Du kanske har hört talas om termen "split hjärna". Vad det är? Hur påverkar det dina kluster? I det här blogginlägget kommer vi att diskutera exakt vad det är, vilken fara det kan utgöra för din databas, hur vi kan förhindra det, och om allt går fel, hur man återhämtar sig från det.
Länge borta är enstaka instansers dagar, nuförtiden körs nästan alla databaser i replikeringsgrupper eller kluster. Detta är bra för hög tillgänglighet och skalbarhet, men en distribuerad databas introducerar nya faror och begränsningar. Ett fall som kan vara dödligt är en splittring av nätverket. Föreställ dig ett kluster av flera noder som, på grund av nätverksproblem, delades upp i två delar. Av uppenbara skäl (datakonsistens) bör båda delarna inte hantera trafik samtidigt som de är isolerade från varandra och data inte kan överföras mellan dem. Det är också fel ur tillämpningssynpunkt - även om det så småningom skulle finnas ett sätt att synkronisera data (även om avstämning av 2 datauppsättningar inte är trivialt). Ett tag skulle en del av applikationen vara omedveten om ändringarna som gjorts av andra applikationsvärdar, som kommer åt den andra delen av databasklustret. Detta kan leda till allvarliga problem.
Tillståndet där klustret har delats upp i två eller flera delar som är villiga att acceptera skrivningar kallas "split brain".
Det största problemet med delad hjärna är datadrift, eftersom skrivningar händer på båda delarna av klustret. Ingen av MySQL-varianter tillhandahåller automatiserade sätt att slå samman datauppsättningar som har divergerat. Du hittar inte en sådan funktion i MySQL-replikering, gruppreplikering eller Galera. När data väl har avvikit är det enda alternativet att antingen använda en av delarna av klustret som källan till sanningen och kassera ändringar som utförts på den andra delen - såvida vi inte kan följa någon manuell process för att slå samman data.
Det är därför vi kommer att börja med hur man förhindrar splittrade hjärnor från att hända. Det här är så mycket enklare än att behöva åtgärda eventuella dataavvikelser.
Hur man förhindrar splittrad hjärna
Den exakta lösningen beror på typen av databas och miljöns inställning. Vi kommer att ta en titt på några av de vanligaste fallen för Galera Cluster och MySQL-replikering.
Galera-kluster
Galera har en inbyggd "kretsbrytare" för att hantera delad hjärna:den förlitar sig på en kvorummekanism. Om en majoritet (50% + 1) av noderna är tillgängliga i klustret kommer Galera att fungera normalt. Om det inte finns någon majoritet kommer Galera att sluta betjäna trafik och byta till så kallat "icke-primärt" tillstånd. Detta är i stort sett allt du behöver för att hantera en splittrad hjärna när du använder Galera. Visst, det finns manuella metoder för att tvinga Galera till "Primär" tillstånd även om det inte finns en majoritet. Saken är den att om du inte gör det bör du vara säker.
Sättet hur kvorum beräknas har viktiga återverkningar - på en enskild datacenternivå vill du ha ett udda antal noder. Tre noder ger dig en tolerans för fel på en nod (2 noder matchar kravet på att mer än 50 % av noderna i klustret är tillgängliga). Fem noder ger dig en tolerans för fel på två noder (5 - 2 =3 vilket är mer än 50 % från 5 noder). Å andra sidan, att använda fyra noder kommer inte att förbättra din tolerans över tre nodkluster. Det skulle fortfarande bara hantera ett fel på en nod (4 - 1 =3, mer än 50 % från 4) medan fel på två noder kommer att göra klustret oanvändbart (4 - 2 =2, bara 50 %, inte mer).
När du distribuerar Galera-kluster i ett enda datacenter, kom ihåg att du helst skulle vilja distribuera noder över flera tillgänglighetszoner (separat strömkälla, nätverk, etc.) - så länge de finns i ditt datacenter, dvs. . En enkel installation kan se ut så här:
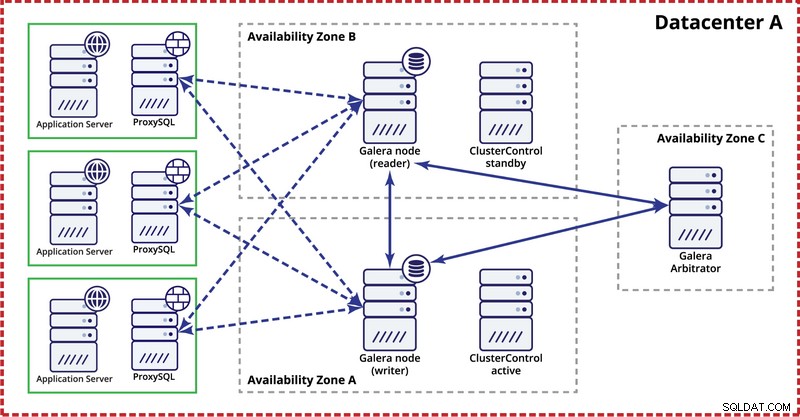
På multidatacenternivå är dessa överväganden också tillämpliga. Om du vill att Galera-klustret automatiskt ska hantera datacenterfel bör du använda ett udda antal datacenter. För att minska kostnaderna kan du använda en Galera-arbitrator i en av dem istället för en databasnod. Galera arbitrator (garbd) är en process som deltar i kvorumberäkningen men den innehåller inga data. Detta gör det möjligt att använda det även på mycket små instanser eftersom det inte är resurskrävande - även om nätverksanslutningen måste vara bra eftersom den "ser" all replikeringstrafik. Exempelinställning kan se ut som i ett diagram nedan:
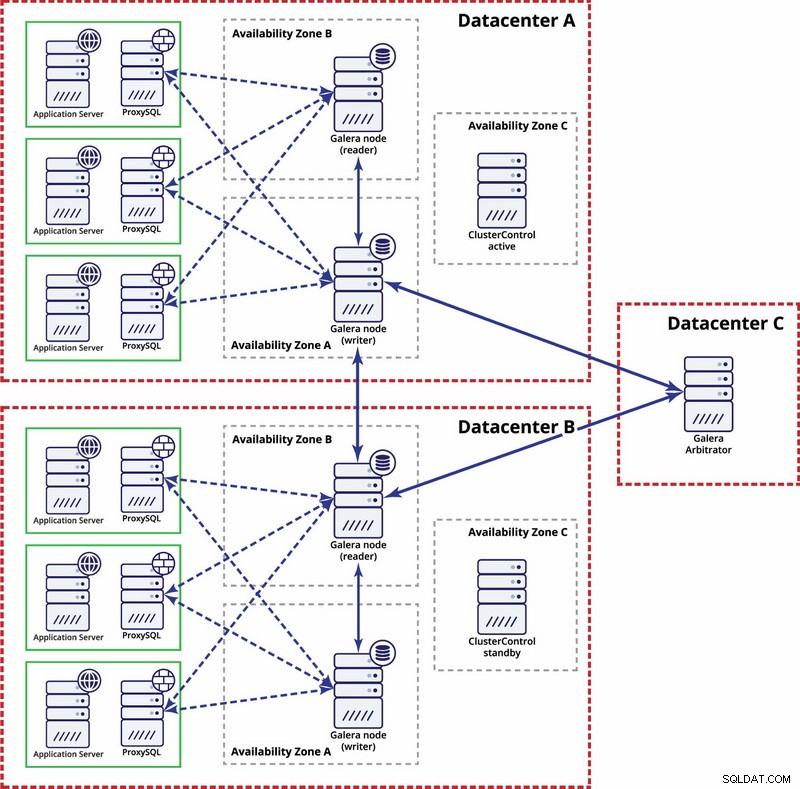
MySQL-replikering
Med MySQL-replikering är det största problemet att det inte finns någon inbyggd kvorummekanism, som det är i Galera-klustret. Därför krävs fler steg för att säkerställa att din installation inte kommer att påverkas av en delad hjärna.
En metod är att undvika automatiserade failovers över datacenter. Du kan konfigurera din failover-lösning (det kan vara genom ClusterControl, eller MHA eller Orchestrator) till failover endast inom ett enda datacenter. Om det var ett fullständigt datacenteravbrott skulle det vara upp till administratören att bestämma hur failover ska ske och hur man säkerställer att servrarna i det misslyckade datacentret inte kommer att användas.
Det finns alternativ för att göra det mer automatiserat. Du kan använda Consul för att lagra data om noderna i replikeringsinställningen, och vilken av dem som är master. Sedan blir det upp till administratören (eller via något skript) att uppdatera denna post och flytta skrivningar till det andra datacentret. Du kan dra nytta av en Orchestrator/Raft-installation där Orchestrator-noder kan distribueras över flera datacenter och upptäcka split hjärna. Baserat på detta kan du vidta olika åtgärder som, som vi nämnde tidigare, uppdatera poster i vår konsul eller etcd. Poängen är att detta är en mycket mer komplex miljö att ställa in och automatisera än Galera-klustret. Nedan kan du hitta exempel på multidatacenterinstallation för MySQL-replikering.
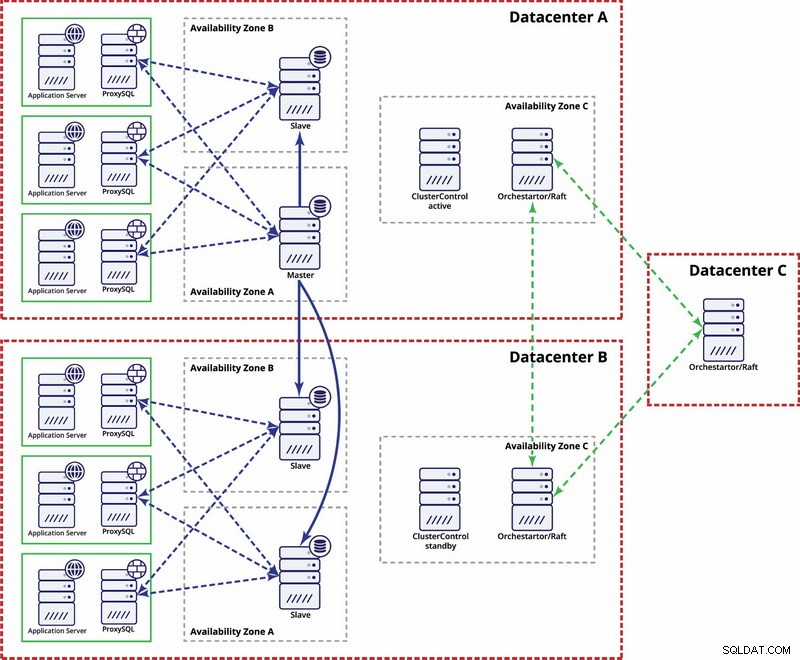
Kom ihåg att du fortfarande måste skapa skript för att få det att fungera, d.v.s. övervaka Orchestrator-noder för en delad hjärna och vidta nödvändiga åtgärder för att implementera STONITH och se till att mastern i datacenter A inte kommer att användas när nätverket konvergerar och anslutningen kommer att återställas.
Split Brain Happened - Vad ska jag göra härnäst?
Det värsta scenariot inträffade och vi har datadrift. Vi ska försöka ge dig några tips om vad som kan göras här. Tyvärr beror de exakta stegen mest på din schemadesign så det kommer inte att vara möjligt att skriva en exakt hur man gör.
Vad du måste tänka på är att det slutliga målet kommer att vara att kopiera data från en master till en annan och återskapa alla relationer mellan tabeller.
Först och främst måste du identifiera vilken nod som kommer att fortsätta tjäna data som master. Detta är en datauppsättning till vilken du kommer att slå samman data som lagrats på den andra "master"-instansen. När det är gjort måste du identifiera data från den gamla mastern som saknas på den nuvarande mastern. Detta kommer att vara manuellt arbete. Om du har tidsstämplar i dina tabeller kan du använda dem för att lokalisera de data som saknas. I slutändan kommer binära loggar att innehålla alla dataändringar så att du kan lita på dem. Du kan också behöva lita på din kunskap om datastrukturen och relationerna mellan tabeller. Om dina data är normaliserade kan en post i en tabell vara relaterad till poster i andra tabeller. Till exempel kan din applikation infoga data i "user"-tabellen som är relaterad till "address"-tabellen med hjälp av user_id. Du måste hitta alla relaterade rader och extrahera dem.
Nästa steg blir att ladda dessa data till den nya mastern. Här kommer den knepiga delen - om du förberett dina inställningar i förväg kan det här helt enkelt vara en fråga om att köra ett par insatser. Om inte, kan detta vara ganska komplicerat. Det handlar om primärnyckel och unika indexvärden. Om dina primärnyckelvärden genereras som unika på varje server med någon sorts UUID-generator eller med inställningarna auto_increment_increment och auto_increment_offset i MySQL, kan du vara säker på att data från den gamla mastern du måste infoga inte kommer att orsaka primärnyckel eller unika nyckelkonflikter med data på den nya mastern. Annars kan du behöva ändra data från den gamla mastern manuellt för att säkerställa att den kan infogas korrekt. Det låter komplext, så låt oss ta en titt på ett exempel.
Låt oss föreställa oss att vi infogar rader med auto_increment på nod A, som är en master. För enkelhetens skull fokuserar vi bara på en enda rad. Det finns kolumner "id" och "värde".
Om vi infogar den utan någon speciell inställning ser vi poster som nedan:
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’Dessa kommer att replikera till slaven (B). Om den splittrade hjärnan inträffar och skrivningar kommer att utföras på både gamla och nya master, kommer vi att hamna i följande situation:
A
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value4’
1005, ‘some value5’
1006, ‘some value7’B
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value6’
1005, ‘some value8’
1006, ‘some value9’Som du kan se finns det inget sätt att helt enkelt dumpa poster med id 1004, 1005 och 1006 från nod A och lagra dem på nod B eftersom vi kommer att sluta med duplicerade primärnyckelposter. Det som behöver göras är att ändra värdena för id-kolumnen i raderna som kommer att infogas till ett värde som är större än maxvärdet för id-kolumnen från tabellen. Detta är allt som behövs för enstaka rader. För mer komplexa relationer, där flera tabeller är inblandade, kan du behöva göra ändringarna på flera platser.
Å andra sidan, om vi hade förutsett detta potentiella problem och konfigurerat våra noder för att lagra udda ID på nod A och jämna ID på nod B, skulle problemet ha varit så mycket lättare att lösa.
Nod A konfigurerades med auto_increment_offset =1 och auto_increment_increment =2
Nod B konfigurerades med auto_increment_offset =2 och auto_increment_increment =2
Så här skulle data se ut på nod A före den delade hjärnan:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’När en delad hjärna inträffade kommer det att se ut som nedan.
Nod A:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’Nod B:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1010, ‘some value8’
1012, ‘some value9’Nu kan vi enkelt kopiera saknade data från nod A:
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’Och ladda den till nod B som slutar med följande datauppsättning:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1009, ‘some value4’
1010, ‘some value8’
1011, ‘some value5’
1012, ‘some value9’
1013, ‘some value7’Visst, raderna är inte i den ursprungliga ordningen, men det här borde vara ok. I värsta fall måste du sortera efter kolumnen "värde" i frågor och kanske lägga till ett index på den för att göra sorteringen snabb.
Föreställ dig nu hundratals eller tusentals rader och en mycket normaliserad tabellstruktur - för att återställa en rad kan det innebära att du måste återställa flera av dem i ytterligare tabeller. Med ett behov av att ändra id:n (eftersom du inte hade skyddsinställningar på plats) över alla relaterade rader och allt detta är manuellt arbete, kan du föreställa dig att detta inte är den bästa situationen att vara i. Det tar tid att återhämta sig och det är en felbenägen process. Lyckligtvis, som vi diskuterade i början, finns det sätt att minimera chansen att delad hjärna kommer att påverka ditt system eller för att minska det arbete som behöver göras för att synkronisera tillbaka dina noder. Se till att du använder dem och var förberedd.