Jag börjar med den andra frågan, som är lättare. Använda dplyr paketet kan du använda top_n för att få de n största raderna för en given kolumn. Till exempel:
> top_n(p_ash_r_100a, 3, SMPL_CNT) %>% arrange(desc(SMPL_CNT))
# A tibble: 3 × 5
SMPL_TIME SQL_ID MODULE EVENT SMPL_CNT
<dttm> <chr> <chr> <chr> <int>
1 2017-04-11 09:01:00 NO_SQL GoldenGate CPU 7
2 2017-04-11 09:00:00 dgzp3at57cagd GoldenGate db file sequential read 2
3 2017-04-11 09:01:00 37cspa0acgqxp GoldenGate db file sequential read 2
Observera att du får fler än n rader om det är oavgjort på n:e plats. Alltså top_n(p_ash_r_100, 10, SMPL_CNT) kommer att returnera hela provdatauppsättningen på grund av den 17-vägsmässiga kopplingen för 4:an.
När det gäller den första frågan, dokumentationen för geom_area ger en ledtråd:
Detta tyder på att geom_area förväntar sig att kolumnen som mappas till x ska vara numerisk. Baserat på listan för p_ash_r_100 , SMPL_TIME verkar vara en teckenvektor. Med lubridate paket, kan vi konvertera SMPL_TIME till en datum-tid med dmy_hm :
p_ash_r_100a <- p_ash_r_100 %>%
mutate_at(vars(SMPL_TIME), dmy_hm)
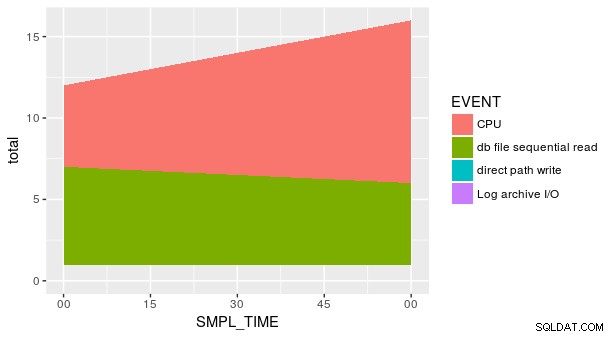
Detta är dock inte tillräckligt för att få den plot du vill ha eftersom det finns flera värden för y för varje kombination av x och fill (vilket är den korrekta estetiken för geom_area , inte "col "). Vi måste sammanfatta data innan vi plottar:
p_ash_r_100a %>%
group_by(SMPL_TIME, EVENT) %>%
summarise(total = sum(SMPL_CNT)) %>%
ggplot(aes(SMPL_TIME, total, fill = EVENT)) +
geom_area()
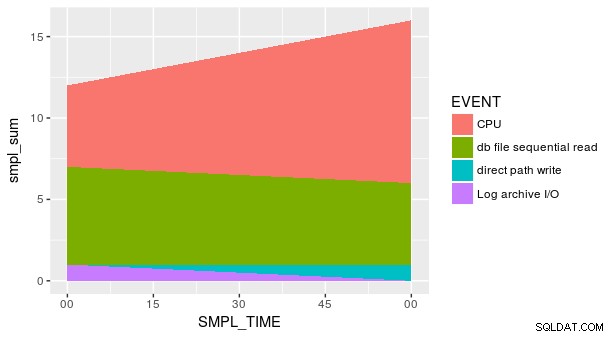
Ändå är handlingen fortfarande inte korrekt. Detta beror på att varje kombination av SMPL_TIME och EVENT är inte representerad i datamängden. Vi måste uttryckligen berätta för geom_area att y är lika med noll för de rader som saknas. Ett sätt är att använda den praktiska fill argument i tidyr::spread .
group_by(p_ash_r_100a, SMPL_TIME, EVENT) %>%
summarise(smpl_sum = sum(SMPL_CNT)) %>%
spread(EVENT, smpl_sum, fill = 0) %>%
gather(EVENT, smpl_sum, CPU, `db file sequential read`,
`direct path write`,
`Log archive I/O`) %>%
ggplot(aes(x = SMPL_TIME, y = smpl_sum, fill = EVENT)) +
geom_area()