Detta är ett ganska vanligt problem.
Vanligt B-Tree index är inte bra för frågor som denna:
SELECT measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
Ett index är bra för att söka efter värden inom de givna gränserna, så här:
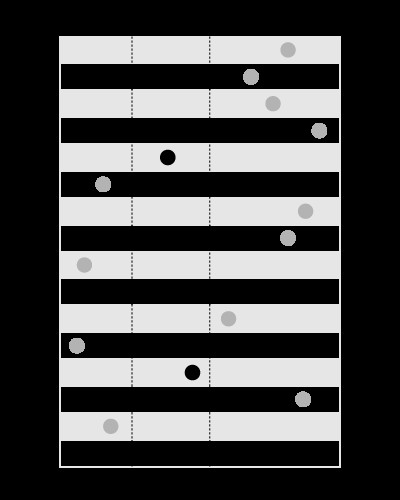
, men inte för att söka efter gränserna som innehåller det givna värdet, så här:
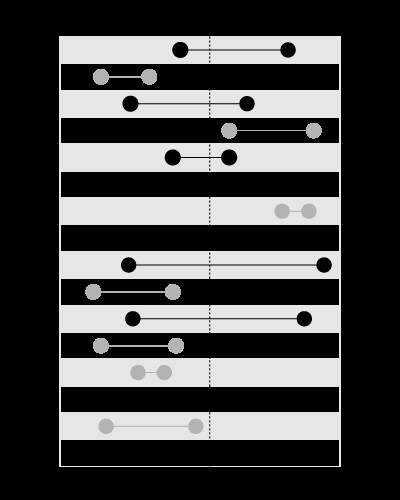
Den här artikeln i min blogg förklarar problemet mer detaljerat:
(modellen med kapslade uppsättningar behandlar liknande typ av predikat).
Du kan göra indexet på time , på detta sätt intervals kommer att vara ledande i sammanfogningen, kommer tidsintervallet att användas inuti de kapslade looparna. Detta kräver sortering på time .
Du kan skapa ett rumsligt index på intervals (tillgänglig i MySQL med MyISAM lagring) som skulle inkludera start och end i en geometrikolumn. På det här sättet measures kan leda i sammanfogningen och ingen sortering kommer att behövas.
De rumsliga indexen är dock långsammare, så detta kommer bara att vara effektivt om du har få mått men många intervall.
Eftersom du har få intervall men många mått, se bara till att du har ett index på measures.time :
CREATE INDEX ix_measures_time ON measures (time)
Uppdatering:
Här är ett exempelskript att testa:
BEGIN
DBMS_RANDOM.seed(20091223);
END;
/
CREATE TABLE intervals (
entry_time NOT NULL,
exit_time NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level,
TO_DATE('23.12.2009', 'dd.mm.yyyy') - level + DBMS_RANDOM.value
FROM dual
CONNECT BY
level <= 1500
/
CREATE UNIQUE INDEX ux_intervals_entry ON intervals (entry_time)
/
CREATE TABLE measures (
time NOT NULL,
measure NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level / 720,
CAST(DBMS_RANDOM.value * 10000 AS NUMBER(18, 2))
FROM dual
CONNECT BY
level <= 1080000
/
ALTER TABLE measures ADD CONSTRAINT pk_measures_time PRIMARY KEY (time)
/
CREATE INDEX ix_measures_time_measure ON measures (time, measure)
/
Denna fråga:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_NL(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
använder NESTED LOOPS och returnerar i 1.7 sekunder.
Denna fråga:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_MERGE(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
använder MERGE JOIN och jag var tvungen att stoppa det efter 5 minuter.
Uppdatering 2:
Du kommer med största sannolikhet att behöva tvinga motorn att använda rätt tabellordning i joinningen med hjälp av ett tips så här:
SELECT /*+ LEADING (intervals) USE_NL(intervals, measures) */
measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
Oracle s optimizer är inte tillräckligt smart för att se att intervallen inte skär varandra. Det är därför den med största sannolikhet kommer att använda measures som en ledande tabell (vilket skulle vara ett klokt beslut om intervallen skär varandra).
Uppdatering 3:
WITH splits AS
(
SELECT /*+ MATERIALIZE */
entry_range, exit_range,
exit_range - entry_range + 1 AS range_span,
entry_time, exit_time
FROM (
SELECT TRUNC((entry_time - TO_DATE(1, 'J')) * 2) AS entry_range,
TRUNC((exit_time - TO_DATE(1, 'J')) * 2) AS exit_range,
entry_time,
exit_time
FROM intervals
)
),
upper AS
(
SELECT /*+ MATERIALIZE */
MAX(range_span) AS max_range
FROM splits
),
ranges AS
(
SELECT /*+ MATERIALIZE */
level AS chunk
FROM upper
CONNECT BY
level <= max_range
),
tiles AS
(
SELECT /*+ MATERIALIZE USE_MERGE (r s) */
entry_range + chunk - 1 AS tile,
entry_time,
exit_time
FROM ranges r
JOIN splits s
ON chunk <= range_span
)
SELECT /*+ LEADING(t) USE_HASH(m t) */
SUM(LENGTH(stuffing))
FROM tiles t
JOIN measures m
ON TRUNC((m.time - TO_DATE(1, 'J')) * 2) = tile
AND m.time BETWEEN t.entry_time AND t.exit_time
Den här frågan delar upp tidsaxeln i intervallen och använder en HASH JOIN för att sammanfoga måtten och tidsstämplarna på intervallvärdena, med finfiltrering senare.
Se den här artikeln i min blogg för mer detaljerade förklaringar om hur det fungerar: