-11e8-9f2f-080027e8bf1b:55893'/*!*/;
# at 29600752
#180427 8:09:21 server id 1 end_log_pos 29600826 CRC32 0xc7b71da5 Query thread_id=44 exec_time=0 error_code=0
SET TIMESTAMP=1524816561/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
BEGIN
/*!*/;
# at 29600826Så vi vill återställa säkerhetskopian upp till föregående commit vid position 29600687. Låt oss göra det nu. Vi kommer att använda extern server för det. Vi kommer att återställa säkerhetskopian till den positionen och vi kommer att hålla återställningsservern igång så att vi senare kan extrahera de saknade data.
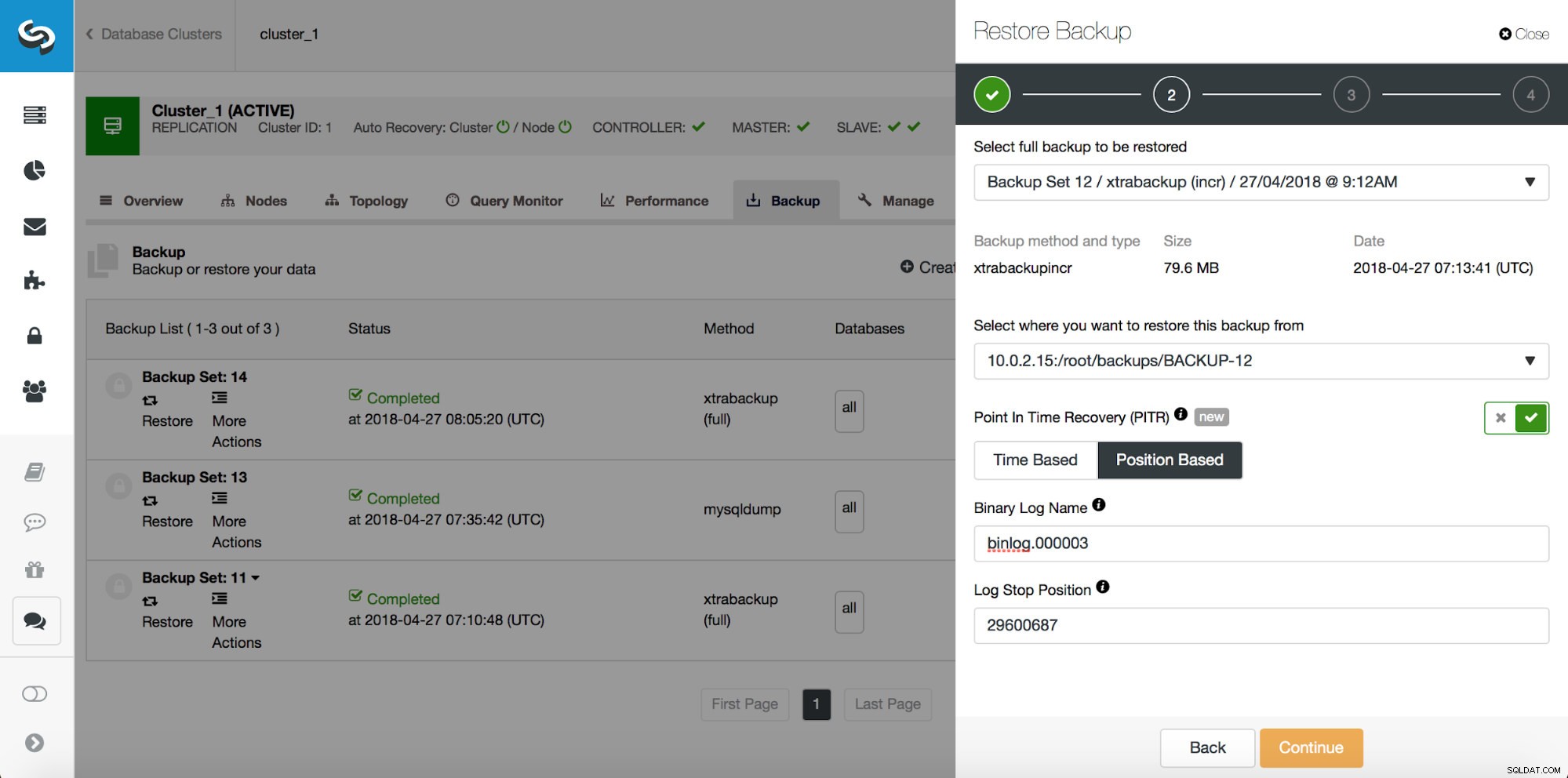
När återställningen är klar, låt oss se till att vår data har återställts:
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.03 sec)Ser bra ut. Nu kan vi extrahera dessa data till en fil som vi laddar tillbaka på mastern.
mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE 'missing.sql';
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statementNågot stämmer inte - det beror på att servern är konfigurerad att bara kunna skriva filer på en viss plats - det handlar om säkerhet, vi vill inte låta användare spara innehåll var de vill. Låt oss kontrollera var vi kan spara vår fil:
mysql> SHOW VARIABLES LIKE "secure_file_priv";
+------------------+-----------------------+
| Variable_name | Value |
+------------------+-----------------------+
| secure_file_priv | /var/lib/mysql-files/ |
+------------------+-----------------------+
1 row in set (0.13 sec)Okej, låt oss försöka en gång till:
mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE '/var/lib/mysql-files/missing.sql';
Query OK, 23145 rows affected (0.05 sec)Nu ser det mycket bättre ut. Låt oss kopiera data till mastern:
example@sqldat.com:~# scp /var/lib/mysql-files/missing.sql 10.0.0.101:/var/lib/mysql-files/
missing.sql 100% 1744KB 1.7MB/s 00:00Nu är det dags att ladda de saknade raderna på mastern och testa om det lyckades:
mysql> LOAD DATA INFILE '/var/lib/mysql-files/missing.sql' INTO TABLE sbtest.sbtest1;
Query OK, 23145 rows affected (2.22 sec)
Records: 23145 Deleted: 0 Skipped: 0 Warnings: 0
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)Det är allt, vi återställde vår saknade data.
Delvis dataförlust – logisk säkerhetskopiering
I föregående avsnitt återställde vi förlorad data med hjälp av fysisk säkerhetskopiering och en extern server. Tänk om vi hade skapat logisk säkerhetskopia? Låt oss ta en titt. Låt oss först verifiera att vi har en logisk säkerhetskopia:
example@sqldat.com:~# ls -alh /root/backups/BACKUP-13/
total 5.8G
drwx------ 2 root root 4.0K Apr 27 07:35 .
drwxr-x--- 5 root root 4.0K Apr 27 07:14 ..
-rw-r--r-- 1 root root 2.4K Apr 27 07:35 cmon_backup.metadata
-rw------- 1 root root 5.8G Apr 27 07:35 mysqldump_2018-04-27_071434_complete.sql.gzJa, den finns där. Nu är det dags att dekomprimera det.
example@sqldat.com:~# mkdir /root/restore
example@sqldat.com:~# zcat /root/backups/BACKUP-13/mysqldump_2018-04-27_071434_complete.sql.gz > /root/restore/backup.sqlNär du tittar på det kommer du att se att data lagras i INSERT-format med flera värden. Till exempel:
INSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399'),(2,1008980,'69708345057-48265944193-91002879830-11554672482-35576538285-03657113365-90301319612-18462263634-56608104414-27254248188','05603373460-16140454933-50476449060-04937808333-32421752305')Allt vi behöver göra nu är att peka ut var vårt bord finns och sedan var raderna, som är av intresse för oss, lagras. Först, genom att känna till mysqldump-mönster (släpp tabell, skapa en ny, inaktivera index, infoga data) låt oss ta reda på vilken rad som innehåller CREATE TABLE-satsen för 'sbtest1'-tabellen:
example@sqldat.com:~/restore# grep -n "CREATE TABLE \`sbtest1\`" backup.sql > out
example@sqldat.com:~/restore# cat out
971:CREATE TABLE `sbtest1` (Nu, med hjälp av en metod för försök och misstag, måste vi ta reda på var vi ska leta efter våra rader. Vi visar dig det sista kommandot vi kom fram till. Hela tricket är att försöka skriva ut olika rader med sed och sedan kontrollera om den senaste raden innehåller rader nära, men senare än vad vi söker efter. I kommandot nedan letar vi efter rader mellan 971 (CREATE TABLE) och 993. Vi ber också sed att avsluta när den når rad 994 eftersom resten av filen inte är av intresse för oss:
example@sqldat.com:~/restore# sed -n '971,993p; 994q' backup.sql > 1.sql
example@sqldat.com:~/restore# tail -n 1 1.sql | lessUtdatan ser ut som nedan:
INSERT INTO `sbtest1` VALUES (31351,1007187,'23938390896-69688180281-37975364313-05234865797-89299459691-74476188805-03642252162-40036598389-45190639324-97494758464','60596247401-06173974673-08009930825-94560626453-54686757363'),Det betyder att vårt radutbud (upp till rad med id 23145) är nära. Därefter handlar det om manuell rengöring av filen. Vi vill att det ska börja med den första raden vi behöver återställa:
INSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399')Och sluta med den sista raden att återställa:
(23145,1001595,'37250617862-83193638873-99290491872-89366212365-12327992016-32030298805-08821519929-92162259650-88126148247-75122945670','60801103752-29862888956-47063830789-71811451101-27773551230');Vi var tvungna att trimma en del av de onödiga data (det är multiline insert) men efter allt detta har vi en fil som vi kan ladda tillbaka på mastern.
example@sqldat.com:~/restore# cat 1.sql | mysql -usbtest -psbtest -h10.0.0.101 sbtest
mysql: [Warning] Using a password on the command line interface can be insecure.Till sist, sista kontrollen:
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)Allt är bra, data har återställts.
Partell dataförlust, fördröjd slav
I det här fallet kommer vi inte att gå igenom hela processen. Vi har redan beskrivit hur man identifierar positionen för en dataförlusthändelse i de binära loggarna. Vi beskrev också hur man stoppar en fördröjd slav och startar replikeringen igen, upp till en punkt före dataförlusthändelsen. Vi förklarade också hur man använder SELECT INTO OUTFILE och LOAD DATA INFILE för att exportera data från extern server och ladda den på mastern. Det är allt du behöver. Så länge data fortfarande finns på den fördröjda slaven måste du stoppa den. Sedan måste du lokalisera positionen före dataförlusthändelsen, starta slaven fram till den punkten och, när detta är gjort, använd den fördröjda slaven för att extrahera data som raderades, kopiera filen till master och ladda den för att återställa data .
Slutsats
Det är inte roligt att återställa förlorad data, men om du följer stegen vi gick igenom i den här bloggen har du en god chans att återställa det du förlorat.